Learning Dynamics of Chain-of-Thought State Tracking in a Solvable Transformer Model
Pith reviewed 2026-06-26 21:47 UTC · model grok-4.3
The pith
Mean-field dynamics for three order parameters track how attention retrieval and MLP logic co-develop during chain-of-thought training on permutation states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
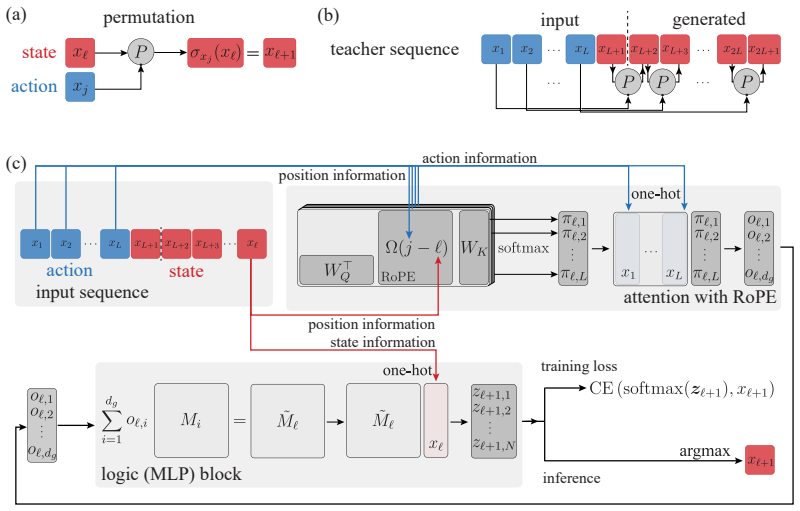
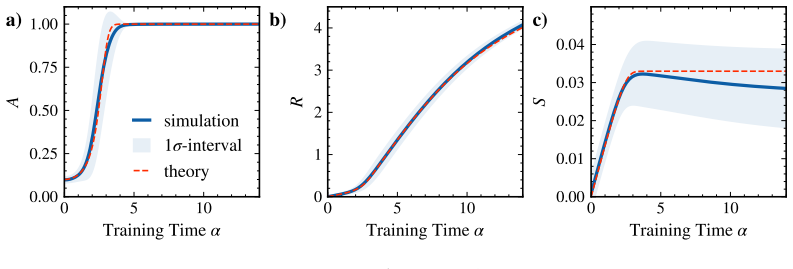
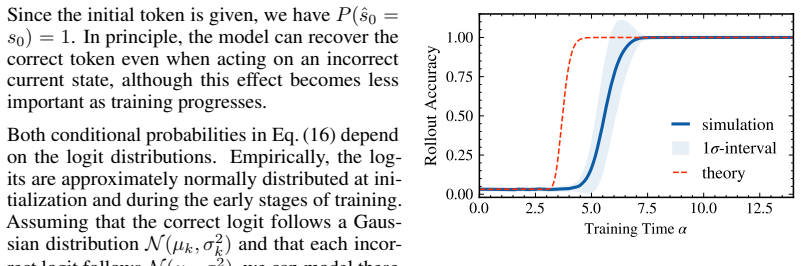
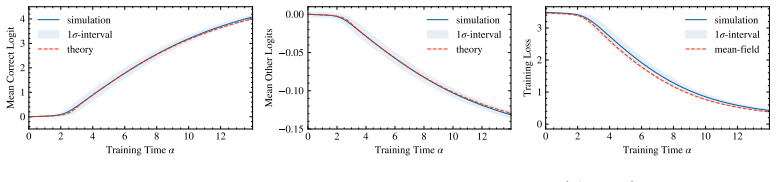
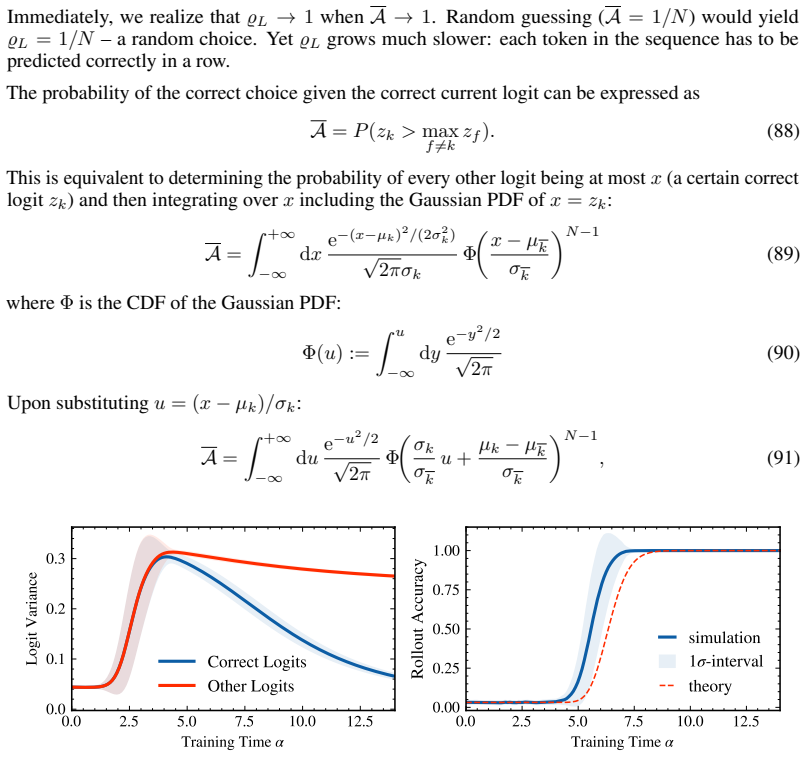
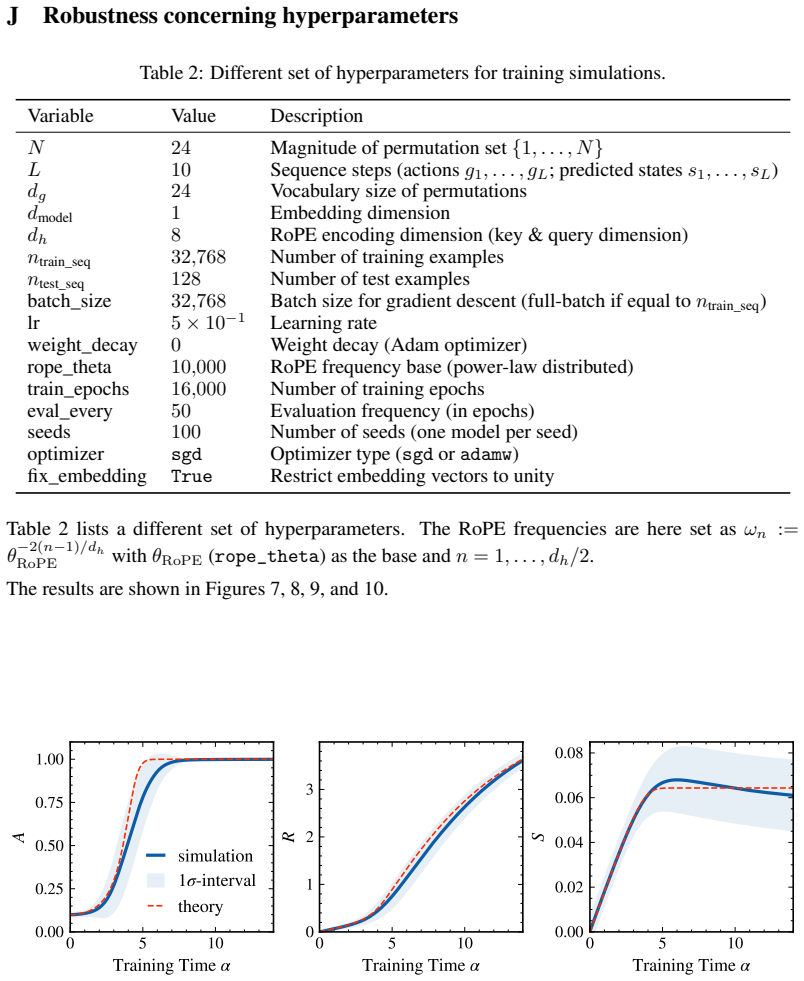
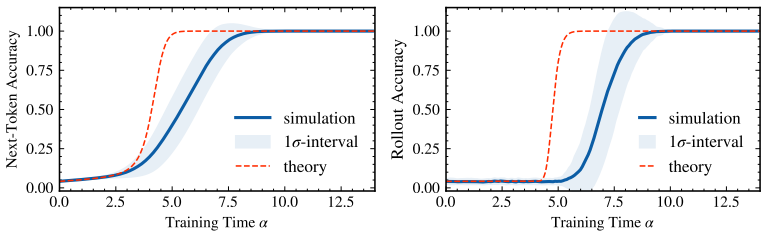
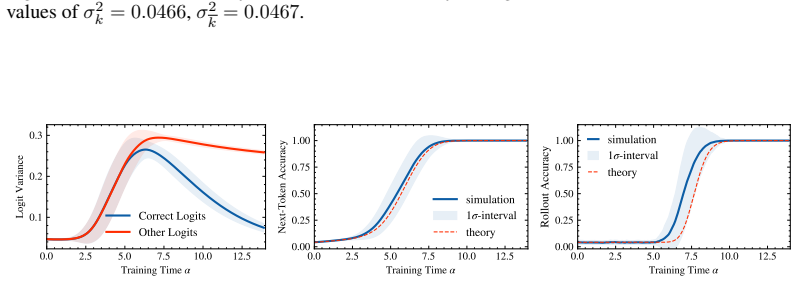
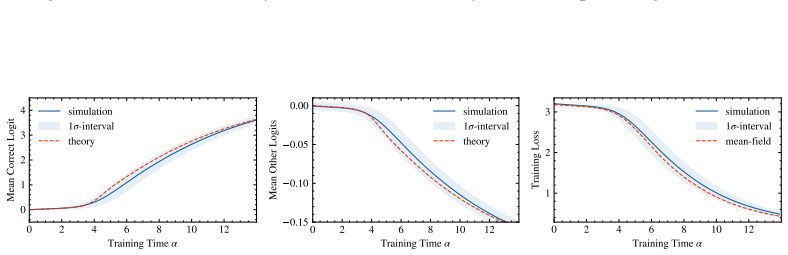
In the solvable architecture that cleanly separates fixed-lag action retrieval (via RoPE attention) from a specialized MLP that applies the retrieved permutation, statistical-physics mean-field theory yields deterministic dynamics for three order parameters. The equations match numerical simulations quantitatively for the order parameters themselves and qualitatively predict the abrupt rise in final accuracy once retrieval and alignment cross a threshold.
What carries the argument
The mean-field closure for the three order parameters (attention retrieval, teacher-matrix alignment, off-target logic overlap) obtained by exploiting the architectural separation between attention-based retrieval and MLP-based logic application.
If this is right
- The three order parameters obey deterministic dynamics whose solutions reproduce the simulated time courses.
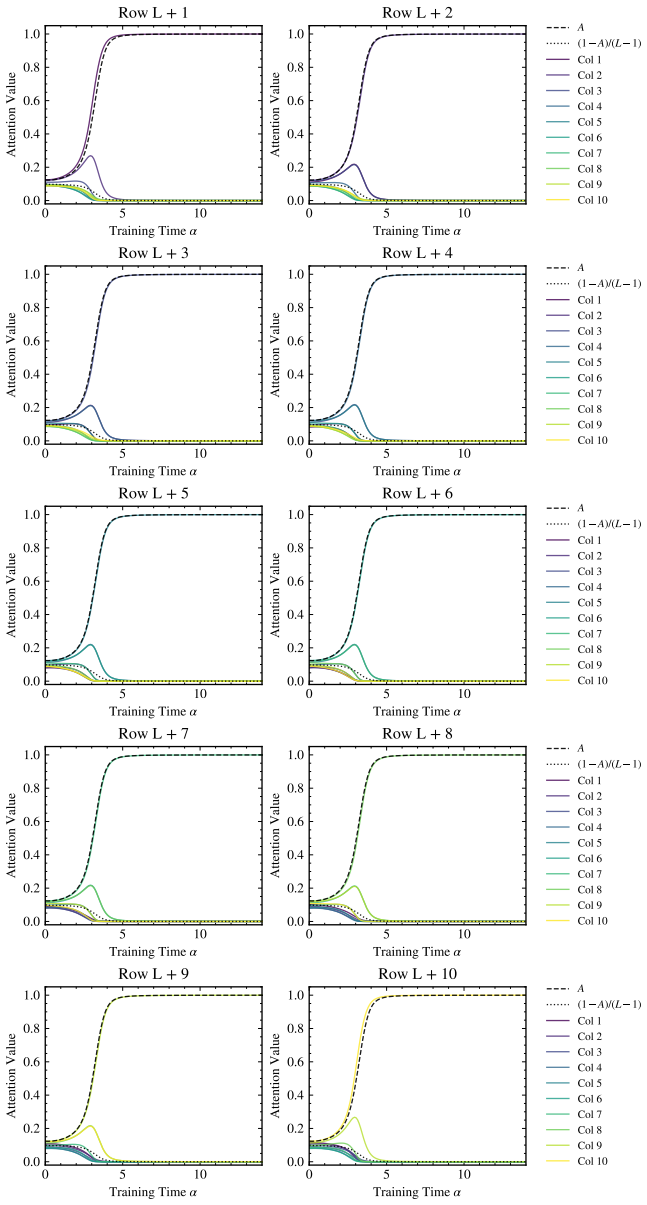
- Logic-module alignment occurs in two stages: an early mixed-heuristic phase followed by a later phase enabled by sharpened attention retrieval.
- A simple logit-distribution approximation derived from the order parameters locates the location of the sharp accuracy transition.
- Quantitative agreement holds for the order parameters while the accuracy prediction remains qualitative.
Where Pith is reading between the lines
- The same staged-learning sequence may appear in other chain-of-thought tasks whose architecture maintains a modular separation between retrieval and computation.
- If the separation assumption is relaxed, the mean-field closure would require additional order parameters that track cross-module interference.
- The sharp transition in rollout accuracy suggests the existence of a critical surface in hyperparameter space separating regimes of successful and unsuccessful multi-step tracking.
Load-bearing premise
The architecture cleanly separates fixed-lag action retrieval learned by attention from the MLP module that applies the retrieved permutation, allowing the mean-field equations to close.
What would settle it
A numerical simulation in which the measured trajectories of attention retrieval accuracy, teacher alignment, or off-target overlap deviate persistently from the derived mean-field ODEs would falsify the description.
Figures
read the original abstract
Chain-of-thought generation can turn a multi-step computation into a sequence of locally checkable state updates, but the training dynamics by which transformers acquire such updates remain poorly understood. We study this question in a solvable setting: a simplified one-block transformer trained by supervised next-token prediction on state sequences generated by composing permutations. The architecture separates fixed-lag action retrieval, learned by RoPE attention, from a specialized MLP logic module that applies the retrieved permutation to the current state. Using a statistical-physics mean-field description, we derive dynamics for three order parameters measuring attention retrieval, teacher-matrix alignment, and off-target logic overlap. These equations quantitatively match simulations for the order parameters and, combined with a logit-distribution approximation, qualitatively predict the sharp transition in final rollout accuracy. The analysis reveals staged learning: the logic module first learns a mixed heuristic; attention then locks onto the relevant action, enabling efficient MLP alignment. Together, these results provide a controlled mechanistic account of how attention-based retrieval and MLP-based logic co-develop during chain-of-thought state tracking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies chain-of-thought state tracking in a simplified one-block transformer trained by next-token prediction on sequences generated by composing permutations. The architecture explicitly separates fixed-lag action retrieval (via RoPE attention) from an MLP logic module that applies the retrieved permutation. A statistical-physics mean-field theory is used to derive closed dynamics for three order parameters (attention retrieval, teacher-matrix alignment, off-target logic overlap). These equations are reported to match simulations quantitatively; combined with a logit-distribution approximation they qualitatively predict the sharp transition in final rollout accuracy. The analysis identifies a staged learning process in which the logic module first acquires a mixed heuristic before attention locks onto the relevant action.
Significance. If the reported quantitative agreement between the derived mean-field equations and independent simulations holds, the work supplies a rare controlled mechanistic account of how attention-based retrieval and MLP-based logic co-develop during training. The explicit architectural separation enables closure of the mean-field equations without hidden correlations, and the staged-learning prediction is falsifiable against the simulations. Credit is due for the direct numerical validation of the order-parameter trajectories and for the logit approximation that links the microscopic dynamics to the macroscopic accuracy transition.
minor comments (3)
- §2 (model definition): the precise form of the RoPE attention kernel and the MLP weight initialization are not stated explicitly; adding these would allow readers to reproduce the mean-field closure without ambiguity.
- Figure 3 caption: the shaded regions around the simulated order-parameter curves are described only as 'standard deviation'; clarifying whether they represent one or two standard errors and over how many independent runs would improve interpretability of the quantitative match.
- Eq. (12) (logit-distribution approximation): the Gaussian assumption for the logit distribution is introduced without a supporting derivation or reference to prior work on similar approximations in attention models; a brief justification would strengthen the qualitative prediction of the accuracy transition.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment of our manuscript on the learning dynamics of chain-of-thought state tracking. The recommendation for minor revision is noted. No specific major comments were provided in the report, so we have no points requiring point-by-point response or manuscript changes at this stage.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper presents a mean-field derivation of order-parameter dynamics directly from the explicit architectural separation (RoPE attention for retrieval, MLP for logic) and statistical-physics assumptions in a deliberately simplified solvable model. These equations are then compared to independent numerical simulations for quantitative match on the order parameters and qualitative prediction of the accuracy transition. No self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work appear in the abstract or description; the closure relies on the model's built-in design rather than reducing the target result to its own inputs by construction. This is the standard case of an internally consistent controlled analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mean-field approximation closes the dynamics of the three order parameters without higher-order correlations
- domain assumption The transformer architecture cleanly separates fixed-lag RoPE attention retrieval from the MLP logic module
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Xlnet: Generalized autoregressive pretraining for language understanding.Advances in neural information processing systems, 32, 2019
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding.Advances in neural information processing systems, 32, 2019
2019
-
[3]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[4]
Bloom: A 176b-parameter open-access multilingual language model
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ili ´c, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176b-parameter open-access multilingual language model. 2023
2023
-
[5]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. Technical report, July 2019. arXiv:1907.11692 [cs] type: article
Pith/arXiv arXiv 2019
-
[6]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[7]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[8]
Transformers learn in-context by gradient descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning, pages 35151–35174. PMLR, 2023
2023
-
[9]
Stephanie CY Chan, Ishita Dasgupta, Junkyung Kim, Dharshan Kumaran, Andrew K Lampinen, and Felix Hill. Transformers generalize differently from information stored in context vs in weights.arXiv preprint arXiv:2210.05675, 2022
arXiv 2022
-
[10]
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression.Advances in neural information processing systems, 36:14228–14246, 2023
Allan Raventós, Mansheej Paul, Feng Chen, and Surya Ganguli. Pretraining task diversity and the emergence of non-bayesian in-context learning for regression.Advances in neural information processing systems, 36:14228–14246, 2023
2023
-
[11]
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177, 2022
Pith/arXiv arXiv 2022
-
[12]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[13]
https://transformer-circuits.pub/2021/framework/index.html. 10
2021
-
[14]
Interpreting context look-ups in transformers: Investigating attention-mlp interactions
Clement Neo, Shay B Cohen, and Fazl Barez. Interpreting context look-ups in transformers: Investigating attention-mlp interactions. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16681–16697, 2024
2024
-
[15]
Reddi, and Sanjiv Kumar
Chulhee Yun, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank J. Reddi, and Sanjiv Kumar. Are transformers universal approximators of sequence-to-sequence functions? InInternational Conference on Learning Representations, 2020
2020
-
[16]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[17]
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small.arXiv preprint arXiv:2211.00593, 2022
Pith/arXiv arXiv 2022
-
[18]
In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Pith/arXiv arXiv 2022
-
[19]
Mechanistic interpretability for ai safety–a review
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024
Pith/arXiv arXiv 2024
-
[20]
Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496, 2025
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496, 2025
Pith/arXiv arXiv 2025
-
[21]
A toy model of universality: Reverse engineering how networks learn group operations
Bilal Chughtai, Lawrence Chan, and Neel Nanda. A toy model of universality: Reverse engineering how networks learn group operations. InInternational Conference on Machine Learning, pages 6243–6267. PMLR, 2023
2023
-
[22]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
-
[23]
Yu Huang, Zixin Wen, Aarti Singh, Yuejie Chi, and Yuxin Chen. Transformers provably learn chain-of-thought reasoning with length generalization.arXiv preprint arXiv:2511.07378, 2025
arXiv 2025
-
[24]
Giovanni Luca Marchetti, Daniel Kunin, Adele Myers, Francisco Acosta, and Nina Miolane. Sequential group composition: A window into the mechanics of deep learning.arXiv preprint arXiv:2602.03655, 2026
Pith/arXiv arXiv 2026
-
[25]
Augmenting self-attention with persistent memory.arXiv preprint arXiv:1907.01470, 2019
Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. Augmenting self-attention with persistent memory.arXiv preprint arXiv:1907.01470, 2019
Pith/arXiv arXiv 1907
-
[26]
Dynamical mean-field theory of self-attention neural networks.arXiv preprint arXiv:2406.07247, 2024
Ángel Poc-López and Miguel Aguilera. Dynamical mean-field theory of self-attention neural networks.arXiv preprint arXiv:2406.07247, 2024
arXiv 2024
-
[27]
Metastable states in asymmetrically diluted hopfield networks.Journal of Physics A: Mathematical and General, 21(14):3155–3169, 1988
Alessandro Treves and Daniel J Amit. Metastable states in asymmetrically diluted hopfield networks.Journal of Physics A: Mathematical and General, 21(14):3155–3169, 1988
1988
-
[28]
A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
Alexander Maloney, Daniel A Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
arXiv 2022
-
[29]
Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
Yue M Lu, Mary Letey, Jacob A Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymp- totic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
2025
-
[30]
Training dynamics of transformers to recognize word co-occurrence via gradient flow analysis
Hongru Yang, Bhavya Kailkhura, Zhangyang Wang, and Yingbin Liang. Training dynamics of transformers to recognize word co-occurrence via gradient flow analysis. 2024. URL https://openreview.net/forum?id=w6q46IslSR
2024
-
[31]
From condensation to rank collapse: A two-stage analysis of trans- former training dynamics
Zheng-An Chen and Tao Luo. From condensation to rank collapse: A two-stage analysis of trans- former training dynamics. 2026. URL https://openreview.net/forum?id=gm5mkiTGOy. 11
2026
-
[32]
How transformers get rich: Approximation and dynamics analysis.arXiv preprint arXiv:2410.11474, 2025
Mingze Wang, Ruoxi Yu, Weinan E, and Lei Wu. How transformers get rich: Approximation and dynamics analysis.arXiv preprint arXiv:2410.11474, 2025
arXiv 2025
-
[33]
JoMA: Demystifying multilayer transformers via joint dynamics of MLP and attention
Yuandong Tian, Yiping Wang, Zhenyu Zhang, Beidi Chen, and Simon Shaolei Du. JoMA: Demystifying multilayer transformers via joint dynamics of MLP and attention. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=LbJqRGNYCf
2024
-
[34]
Distributional associations vs in-context reasoning: A study of feed-forward and attention layers
Lei Chen, Joan Bruna, and Alberto Bietti. Distributional associations vs in-context reasoning: A study of feed-forward and attention layers. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=WCVMqRHWW5
2025
-
[35]
Time course MechInterp: Analyzing the evolution of components and knowledge in large language models
Ahmad Dawar Hakimi, Ali Modarressi, Philipp Wicke, and Hinrich Schuetze. Time course MechInterp: Analyzing the evolution of components and knowledge in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025. Association for Computa-...
2025
-
[36]
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021
Pith/arXiv arXiv 2021
-
[37]
Can language models learn from explanations in context? InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 537–563, 2022
Andrew Lampinen, Ishita Dasgupta, Stephanie Chan, Kory Mathewson, Mh Tessler, Antonia Creswell, James McClelland, Jane Wang, and Felix Hill. Can language models learn from explanations in context? InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 537–563, 2022
2022
-
[38]
Star: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 15476–15488. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/ 2022/file/63...
2022
-
[39]
Why think step by step? reasoning emerges from the locality of experience.Advances in Neural Information Processing Systems, 36: 70926–70947, 2023
Ben Prystawski, Michael Li, and Noah Goodman. Why think step by step? reasoning emerges from the locality of experience.Advances in Neural Information Processing Systems, 36: 70926–70947, 2023
2023
-
[40]
Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749, 2022
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749, 2022
arXiv 2022
-
[41]
Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757–70798, 2023
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757–70798, 2023
2023
-
[42]
How does chain of thought decompose complex tasks?arXiv preprint arXiv:2604.08872, 2026
Amrut Nadgir, Vijay Balasubramanian, and Pratik Chaudhari. How does chain of thought decompose complex tasks?arXiv preprint arXiv:2604.08872, 2026
Pith/arXiv arXiv 2026
-
[43]
Chain of thought empowers transformers to solve inherently serial problems
Zhiyuan Li, Hong Liu, Denny Zhou, and Tengyu Ma. Chain of thought empowers transformers to solve inherently serial problems. InInternational Conference on Learning Representations, 2024
2024
-
[44]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[45]
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 1, learning hierarchical language structures.arXiv preprint arXiv:2305.13673, 2025
arXiv 2025
-
[46]
Springer- Verlag, Berlin / New York, 2 edition, 1993
Ernst Hairer, Syvert Paul Nørsett, and Gerhard Wanner.Solving Ordinary Differential Equations I: Nonstiff Problems, volume 8 ofSpringer Series in Computational Mathematics. Springer- Verlag, Berlin / New York, 2 edition, 1993. 12 A Hyperparameters Table 1: Hyperparameters for the training simulations. Variable Value Description N32Magnitude of permutation...
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.