Splaxel: Efficient Distributed Training of 3D Gaussian Splatting for Large-scale Scene Reconstruction via Pixel-level Communication
Pith reviewed 2026-06-26 19:55 UTC · model grok-4.3
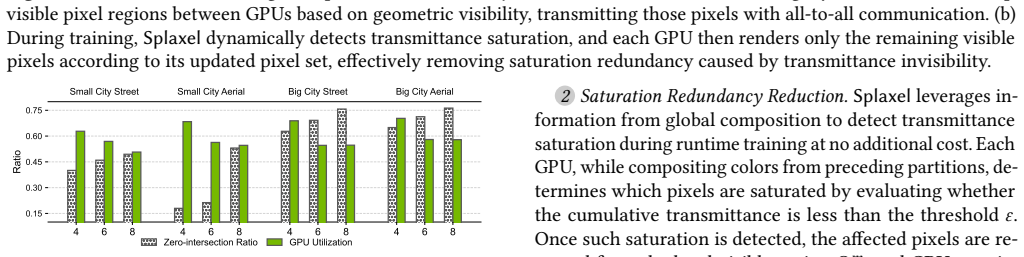
The pith
Splaxel trains large-scale 3D Gaussian Splatting models by exchanging rendered pixel values instead of full Gaussians across GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
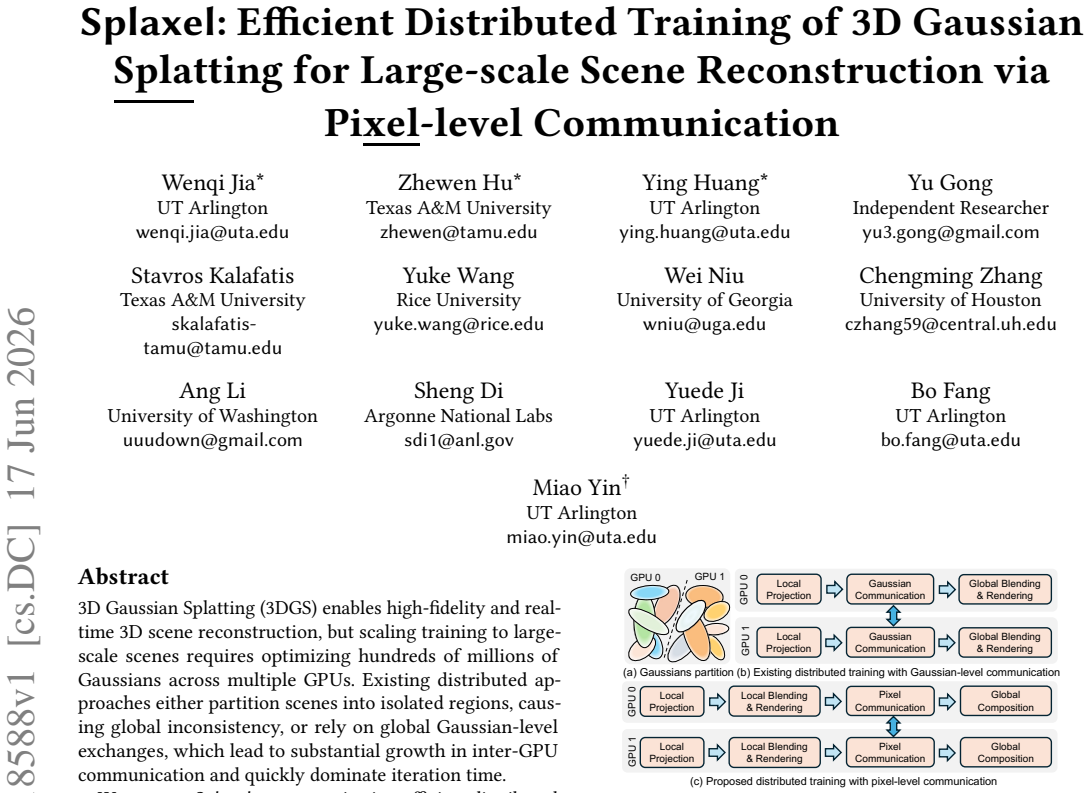
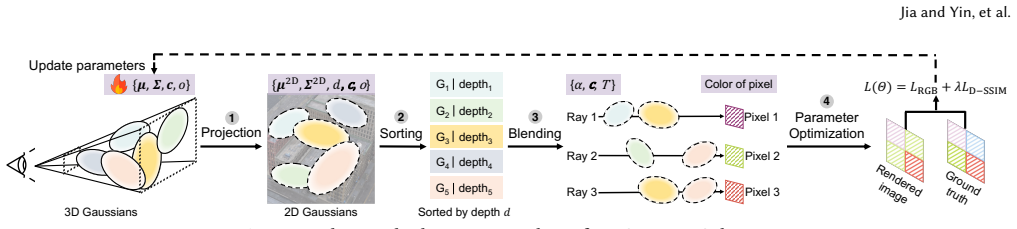
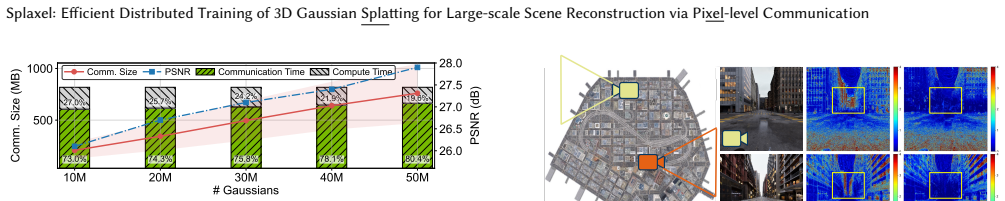
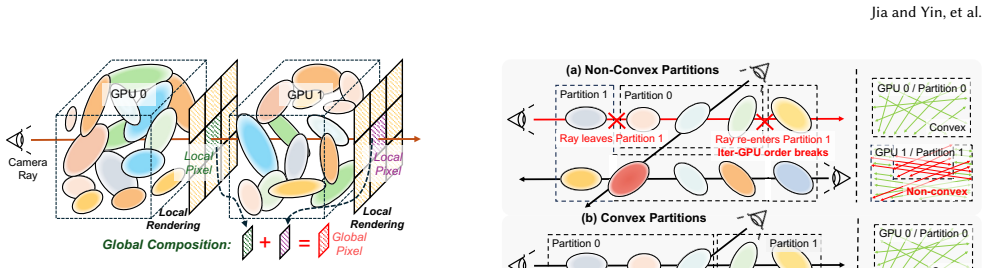
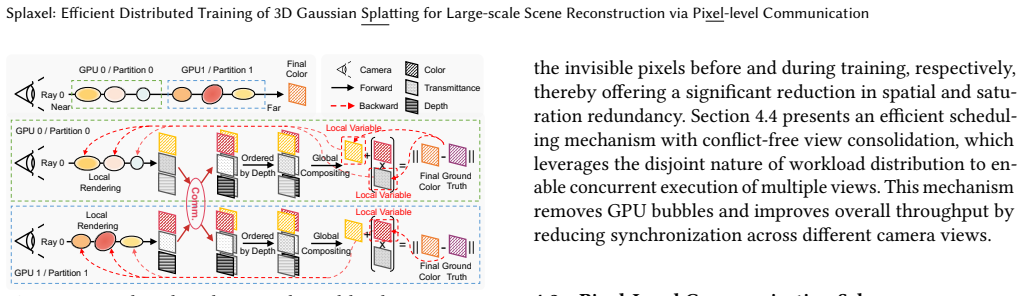
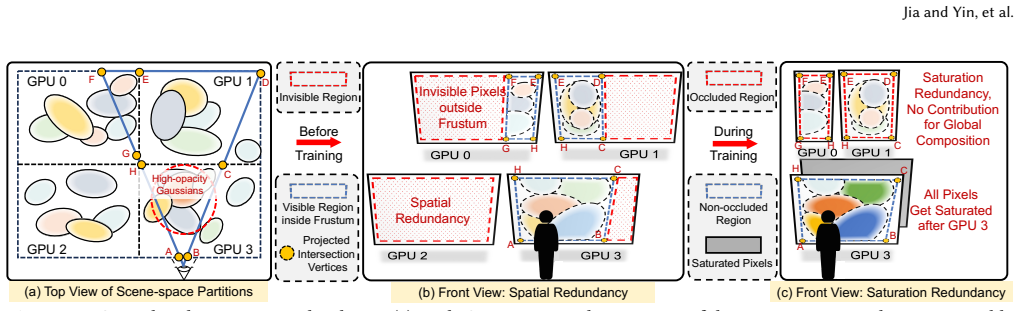
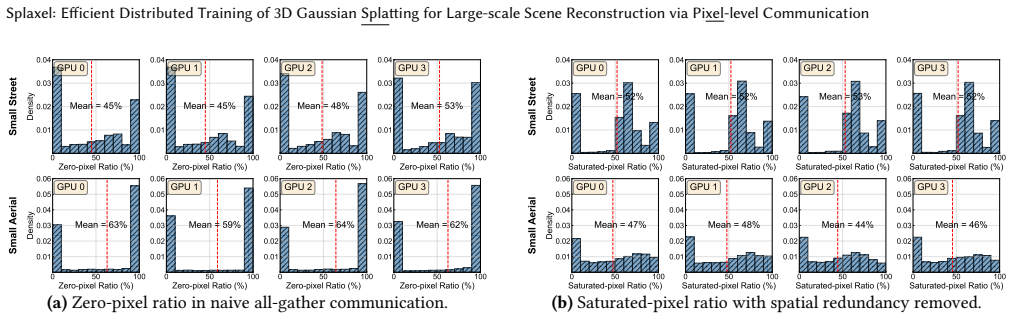
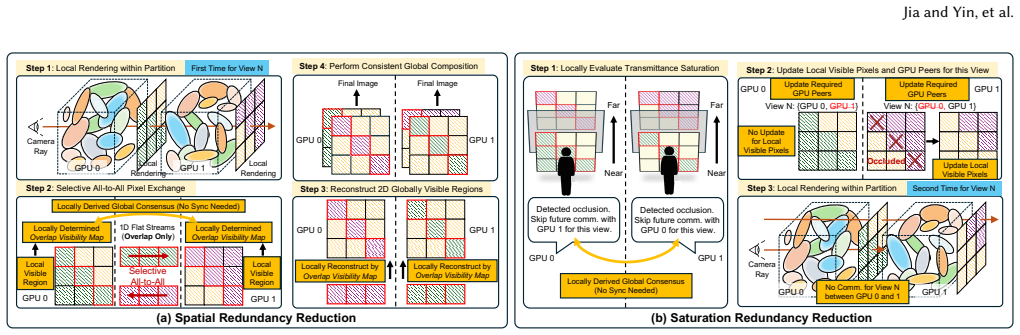
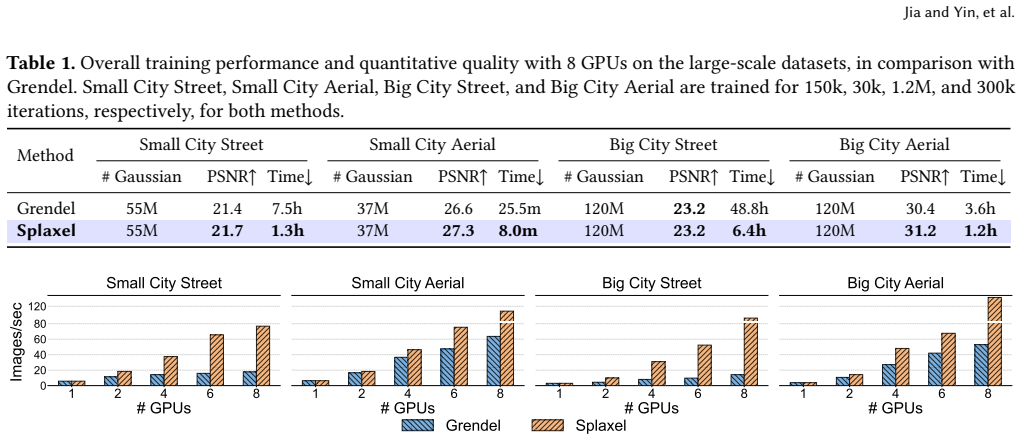
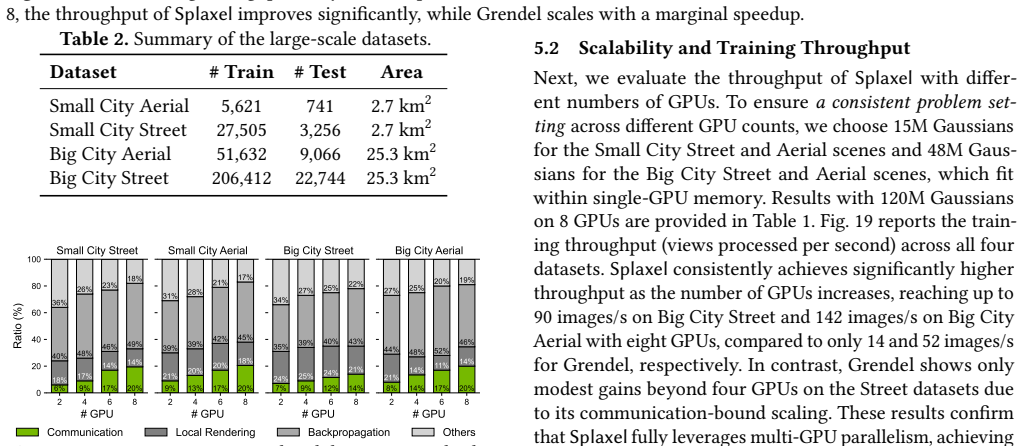
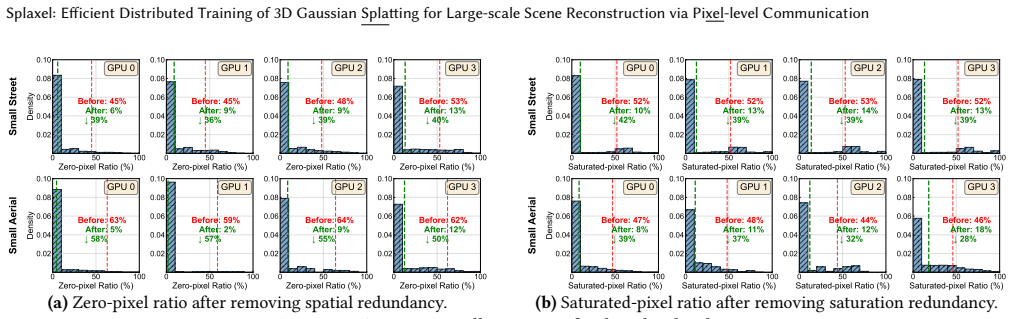
Splaxel replaces Gaussian-level synchronization with pixel-level local rendering and global composition: each GPU renders only its assigned Gaussians, exchanges the resulting partial pixel values, and composes them into a consistent image. Geometric and transmittance visibility prediction removes redundant pixels before transfer, and conflict-free camera-view consolidation improves parallel GPU efficiency. On datasets reaching 120 million Gaussians the method produces up to 7.6 times faster training than prior distributed 3DGS systems while the authors report no measurable drop in reconstruction quality.
What carries the argument
Pixel-level local rendering and global composition that substitutes for full Gaussian synchronization.
If this is right
- Communication volume stays roughly constant even as the number of Gaussians rises into the hundreds of millions.
- Training time for large scenes drops by as much as 7.6 times compared with existing distributed 3DGS methods.
- Reconstruction quality metrics remain comparable to non-distributed training on the evaluated large-scale datasets.
- GPU idle time decreases through visibility-based culling and consolidated camera views.
Where Pith is reading between the lines
- The same pixel-exchange pattern could be tested on other differentiable rendering pipelines that currently rely on point or primitive synchronization.
- If the consistency claim holds, incremental training of dynamic large scenes becomes feasible without full resynchronization at every step.
- The method opens the possibility of running 3DGS training on clusters whose interconnect bandwidth would otherwise be saturated by Gaussian data.
Load-bearing premise
Exchanging only partial pixel values after local rendering produces the same final image as exchanging and synchronizing every Gaussian.
What would settle it
A side-by-side comparison on a 120-million-Gaussian scene showing whether PSNR or visual artifacts differ between Splaxel runs and an equivalent full-synchronization baseline as the number of Gaussians or GPUs is increased.
Figures







read the original abstract
3D Gaussian Splatting (3DGS) enables high-fidelity and real-time 3D scene reconstruction, but scaling training to large-scale scenes requires optimizing hundreds of millions of Gaussians across multiple GPUs. Existing distributed approaches either partition scenes into isolated regions, causing global inconsistency, or rely on global Gaussian-level exchanges, which lead to substantial growth in inter-GPU communication and quickly dominate iteration time. We propose Splaxel, a communication-efficient distributed 3DGS training framework based on pixel-level local rendering and global composition. Instead of synchronizing Gaussians, each GPU renders its local subset and exchanges only partial pixel values, maintaining mathematical consistency while keeping communication cost stable as the scene size increases. Splaxel further reduces pixel-level redundancy through geometric and transmittance visibility prediction and improves GPU utilization via conflict-free camera-view consolidation. Evaluated on large-scale datasets with up to 120M Gaussians, Splaxel achieves up to 7.6$\times$ speedup over the state-of-the-art distributed 3DGS framework while preserving high reconstruction quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Splaxel, a distributed 3D Gaussian Splatting training framework that partitions Gaussians across GPUs, performs local rendering on each subset, and exchanges only partial pixel values for global composition rather than synchronizing full Gaussians. It incorporates geometric and transmittance-based visibility prediction to reduce pixel redundancy and conflict-free camera-view consolidation to improve utilization. Experiments on large-scale scenes with up to 120M Gaussians report up to 7.6× speedup over prior distributed 3DGS methods while preserving reconstruction quality.
Significance. If the pixel-level composition is shown to preserve exact per-pixel blending, depth ordering, and gradients equivalent to full Gaussian synchronization, the approach would meaningfully advance scalable 3DGS by decoupling communication volume from scene size, addressing a primary bottleneck in multi-GPU training for massive environments.
major comments (2)
- [§3] §3 (Pixel-level Composition): The central claim that local rendering plus global pixel composition maintains exact mathematical equivalence to full Gaussian synchronization (including correct transmittance accumulation and contribution weights across partitions) is load-bearing for the quality-preservation result, yet the manuscript supplies no explicit equations or derivation showing how cross-partition depth ordering is reconstructed without approximation when Gaussians overlap multiple GPUs.
- [§4] §4 (Experiments, visibility prediction): The reported 7.6× speedup must be shown to remain after subtracting visibility-prediction overhead; without a per-component timing breakdown (e.g., prediction vs. communication vs. rendering) in Table 2 or Figure 5, it is unclear whether the net gain holds as partition count or scene size increases.
minor comments (2)
- [§3.1] Notation for partial pixel values and the global composition operator should be defined once in §3.1 and used consistently thereafter to avoid ambiguity in the gradient-flow argument.
- [Figure 4] Figure 4 caption should explicitly state the number of Gaussians and GPUs used for the scaling plot to allow direct comparison with the 120M-Gaussian experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of mathematical equivalence and experimental analysis.
read point-by-point responses
-
Referee: [§3] §3 (Pixel-level Composition): The central claim that local rendering plus global pixel composition maintains exact mathematical equivalence to full Gaussian synchronization (including correct transmittance accumulation and contribution weights across partitions) is load-bearing for the quality-preservation result, yet the manuscript supplies no explicit equations or derivation showing how cross-partition depth ordering is reconstructed without approximation when Gaussians overlap multiple GPUs.
Authors: We agree that an explicit derivation would strengthen the central claim. Although Section 3 describes the pixel-level composition and states that it maintains mathematical consistency, the manuscript does not include a full set of equations deriving cross-partition depth ordering and transmittance accumulation. We will add a dedicated derivation subsection in the revised §3 demonstrating exact equivalence to full Gaussian synchronization without approximation. revision: yes
-
Referee: [§4] §4 (Experiments, visibility prediction): The reported 7.6× speedup must be shown to remain after subtracting visibility-prediction overhead; without a per-component timing breakdown (e.g., prediction vs. communication vs. rendering) in Table 2 or Figure 5, it is unclear whether the net gain holds as partition count or scene size increases.
Authors: The experiments report aggregate speedups on scenes up to 120M Gaussians, but we concur that component-wise timings are needed to isolate visibility-prediction overhead. We will expand Table 2 and Figure 5 with per-component breakdowns (prediction, communication, rendering) to confirm that the reported net gains persist as the number of partitions or scene size grows. revision: yes
Circularity Check
No circularity: empirical performance claim with no self-referential derivations
full rationale
The paper proposes a distributed 3DGS framework and asserts that pixel-level local rendering plus global composition maintains mathematical consistency. The central claim is an empirical speedup (7.6×) on large scenes while preserving quality. No equations, fitted parameters, or derivations appear in the provided text that reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is presented as a derivation. The consistency assertion is stated without a closed-form reduction to the input data or prior self-work, leaving the result externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jon Louis Bentley. 1975. Multidimensional binary search trees used for associative searching.Commun. ACM18 (1975), 509–517.https: //api.semanticscholar.org/CorpusID:13091446
1975
-
[2]
2003.Convex analysis and optimization
Dimitri Bertsekas, Angelia Nedic, and Asuman Ozdaglar. 2003.Convex analysis and optimization. Vol. 1. Athena Scientific
2003
-
[3]
2004.Convex optimization
Stephen Boyd and Lieven Vandenberghe. 2004.Convex optimization. Cambridge university press
2004
-
[4]
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. 2024. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19457–19467
2024
-
[5]
Junyi Chen, Weicai Ye, Yifan Wang, Danpeng Chen, Di Huang, Wanli Ouyang, Guofeng Zhang, Yu Qiao, and Tong He. 2024. Gigags: Scaling up planar-based 3d gaussians for large scene surface reconstruction. arXiv preprint arXiv:2409.06685(2024)
arXiv 2024
-
[6]
Youyu Chen, Junjun Jiang, Kui Jiang, Xiao Tang, Zhihao Li, Xianming Liu, and Yinyu Nie. 2025. DashGaussian: Optimizing 3D Gaussian Splatting in 200 Seconds. InProceedings of the Computer Vision and Pattern Recognition Conference. 11146–11155
2025
-
[7]
Yu Chen and Gim Hee Lee. 2024. Dogs: Distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaussian consensus. Advances in Neural Information Processing Systems37 (2024), 34487– 34512
2024
-
[8]
Sina Darabi, Mohammad Sadrosadati, Negar Akbarzadeh, Joël Lin- degger, Mohammad Hosseini, Jisung Park, Juan Gómez-Luna, Onur Mutlu, and Hamid Sarbazi-Azad. 2022. Morpheus: Extending the last level cache capacity in GPU systems using idle GPU core resources. In2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 228–244
2022
-
[9]
Tianhu Deng, Keren Zhang, and Zuo-Jun Max Shen. 2021. A systematic review of a digital twin city: A new pattern of urban governance toward smart cities.Journal of management science and engineering6, 2 (2021), 125–134
2021
-
[10]
Sankeerth Durvasula, Adrian Zhao, Fan Chen, Ruofan Liang, Pawan Kumar Sanjaya, Yushi Guan, Christina Giannoula, and Nandita Vijaykumar. 2025. ARC: Warp-level Adaptive Atomic Reduction in GPUs to Accelerate Differentiable Rendering. InProceedings of the 30th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Sys...
2025
-
[11]
Sankeerth Durvasula, Adrian Zhao, Fan Chen, Ruofan Liang, Pawan Kumar Sanjaya, and Nandita Vijaykumar. 2023. Distwar: Fast differentiable rendering on raster-based rendering pipelines.arXiv preprint arXiv:2401.05345(2023)
arXiv 2023
-
[12]
Jixuan Fan, Wanhua Li, Yifei Han, Tianru Dai, and Yansong Tang. 2025. Momentum-gs: Momentum gaussian self-distillation for high-quality large scene reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision. 25250–25260
2025
-
[13]
Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, Zhangyang Wang, et al. 2024. Lightgaussian: Unbounded 3d gaussian compression with 15x reduction and 200+ fps.Advances in neural information processing systems37 (2024), 140138–140158
2024
-
[14]
Guangchi Fang and Bing Wang. 2024. Mini-splatting: Representing scenes with a constrained number of gaussians. InEuropean Conference on Computer Vision. Springer, 165–181
2024
-
[15]
Guofeng Feng, Siyan Chen, Rong Fu, Zimu Liao, Yi Wang, Tao Liu, Boni Hu, Linning Xu, Zhilin Pei, Hengjie Li, et al. 2025. Flashgs: Efficient 3d gaussian splatting for large-scale and high-resolution rendering. In Proceedings of the Computer Vision and Pattern Recognition Conference. 26652–26662
2025
-
[16]
Linus Franke, Laura Fink, and Marc Stamminger. 2025. Vr-splatting: Foveated radiance field rendering via 3d gaussian splatting and neural points.Proceedings of the ACM on Computer Graphics and Interactive Techniques8, 1 (2025), 1–21
2025
-
[17]
Sharath Girish, Kamal Gupta, and Abhinav Shrivastava. 2024. Ea- gles: Efficient accelerated 3d gaussians with lightweight encodings. In European Conference on Computer Vision. Springer, 54–71
2024
-
[18]
Antoine Guédon and Vincent Lepetit. 2024. Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high- quality mesh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5354–5363
2024
-
[19]
Alex Hanson, Allen Tu, Geng Lin, Vasu Singla, Matthias Zwicker, and Tom Goldstein. 2025. Speedy-splat: Fast 3d gaussian splatting with sparse pixels and sparse primitives. InProceedings of the Computer Vision and Pattern Recognition Conference. 21537–21546
2025
-
[20]
Alex Hanson, Allen Tu, Vasu Singla, Mayuka Jayawardhana, Matthias Zwicker, and Tom Goldstein. 2025. Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference. 5949–5958
2025
-
[21]
Houshu He, Naifeng Jing, Li Jiang, Xiaoyao Liang, and Zhuoran Song
-
[22]
AGS: Accelerating 3D Gaussian Splatting SLAM via CODEC- Assisted Frame Covisibility Detection. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1(USA)(ASPLOS ’26). As- sociation for Computing Machinery, New York, NY, USA, 20–34. doi:10.1145/3760250.3762229
-
[23]
Houshu He, Gang Li, Fangxin Liu, Li Jiang, Xiaoyao Liang, and Zhuo- ran Song. 2025. GSArch: Breaking Memory Barriers in 3D Gaussian Splatting Training via Architectural Support. In2025 IEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA). IEEE, 366–379
2025
-
[24]
2013.Con- vex analysis and minimization algorithms I: Fundamentals
Jean-Baptiste Hiriart-Urruty and Claude Lemaréchal. 2013.Con- vex analysis and minimization algorithms I: Fundamentals. Vol. 305. Springer science & business media
2013
-
[25]
Qiqi Hou, Randall Rauwendaal, Zifeng Li, Hoang Le, Farzad Farhadzadeh, Fatih Porikli, Alexei Bourd, and Amir Said. 2024. Sort- free gaussian splatting via weighted sum rendering.arXiv preprint arXiv:2410.18931(2024)
arXiv 2024
-
[26]
Lihan Jiang, Kerui Ren, Mulin Yu, Linning Xu, Junting Dong, Tao Lu, Feng Zhao, Dahua Lin, and Bo Dai. 2025. Horizon-GS: Unified 3D Gaussian Splatting for Large-Scale Aerial-to-Ground Scenes. In Proceedings of the Computer Vision and Pattern Recognition Conference. 26789–26799
2025
-
[27]
Ying Jiang, Chang Yu, Tianyi Xie, Xuan Li, Yutao Feng, Huamin Wang, Minchen Li, Henry Lau, Feng Gao, Yin Yang, et al . 2024. Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. InACM SIGGRAPH 2024 Conference Papers. 1–1
2024
-
[28]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 2023. 3D Gaussian splatting for real-time radiance field rendering.ACM Trans. Graph.42, 4 (2023), 139–1
2023
-
[29]
Bernhard Kerbl, Andreas Meuleman, Georgios Kopanas, Michael Wim- mer, Alexandre Lanvin, and George Drettakis. 2024. A hierarchical 3d gaussian representation for real-time rendering of very large datasets. ACM Transactions on Graphics (TOG)43, 4 (2024), 1–15
2024
-
[30]
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. 2017. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics (ToG)36, 4 (2017), 1–13
2017
-
[31]
Jonas Kulhanek, Songyou Peng, Zuzana Kukelova, Marc Pollefeys, and Torsten Sattler. 2024. Wildgaussians: 3d gaussian splatting in the wild.arXiv preprint arXiv:2407.08447(2024)
arXiv 2024
-
[32]
Donghyun Lee, Dawoon Jeong, Jae W. Lee, and Hongil Yoon. 2026. GS- Scale: Unlocking Large-Scale 3D Gaussian Splatting Training via Host Offloading. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA)(ASPLOS ’26). Association for Computing Ma- chinery, New York, NY, ...
-
[33]
Junseo Lee, Kwanseok Choi, Jungi Lee, Seokwon Lee, Joonho Whangbo, and Jaewoong Sim. 2023. Neurex: A case for neural ren- dering acceleration. InProceedings of the 50th Annual International Symposium on Computer Architecture. 1–13
2023
-
[34]
Junseo Lee, Seokwon Lee, Jungi Lee, Junyong Park, and Jaewoong Sim. 2024. Gscore: Efficient radiance field rendering via architectural support for 3d gaussian splatting. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 497–511
2024
-
[35]
Chaojian Li, Sixu Li, Linrui Jiang, Jingqun Zhang, and Yingyan Celine Lin. 2025. Uni-Render: A Unified Accelerator for Real-Time Ren- dering Across Diverse Neural Renderers. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 246–260
2025
-
[36]
Chaojian Li, Sixu Li, Yang Zhao, Wenbo Zhu, and Yingyan Lin. 2022. Rt-nerf: Real-time on-device neural radiance fields towards immersive ar/vr rendering. InProceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design. 1–9
2022
-
[37]
Haolin Li, Jinyang Liu, Mario Sznaier, and Octavia Camps. 2025. 3D- HGS: 3D Half-Gaussian Splatting. InProceedings of the Computer Vision and Pattern Recognition Conference. 10996–11005
2025
-
[38]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. 2020. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704(2020)
Pith/arXiv arXiv 2020
-
[39]
Wei Li, CW Pan, Rong Zhang, JP Ren, YX Ma, Jin Fang, FL Yan, QC Geng, XY Huang, HJ Gong, et al. 2019. AADS: Augmented autonomous driving simulation using data-driven algorithms.Science robotics4, 28 (2019), eaaw0863
2019
-
[40]
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, and Bo Dai. 2023. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3205–3215
2023
-
[41]
Kaimin Liao, Hua Wang, Zhi Chen, Luchao Wang, and Yaohua Tang
-
[42]
arXiv:2503.01199 [cs.CV] https://arxiv.org/abs/2503.01199
LiteGS: A High-performance Framework to Train 3DGS in Sub- minutes via System and Algorithm Codesign. arXiv:2503.01199 [cs.CV] https://arxiv.org/abs/2503.01199
-
[43]
Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, Youliang Yan, et al . 2024. Vastgaussian: Vast 3d gaussians for large scene reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5166–5175
2024
-
[44]
Weikai Lin, Yu Feng, and Yuhao Zhu. 2025. Metasapiens: Real-time neu- ral rendering with efficiency-aware pruning and accelerated foveated rendering. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 669–682
2025
-
[45]
Yang Liu, Chuanchen Luo, Lue Fan, Naiyan Wang, Junran Peng, and Zhaoxiang Zhang. 2024. Citygaussian: Real-time high-quality large- scale scene rendering with gaussians. InEuropean Conference on Com- puter Vision. Springer, 265–282
2024
-
[46]
Yang Liu, Chuanchen Luo, Zhongkai Mao, Junran Peng, and Zhaoxiang Zhang. 2024. Citygaussianv2: Efficient and geometrically accurate reconstruction for large-scale scenes.arXiv preprint arXiv:2411.00771 (2024)
arXiv 2024
-
[47]
Yifei Liu, Zhihang Zhong, Yifan Zhan, Sheng Xu, and Xiao Sun. 2025. Maskgaussian: Adaptive 3d gaussian representation from probabilistic masks. InProceedings of the Computer Vision and Pattern Recognition Conference. 681–690
2025
-
[48]
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. 2024. Scaffold-gs: Structured 3d gaussians for view- adaptive rendering. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. 20654–20664
2024
-
[49]
Saswat Subhajyoti Mallick, Rahul Goel, Bernhard Kerbl, Markus Stein- berger, Francisco Vicente Carrasco, and Fernando De La Torre. 2024. Taming 3dgs: High-quality radiance fields with limited resources. In SIGGRAPH Asia 2024 Conference Papers. 1–11
2024
-
[50]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM 65, 1 (2021), 99–106
2021
-
[51]
Simon Niedermayr, Josef Stumpfegger, and Rüdiger Westermann. 2024. Compressed 3d gaussian splatting for accelerated novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10349–10358
2024
-
[52]
Changhun Oh, Seongryong Oh, Jinwoo Hwang, Yoonsung Kim, Hardik Sharma, and Jongse Park. 2026. Neo: Real-Time On-Device 3D Gauss- ian Splatting with Reuse-and-Update Sorting Acceleration. InProceed- ings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA) (ASPLOS ’26). Association...
-
[53]
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide
-
[54]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Neural scene graphs for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2856– 2865
-
[55]
Panagiotis Papantonakis, Georgios Kopanas, Bernhard Kerbl, Alexan- dre Lanvin, and George Drettakis. 2024. Reducing the memory foot- print of 3d gaussian splatting.Proceedings of the ACM on Computer Graphics and Interactive Techniques7, 1 (2024), 1–17
2024
-
[56]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
-
[57]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
-
[58]
Kerui Ren, Lihan Jiang, Tao Lu, Mulin Yu, Linning Xu, Zhangkai Ni, and Bo Dai. 2024. Octree-gs: Towards consistent real-time rendering with lod-structured 3d gaussians.arXiv preprint arXiv:2403.17898 (2024)
arXiv 2024
-
[59]
Xinkai Song, Yuanbo Wen, Xing Hu, Tianbo Liu, Haoxuan Zhou, Husheng Han, Tian Zhi, Zidong Du, Wei Li, Rui Zhang, et al . 2023. Cambricon-r: A fully fused accelerator for real-time learning of neural scene representation. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 1305–1318
2023
-
[60]
Mai Su, Zhongtao Wang, Huishan Au, Yilong Li, Xizhe Cao, Chengwei Pan, Yisong Chen, and Guoping Wang. 2025. HUG: Hierarchical Urban Gaussian Splatting with Block-Based Reconstruction for Large-Scale Aerial Scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision. 28839–28848
2025
-
[61]
Jiakai Sun, Han Jiao, Guangyuan Li, Zhanjie Zhang, Lei Zhao, and Wei Xing. 2024. 3dgstream: On-the-fly training of 3d gaussians for efficient streaming of photo-realistic free-viewpoint videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20675–20685
2024
-
[62]
Linye Wei, Jiajun Tang, Fan Fei, Boxin Shi, Runsheng Wang, and Meng Li. 2025. No Redundancy, No Stall: Lightweight Streaming 3D Gaussian Splatting for Real-time Rendering.arXiv preprint arXiv:2507.21572 (2025)
arXiv 2025
-
[63]
Lizhou Wu, Haozhe Zhu, Siqi He, Jiapei Zheng, Chixiao Chen, and Xiaoyang Zeng. 2024. GauSPU: 3D Gaussian Splatting Processor for Real-Time SLAM Systems. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1562–1573
2024
-
[64]
Haozhe Xie, Zhaoxi Chen, Fangzhou Hong, and Ziwei Liu. 2025. Gen- erative Gaussian splatting for unbounded 3D city generation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference. 6111–6120. 14 Splaxel: Efficient Distributed Training of 3D Gaussian Splatting for Large-scale Scene Reconstruction via Pixel-level Communication
2025
-
[65]
Shuzhao Xie, Jiahang Liu, Weixiang Zhang, Shijia Ge, Sicheng Pan, Chen Tang, Yunpeng Bai, and Zhi Wang. 2024. SizeGS: Size-aware Compression of 3D Gaussians with Hierarchical Mixed Precision Quantization.arXiv preprint arXiv:2412.05808(2024)
arXiv 2024
-
[66]
Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li. 2024. Gs-slam: Dense visual slam with 3d gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19595–19604
2024
-
[67]
Runyi Yang, Zhenxin Zhu, Zhou Jiang, Baijun Ye, Xiaoxue Chen, Yifei Zhang, Yuantao Chen, Jian Zhao, and Hao Zhao. 2024. Spectrally pruned gaussian fields with neural compensation.arXiv preprint arXiv:2405.00676(2024)
arXiv 2024
-
[68]
Shuangyan Yang, Minjia Zhang, Wenqian Dong, and Dong Li. 2023. Betty: Enabling large-scale gnn training with batch-level graph par- titioning. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 103–117
2023
-
[69]
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. 2024. Deformable 3d gaussians for high-fidelity monoc- ular dynamic scene reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20331–20341
2024
-
[70]
Baijun Ye, Minghui Qin, Saining Zhang, Moonjun Gong, Shaoting Zhu, Hao Zhao, and Hang Zhao. 2025. GS-Occ3D: Scaling Vision-only Occupancy Reconstruction with Gaussian Splatting. InProceedings of the IEEE/CVF International Conference on Computer Vision. 25925– 25937
2025
-
[71]
Zhifan Ye, Yonggan Fu, Jingqun Zhang, Leshu Li, Yongan Zhang, Sixu Li, Cheng Wan, Chenxi Wan, Chaojian Li, Sreemanth Prathipati, et al. 2025. Gaussian Blending Unit: An Edge GPU Plug-in for Real- Time Gaussian-Based Rendering in AR/VR. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 353–365
2025
-
[72]
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. 2024. Mip-splatting: Alias-free 3d gaussian splatting. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19447–19456
2024
-
[73]
Zehao Yu, Torsten Sattler, and Andreas Geiger. 2024. Gaussian opacity fields: Efficient adaptive surface reconstruction in unbounded scenes. ACM Transactions on Graphics (ToG)43, 6 (2024), 1–13
2024
-
[74]
Chenqi Zhang, Yu Feng, Jieru Zhao, Guangda Liu, Wenchao Ding, Chentao Wu, and Minyi Guo. 2025. StreamingGS: Voxel-Based Stream- ing 3D Gaussian Splatting with Memory Optimization and Archi- tectural Support. InProceedings of the 62nd Annual ACM/IEEE De- sign Automation Conference(San Francisco, California, United States) (DAC ’25). IEEE Press, Article 42,...
-
[75]
Optimizing-Sparsifying
Yangming Zhang, Wenqi Jia, Wei Niu, and Miao Yin. 2025. Gaus- sianSpa: An" Optimizing-Sparsifying" Simplification Framework for Compact and High-Quality 3D Gaussian Splatting. InProceedings of the Computer Vision and Pattern Recognition Conference. 26673–26682
2025
-
[76]
Ziyu Zhang, Binbin Huang, Hanqing Jiang, Liyang Zhou, Xiaojun Xi- ang, and Shuhan Shen. 2025. Quadratic Gaussian Splatting: High Qual- ity Surface Reconstruction with Second-order Geometric Primitives. InProceedings of the IEEE/CVF International Conference on Computer Vision. 28260–28270
2025
-
[77]
Zhaoliang Zhang, Tianchen Song, Yongjae Lee, Li Yang, Cheng Peng, Rama Chellappa, and Deliang Fan. 2024. Lp-3dgs: Learning to prune 3d gaussian splatting.Advances in Neural Information Processing Systems 37 (2024), 122434–122457
2024
-
[78]
Hexu Zhao, Xiwen Min, Xiaoteng Liu, Moonjun Gong, Yiming Li, Ang Li, Saining Xie, Jinyang Li, and Aurojit Panda. 2026. CLM: Removing the GPU Memory Barrier for 3D Gaussian Splatting. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(USA)(ASP- LOS ’26). Association for ...
-
[79]
Hexu Zhao, Haoyang Weng, Daohan Lu, Ang Li, Jinyang Li, Aurojit Panda, and Saining Xie. 2025. On Scaling Up 3D Gaussian Splat- ting Training. InThe Thirteenth International Conference on Learning Representations.https://openreview.net/forum?id=pQqeQpMkE7
2025
-
[80]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. 2022. Alpa: Automating inter-and {Intra-Operator} parallelism for distributed deep learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 559–578
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.