Grounding Spoken LLMs in Multi-Speaker Audio via Diarization Conditioning
Pith reviewed 2026-06-26 22:36 UTC · model grok-4.3
The pith
Conditioning the acoustic encoder on diarization masks lets frozen spoken LLMs handle multi-speaker far-field audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
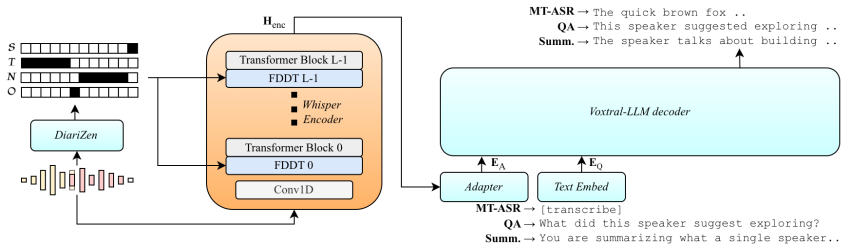
We propose diarization-conditioned spoken language models (SLMs), a strategy for extending SLMs to far-field multi-talker audio. Rather than adapting the decoder via Serialized Output Training, which risks catastrophic forgetting, we condition the acoustic encoder on diarization masks to extract target-speaker representations, keeping the decoder frozen. We instantiate this as Dixtral, integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM.
What carries the argument
The Diarization Conditioned Whisper (DiCoW) encoder, which receives diarization masks as conditioning input to extract target-speaker acoustic representations for the frozen decoder.
If this is right
- Dixtral outperforms Gemini 3.0 Flash by 29.0% absolute cpWER on speaker-attributed transcription across AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6.
- Zero-shot Dixtral matches Gemini on far-field content understanding in the long-form multi-speaker QA benchmark.
- Fine-tuned Dixtral surpasses both Gemini and Voxtral operating on close-talk across all QA tasks.
Where Pith is reading between the lines
- The encoder-only conditioning pattern could be applied to other frozen multimodal LLMs where only the perception front-end needs task-specific signals.
- If diarization quality improves independently, the same frozen decoder could support increasingly complex multi-speaker interactions without further tuning.
- This separation of concerns might make it easier to swap in newer encoders while preserving the language capabilities of the original SLM.
Load-bearing premise
Diarization masks are sufficiently accurate to allow the conditioned encoder to extract useful target-speaker representations that the frozen decoder can leverage for multi-speaker tasks.
What would settle it
Running the model on audio with deliberately degraded or random diarization masks and measuring whether cpWER gains disappear relative to the unconditioned baseline.
Figures
read the original abstract
We propose diarization-conditioned spoken language models (SLMs), a strategy for extending SLMs to far-field multi-talker audio. Rather than adapting the decoder via Serialized Output Training, which risks catastrophic forgetting, we condition the acoustic encoder on diarization masks to extract target-speaker representations, keeping the decoder frozen. We instantiate this as Dixtral, integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM. On AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6, Dixtral outperforms Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2 on speaker-attributed transcription by 29.0%, 19.8%, and 16.0% absolute cpWER respectively. On a novel long-form multi-speaker QA benchmark, zero-shot Dixtral matches Gemini on far-field content understanding, and when fine-tuned surpasses both Gemini and Voxtral operating on close-talk across all tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes diarization-conditioned spoken language models (SLMs) for far-field multi-talker audio. Instead of fine-tuning the decoder via Serialized Output Training, it conditions the acoustic encoder on diarization masks to extract target-speaker representations while keeping the decoder frozen. The approach is instantiated as Dixtral by integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM. It reports that Dixtral outperforms Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2 on speaker-attributed transcription by 29.0%, 19.8%, and 16.0% absolute cpWER on AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6, and that zero-shot Dixtral matches Gemini on a novel long-form multi-speaker QA benchmark while fine-tuned Dixtral surpasses both Gemini and close-talk Voxtral across tasks.
Significance. If the empirical claims hold, the work demonstrates a practical route to grounding SLMs in multi-speaker far-field audio without decoder adaptation and its attendant risk of catastrophic forgetting. The reported absolute cpWER reductions of 16–29% on four public benchmarks and the competitive or superior results on the new QA task would constitute a meaningful advance for speaker-attributed transcription and content understanding in realistic acoustic conditions. The explicit design choice to freeze the decoder is a clear methodological strength that merits attention if the supporting experiments are completed.
major comments (2)
- [Abstract/Methods] Abstract and Methods: the reported 16–29% absolute cpWER gains and the QA benchmark results rest on the assumption that diarization masks are accurate enough for the conditioned encoder to produce representations the frozen decoder can exploit. No description is given of the diarization system, its word or speaker error rates on the evaluation sets, or any ablation that replaces oracle masks with realistic noisy masks; without these, the central claim cannot be evaluated.
- [Results] Results section: the manuscript states performance gains on multiple benchmarks but supplies neither full training details, hyper-parameters, baseline re-implementation verification, nor error analysis. This absence directly prevents assessment of whether the data support the outperformance claims against Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency on diarization details and experimental reproducibility. We will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: the reported 16–29% absolute cpWER gains and the QA benchmark results rest on the assumption that diarization masks are accurate enough for the conditioned encoder to produce representations the frozen decoder can exploit. No description is given of the diarization system, its word or speaker error rates on the evaluation sets, or any ablation that replaces oracle masks with realistic noisy masks; without these, the central claim cannot be evaluated.
Authors: We agree that explicit details on the diarization system are required to fully evaluate the central claim. The revised manuscript will add a dedicated subsection describing the diarization pipeline, its word and speaker error rates on each evaluation set, and an ablation replacing oracle masks with the system's realistic (noisy) outputs to quantify robustness. revision: yes
-
Referee: [Results] Results section: the manuscript states performance gains on multiple benchmarks but supplies neither full training details, hyper-parameters, baseline re-implementation verification, nor error analysis. This absence directly prevents assessment of whether the data support the outperformance claims against Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2.
Authors: We acknowledge the absence of these details limits independent verification. The revision will include an expanded experimental section with complete training hyper-parameters, optimizer settings, data splits, baseline re-implementation notes (including any API or checkpoint versions used), and a concise error analysis breaking down failure modes on the reported benchmarks. revision: yes
Circularity Check
No circularity: empirical results on public benchmarks with no derivations or self-referential fitting
full rationale
The paper presents an empirical method for conditioning an acoustic encoder on diarization masks while freezing the decoder, instantiated as Dixtral, and reports direct performance comparisons (cpWER, QA tasks) against external models on public datasets (AMI, NOTSOFAR-1, LibriSpeechMix, Mixer6). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmark results rather than any internal reduction to the method's own inputs by construction. This is the standard case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diarization masks can be supplied as input and used by the acoustic encoder to extract target-speaker representations without degrading overall model function.
Reference graph
Works this paper leans on
-
[1]
Introduction Spoken Large Language Models (SLMs) are increasingly being more capable of multi-talker speech processing [1–4] with some models now supporting long-form speaker attributed transcrip- tion. While not yet as performant as the modular pipelines [5– 10] that dominate current challenges such as CHiME-6-8 [11– 13] and NOTSOFAR-1 [14,15], they prom...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Dixtral builds upon V oxtral [37], a pretrained SLM comprising a Whisper [38] encoder, a modality adapter, and a Ministral 3 [39] LLM-based decoder
Dixtral: Architecture The overall architecture is illustrated in Figure 1. Dixtral builds upon V oxtral [37], a pretrained SLM comprising a Whisper [38] encoder, a modality adapter, and a Ministral 3 [39] LLM-based decoder. While V oxtral demonstrates strong single-speaker speech understanding, it does not support speaker attribution. Our approach is to r...
-
[3]
Which city did this speaker men- tion as an example of good dog parks?
Experimental Setup 3.1. Model Initialization To initialize Dixtral, we leverage the shared pretraining dynam- ics of V oxtral and DiCoW. Because V oxtral learned its projec- tor with a frozen Whisper encoder [37] and DiCoW learned its FDDT with a frozen decoder, combining them introduces minimal architectural friction. This compatibility allows for an ini...
-
[4]
parent model
Results 4.1. Target-Speaker Transcription Performance Table 2 evaluates Dixtral against task-specific systems (Di- CoW v3.3 [50], VibeV oice [1], V oxtral MTv2 [46]) and the 1https://hf.co/datasets/popcornell/NSF-QA 2https://github.com/BUTSpeechFIT/Dixtral Table 2:Concatenated Minimum-Permutation Word Error Rate (cpWER, %) comparison across multi-talker d...
-
[5]
In- stantiated as Dixtral, this approach outperforms existing spoken LLMs on speaker-attributed transcription across four datasets
Conclusion We proposed diarization-conditioned spoken LLMs, a general strategy for grounding spoken LLMs in multi-talker audio by conditioning the encoder while keeping the decoder frozen. In- stantiated as Dixtral, this approach outperforms existing spoken LLMs on speaker-attributed transcription across four datasets. On QA and summarization, zero-shot D...
-
[6]
Linguistics, Artificial Intelligence and Language and Speech Technologies: from Research to Applications
Acknowledgements The work was supported by Ministry of Education, Youth and Sports of the Czech Republic (MoE) through the OP JAK project “Linguistics, Artificial Intelligence and Language and Speech Technologies: from Research to Applications” (ID:CZ.02.01.01/00/23 020/0008518), and Brno Ph.D. Talent Scholarship Programme. Computing on IT4I supercomputer...
-
[7]
Generative AI Use Disclosure Generative AI tools have been used to help revise and refine the manuscript
-
[8]
VIBEVOICE-ASR technical report,
Z. Penget al., “VIBEVOICE-ASR technical report,” 2026. [Online]. Available: https://arxiv.org/abs/2601.18184
-
[9]
TagSpeech: End-to-end multi-speaker ASR and diarization with fine-grained temporal grounding,
M. Huo, Y . Shao, and Y . Zhang, “TagSpeech: End-to-end multi-speaker ASR and diarization with fine-grained temporal grounding,” 2026. [Online]. Available: https://arxiv.org/abs/2601. 06896
2026
-
[10]
Large language model can transcribe speech in multi-talker scenarios with versatile instructions,
L. Meng, S. Hu, J. Kang, Z. Li, Y . Wang, W. Wu, X. Wu, X. Liu, and H. Meng, “Large language model can transcribe speech in multi-talker scenarios with versatile instructions,” in ICASSP 2025 - 2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[11]
MOSS transcribe diarize: Accurate transcription with speaker diarization,
D. Yuet al., “MOSS transcribe diarize: Accurate transcription with speaker diarization,”arXiv preprint arXiv:2601.01554, 2026
-
[12]
The USTC-NERCSLIP systems for CHiME-7 challenge,
R. Wanget al., “The USTC-NERCSLIP systems for CHiME-7 challenge,” inProc. of CHiME, 2023, pp. 13–18
2023
-
[13]
The USTC-NERCSLIP systems for the CHiME- 8 NOTSOFAR-1 challenge,
S. Niuet al., “The USTC-NERCSLIP systems for the CHiME- 8 NOTSOFAR-1 challenge,” in8th International Workshop on Speech Processing in Everyday Environments (CHiME 2024), 2024, pp. 31–36
2024
-
[14]
The IACAS-Thinkit system for CHiME-7 challenge,
L. Ye, H. Lu, G. Cheng, Y . Chen, Z. Shang, and X. Li, “The IACAS-Thinkit system for CHiME-7 challenge,” inProc. of CHiME, 2023, pp. 23–26
2023
-
[15]
STCON System for the CHiME-8 Chal- lenge,
A. Mitrofanovet al., “STCON System for the CHiME-8 Chal- lenge,” inProc. of CHiME, 2024, pp. 13–17
2024
-
[16]
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge,
N. Kamoet al., “NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge,” inProc. of CHiME, 2024, pp. 69– 74
2024
-
[17]
BUT/JHU system de- scription for CHiME-8 NOTSOFAR-1 challenge,
A. Polok, D. Klement, J. Han, S. Sedl ´aˇcek, B. Yusuf, M. Ma- ciejewski, M. Wiesner, and L. Burget, “BUT/JHU system de- scription for CHiME-8 NOTSOFAR-1 challenge,” in8th Interna- tional Workshop on Speech Processing in Everyday Environments (CHiME 2024), 2024, pp. 18–22
2024
-
[18]
CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,
S. Watanabeet al., “CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,” in6th Interna- tional Workshop on Speech Processing in Everyday Environments (CHiME 2020), 2020, pp. 1–7
2020
-
[19]
Recent trends in distant conversational speech recognition: A review of CHiME-7 and 8 DASR challenges,
S. Cornellet al., “Recent trends in distant conversational speech recognition: A review of CHiME-7 and 8 DASR challenges,”Computer Speech & Language, vol. 97, p. 101901, 2026. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0885230825001263
2026
-
[20]
The CHiME-8 MMCSG Challenge: Multi- modal conversations in smart glasses,
K. ˇZmol´ıkov´aet al., “The CHiME-8 MMCSG Challenge: Multi- modal conversations in smart glasses,” inProc. of CHiME, 2024, pp. 7–12
2024
-
[21]
Summary of the NOTSOFAR-1 chal- lenge: Highlights and learnings,
I. Abramovski, A. Vinnikov, S. Shaer, N. Kanda, X. Wang, A. Ivry, and E. Krupka, “Summary of the NOTSOFAR-1 chal- lenge: Highlights and learnings,”Computer Speech & Language, vol. 93, p. 101796, 2025
2025
-
[22]
NOTSOFAR-1 challenge: New datasets, baseline, and tasks for distant meeting transcription,
A. Vinnikovet al., “NOTSOFAR-1 challenge: New datasets, baseline, and tasks for distant meeting transcription,” inProc. of Interspeech, 2024, pp. 5003–5007
2024
-
[23]
Seri- alized output training for end-to-end overlapped speech recogni- tion,
N. Kanda, Y . Gaur, X. Wang, Z. Meng, and T. Yoshioka, “Seri- alized output training for end-to-end overlapped speech recogni- tion,” inInterspeech 2020, 2020, pp. 2797–2801
2020
-
[24]
Streaming multi-talker ASR with token-level serialized output training,
N. Kanda, J. Wu, Y . Wu, X. Xiao, Z. Meng, X. Wang, Y . Gaur, Z. Chen, J. Li, and T. Yoshioka, “Streaming multi-talker ASR with token-level serialized output training,” inInterspeech 2022, 2022, pp. 3774–3778
2022
-
[25]
BA-SOT: Boundary-aware serialized output training for multi- talker ASR,
Y . Liang, F. Yu, Y . Li, P. Guo, S. Zhang, Q. Chen, and L. Xie, “BA-SOT: Boundary-aware serialized output training for multi- talker ASR,” inProc. of Interspeech, 2023, pp. 3487–3491
2023
-
[26]
SA-SOT: Speaker- aware serialized output training for multi-talker ASR,
Z. Fan, L. Dong, J. Zhang, L. Lu, and Z. Ma, “SA-SOT: Speaker- aware serialized output training for multi-talker ASR,” inProc. of ICASSP, 2024, pp. 9986–9990
2024
-
[27]
Adapting diarization-conditioned Whisper for end-to-end multi-talker speech recognition,
M. Kocour, M. Karafiat, A. Polok, D. Klement, L. Burget, and J. ˇCernock´y, “Adapting diarization-conditioned Whisper for end-to-end multi-talker speech recognition,” 2025. [Online]. Available: https://arxiv.org/abs/2510.03723
-
[28]
Serialized output prompting for large language model-based multi-talker speech recognition,
H. Shi, Y . Fujita, T. Mizumoto, L. Liu, A. Kojima, and Y . Sudo, “Serialized output prompting for large language model-based multi-talker speech recognition,” 2025. [Online]. Available: https://arxiv.org/abs/2509.04488
-
[29]
An empirical study of catastrophic forgetting in large language mod- els during continual fine-tuning,
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang, “An empirical study of catastrophic forgetting in large language mod- els during continual fine-tuning,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 3776–3786, 2025
2025
-
[30]
Revisiting catastrophic forgetting in large language model tuning,
H. Li, L. Ding, M. Fang, and D. Tao, “Revisiting catastrophic forgetting in large language model tuning,” inFindings of the Association for Computational Linguistics: EMNLP 2024, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 4297–4308. [Online]. Available: https://aclantholo...
2024
-
[31]
Neural target speech extraction: An overview,
K. Zmolikova, M. Delcroix, T. Ochiai, K. Kinoshita, J. ˇCernock´y, and D. Yu, “Neural target speech extraction: An overview,”IEEE Signal Processing Magazine, vol. 40, no. 3, pp. 8–29, 2023
2023
-
[32]
V oiceFilter-Lite: Streaming targeted voice sep- aration for on-device speech recognition,
Q. Wanget al., “V oiceFilter-Lite: Streaming targeted voice sep- aration for on-device speech recognition,” inInterspeech 2020, 2020, pp. 2677–2681
2020
-
[33]
Target-speaker voice activity detection: A novel approach for multi-speaker diarization in a dinner party sce- nario,
I. Medennikovet al., “Target-speaker voice activity detection: A novel approach for multi-speaker diarization in a dinner party sce- nario,” inInterspeech 2020, 2020, pp. 274–278
2020
-
[34]
Adapting self-supervised models to multi-talker speech recognition using speaker embeddings,
Z. Huang, D. Raj, P. Garc ´ıa, and S. Khudanpur, “Adapting self-supervised models to multi-talker speech recognition using speaker embeddings,” inProc. of ICASSP, 2023, pp. 1–5
2023
-
[35]
Extending Whisper with prompt tuning to target-speaker ASR,
H. Ma, Z. Peng, M. Shao, J. Li, and J. Liu, “Extending Whisper with prompt tuning to target-speaker ASR,” in2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 516–12 520
2024
-
[36]
Streaming target-speaker ASR with neural transducer,
T. Moriya, H. Sato, T. Ochiai, M. Delcroix, and T. Shinozaki, “Streaming target-speaker ASR with neural transducer,” inInter- speech 2022, 2022, pp. 2673–2677
2022
-
[37]
Single channel target speaker extraction and recog- nition with speaker beam,
M. Delcroix, K. Zmolikova, K. Kinoshita, A. Ogawa, and T. Nakatani, “Single channel target speaker extraction and recog- nition with speaker beam,” in2018 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5554–5558
2018
-
[38]
Empowering Whisper as a joint multi-talker and target-talker speech recognition system,
L. Meng, J. Kang, Y . Wang, Z. Jin, X. Wu, X. Liu, and H. Meng, “Empowering Whisper as a joint multi-talker and target-talker speech recognition system,” inInterspeech 2024, 2024, pp. 4653– 4657
2024
-
[39]
SQ-Whisper: Speaker-querying based Whisper model for target-speaker ASR,
P. Guo, X. Chang, H. Lv, S. Watanabe, and L. Xie, “SQ-Whisper: Speaker-querying based Whisper model for target-speaker ASR,” arXiv preprint arXiv:2412.05589, 2024
-
[40]
End-to-end joint target and non-target speak- ers ASR,
R. Masumuraet al., “End-to-end joint target and non-target speak- ers ASR,” inInterspeech 2023, 2023, pp. 2903–2907
2023
-
[41]
META-CAT: Speaker-informed speech embeddings via meta information con- catenation for multi-talker ASR,
J. Wang, W. Wang, K. Dhawan, T. Park, M. Kim, I. Medennikov, H. Huang, N. Koluguri, J. Balam, and B. Ginsburg, “META-CAT: Speaker-informed speech embeddings via meta information con- catenation for multi-talker ASR,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2025, pp. 1–5
2025
-
[42]
Speaker targeting via self-speaker adaptation for multi-talker ASR,
W. Wang, T. Park, I. Medennikov, J. Wang, K. Dhawan, H. Huang, N. Rao Koluguri, J. Balam, and B. Ginsburg, “Speaker targeting via self-speaker adaptation for multi-talker ASR,” inProc. of In- terspeech, 2025, pp. 5498–5502
2025
-
[43]
Target speaker ASR with Whisper,
A. Polok, D. Klement, M. Wiesner, S. Khudanpur, J. ˇCernock´y, and L. Burget, “Target speaker ASR with Whisper,” in2025 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2025, pp. 1–5
2025
- [44]
-
[45]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[46]
A. H. L. K. Khandelwalet al., “Ministral 3,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
DiCoW: Diarization-conditioned Whisper for target speaker automatic speech recognition,
A. Polok, D. Klement, M. Kocour, J. Han, F. Landini, B. Yusuf, M. Wiesner, S. Khudanpur, J. ˇCernock´y, and L. Burget, “DiCoW: Diarization-conditioned Whisper for target speaker automatic speech recognition,”Computer Speech & Language, vol. 95, p. 101841, 2026. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S088523082500066X
2026
-
[48]
The AMI meeting corpus,
I. Mccowanet al., “The AMI meeting corpus,”Int’l. Conf. on Methods and Techniques in Behavioral Research, 01 2005
2005
-
[49]
Mixer 6,
L. Brandschain, D. Graff, C. Cieri, K. Walker, C. Caruso, and A. Neely, “Mixer 6,” inProceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), N. C. C. Chair), K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner, and D. Tapias, Eds. Valletta, Malta: European Language Resources Association (ELRA)...
2010
-
[50]
MeetEval: A toolkit for computation of word error rates for meeting transcription systems,
T. v. Neumann, C. B. Boeddeker, M. Delcroix, and R. Haeb- Umbach, “MeetEval: A toolkit for computation of word error rates for meeting transcription systems,” inProceedings of the 7th International Workshop on Speech Processing in Everyday Envi- ronments (CHiME 2023), 2023, pp. 27–32
2023
-
[51]
Gemini 3 flash model card,
Google DeepMind, “Gemini 3 flash model card,” 2025, accessed: 2026-02-25. [Online]. Available: https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf
2025
-
[52]
G. Comaniciet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,” 2025. [Online]. Available: https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
A. H. Liuet al., “V oxtral realtime,” 2026. [Online]. Available: https://arxiv.org/abs/2602.11298
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Fine-tune before structured pruning: Towards compact and accurate self-supervised models for speaker diariza- tion,
J. Han, F. Landini, J. Rohdin, A. Silnova, M. Diez, J. ˇCernock´y, and L. Burget, “Fine-tune before structured pruning: Towards compact and accurate self-supervised models for speaker diariza- tion,” inInterspeech 2025, 2025, pp. 1583–1587
2025
-
[55]
emotion2vec: Self-supervised pre-training for speech emotion representation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion representation,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 747–15 760. [Online]...
2024
-
[56]
Rouge: A package for automatic evaluation of sum- maries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of sum- maries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[57]
SE-DiCoW: Self-enrolled diarization-conditioned Whisper,
A. Polok, D. Klement, S. Cornell, M. Wiesner, J. ˇCernock´y, S. Khudanpur, and L. Burget, “SE-DiCoW: Self-enrolled diarization-conditioned Whisper,” inICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.