Deep Reinforcement Learning for Minimum Zero-Forcing Sets
Pith reviewed 2026-06-27 00:59 UTC · model grok-4.3
The pith
A reinforcement learning model adapted from S2V-DQN can identify small zero-forcing sets on undirected graphs by learning node selection policies under the color-change rule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The SD-ZFS framework adapts the S2V-DQN architecture so that states are represented as graph embeddings and actions correspond to selecting a node that triggers the zero-forcing color-change rule; models trained under this adaptation return zero-forcing sets whose sizes are competitive with optimal solutions on small graphs and smaller than those returned by the greedy heuristic across multiple graph datasets with different structures.
What carries the argument
The SD-ZFS adaptation of S2V-DQN, which encodes the zero-forcing color propagation rule inside the reinforcement learning state and action space so that learned policies directly select nodes that force uncolored vertices to change color.
If this is right
- The same trained policy can be applied to new graphs without retraining from scratch when the graphs share structural features with the training set.
- Network-control tasks that rely on minimum zero-forcing sets become solvable at larger scales than exact methods allow.
- Performance differences across graph families reveal how local connectivity patterns affect the difficulty of finding a minimum forcing set.
Where Pith is reading between the lines
- Similar reinforcement-learning adaptations could be tried on other NP-hard graph problems that admit a local propagation or coloring rule.
- If the approach transfers reliably, it reduces the need to design separate heuristics for each new network-control application that uses zero-forcing sets.
Load-bearing premise
The S2V-DQN architecture can be adapted to the zero-forcing set problem so that the resulting policies generalize, scale, and transfer across different network types without problem-specific modifications that would invalidate the reported performance.
What would settle it
A family of graphs on which the trained SD-ZFS policy consistently returns zero-forcing sets whose size exceeds the known minimum size obtained from an exact solver on the same instances.
Figures


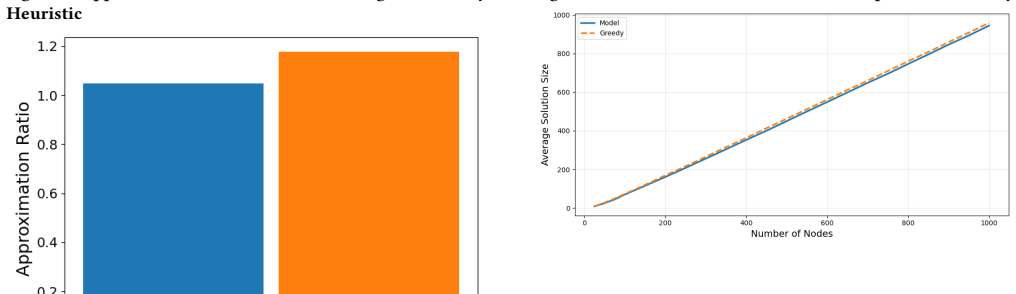

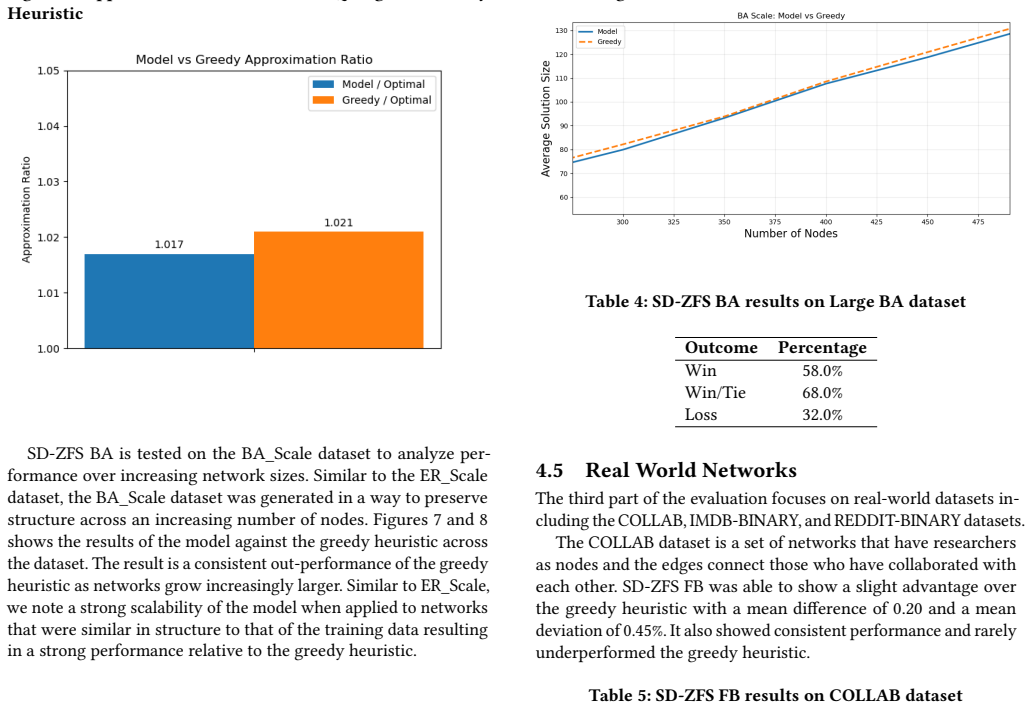
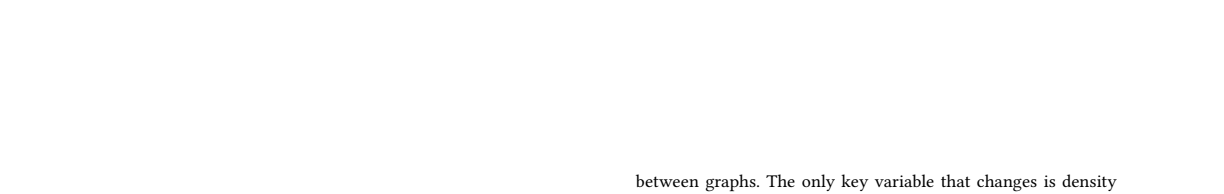


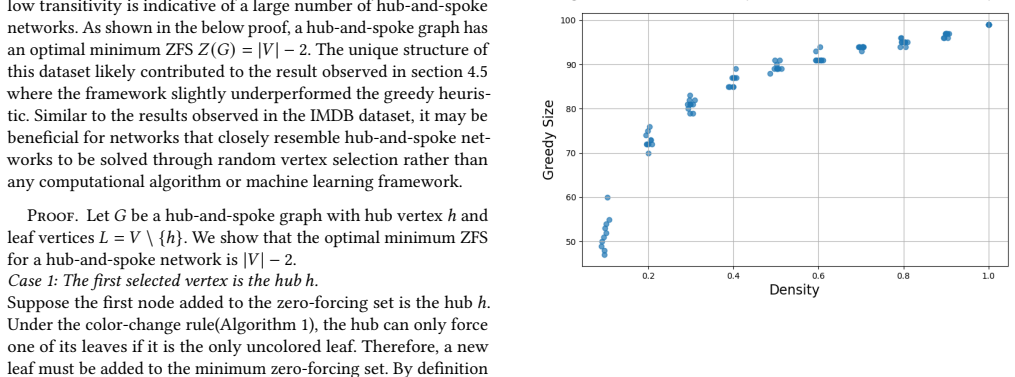
read the original abstract
This paper explores the problem of finding the minimum zero-forcing set on undirected graphs and proposes an adapted machine-learning framework to solve the problem. The minimum zero-forcing set problem is a graph coloring problem where the color of an initial set of nodes propagates throughout a network. The set of nodes is zero-forcing if it forces all uncolored nodes to change color under the constraint of the color-change rule. There are several applications to this problem across different domains such as network science, network control, and designing logical circuits. Finding the minimum zero-forcing set is shown to be NP-hard. We propose a reinforcement learning framework, SD-ZFS, that adapts the S2V-DQN architecture to the ZFS problem. We train several models on this adapted framework and analyze the performance across graph datasets that have varying structures. We evaluate how the models trained on the framework generalize, scale, and transfer to different network types. The results demonstrate the effectiveness of the framework when compared against the optimal solution and greedy heuristic. We provide further insight into how the ZFS problem can be solved through machine-learning and the influence of network structure on the problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SD-ZFS, a reinforcement-learning framework adapting the S2V-DQN architecture to compute minimum zero-forcing sets on undirected graphs. It trains models on graph datasets with varying structures and evaluates generalization, scaling, and transfer, claiming that the learned policies outperform both exact optimal solutions and a greedy heuristic.
Significance. If the empirical claims are substantiated with complete experimental protocols, the work would supply a practical, data-driven heuristic for an NP-hard graph problem relevant to network control and circuit design. The adaptation of an existing RL architecture to a new combinatorial setting is a modest but potentially useful contribution; however, the absence of reported details on graph sizes, instance counts, variance, and baseline computation limits any assessment of whether the performance gains are robust or merely artifacts of small-graph regimes.
major comments (2)
- [Abstract] Abstract: the central claim that SD-ZFS 'demonstrates the effectiveness of the framework when compared against the optimal solution and greedy heuristic' across datasets with varying structures is not supported by any reported experimental protocol, graph-size statistics, number of instances, error bars, or ablation results. Without these, the superiority assertion cannot be evaluated.
- [Evaluation] Evaluation on generalization, scaling, and transfer (implied experimental section): because the minimum zero-forcing set problem is NP-hard, exact optima are feasible only for small n (typically n ≲ 20–25). The manuscript must explicitly state the sizes of graphs used for each baseline; any claim of effectiveness versus the true optimum on larger instances used for scaling or transfer experiments constitutes an untested extrapolation from the greedy baseline alone.
minor comments (1)
- [Abstract] The abstract and introduction should include a brief statement of the precise graph families (Erdős–Rényi, scale-free, etc.) and the range of n and edge densities employed.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater experimental transparency. We will revise the manuscript to provide the requested details on protocols, graph sizes, instance counts, and variance, while clarifying the scope of comparisons to optimal solutions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SD-ZFS 'demonstrates the effectiveness of the framework when compared against the optimal solution and greedy heuristic' across datasets with varying structures is not supported by any reported experimental protocol, graph-size statistics, number of instances, error bars, or ablation results. Without these, the superiority assertion cannot be evaluated.
Authors: We agree that the abstract and evaluation sections currently omit explicit reporting of graph sizes, instance counts, error bars, and ablation results. In the revision we will add a dedicated experimental protocol subsection that reports these statistics, including the number of graphs per dataset, multiple random seeds for variance, and any ablations performed. This will allow readers to properly assess the performance claims. revision: yes
-
Referee: [Evaluation] Evaluation on generalization, scaling, and transfer (implied experimental section): because the minimum zero-forcing set problem is NP-hard, exact optima are feasible only for small n (typically n ≲ 20–25). The manuscript must explicitly state the sizes of graphs used for each baseline; any claim of effectiveness versus the true optimum on larger instances used for scaling or transfer experiments constitutes an untested extrapolation from the greedy baseline alone.
Authors: We accept this point. The revised manuscript will explicitly state that exact optimal solutions are computed only for graphs with n ≤ 25 and that all scaling, generalization, and transfer experiments on larger graphs are evaluated exclusively against the greedy heuristic. We will remove or qualify any phrasing that could be read as claiming optimality on instances beyond the small-n regime. revision: yes
Circularity Check
No circularity: empirical RL adaptation with external baselines
full rationale
The paper adapts an existing S2V-DQN architecture to the minimum zero-forcing set problem and reports empirical performance of trained policies versus optimal solutions (small graphs) and greedy heuristics (larger graphs). No derivation, equation, or prediction reduces to a fitted parameter or self-citation by construction; results are obtained from standard RL training and hold-out evaluation on graph datasets. The central claims rest on experimental comparisons rather than any closed-form reduction to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL training hyperparameters
axioms (1)
- domain assumption The color-change rule (a colored vertex with exactly one uncolored neighbor forces that neighbor to color) correctly models the zero-forcing process.
Reference graph
Works this paper leans on
-
[1]
2008.Hardness Results and Approximation Algorithms for Some Problems on Graphs
Ashkan Aazami. 2008.Hardness Results and Approximation Algorithms for Some Problems on Graphs. Doctor of Philosophy Thesis. University of Waterloo, Wa- terloo, Ontario, Canada
2008
-
[2]
Obaid Ullah Ahmad, Mudassir Shabbir, Waseem Abbas, and Xenofon Koutsoukos
-
[3]
A Graph Machine Learning Framework to Compute Zero Forcing Sets in Graphs.IEEE Transactions on Network Science and Engineering11, 2 (2024)
2024
-
[4]
AIM Minimum Rank Special Graphs Work Group. 2008. Zero forcing sets and the minimum rank of graphs.Linear Algebra Appl.428, 7 (2008), 1628–1648
2008
-
[5]
2016.Network Science
Albert-László Barabási. 2016.Network Science. Cambridge University Press
2016
-
[6]
Fast, and Illya V
Boris Brimkov, Caleb C. Fast, and Illya V. Hicks. 2019. Computational Approaches for Zero Forcing and Related Problems.European Journal of Operational Research 273, 3 (2019), 889–903
2019
-
[7]
Boris Brimkov, Derek Mikesell, and Illya V. Hicks. 2021. Improved Computational Approaches and Heuristics for Zero Forcing.INFORMS Journal on Computing33, 4 (2021), 1384–1399. doi:10.1287/ijoc.2020.1032
-
[8]
Burgarth, D
D. Burgarth, D. D’Alessandro, L. Hogben, S. Severini, and M. Young. 2013. Zero forcing, linear and quantum controllability for systems evolving on networks. IEEE Trans. Automat. Control58, 9 (Sept. 2013), 2349–2354
2013
-
[9]
Daniel Burgarth, Vittorio Giovannetti, Leslie Hogben, Simone Severini, and Michael Young. 2014. Logic circuits from zero forcing.Natural Computing(2014). doi:10.1007/s11047-014-9438-5
-
[10]
Butler, L
S. Butler, L. DeLoss, J. Grout, H. T. Hall, J. LaGrange, T. McKay, J. Smith, and G. Tims. 2014. Minimum Rank Library (Sage Programs for Calculating Bounds on the Minimum Rank of a Graph, and for Computing Zero Forcing Parameters)
2014
-
[11]
Learning Combinatorial Optimization Algorithms over Graphs
Hanjun Dai, Elias B. Khalil, Yuyu Zhang, Bistra Dilkina, and Le Song. 2017. Learning Combinatorial Optimization Algorithms over Graphs. InAdvances in Neural Information Processing Systems (NeurIPS). arXiv:1704.01665 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Haynes, Sandra M
Teresa W. Haynes, Sandra M. Hedetniemi, Stephen T. Hedetniemi, and Michael A. Henning. 2002. Domination in Graphs Applied to Electric Power Networks. SIAM Journal on Discrete Mathematics15, 4 (2002), 519–529. doi:10.1137/ S0895480100375831
2002
-
[13]
Hopcroft and Richard M
John E. Hopcroft and Richard M. Karp. 1973. An 𝑛5/2 Algorithm for Maximum Matchings in Bipartite Graphs.SIAM J. Comput.2, 4 (1973), 225–231. doi:10.1137/ 0202019
1973
-
[14]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-Level Control Through Deep Reinforce...
-
[15]
Hado van Hasselt, Arthur Guez, and David Silver. 2016. Deep Reinforcement Learning with Double Q-Learning.Proceedings of the AAAI Conference on Artificial Intelligence30, 1 (2016), 2094–2100
2016
-
[16]
Yedidia, William T
Jonathan S. Yedidia, William T. Freeman, and Yair Weiss. 2003. Understanding Belief Propagation and Its Generalizations. InExploring Artificial Intelligence in the New Millennium. Morgan Kaufmann, 239–269. Delivered in the Distinguished Lecture track of IJCAI 2001. Table 8: Performance on large and real-world graphs. Large ER Large BA COLLAB IMDB REDDIT M...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.