OmniPlan: An Adaptive Framework for Timely and Near-Optimal Network Planning Optimization
Pith reviewed 2026-06-26 21:56 UTC · model grok-4.3
The pith
OmniPlan translates natural-language user goals into a preference vector that selects and tunes a mix of solvers for fast near-optimal network plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
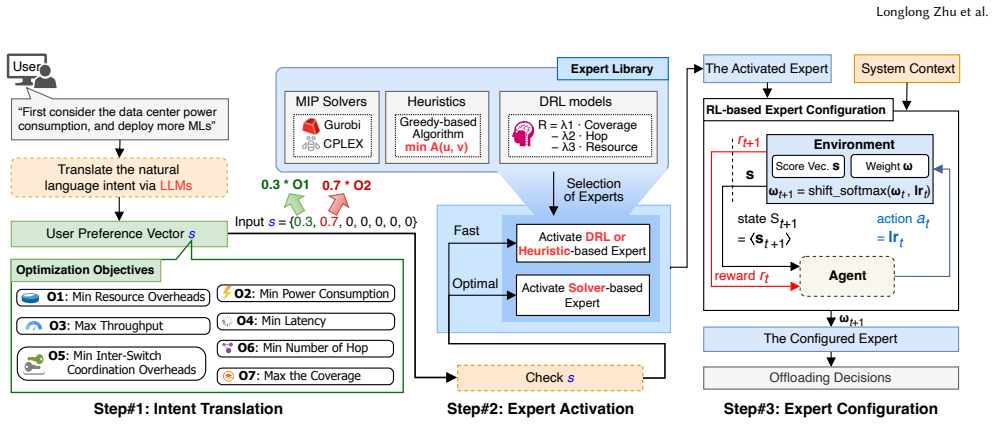
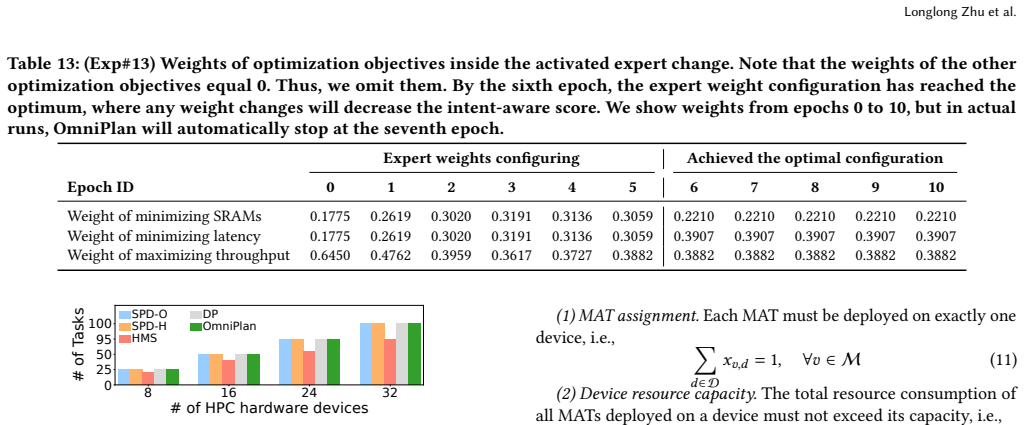
OmniPlan achieves near-optimal and low-execution-time offloading for real-world ML inference tasks by converting natural-language intents into a unified preference vector via an LLM interpreter, dynamically selecting among MIP solvers, heuristics, and DRL experts, and fine-tuning weights with a DRL configuration module, yielding latency reductions of up to 97.8 percent and network device resource reductions of up to 11.5 percent.
What carries the argument
Mixture-of-experts architecture that dynamically selects and configures MIP solvers, heuristics, and DRL models according to an LLM-derived user-preference vector.
If this is right
- Planning decisions for distributed ML inference can be generated in low time while staying close to optimal across decision trees, SVMs, naive Bayes, XGBoost, and random forests.
- The same framework can be applied to any network planning task whose objectives can be expressed as weighted combinations of latency and resource metrics.
- User preferences stated in ordinary language become directly usable inputs without requiring manual translation into solver parameters.
- Dynamic intent changes no longer require restarting the entire optimization pipeline.
Where Pith is reading between the lines
- The approach could be tested on transportation or power-grid planning problems that also involve competing objectives and natural-language stakeholder goals.
- If the preference vector generalizes across domains, the framework might reduce the engineering effort needed to adapt optimization tools to new application areas.
- Real-time scenarios with rapidly changing intents become feasible once the LLM interpreter and expert selector run with low overhead.
Load-bearing premise
The LLM interpreter converts natural-language intents into a preference vector that accurately guides expert choice and weight tuning without introducing errors that degrade planning quality.
What would settle it
A test case in which the LLM misreads a user intent, selects a mismatched expert, and produces a plan whose latency or resource use exceeds that of a fixed baseline solver.
Figures
read the original abstract
Network planning optimization is a fundamental problem across diverse domains, including transportation systems, communication networks, and power grids. It requires simultaneous optimization of multiple competing objectives under complex constraints. Existing network planning optimization frameworks rely on mixed integer programming (MIP) solvers, heuristics, and deep reinforcement learning (DRL) models to compute planning decisions. However, they lack effective adaptability to diverse and dynamic user intents, thus leading to the trade-off between execution time and optimality. In this paper, we propose OmniPlan, an adaptive framework that achieves both timeliness and near-optimality in network planning optimization. To achieve the adaptability lacking in existing solutions, OmniPlan employs a large language model (LLM)-based interpreter to convert heterogeneous natural-language intents into a unified and quantifiable user-preference vector. Then it employs a mixture-of-experts architecture that integrates MIP solvers, heuristics, and DRL models as specialized experts, where OmniPlan adapts to diverse intents by dynamically selecting timely and near-optimal experts. Finally, it incorporates a DRL-based expert configuration module that fine-tunes optimization objective weights to align planning decisions with user-specific preferences. We evaluate OmniPlan with a representative real-world workload, i.e., distributed machine learning (ML), where we leverage OmniPlan to offload a wide spectrum of ML inference tasks, e.g., decision trees, SVM, naive Bayes, XGBoost, and random forests, onto a network of hardware devices. Our experiments on a real-world testbed indicate that OmniPlan achieves near-optimal and low-execution-time offloading for real-world ML inference tasks, reducing latency by up to 97.8\% and network device resource consumption by up to 11.5\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniPlan, an adaptive framework for network planning optimization. It converts heterogeneous natural-language user intents into a unified preference vector via an LLM-based interpreter, then uses a mixture-of-experts architecture (MIP solvers, heuristics, DRL models) dynamically selected for timeliness and near-optimality, plus a DRL expert-configuration module to tune objective weights. Evaluated on distributed ML inference offloading (decision trees, SVM, naive Bayes, XGBoost, random forests) to hardware devices on a real-world testbed, it claims near-optimal low-execution-time decisions with up to 97.8% latency reduction and 11.5% resource savings.
Significance. If the central claims hold, the work could meaningfully advance adaptive multi-objective network optimization by linking natural-language intents to quantitative planning via LLM interpretation and expert selection. The integration of MIP, heuristics, and DRL with dynamic weighting addresses a recognized gap in existing solvers. The real-world ML workload evaluation on a testbed adds practical value, though the absence of supporting data or validation metrics limits assessment of the reported gains.
major comments (2)
- [Abstract] Abstract: the performance claims (97.8% latency reduction, 11.5% resource savings) are stated without any equations, data tables, error bars, derivation steps, or baseline comparisons, preventing verification that the gains arise from the proposed LLM interpreter, expert selection, and DRL tuning rather than experimental artifacts or post-hoc selection.
- [Evaluation] Evaluation section: no quantitative metrics (e.g., vector error rates, intent-to-preference correlation, or optimality-gap analysis across intent types) are supplied for the LLM interpreter's fidelity in mapping natural-language intents to the preference vector; this mapping is load-bearing for the adaptability claim and the reported gains, as biased or erroneous vectors would misalign expert choice and weight tuning.
minor comments (2)
- The abstract lists ML models (decision trees, SVM, naive Bayes, XGBoost, random forests) but provides no details on how these tasks were mapped to network offloading decisions or the specific constraints used.
- No discussion of potential LLM hallucinations or bias in the interpreter, nor any fallback mechanism if the preference vector is unreliable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation. We address each major comment below with proposed revisions where the manuscript can be strengthened without misrepresenting the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (97.8% latency reduction, 11.5% resource savings) are stated without any equations, data tables, error bars, derivation steps, or baseline comparisons, preventing verification that the gains arise from the proposed LLM interpreter, expert selection, and DRL tuning rather than experimental artifacts or post-hoc selection.
Authors: Abstracts are space-constrained and conventionally omit equations, tables, and full derivations; the manuscript supplies these details in the Evaluation section via baseline comparisons (standalone MIP, heuristics, DRL) and reported figures/tables. We will partially revise the abstract to name the primary baselines and add a sentence directing readers to the evaluation results for verification of the gains. revision: partial
-
Referee: [Evaluation] Evaluation section: no quantitative metrics (e.g., vector error rates, intent-to-preference correlation, or optimality-gap analysis across intent types) are supplied for the LLM interpreter's fidelity in mapping natural-language intents to the preference vector; this mapping is load-bearing for the adaptability claim and the reported gains, as biased or erroneous vectors would misalign expert choice and weight tuning.
Authors: The current evaluation validates the interpreter indirectly via end-to-end ML offloading performance. We agree that direct metrics would better support the adaptability claim. We will revise the Evaluation section to add quantitative analysis, including intent-to-preference correlation and error rates on a held-out intent set, to quantify mapping fidelity. revision: yes
Circularity Check
No circularity detected; framework claims rest on described components without self-referential reductions.
full rationale
The provided abstract describes OmniPlan's components (LLM interpreter, mixture-of-experts, DRL configuration) and reports empirical results on a testbed (latency and resource reductions), but contains no equations, fitting procedures, or self-citations that reduce any claimed prediction or optimality to its own inputs by construction. No derivation chain is exhibited that would allow identification of self-definitional, fitted-input, or self-citation load-bearing steps. The central claims are presented as outcomes of evaluation rather than mathematical derivations forced by prior steps within the paper. Without internal equations or load-bearing citations in the given text, the derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barefoot Tofino
Barefoot Network. Barefoot Tofino. 2025. https://www.barefootnetworks.com/ technology/#tofino
2025
-
[2]
Rajarshi Chattopadhyay and Chen-Khong Tham. 2022. Mixture of Experts based Model Integration for Traffic State Prediction. In2022 IEEE 95th Vehicular Technology Conference:(VTC2022-Spring). IEEE, 1–7
2022
-
[3]
Xiang Chen, Qun Huang, Peiqiao Wang, Hongyan Liu, Yuxin Chen, Dong Zhang, Haifeng Zhou, and Chunming Wu. 2021. MTP: Avoiding control plane overload with measurement task placement. InIEEE INFOCOM. 1–10
2021
-
[4]
Xiang Chen, Qun Huang, Peiqiao Wang, Zili Meng, Hongyan Liu, Yuxin Chen, Dong Zhang, Haifeng Zhou, Boyang Zhou, and Chunming Wu. 2021. Lightnf: Simplifying network function offloading in programmable networks. In2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS). IEEE, 1–10
2021
-
[5]
Xiang Chen, Hongyan Liu, Qun Huang, Peiqiao Wang, Dong Zhang, Haifeng Zhou, and Chunming Wu. 2020. SPEED: Resource-Efficient and High- Performance Deployment for Data Plane Programs. InIEEE ICNP. 1–12
2020
-
[6]
Xiang Chen, Hongyan Liu, Qingjiang Xiao, Qun Huang, Dong Zhang, Haifeng Zhou, Boyang Zhou, Chunming Wu, Xuan Liu, and Qiang Yang. 2024. Hermes: Low-Overhead Inter-Switch Coordination in Network-Wide Data Plane Program Deployment.IEEE/ACM Transactions on Networking(2024), 2842–2857
2024
-
[7]
Xiang Chen, Qingjiang Xiao, Hongyan Liu, Qun Huang, Dong Zhang, Xuan Liu, Longbing Hu, Haifeng Zhou, Chunming Wu, and Kui Ren. 2024. Eagle: To- ward Scalable and Near-Optimal Network-Wide Sketch Deployment in Network Measurement. InACM SIGCOMM. 291–310
2024
-
[8]
CPLEX. 2025. https://www.ibm.com/analytics/cplex-optimizer
2025
- [9]
- [10]
-
[11]
Paul Emmerich, Sebastian Gallenmüller, Daniel Raumer, Florian Wohlfart, and Georg Carle. 2015. MoonGen: A scriptable high-speed packet generator. InACM IMC. 275–287
2015
-
[12]
Jiaqi Gao, Ennan Zhai, Hongqiang Harry Liu, Rui Miao, Yu Zhou, Bingchuan Tian, Chen Sun, Dennis Cai, Ming Zhang, and Minlan Yu. 2020. Lyra: A cross- platform language and compiler for data plane programming on heterogeneous asics. InACM SIGCOMM. 435–450
2020
-
[13]
Sam Gross, Marc’Aurelio Ranzato, and Arthur Szlam. 2017. Hard mixtures of experts for large scale weakly supervised vision. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6865–6873
2017
-
[14]
Yang Gu, Hengyu You, Jian Cao, Muran Yu, Haoran Fan, and Shiyou Qian. 2025. Large Language Models for Constructing and Optimizing Machine Learning Workflows: A Survey.ACM Trans. Softw. Eng. Methodol.(2025)
2025
-
[15]
Arpit Gupta, Rob Harrison, Marco Canini, Nick Feamster, Jennifer Rexford, and Walter Willinger. 2018. Sonata: Query-driven streaming network telemetry. In ACM SIGCOMM. 357–371
2018
-
[16]
Gurobi Optimizer. 2025. http://www.gurobi.com
2025
-
[17]
Joseph L Hodges Jr and Erich L Lehmann. 2011. Estimates of location based on rank tests. InSelected works of EL Lehmann. Springer, 287–300
2011
-
[18]
Mary Hogan, Shir Landau-Feibish, Mina Tahmasbi Arashloo, Jennifer Rexford, and David Walker. 2022. Modular Switch Programming Under Resource Con- straints. InUSENIX NSDI. 1–15
2022
- [19]
-
[20]
Wenzhao Jiang, Jindong Han, Hao Liu, Tao Tao, Naiqiang Tan, and Hui Xiong
-
[21]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Interpretable cascading mixture-of-experts for urban traffic congestion prediction. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5206–5217
-
[22]
Lavanya Jose, Lisa Yan, George Varghese, and Nick McKeown. 2015. Compiling Packet Programs to Reconfigurable Switches.. InUSENIX NSDI. 103–115
2015
-
[23]
Simon Knight, Hung X Nguyen, Nickolas Falkner, Rhys Bowden, and Matthew Roughan. 2011. The internet topology zoo.IEEE Journal on Selected Areas in Communications29, 9 (2011), 1765–1775
2011
- [24]
-
[25]
Yuanpeng Li, Zhen Xu, Zongwei Lv, Yannan Hu, Yong Cui, and Tong Yang
- [26]
-
[27]
Hongyan Liu, Xiang Chen, Qun Huang, Guoqiang Sun, Peiqiao Wang, Dong Zhang, Chunming Wu, Xuan Liu, and Qiang Yang. 2024. Toward Resource- Efficient and High- Performance Program Deployment in Programmable Net- works.IEEE/ACM Transactions on Networking(2024), 4270–4285
2024
-
[28]
Hongyan Liu, Xiang Chen, Qun Huang, Haifeng Zhou, Dong Zhang, and Chun- ming Wu. 2020. Sra: Switch resource aggregation for application offloading in programmable networks. InGLOBECOM 2020-2020 IEEE Global Communications Conference. IEEE, 1–6
2020
-
[29]
Saeed Masoudnia and Reza Ebrahimpour. 2014. Mixture of experts: a literature survey.Artificial Intelligence Review42 (2014), 275–293
2014
-
[30]
Mininet. 2025. http://mininet.org/
2025
-
[31]
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. 2022. Multimodal contrastive learning with limoe: the language-image mixture of experts.Advances in Neural Information Processing Systems35 (2022), 9564–9576
2022
-
[32]
Jianing Pei, Peilin Hong, Kaiping Xue, and Defang Li. 2018. Efficiently embedding service function chains with dynamic virtual network function placement in geo- distributed cloud system.IEEE Transactions on Parallel and Distributed Systems 30, 10 (2018), 2179–2192
2018
- [33]
-
[34]
Nik Sultana, John Sonchack, Hans Giesen, Isaac Pedisich, Zhaoyang Han, Nis- hanth Shyamkumar, Shivani Burad, André DeHon, and Boon Thau Loo. 2021. Flightplan: Dataplane disaggregation and placement for p4 programs. InUSENIX NSDI. 571–592
2021
-
[35]
LangGenius Team. 2023. Dify: The open platform for LLMOps and AI-native apps. https://github.com/langgenius/dify. Accessed: 2025-05-13
2023
-
[36]
Arpita Vats, Rahul Raja, Vinija Jain, and Aman Chadha. 2024. The Evolution of Mixture of Experts: A Survey from Basics to Breakthroughs.Preprints(August 2024). doi:10.20944/preprints202408.0583.v1
-
[37]
Duo Wu, Xianda Wang, Yaqi Qiao, Zhi Wang, Junchen Jiang, Shuguang Cui, and Fangxin Wang. 2024. Netllm: Adapting large language models for networking. InProceedings of the ACM SIGCOMM 2024 Conference. 661–678
2024
-
[38]
Yihan Wu, Yifan Peng, Yichen Lu, Xuankai Chang, Ruihua Song, and Shinji Watanabe. 2024. Robust Audiovisual Speech Recognition Models with Mixture- of-Experts. In2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 43–48
2024
-
[39]
Minrui Xu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Shiwen Mao, Zhu Han, Abbas Jamalipour, Dong In Kim, Xuemin Shen, Victor C. M. Leung, and H. Vincent Poor. 2024. Unleashing the Power of Edge-Cloud Generative AI in Mobile Networks: A Survey of AIGC Services.Commun. Surveys Tuts.26, 2 (2024), 1127–1170
2024
-
[40]
Wenquan Xu et al. 2023. Clickinc: In-network computing as a service in hetero- geneous programmable data-center networks. InACM SIGCOMM. 798–815
2023
-
[41]
Xiang Xu, Lingdong Kong, Hui Shuai, Liang Pan, Ziwei Liu, and Qingshan Liu
- [42]
-
[43]
Yunting Xu, Jiacheng Wang, Ruichen Zhang, Changyuan Zhao, Dusit Niyato, Jiawen Kang, Zehui Xiong, Bo Qian, Haibo Zhou, Shiwen Mao, et al. 2025. De- centralization of Generative AI via Mixture of Experts for Wireless Networks: A Comprehensive Survey.arXiv preprint arXiv:2504.19660(2025)
-
[44]
Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuofan Zong, Yu Liu, and Ping Luo. 2023. Raphael: Text-to-image generation via large mixture of diffusion paths.Advances in Neural Information Processing Systems36 (2023), 41693–41706
2023
-
[45]
Wilson, and Paul D
Seniha Esen Yuksel, Joseph N. Wilson, and Paul D. Gader. 2012. Twenty Years of Mixture of Experts.IEEE Transactions on Neural Networks and Learning Systems 23, 8 (2012), 1177–1193
2012
-
[46]
Songli Zhang, Weijia Jia, Zhiqing Tang, Jiong Lou, and Wei Zhao. 2022. Efficient instance reuse approach for service function chain placement in mobile edge computing.Computer Networks211 (2022), 109010
2022
-
[47]
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Xiaoquan Zhang, Lin Cui, Fung Po Tso, Zhetao Li, and Weijia Jia. 2023. Dapper: Deploying Service Function Chains in the Programmable Data Plane Via Deep Reinforcement Learning.IEEE Transactions on Services Computing16, 4 (2023), 2532–2544
2023
-
[49]
Changgang Zheng, Haoyue Tang, Mingyuan Zang, Xinpeng Hong, Aosong Feng, Leandros Tassiulas, and Noa Zilberman. 2023. DINC: Toward Distributed In-Network Computing.Proc. ACM Netw.1, CoNEXT3 (2023), 14:1–14:25
2023
-
[50]
maximize bandwidth and minimize latency
Yan Zhuang, Zhenzhe Zheng, Fan Wu, and Guihai Chen. 2024. LiteMoE: Cus- tomizing On-device LLM Serving via Proxy Submodel Tuning. InProceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems. 521–534. OmniPlan : An Adaptive Framework for Timely and Near-Optimal Network Planning Optimization 11 Appendix 11.1 Notation of Main Symbols Table ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.