CODEBLOCK: Learning to Supervise Code at the Right Granularity
Pith reviewed 2026-06-27 10:49 UTC · model grok-4.3
The pith
Supervising only selected complete code blocks improves pass rates over full-token training while using 1.9 percent of response tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
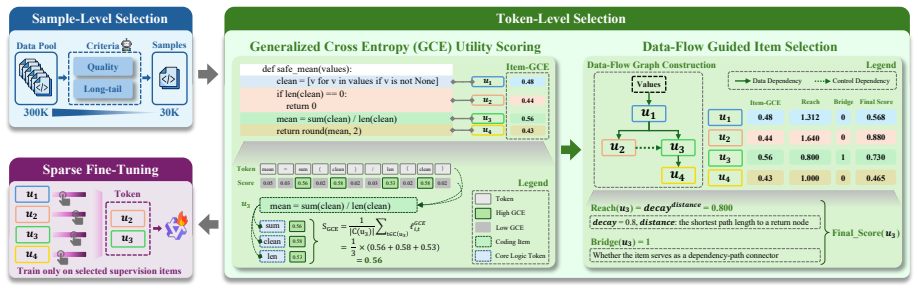
CodeBlock is a structure-aware sparse supervision framework that first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training the full response remains available as context while loss is applied only to selected code items and informative natural-language tokens, producing stronger average pass@1 than full-token SFT on six code-generation benchmarks while supervising only 1.9 percent of re
What carries the argument
The CodeBlock selection process that partitions responses into syntactically coherent coding items, aggregates generalized cross-entropy on core logic tokens, and reranks with data-flow reach and bridge signals.
If this is right
- Models trained with CodeBlock achieve higher average pass@1 than full-token SFT on code generation benchmarks.
- Only 1.9 percent of response tokens require supervision under the method.
- Performance remains competitive with other token-level selection baselines.
- The full response is retained as context while loss is restricted to selected blocks and natural-language tokens.
Where Pith is reading between the lines
- The emphasis on syntactic completeness and data-flow connections suggests the same selection logic could be tested on other structured outputs that rely on dependency relations.
- Lower supervised-token counts may allow fine-tuning runs on larger code datasets without proportional increases in compute.
- Replacing uniform loss with block-level selection could be combined with existing data-filtering pipelines to further reduce training cost.
Load-bearing premise
That selecting syntactically complete code items via aggregated generalized cross-entropy on core logic tokens plus data-flow reach and bridge reranking identifies blocks that deliver superior learning signal compared with uniform token supervision.
What would settle it
Train identical models on the same data once with CodeBlock block selection and once with uniform token loss, then compare their pass@1 scores on the six benchmarks; equal or lower scores for the CodeBlock version would falsify the claim.
Figures



read the original abstract
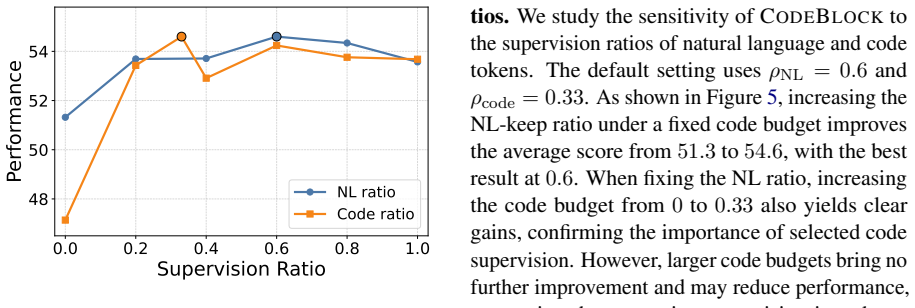
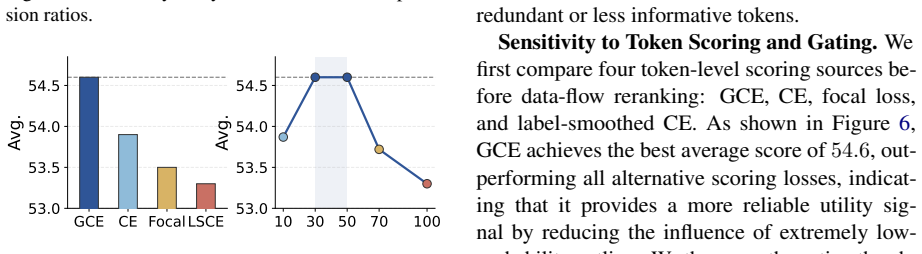
Supervised fine-tuning of code LLMs typically applies uniform cross-entropy loss to all response tokens, implicitly assuming that every token provides equally useful learning signal. Recent token-level selection methods challenge this assumption in natural-language SFT by supervising only high-value tokens. However, directly transferring token-level masking to code can break syntactically and semantically coherent program units, because code depends on structural completeness and definition-use relations. We therefore propose CodeBlock, a structure-aware sparse supervision framework that selects structure-complete code evidence rather than isolated tokens. CodeBlock first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training, the full response remains available as context, while loss is applied only to selected code items and informative natural-language tokens. Experiments on six code-generation benchmarks show that CodeBlock achieves stronger average pass@1 than full-token SFT and competitive selection baselines, while using only 1.9% of supervised response tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodeBlock, a structure-aware sparse supervision method for fine-tuning code LLMs. It first filters high-quality instruction-response pairs, partitions code responses into syntactically complete blocks, estimates block utility via aggregated generalized cross-entropy on core logic tokens combined with data-flow reach and bridge reranking, and applies loss only to selected blocks plus informative NL tokens while keeping the full response as context. On six code-generation benchmarks, it reports stronger average pass@1 than full-token SFT and competitive selection baselines while supervising only 1.9% of response tokens.
Significance. If the performance gains are shown to arise from the block-level mechanism rather than upstream pair filtering, the work would provide a principled way to respect syntactic and data-flow structure in code supervision, potentially improving sample efficiency over uniform or token-level masking approaches.
major comments (2)
- [Experimental Results] Experimental Results section: the full-token SFT baseline is not described as using the same high-quality pair filter as CodeBlock, so the reported pass@1 gains cannot be attributed to block granularity versus pair selection. An ablation that applies full-token SFT to the filtered pairs (and block supervision to unfiltered pairs) is required to support the central claim.
- [Experimental protocol] § on experimental protocol (and Abstract): no description of the training protocol, exact baseline implementations, number of runs, statistical tests, or error bars is supplied, preventing verification that the average pass@1 improvements are reliable rather than artifacts of a single run or implementation detail.
minor comments (1)
- [Method] Notation for 'generalized cross-entropy' and 'data-flow reach/bridge' should be defined with an equation or pseudocode in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the experimental claims.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the full-token SFT baseline is not described as using the same high-quality pair filter as CodeBlock, so the reported pass@1 gains cannot be attributed to block granularity versus pair selection. An ablation that applies full-token SFT to the filtered pairs (and block supervision to unfiltered pairs) is required to support the central claim.
Authors: We agree that the manuscript does not explicitly clarify whether the full-token SFT baseline applies the same pair filter used by CodeBlock. To isolate the contribution of block-level selection from pair filtering, we will add the requested ablations (full SFT on filtered pairs; block supervision on unfiltered pairs) to the Experimental Results section of the revised manuscript. revision: yes
-
Referee: [Experimental protocol] § on experimental protocol (and Abstract): no description of the training protocol, exact baseline implementations, number of runs, statistical tests, or error bars is supplied, preventing verification that the average pass@1 improvements are reliable rather than artifacts of a single run or implementation detail.
Authors: We acknowledge that the current manuscript lacks sufficient detail on the experimental protocol. In the revision we will expand the relevant section (and update the abstract if needed) to specify the full training protocol, exact baseline implementations, number of runs with different random seeds, statistical tests performed, and error bars on all reported metrics. revision: yes
Circularity Check
No significant circularity; empirical method with independent benchmarks
full rationale
The paper describes an empirical framework (pair selection, syntactic partitioning, utility estimation via aggregated GCE plus data-flow reranking, then masked loss) and reports pass@1 results on six benchmarks. No equations, derivations, or first-principles claims appear that reduce an output quantity to a fitted parameter or self-citation by construction. The central claim rests on comparative experiments rather than any self-definitional or load-bearing self-citation step. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Miltiadis Allamanis, Marc Brockschmidt, and Mah- moud Khademi
Opencodein- struct: A large-scale instruction tuning dataset for code llms.arXiv preprint arXiv:2504.04030. Miltiadis Allamanis, Marc Brockschmidt, and Mah- moud Khademi
-
[2]
Learning to Represent Programs with Graphs
Learning to repre- sent programs with graphs.arXiv preprint arXiv:1711.00740. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Program Synthesis with Large Language Models
Program synthesis with large language models.arXiv preprint arXiv:2108.07732. Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srini- vasan, Tianyi Zhou, Heng Huang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2307.08701
Alpagasus: Training a better alpaca with fewer data. arXiv preprint arXiv:2307.08701. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others
-
[5]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Yicheng Chen, Yining Li, Kai Hu, Ma Zerun, HaochenYe HaochenYe, and Kai Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
In Findings of the Association for Computational Lin- guistics: ACL 2025, pages 9902–9915
Mig: Automatic data selection for instruction tuning by maximizing information gain in semantic space. In Findings of the Association for Computational Lin- guistics: ACL 2025, pages 9902–9915. Zhijie Deng, Zhouan Shen, Ling Li, Yao Zhou, Zhaowei Zhu, Yanji He, Wei Wang, and Jiaheng Wei
2025
-
[7]
Yanjun Fu, Faisal Hamman, and Sanghamitra Dutta
Lm-mixup: Text data augmentation via language model based mixup.arXiv preprint arXiv:2510.20449. Yanjun Fu, Faisal Hamman, and Sanghamitra Dutta
-
[8]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Graph- codebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366. Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yi- fan Wu, YK Li, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Deepseek- coder: when the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196. Siming Huang, Tianhao Cheng, Jason Klein Liu, Weidi Xu, Jiaran Hao, Liuyihan Song, Yang Xu, Jian Yang, Jiaheng Liu, Chenchen Zhang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186. Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
From quantity to quality: Boost- ing llm performance with self-guided data selection for instruction tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7602–7635. Yanping Li, Zhening Liu, Zijian Li, Zehong Lin, and Jun Zhang
2024
-
[12]
Xiaotian Lin, Yanlin Qi, Yuxiang Luo, Themis Palpanas, and Yuyu Luo
Token-level data selection for safe llm fine-tuning.arXiv preprint arXiv:2603.01185. Xiaotian Lin, Yanlin Qi, Yuxiang Luo, Themis Palpanas, and Yuyu Luo
-
[13]
Tokentune: Dual-level utility estimation for scalable data selection in instruction tuning. Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and 1 others. 2024a. Rho-1: Not all tokens are what you need.arXiv preprint arXiv:2404.07965. Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wa...
-
[14]
9 Weijie Lyu, Sheng-Jun Huang, and Xuan Xia
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning.arXiv preprint arXiv:2312.15685. 9 Weijie Lyu, Sheng-Jun Huang, and Xuan Xia
-
[15]
Jinlong Pang, Na Di, Zhaowei Zhu, Jiaheng Wei, Hao Cheng, Chen Qian, and Yang Liu
Efficient code llm training via distribution-consistent and diversity-aware data selection.arXiv preprint arXiv:2507.02378. Jinlong Pang, Na Di, Zhaowei Zhu, Jiaheng Wei, Hao Cheng, Chen Qian, and Yang Liu
-
[16]
Improving data efficiency via curating llm-driven rating systems.arXiv preprint arXiv:2410.10877. Xiaohan Qin, Xiaoxing Wang, Ning Liao, Cancheng Zhang, Xiangdong Zhang, Mingquan Feng, Jingzhi Wang, and Junchi Yan
-
[17]
sstoken: Self- modulated and semantic-aware token selection for llm fine-tuning.arXiv preprint arXiv:2510.18250. ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, and 1 others
-
[18]
arXiv preprint arXiv:2506.03524
Seed-coder: Let the code model curate data for itself. arXiv preprint arXiv:2506.03524. Yun-Da Tsai, Mingjie Liu, and Haoxing Ren
-
[19]
Code less, align more: Efficient llm fine-tuning for code generation with data pruning.arXiv preprint arXiv:2407.05040. Yejie Wang, Keqing He, Dayuan Fu, Zhuoma GongQue, Heyang Xu, Yanxu Chen, Zhexu Wang, Yujia Fu, Guanting Dong, Muxi Diao, and 1 others
-
[20]
How do your code llms perform? empowering code in- struction tuning with really good data. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14027–14043. Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro V on Werra, Arjun Guha, and Lingming Zhang. 202...
-
[21]
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen
Rose: A reward-oriented data selection framework for llm task-specific instruction tuning.arXiv preprint arXiv:2412.00631. Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen
-
[22]
arXiv preprint arXiv:2402.04333
Less: Se- lecting influential data for targeted instruction tuning. arXiv preprint arXiv:2402.04333. Jiapeng Yu, Yuqian Wu, Yajing Zhan, Wenhao Guo, Zhou Xu, and Raymond Lee
-
[23]
InInternational Conference on Learning Representations, volume 2025, pages 66602–66656
Bigcodebench: Benchmarking code generation with diverse function calls and complex in- structions. InInternational Conference on Learning Representations, volume 2025, pages 66602–66656. 10 A Experimental Details A.1 Sample-Level Selection Settings We perform sample-level selection from the 300K OpenCodeInstruct (OCI) source pool before ap- plying item-le...
2025
-
[24]
For full-token SFT, we train the model for 30,000 steps to provide a strong dense-supervision base- line. For CodeBlcok and all sparse-selection base- lines, we use 3,000 training steps under the same optimization setup, so that the comparison focuses on the quality of selected supervision signals un- der a limited training budget. All experiments are con...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.