How Well Do Large Language Models Capture Human Personality?
Pith reviewed 2026-06-30 22:18 UTC · model grok-4.3
The pith
Richer persona descriptions cause LLMs to contract rather than expand the diversity of simulated human behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
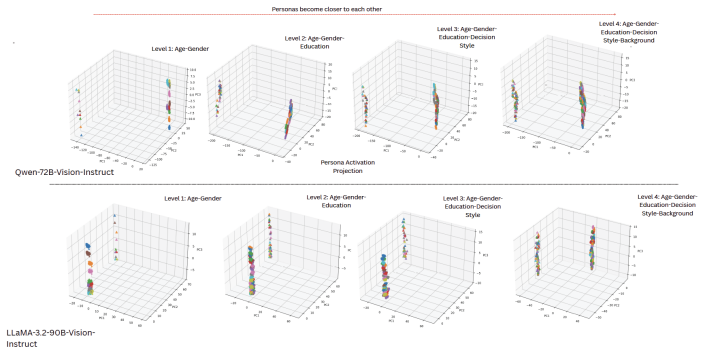
The authors identify persona manifold collapse, in which increasingly expressive persona specifications lead to systematic contraction of representational and behavioral diversity. Across models, increasing persona complexity consistently reduces inter-persona separation in latent space and weakens behavioral differentiation in downstream simulation tasks. These effects persist across analyses as richer personas fail to preserve human subgroup disagreement, performance varies across attribute combinations of similar size, and adding descriptive detail often degrades rather than improves simulation fidelity. Simple Age-Gender personas consistently outperform richly specified Ideal Customer Pr
What carries the argument
Persona manifold collapse, the contraction of inter-persona separation in latent space and behavioral differentiation as persona specifications grow more expressive.
If this is right
- Increasing persona complexity reduces inter-persona separation in latent space across architectures.
- Behavioral differentiation weakens in downstream simulation tasks as persona detail grows.
- Simple Age-Gender personas achieve substantially higher downstream prediction accuracy than complex Ideal Customer Profiles.
- Collapse is not uniform; some attribute combinations remain stable and form localized alignment bridges.
- Rich personas often fail to preserve human subgroup disagreement patterns.
Where Pith is reading between the lines
- Persona construction for population simulation may benefit from prioritizing stable attribute sets over maximum expressivity.
- Applications that rely on diverse human-like outputs, such as market modeling or policy testing, need to measure actual behavioral spread rather than prompt richness alone.
- Alternative methods for injecting variation, such as post-hoc sampling or architecture-level controls, could be tested against the observed collapse pattern.
Load-bearing premise
The chosen simulation tasks and human response benchmarks serve as valid proxies for real human subgroup disagreement and behavioral variation.
What would settle it
A replication in which richer persona prompts produce measurably greater inter-persona separation in latent space and stronger behavioral differentiation on the same or new downstream tasks.
Figures
read the original abstract
Large language models (LLMs) are increasingly used to simulate human populations via persona prompting, often under the assumptions that richer persona descriptions improve behavioral fidelity, similarly sized attribute combinations are equally simulatable, and persona definitions generalize across tasks. In this work, we formalize these assumptions and systematically evaluate them across multiple architectures, scales, and simulation settings. We identify a fundamental limitation we term persona manifold collapse, where increasingly expressive persona specifications lead to systematic contraction of representational and behavioral diversity. Across models, increasing persona complexity consistently reduces inter-persona separation in latent space and weakens behavioral differentiation in downstream simulation tasks. These effects persist across multiple analyses as richer personas fail to preserve human subgroup disagreement, performance varies across attribute combinations of similar size, and adding descriptive detail often degrades rather than improves simulation fidelity. Surprisingly, simple Age-Gender personas consistently outperform richly specified Ideal Customer Profiles (ICPs) across industries, achieving substantially higher downstream prediction accuracy. We find that collapse is not uniform across attributes. Certain combinations remain behaviorally stable and preserve stronger alignment with human responses, forming localized regions we term alignment bridges. Together, our results provide empirical and conceptual foundations for understanding the limits of persona-conditioned simulation, highlighting the need for representation-aware persona construction rather than increasing persona expressivity alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs used for persona-prompted simulation of human populations exhibit 'persona manifold collapse,' in which increasingly expressive persona specifications systematically contract representational diversity (reduced inter-persona separation in latent space) and behavioral diversity (weakened differentiation on downstream tasks). It reports that richer personas fail to preserve human subgroup disagreement, that performance varies across similarly sized attribute combinations, that adding detail often degrades fidelity, and that simple Age-Gender personas outperform complex Ideal Customer Profiles (ICPs) on downstream prediction accuracy. The work identifies localized 'alignment bridges' where certain attribute combinations remain stable and better aligned with human responses, based on evaluations across architectures, scales, and simulation settings.
Significance. If the central empirical patterns hold after validation of the measurement tasks, the result would be significant for the rapidly growing practice of using LLMs to simulate human populations in social science, marketing, and policy contexts. It supplies concrete evidence against the common assumption that richer persona descriptions monotonically improve fidelity and supplies an empirical basis for preferring representation-aware rather than maximally expressive persona construction. The cross-model consistency and the identification of non-uniform collapse (alignment bridges) are strengths that could guide future work.
major comments (2)
- [Abstract, paragraph on evaluation across simulation settings] Abstract, paragraph on evaluation across simulation settings: the claim that richer personas 'fail to preserve human subgroup disagreement' and that Age-Gender outperforms ICPs on downstream prediction accuracy is load-bearing for the collapse conclusion, yet the manuscript supplies no evidence that the chosen simulation tasks or human-response benchmarks were validated against external population data or known axes of real subgroup variation rather than selected for convenience or model-internal properties. Without such validation, the observed contraction could be an artifact of the measurement instruments.
- [Methods description (systematic evaluation across architectures, scales, and simulation settings)] Methods description (systematic evaluation across architectures, scales, and simulation settings): the abstract states that the evaluation is systematic, but the manuscript lacks explicit reporting of data exclusion rules, pre-registered analysis plans, or statistical controls for multiple comparisons and post-hoc task selection. These omissions prevent assessment of whether the reported collapse is robust or sensitive to analytic choices.
minor comments (2)
- The newly introduced terms 'persona manifold collapse' and 'alignment bridges' are used throughout without a concise formal definition or operationalization that could be reproduced from the text alone; a short definitional paragraph or boxed equation would improve clarity.
- Figure captions for latent-space visualizations should explicitly state the dimensionality reduction method, distance metric, and number of personas plotted so readers can assess the separation claims without consulting the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The points regarding validation of benchmarks and methodological transparency are substantive and we address them directly below with planned revisions.
read point-by-point responses
-
Referee: [Abstract, paragraph on evaluation across simulation settings] Abstract, paragraph on evaluation across simulation settings: the claim that richer personas 'fail to preserve human subgroup disagreement' and that Age-Gender outperforms ICPs on downstream prediction accuracy is load-bearing for the collapse conclusion, yet the manuscript supplies no evidence that the chosen simulation tasks or human-response benchmarks were validated against external population data or known axes of real subgroup variation rather than selected for convenience or model-internal properties. Without such validation, the observed contraction could be an artifact of the measurement instruments.
Authors: We agree that stronger grounding of the benchmarks would improve the manuscript. The human-response data are drawn from established public sources (e.g., General Social Survey items and published consumer panels) that prior literature has linked to documented demographic axes. In revision we will add a dedicated Methods subsection describing these sources, their documented subgroup variation, and explicit limitations on external population validation. We will also discuss task selection criteria to reduce concerns about convenience sampling. revision: yes
-
Referee: [Methods description (systematic evaluation across architectures, scales, and simulation settings)] Methods description (systematic evaluation across architectures, scales, and simulation settings): the abstract states that the evaluation is systematic, but the manuscript lacks explicit reporting of data exclusion rules, pre-registered analysis plans, or statistical controls for multiple comparisons and post-hoc task selection. These omissions prevent assessment of whether the reported collapse is robust or sensitive to analytic choices.
Authors: We accept that greater transparency is required. The revised manuscript will include an explicit subsection on analysis procedures that reports all data exclusion rules applied, describes the statistical controls and multiple-comparison adjustments used, and clarifies the a-priori rationale for task selection. Because the study was not pre-registered, we will state this fact directly while providing the full analysis code and sensitivity checks. revision: partial
Circularity Check
No circularity: purely empirical measurements against external human benchmarks
full rationale
The paper reports empirical observations of LLM outputs under varying persona specifications, measuring inter-persona separation in latent space and behavioral differentiation on downstream tasks against human response benchmarks. No equations, fitted parameters, or derivations are defined such that any reported quantity (e.g., collapse) reduces by construction to an input fitted from the same data. The central claims rest on comparisons to independent human data rather than self-referential definitions or self-citation chains. This is the standard case of a measurement study whose results remain falsifiable outside the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be used to simulate human populations via persona prompting
invented entities (2)
-
persona manifold collapse
no independent evidence
-
alignment bridges
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aher, Rosa I
Gati V . Aher, Rosa I. Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pages 337–371. PMLR, 2023. URLhttps://proceedings.mlr.press/v202/aher23a.html
2023
-
[2]
Argyle, Ethan C
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351,
-
[3]
doi: 10.1017/pan.2023.2
-
[4]
The moral machine experiment.Nature, 563(7729):59–64, 2018
Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean- François Bonnefon, and Iyad Rahwan. The moral machine experiment.Nature, 563(7729):59–64, 2018. doi: 10.1038/s41586-018-0637-6
-
[5]
Aanisha Bhattacharyya, Susmit Agrawal, Yaman Kumar Singla, Tarun Ram Menta, Nikitha Sr, Rajiv Ratn Shah, Changyou Chen, and Balaji Krishnamurthy. Alpha: Action-based learning for pluralistic human alignment in large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 40 (44):37249–37258, Mar. 2026. doi: 10.1609/aaai.v40i44.41056...
-
[6]
Social agents: Collective intelligence improves llm predictions
Aanisha Bhattacharyya, Abhilekh Borah, Yaman Kumar Singla, Rajiv Ratn Shah, Changyou Chen, and Balaji Krishnamurthy. Social agents: Collective intelligence improves llm predictions. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=73J3hsato3
2026
-
[7]
Nicolas Bougie and Narimasa Watanabe. SimUSER: Simulating user behavior with large language models for recommender system evaluation.arXiv preprint arXiv:2504.12722, 2025
-
[8]
Using LLMs for market research
James Brand, Ayelet Israeli, and Donald Ngwe. Using LLMs for market research. InProceedings of the 25th ACM Conference on Economics and Computation (EC). ACM, 2024. doi: 10.1145/3670865.3673479. Also: Harvard Business School Working Paper 23-062
-
[9]
Personas with attitudes: Controlling LLMs for diverse data annotation
Leon Fröhling, Gianluca Demartini, and Dennis Assenmacher. Personas with attitudes: Controlling LLMs for diverse data annotation. In Agostina Calabrese, Christine de Kock, Debora Nozza, Flor Miriam Plaza- del Arco, Zeerak Talat, and Francielle Vargas, editors,Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH), pages 468–481, Vienna, Aust...
2025
-
[10]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas, 2025. URLhttps://arxiv.org/abs/2406.20094
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Evaluating large language models in generating synthetic HCI research data: A case study
Perttu Hämäläinen, Mikke Tavast, and Anton Kunnari. Evaluating large language models in generating synthetic HCI research data: A case study. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI). ACM, 2023. doi: 10.1145/3544548.3580688
-
[12]
Predicting results of social science experiments using large language models, 2024
Luke Hewitt, Ashwini Ashokkumar, Isaias Ghezae, and Robb Willer. Predicting results of social science experiments using large language models, 2024. Accessed: 2024
2024
-
[13]
John J. Horton, Apostolos Filippas, and Benjamin S. Manning. Large language models as simulated economic agents: What can we learn from Homo Silicus? InProceedings of the 25th ACM Conference on Economics and Computation (EC). ACM, 2024. doi: 10.1145/3670865.3673513. Also: NBER Working Paper No. 31122
-
[14]
Carolin Kaiser, Jakob Kaiser, Vladimir Manewitsch, Lea Rau, and Rene Schallner. Simulating human opinions with large language models: Opportunities and challenges for personalized survey data modeling. InAdjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, 10 UMAP Adjunct ’25, page 82–86, New York, NY , USA, 202...
-
[15]
Large content and behavior models to understand, simulate, and optimize con- tent and behavior
Ashmit Khandelwal, Aditya Agrawal, Aanisha Bhattacharyya, Yaman Kumar, Somesh Singh, Ut- taran Bhattacharya, Ishita Dasgupta, Stefano Petrangeli, Rajiv Ratn Shah, Changyou Chen, and Bal- aji Krishnamurthy. Large content and behavior models to understand, simulate, and optimize con- tent and behavior. InThe Twelfth International Conference on Learning Repr...
2024
- [16]
-
[17]
Leo Yeykelis Li, Benjamin Kaveladze, Byron Reeves, and Thomas N. Robinson. Using large language models to create AI personas for replication, generalization and prediction of media effects: An empirical test of 133 published experimental research findings.arXiv preprint arXiv:2408.16073, 2024
-
[18]
Agent a/b: Automated and scalable a/b testing on live websites with interactive llm agents
Yuxuan Lu, Ting-Yao Hsu, Hansu Gu, Limeng Cui, Yaochen Xie, III Headden, William P., Bingsheng Yao, Akash Veeragouni, Jiapeng Liu, Sreyashi Nag, Jessie Wang, and Dakuo Wang. Agent a/b: Automated and scalable a/b testing on live websites with interactive llm agents. InProceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Comp...
2026
-
[19]
Association for Computing Machinery. ISBN 9798400722813. doi: 10.1145/3772363.3799039. URLhttps://doi.org/10.1145/3772363.3799039
-
[20]
PUB: An LLM-enhanced personality-driven user behaviour simulator for recommender system evaluation
Chenglong Ma, Ziqi Xu, Yongli Ren, Danula Hettiachchi, and Jeffrey Chan. PUB: An LLM-enhanced personality-driven user behaviour simulator for recommender system evaluation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR),
-
[21]
doi: 10.1145/3726302.3730238
-
[22]
Manning, Kehang Zhu, and John J
Benjamin S. Manning, Kehang Zhu, and John J. Horton. Automated social science: Language models as scientist and subjects. NBER Working Paper 32381, National Bureau of Economic Research, 2024
2024
-
[23]
Elyas Meguellati, Lei Han, Abraham Bernstein, Shazia Sadiq, and Gianluca Demartini. How good are llms in generating personalized advertisements? InCompanion Proceedings of the ACM Web Conference 2024, WWW ’24, page 826–829, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400701726. doi: 10.1145/3589335.3651520. URL https://doi.org/...
-
[24]
Suhong Moon, Marwa Abdulhai, Minwoo Kang, Joseph Suh, Widyadewi Soedarmadji, Eran Kohen Behar, and David M. Chan. Virtual personas for language models via an anthology of backstories.arXiv preprint arXiv:2407.06576, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Nemotron-personas: Synthetic personas aligned to real-world demographic distributions, 2025
NVIDIA. Nemotron-personas: Synthetic personas aligned to real-world demographic distributions, 2025. URLhttps://huggingface.co/blog/nvidia/nemotron-personas
2025
-
[26]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Quantifying visual preferences around the world
Katharina Reinecke and Krzysztof Z Gajos. Quantifying visual preferences around the world. InProceed- ings of the SIGCHI conference on human factors in computing systems, pages 11–20, 2014
2014
-
[28]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect? In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machi...
2023
-
[29]
Postermate: Audience-driven collaborative persona agents for poster design
Donghoon Shin, Daniel Lee, Gary Hsieh, and Gromit Yeuk-Yin Chan. Postermate: Audience-driven collaborative persona agents for poster design. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, UIST ’25, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400720376. doi: 10.1145/3746059.3747769. URL...
-
[30]
Deeppersona: A generative engine for scaling deep synthetic personas, 2025
Zhen Wang, Yufan Zhou, Zhongyan Luo, Lyumanshan Ye, Adam Wood, Man Yao, Saab Mansour, and Luoshang Pan. Deeppersona: A generative engine for scaling deep synthetic personas, 2025. URL https://arxiv.org/abs/2511.07338. 11 A Appendix A.1 Experimental Results Across three complementary experimental settings, we consistently observe strong evidence of persona...
-
[31]
Describe it in detail: visuals, message, and how it made you feel
Think about the last advertisement you can clearly remember. Describe it in detail: visuals, message, and how it made you feel
-
[32]
When was the last time you clicked on an online ad? What was the ad for and why did you click?
-
[33]
What made it memorable?
Describe the most memorable TV or streaming ad you have seen recently. What made it memorable?
-
[34]
Which brands’ ads do you actively follow on social media? Why those brands?
-
[35]
Which elements created that trust?
Describe a website whose design instantly made you trust it. Which elements created that trust?
-
[36]
Which elements pushed you away?
Describe a website whose design made you distrust it. Which elements pushed you away?
-
[37]
How did you react?
Tell me about the last product recommendation widget you noticed while shopping. How did you react?
-
[38]
When you remember an ad, do you recall the brand, the creative, or the tagline first? Give an example
-
[39]
Why did you share it?
Describe a time you shared an ad with friends. Why did you share it?
-
[40]
Do you prefer ads that are funny, informative, or practical? Give a recent example for each
-
[41]
How do you judge whether an online ad feels credible or spammy?
-
[42]
What makes an in-app ad feel safe to interact with versus risky to interact with?
-
[43]
What went wrong?
Describe a landing page you visited after clicking an ad that disappointed you. What went wrong?
-
[44]
When you evaluate a product page, which matters most: images, reviews, specs, or price? Give an example
-
[45]
How did you realize it was sponsored?
Describe the last native article or sponsored post you read. How did you realize it was sponsored?
-
[46]
How do personalized ads based on your browsing history make you feel? Describe a recent reaction
-
[47]
If a brand you liked ran an ad you disliked, how would that change your view of the brand?
-
[48]
How often do you notice or remember a jingle or music from an ad? Describe one you still recall
-
[49]
What triggered you to look it up?
Describe an ad that made you research a brand further. What triggered you to look it up?
-
[50]
When comparing two similar products online, how much does ad exposure affect your choice? Give an example
-
[51]
Which call to action in ads do you respond to most: buy now, learn more, sign up, or other? Why?
-
[52]
Describe how you decide whether to install an app after seeing an app install ad
-
[53]
How do influencer endorsements affect your trust in a product? Describe a case where it changed your mind
-
[54]
What language or visuals made it feel that way?
Describe an ad that felt manipulative. What language or visuals made it feel that way?
-
[55]
What ad formats annoy you most and cause you to close the tab or app? Why?
-
[56]
Describe a brand whose advertising you actively avoid and why
-
[57]
How do social values like sustainability or diversity affect whether you remember or like an ad?
-
[58]
What detail stuck with you?
Describe a time an in-store ad or shelf display influenced your purchase. What detail stuck with you?
-
[59]
How reliably can you recall where you first saw an ad: TV , social, billboard, or elsewhere?
-
[60]
When you see retargeted ads after visiting a site, how does that make you feel and act?
-
[61]
How did you find and use it?
Describe the last promotional code you used that came from an ad. How did you find and use it?
-
[62]
What UX elements on checkout pages cause you to abandon a cart? Give a recent example
-
[63]
What cues convinced you?
Describe a mobile ad that led you to install an app. What cues convinced you?
-
[64]
How much does representation of social groups in an ad influence your perception of the brand?
-
[65]
What convinced you? Table 14: Question set used for persona elicitation and behavioral profiling across advertising perception, trust formation, and decision-making dimensions
Describe an ad that changed your behavior, such as buying or signing up. What convinced you? Table 14: Question set used for persona elicitation and behavioral profiling across advertising perception, trust formation, and decision-making dimensions. 23 Questions
-
[66]
How do you judge the trustworthiness of customer reviews shown on product pages?
-
[67]
When an ad claims a limited-time offer, how likely are you to act quickly? Why or why not?
-
[68]
What signaled that?
Describe a time you felt an ad respected your privacy. What signaled that?
-
[69]
What makes an ad feel authentic versus staged or scripted?
-
[70]
How often do you notice ad frequency and what frequency becomes irritating?
-
[71]
Why did it work?
Describe an ad creative that used humor well. Why did it work?
-
[72]
How do you react to cause-based ads that take a political or social stance?
-
[73]
What elements on a landing page signal credibility within the first five seconds?
-
[74]
Describe the last video ad you watched to completion and why you stayed
-
[75]
How do you decide whether to trust a sponsored review or influencer post?
-
[76]
What microcopy or small UI details on a product page most influence your trust?
-
[77]
Describe a brand touchpoint that increased your loyalty after seeing an ad or campaign
-
[78]
How would you describe yourself in three sentences?
-
[79]
What are the top three values that guide your decisions?
-
[80]
Why did you choose it?
Describe a recent choice you made that surprised people who know you. Why did you choose it?
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.