Domain Generalizable Adaptation of 3D Vision-Language Models via Regularized Fine-Tuning
Pith reviewed 2026-06-27 00:56 UTC · model grok-4.3
The pith
ReFine3D applies selective fine-tuning plus multi-view and text-diversity regularization to lift domain generalization in 3D vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReFine3D combines selective layer tuning with multi-view consistency regularization across augmented point clouds, synonym-based text diversity prompts from large language models, point-rendered vision supervision, and confidence-weighted test-time aggregation, producing reported gains of 1.36% on base-to-novel generalization, 2.43% on cross-dataset transfer, 1.80% on corruption robustness, and up to 3.11% on few-shot accuracy over prior methods.
What carries the argument
The ReFine3D regularized fine-tuning framework that enforces multi-view consistency on point clouds and text diversity via LLM synonym prompts during adaptation of 3D large multimodal models.
If this is right
- Base-to-novel class accuracy rises by 1.36% on the evaluated 3D benchmarks.
- Cross-dataset transfer accuracy increases by 2.43%.
- Robustness under common 3D corruptions improves by 1.80%.
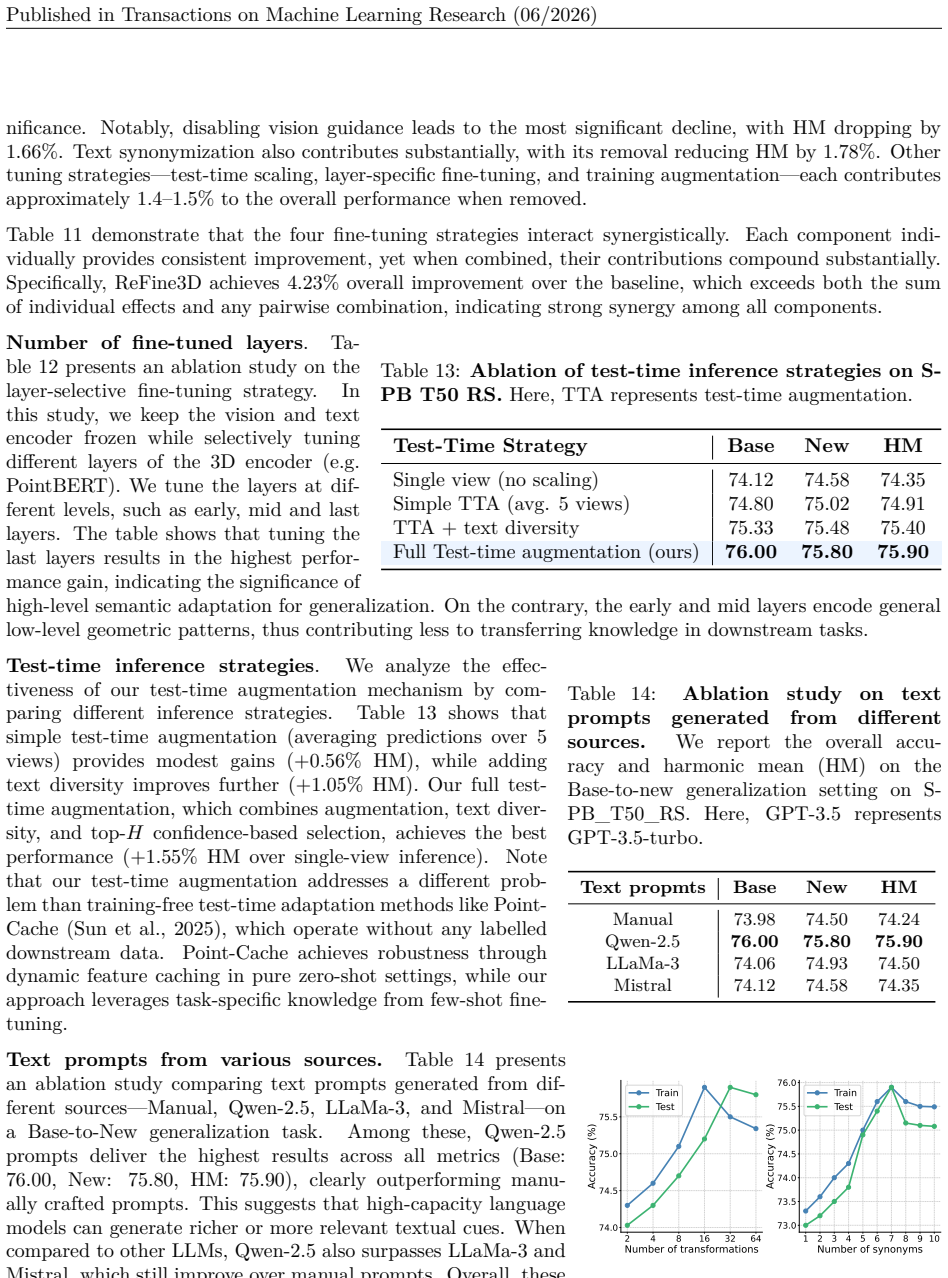
- Few-shot accuracy gains reach 3.11% with the same training budget.
- The added regularization incurs only minimal extra compute during training and inference.
Where Pith is reading between the lines
- The same consistency-plus-diversity pattern could be tested on 2D vision-language models to check whether the gains transfer across dimensionality.
- Replacing the LLM synonym generator with a smaller, domain-specific paraphraser might reduce dependence on large external models while preserving the reported benefit.
- The test-time aggregation step could be adapted for online 3D streaming scenarios where multiple partial scans arrive sequentially.
- Because the method keeps most layers frozen, it may scale to even larger 3D foundation models without proportional growth in memory.
Load-bearing premise
The observed generalization improvements stem mainly from the two regularization terms and the added supervision and aggregation steps rather than from dataset particulars or baseline implementation choices.
What would settle it
A controlled ablation that removes the multi-view consistency loss and the LLM synonym diversity prompts while keeping all other components fixed shows no statistically significant improvement over standard fine-tuning on the same four benchmark suites.
Figures
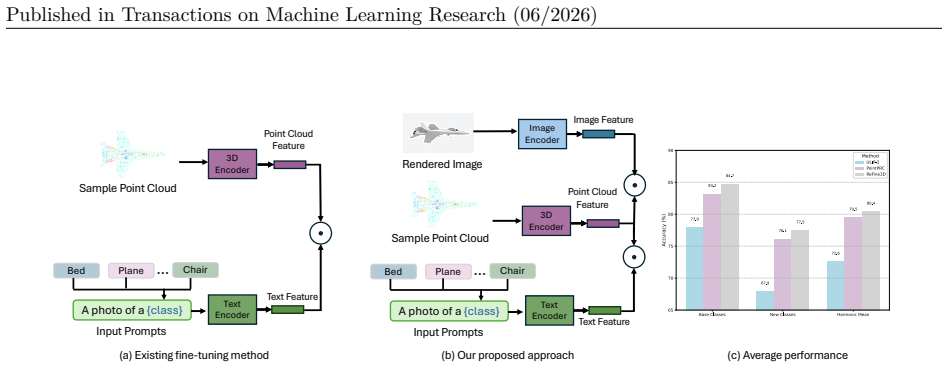

read the original abstract
Domain adaptation remains a central challenge in 3D vision, especially for multimodal foundation models that align 3D point clouds with visual and textual data. While these models demonstrate strong general capabilities, adapting them to downstream domains with limited data often leads to overfitting and catastrophic forgetting. To address this, we introduce ReFine3D, a regularized fine-tuning framework designed for domain-generalizable tuning of 3D large multimodal models (LMMs). ReFine3D combines selective layer tuning with two targeted regularization strategies: multi-view consistency across augmented point clouds and text diversity through synonym-based prompts generated by large language models. Additionally, we incorporate point-rendered vision supervision and a test-time augmentation mechanism with confidence-based aggregation to further enhance robustness. Extensive experiments across different 3D domain generalization benchmarks show that ReFine3D improves base-to-novel class generalization by 1.36%, cross-dataset transfer by 2.43%, robustness to corruption by 1.80%, and few-shot accuracy by up to 3.11%, outperforming prior state-of-the-art methods with minimal added computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ReFine3D, a regularized fine-tuning framework for domain-generalizable adaptation of 3D vision-language models. It uses selective layer tuning, multi-view consistency across augmented point clouds, text diversity via synonym-based LLM prompts, point-rendered vision supervision, and test-time augmentation with confidence-based aggregation. Reported improvements include 1.36% in base-to-novel class generalization, 2.43% in cross-dataset transfer, 1.80% in robustness to corruption, and up to 3.11% in few-shot accuracy, outperforming prior SOTA with minimal overhead.
Significance. If substantiated by detailed experiments, this approach could provide an effective way to adapt 3D multimodal models to new domains while preserving generalization, which is critical for practical applications in varying environments. The use of regularization and test-time methods addresses common issues like overfitting in fine-tuning.
major comments (1)
- [Abstract] The abstract states performance numbers but supplies no experimental protocol, baselines, statistical significance, or ablation details; without the full paper the numerical claims cannot be verified and the soundness of the central claim remains unassessable.
Simulated Author's Rebuttal
Thank you for your review of our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract states performance numbers but supplies no experimental protocol, baselines, statistical significance, or ablation details; without the full paper the numerical claims cannot be verified and the soundness of the central claim remains unassessable.
Authors: The abstract is a concise summary by design and does not include full experimental protocols, which are standardly placed in the main body. The full manuscript (Sections 4 and 5 plus supplementary material) details the benchmarks (ModelNet, ScanNet, etc.), baselines (including prior SOTA), evaluation protocols, multiple-run statistical significance, and ablations for each component. These sections allow verification of the reported gains (1.36% base-to-novel, etc.). If the review was performed on the abstract alone, we are happy to highlight the relevant sections or supply excerpts. revision: no
Circularity Check
No significant circularity; empirical framework with independent validation
full rationale
The paper proposes ReFine3D, a practical fine-tuning method that combines selective layer tuning with multi-view consistency regularization, LLM-generated synonym prompts for text diversity, point-rendered supervision, and test-time aggregation. All reported gains (base-to-novel, cross-dataset, corruption robustness, few-shot) are presented as outcomes of controlled experiments on external benchmarks rather than any closed-form derivation, fitted parameter relabeled as prediction, or self-citation chain. No equation or uniqueness claim reduces to its own inputs by construction; the central contribution is an algorithmic recipe whose performance is measured against independent baselines and datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
International Journal of Man-Machine Studies , volume = 20, number = 1, pages =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Pointclip: Point cloud understanding by clip , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Clip2point: Transfer clip to point cloud classification with image-depth pre-training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Clip goes 3d: Leveraging prompt tuning for language grounded 3d recognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[17]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Robust fine-tuning of zero-shot models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Domain generalization: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
2022
-
[19]
International Conference on Machine Learning , pages=
Benchmarking and analyzing point cloud classification under corruptions , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[20]
Advances in Neural Information Processing Systems , volume=
Learning generalizable part-based feature representation for 3d point clouds , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Advances in Neural Information Processing Systems , volume=
Pointdan: A multi-scale 3d domain adaption network for point cloud representation , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Metasets: Meta-learning on point sets for generalizable representations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ulip-2: Towards scalable multimodal pre-training for 3d understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instance-aware dynamic prompt tuning for pre-trained point cloud models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[27]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Parameter-efficient prompt learning for 3d point cloud understanding , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Point-peft: Parameter-efficient fine-tuning for 3d pre-trained models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Dynamic adapter meets prompt tuning: Parameter-efficient transfer learning for point cloud analysis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
The Annals of Mathematical Statistics , volume=
On an inequality of Hoeffding , author=. The Annals of Mathematical Statistics , volume=. 1967 , publisher=
1967
-
[31]
Machine learning , volume=
A theory of learning from different domains , author=. Machine learning , volume=. 2010 , publisher=
2010
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
2023 20th Conference on Robots and Vision (CRV) , pages=
Crossmoco: multi-modal momentum contrastive learning for point cloud , author=. 2023 20th Conference on Robots and Vision (CRV) , pages=. 2023 , organization=
2023
-
[34]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Point-PRC: A Prompt Learning Based Regulation Framework for Generalizable Point Cloud Analysis , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[35]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Pointnet: Deep learning on point sets for 3d classification and segmentation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[36]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Deep Learning for 3D Point Clouds: A Survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Emergent correspondence from image diffusion , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:2310.03693 , year=
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. arXiv preprint arXiv:2310.03693 , year=
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Point-bert: Pre-training 3d point cloud transformers with masked point modeling , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
2011 IEEE International Conference on Robotics and Automation (ICRA) , year=
3D is here: Point Cloud Library (PCL) , author=. 2011 IEEE International Conference on Robotics and Automation (ICRA) , year=
2011
-
[41]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Self-regulating prompts: Foundational model adaptation without forgetting , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Promptkd: Unsupervised prompt distillation for vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
arXiv preprint arXiv:1512.03012 , year=
Shapenet: An information-rich 3d model repository , author=. arXiv preprint arXiv:1512.03012 , year=
-
[44]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[45]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
3d shapenets: A deep representation for volumetric shapes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[46]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning 3d representations from 2d pre-trained models via image-to-point masked autoencoders , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[49]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Cogvlm: Visual expert for pretrained language models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
International Journal of Computer Vision , volume=
Clip-adapter: Better vision-language models with feature adapters , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
2024
-
[52]
Advances in Neural Information Processing Systems , volume=
Meta-adapter: An online few-shot learner for vision-language model , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[54]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
European conference on computer vision , pages=
Slip: Self-supervision meets language-image pre-training , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Communications of the ACM , volume=
WordNet: a lexical database for English , author=. Communications of the ACM , volume=. 1995 , publisher=
1995
-
[58]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
InvariantOODG: Learning Invariant Features of Point Clouds for Out-of-Distribution Generalization , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[59]
arXiv preprint arXiv:1911.01911 , year=
Blenderproc , author=. arXiv preprint arXiv:1911.01911 , year=
arXiv 1911
-
[60]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[61]
ICLR , year=
Uni3D: Exploring Unified 3D Representation at Scale , author=. ICLR , year=
-
[62]
Advances in neural information processing systems , volume=
Openshape: Scaling up 3d shape representation towards open-world understanding , author=. Advances in neural information processing systems , volume=
-
[63]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Point-Cache: Test-time Dynamic and Hierarchical Cache for Robust and Generalizable Point Cloud Analysis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
PointLoRA: Low-rank adaptation with token selection for point cloud learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Minigpt-3d: Efficiently aligning 3d point clouds with large language models using 2d priors , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[66]
2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=
Spatial 3D-LLM: exploring spatial awareness in 3D vision-language models , author=. 2025 IEEE International Conference on Multimedia and Expo (ICME) , pages=. 2025 , organization=
2025
-
[67]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[68]
arXiv preprint arXiv:2603.23730 , year=
An Adapter-free Fine-tuning Approach for Tuning 3D Foundation Models , author=. arXiv preprint arXiv:2603.23730 , year=
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Point Cloud as a Foreign Language for Multi-modal Large Language Model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
European Conference on Computer Vision , pages=
Improving 3D Semi-supervised Learning by Effectively Utilizing All Unlabelled Data , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.