MetaboNet-Bench: A Multi-modal Benchmark for Glucose Forecasting in Type 1 Diabetes
Pith reviewed 2026-06-26 21:52 UTC · model grok-4.3
The pith
The benefit of adding data modalities to glucose forecasting depends on model complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
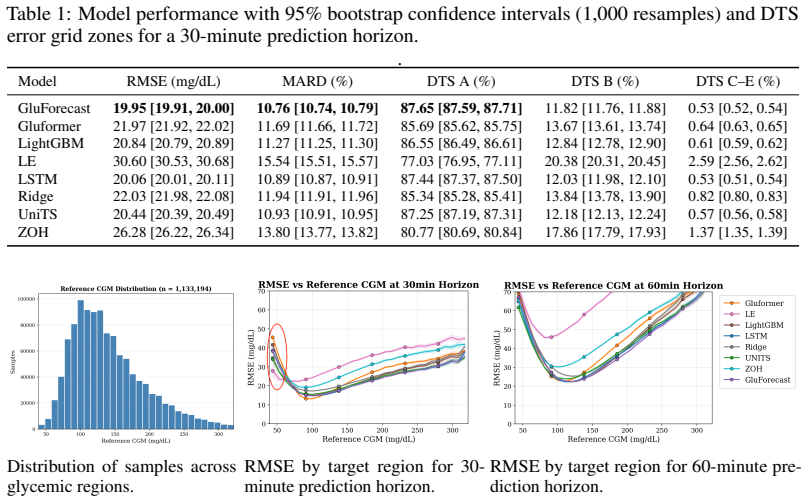
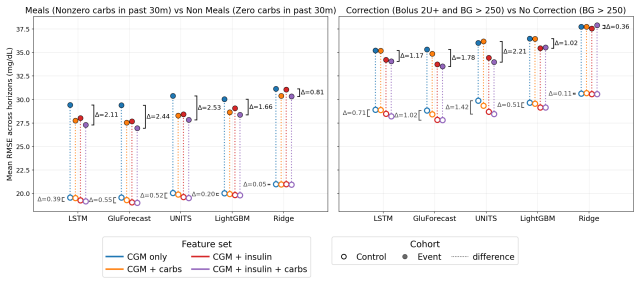
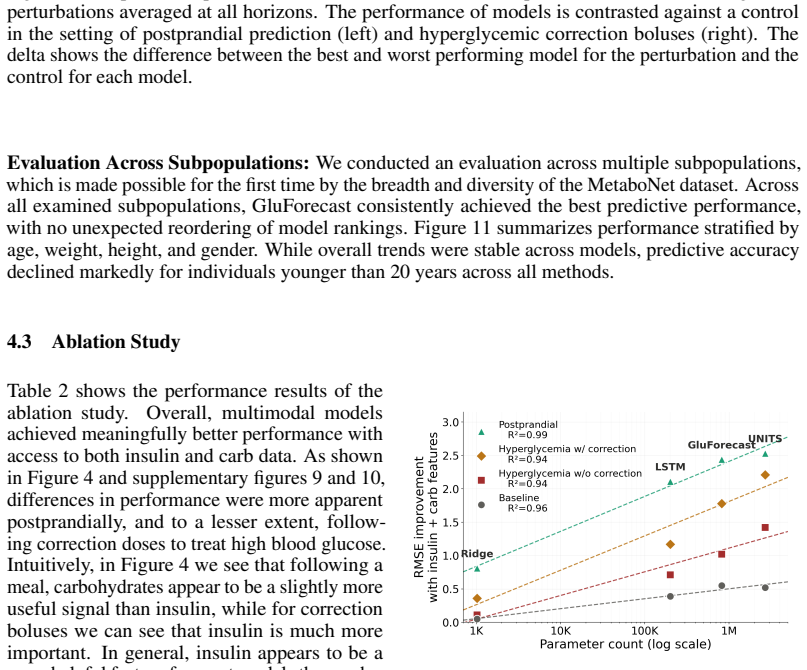
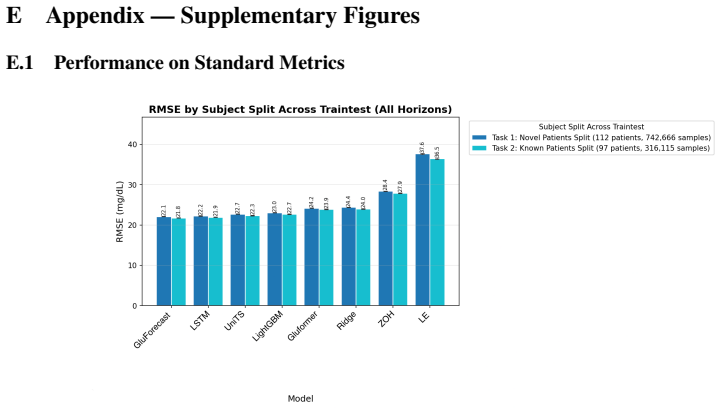
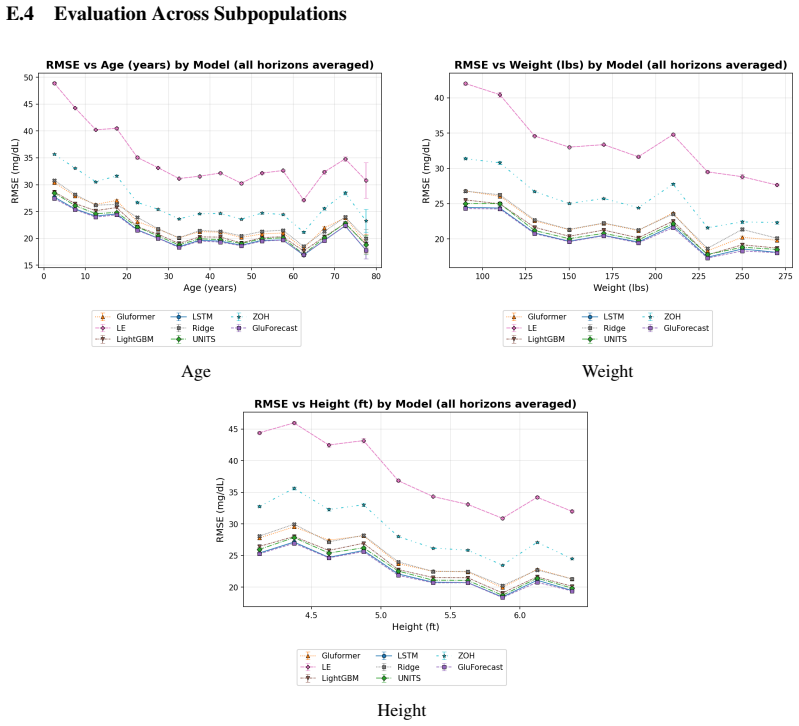
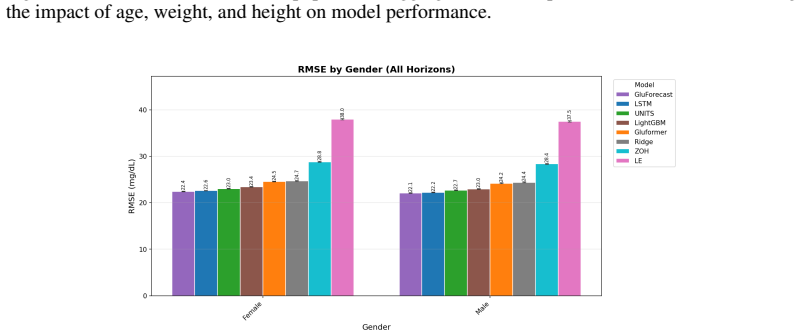
MetaboNet-Bench supplies an extensible evaluation framework for multimodal glucose forecasting. When applied to existing models and a custom architecture, it shows that gains from including insulin and carbohydrate signals are conditioned on the complexity of the underlying model, while the expanded set of clinical metrics surfaces concrete gaps that future algorithms must address.
What carries the argument
MetaboNet-Bench, an extensible open-source evaluation framework that standardizes testing of glucose forecasting models on glucose, insulin, and carbohydrate inputs.
If this is right
- Algorithms can now be compared on identical multimodal datasets rather than single-modality subsets.
- Developers can isolate whether their architecture gains from insulin or carbohydrate signals.
- Expanded clinical metrics make it easier to name specific forecasting weaknesses for targeted fixes.
Where Pith is reading between the lines
- Wider adoption of the benchmark could shift research focus from single-modality CGM models to integrated closed-loop designs.
- Testing the framework on larger, more diverse patient cohorts might expose whether modality benefits vary by individual physiology.
Load-bearing premise
The handful of recently published models and one custom model chosen for testing are representative of the wider space of glucose forecasting algorithms.
What would settle it
Re-running the benchmark on a fresh collection of models and obtaining performance gains from extra modalities that show no dependence on model complexity would falsify the central claim.
Figures


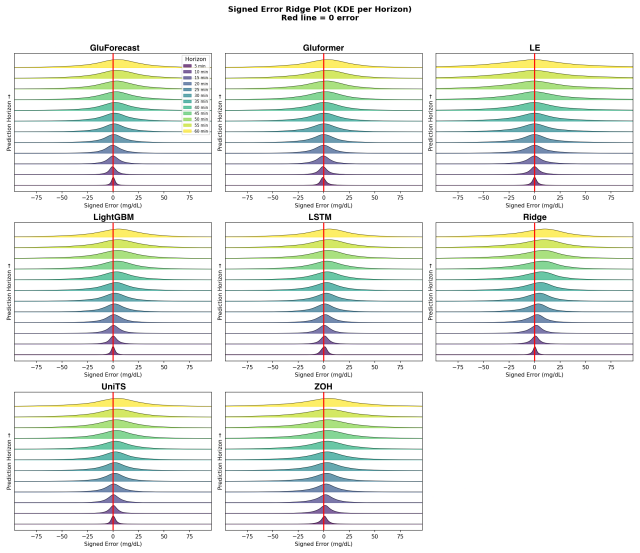
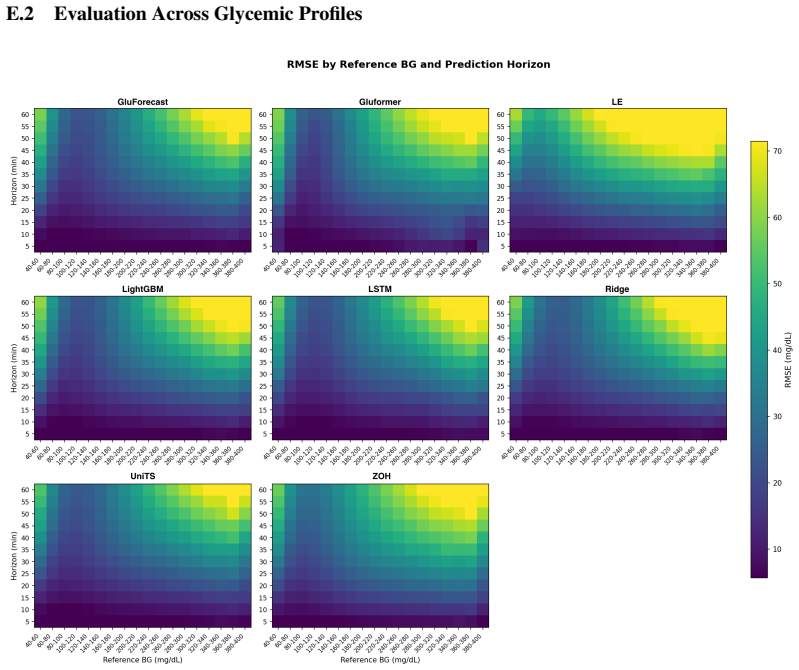
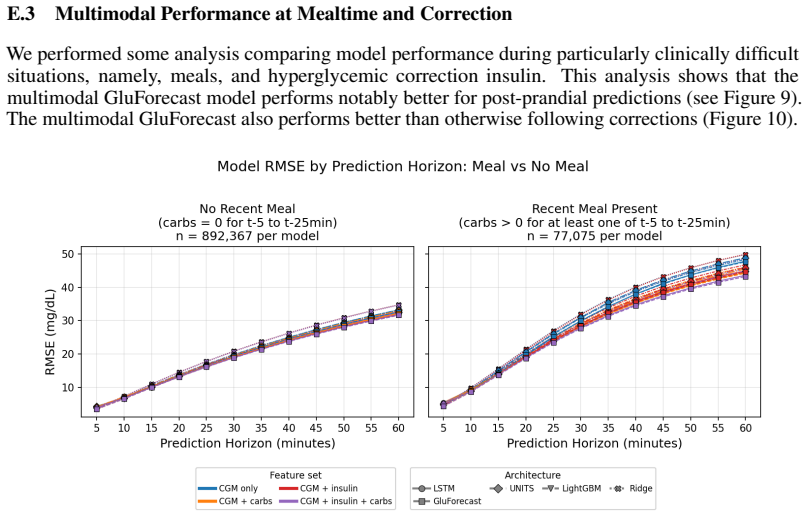
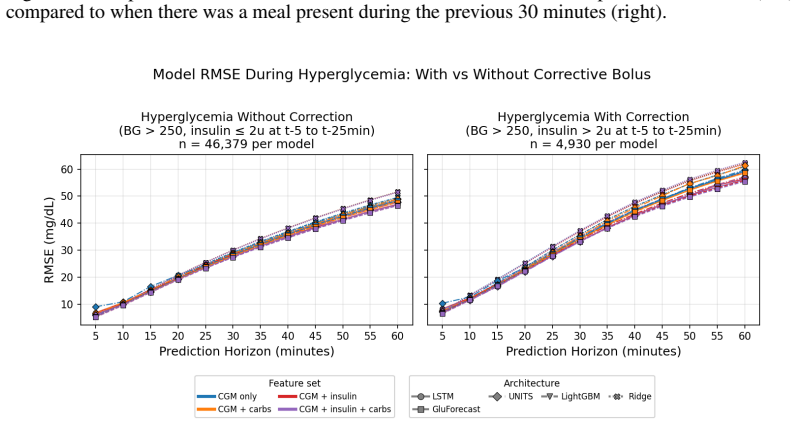
read the original abstract
Glucose forecasting algorithms are an important aspect of glycemic control management in type 1 diabetes. So far, the research community has developed numerous algorithms and models for forecasting. However, it is well-recognized that the lack of standardized model performance evaluation benchmarks makes fair comparison difficult and hinders further innovation, and thus benchmark standardization is in urgent need. Furthermore, many published glucose forecasting algorithms are limited to CGM data alone, ignoring other multimodal signals such as insulin dosing and carbohydrate intake. Here, we introduce MetaboNet-Bench, a benchmark for multimodal glucose forecasting for patients with type 1 diabetes that provides an extensible open-source evaluation framework for comparison of glucose forecasting algorithms that leverage glucose, insulin, and carbohydrate data. We then demonstrate its utility by benchmarking several recently published glucose forecasting models and a custom multimodal time-series model, representing different model architectures. The results show that the benefit of adding data modalities is conditioned on the complexity of the model and that incorporating more clinical metrics helps identify meaningful gaps to fill for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MetaboNet-Bench, an extensible open-source benchmark framework for multimodal glucose forecasting in type 1 diabetes that incorporates CGM glucose, insulin dosing, and carbohydrate intake data. It evaluates several recently published glucose forecasting models plus one custom multimodal time-series model representing different architectures, and reports that the benefit of additional modalities is conditioned on model complexity while multimodal clinical metrics help surface research gaps.
Significance. A standardized, reproducible benchmark for multimodal T1D forecasting would address a recognized gap in the literature and could facilitate fairer model comparisons. The open-source framework and emphasis on clinical metrics are constructive contributions; if the empirical claims are supported by properly controlled experiments, the work could usefully guide future multimodal modeling efforts.
major comments (2)
- [Abstract] Abstract: the claim that 'the benefit of adding data modalities is conditioned on the complexity of the model' is not supported by a controlled isolation of complexity. The evaluation compares a small set of published models plus one custom model; these differ simultaneously in architecture family, training procedure, and other factors, so any observed interaction cannot be attributed specifically to complexity rather than confounders.
- [Abstract] Abstract (and presumed Results section): no quantitative performance numbers, error bars, dataset sizes, train/test splits, or statistical tests are referenced, preventing assessment of whether the modality-benefit pattern is robust or merely descriptive.
minor comments (1)
- [Abstract] The abstract would be strengthened by a brief statement of the primary evaluation metric(s) and the number of subjects or time-series length used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims and the presentation of results. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the benefit of adding data modalities is conditioned on the complexity of the model' is not supported by a controlled isolation of complexity. The evaluation compares a small set of published models plus one custom model; these differ simultaneously in architecture family, training procedure, and other factors, so any observed interaction cannot be attributed specifically to complexity rather than confounders.
Authors: We agree that the evaluated models vary across multiple dimensions (architecture family, training procedures, hyperparameters, etc.) and that our results do not isolate model complexity through controlled ablation or matched experiments. The reported pattern is therefore an empirical observation across the selected models rather than a causal attribution to complexity alone. We will revise the abstract to state that the benefit of additional modalities 'appears to depend on model complexity in the evaluated models' and will add a limitations paragraph in the discussion section explicitly noting the presence of confounding factors and the observational nature of the finding. revision: yes
-
Referee: [Abstract] Abstract (and presumed Results section): no quantitative performance numbers, error bars, dataset sizes, train/test splits, or statistical tests are referenced, preventing assessment of whether the modality-benefit pattern is robust or merely descriptive.
Authors: The abstract is intentionally concise and summarizes the high-level contribution and key observation. The full manuscript contains the requested quantitative details (performance metrics with error bars, dataset sizes, train/test splits, and statistical comparisons) in the Results and Experimental Setup sections. To improve accessibility, we will add one or two representative quantitative highlights (e.g., key RMSE or clinical metric values) to the abstract while remaining within length limits, and we will ensure the Results section explicitly cross-references all evaluation details. revision: partial
Circularity Check
Empirical benchmark paper with no derivation chain or self-referential structure
full rationale
The paper introduces MetaboNet-Bench as an evaluation framework and reports empirical results from benchmarking published models plus one custom model on glucose, insulin, and carbohydrate data. No mathematical derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The central observation that modality benefit is conditioned on model complexity is presented as a direct outcome of the benchmark experiments rather than reducing to any input by construction. This is a standard empirical comparison study whose claims rest on external data evaluations, not internal redefinitions or citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cappon, G., Prendin, F., Facchinetti, A., Sparacino, G., and Del Favero, S. Individualized models for glucose prediction in type 1 diabetes: Comparing black-box approaches to a physiological white-box one.IEEE Transactions on Biomedical Engineering, 70(11):3105–3115, Nov 2023a. doi: 10.1109/TBME.2023.3276193. Cappon, G., Vettoretti, M., Sparacino, G., Del...
-
[2]
Deep Multi-Output Forecasting: Learning to Accurately Predict Blood Glucose Trajectories
doi: 10.48550/arXiv.1806.05357. URL https://arxiv.org/abs/1806.05357. Gao, S., Hartvigsen, T., Koker, T., Queen, O., Tsiligkaridis, T., and Zitnik, M. UniTS: A unified multi- task time series model. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Systems 37, volum...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.05357
-
[3]
doi: 10.1016/j.dib.2024.110559. eCollection 2024 Aug. Jaloli, M. and Cescon, M. Long-term prediction of blood glucose levels in type 1 diabetes using a CNN-LSTM-based deep neural network.J. Diabetes Sci. Technol., 17(6):1590–1601, November
-
[4]
URL https://www.nature.com/articles/ s41597-023-02469-5
doi: 10.1038/s41597-023-02469-5. URL https://www.nature.com/articles/ s41597-023-02469-5. Prioleau, T., Lu, B., and Cui, Y . Glucose-ml: A collection of longitudinal diabetes datasets for development of robust ai solutions
-
[5]
URL https: //arxiv.org/abs/2507.14077
doi: 10.48550/arXiv.2507.14077. URL https: //arxiv.org/abs/2507.14077. Replica Health. Metabonet data dictionary. https://metabo-net.org/data-dictionary,
-
[6]
Glu- cobench: Curated list of continuous glucose monitoring datasets with prediction benchmarks
Sergazinov, R., Chun, E., Rogovchenko, V ., Fernandes, N., Kasman, N., and Gaynanova, I. Glu- cobench: Curated list of continuous glucose monitoring datasets with prediction benchmarks. arXiv preprint arXiv:2410.05780,
-
[7]
URLhttps://doi.org/10.21105/joss.06904
doi: 10.21105/joss.06904. URLhttps://doi.org/10.21105/joss.06904. Wolff, M. K., Royston, S., Fougner, A. L., Schaathun, H. G., Steinert, M., and V olden, R. A perspective on harmonizing diabetes management datasets.Data Brief, 59(111399):111399, April 2025a. Wolff, M. K., Schaathun, H. G., Gros, S., V olden, R., Steinert, M., and Fougner, A. L. Blood gluc...
-
[8]
doi: 10.48550/arXiv.2601. 11505. URLhttps://arxiv.org/abs/2601.11505. 12 Xie, J. and Wang, Q. Benchmarking machine learning algorithms on blood glucose prediction for type i diabetes in comparison with classical time -series models.IEEE Transactions on Biomedical Engineering, 67(11):3101–3124,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601
-
[9]
URL https://pubmed.ncbi.nlm.nih.gov/32091990/
doi: 10.1109/TBME.2020.2975959. URL https://pubmed.ncbi.nlm.nih.gov/32091990/. Yang, T., Wu, R., Tao, R., Wen, S., Ma, N., Zhao, Y ., Yu, X., and Li, H. Multi-scale long short- term memory network with multi-lag structure for blood glucose prediction. InProceedings of the 5th International Workshop on Knowledge Discovery in Healthcare Data (KDH@ECAI 2020)...
-
[10]
Zisser, H., Renard, E., Kovatchev, B., Cobelli, C., Avogaro, A., Nimri, R., Magni, L., Buckingham, B
doi: 10.1038/s41597-023-01940-7. Zisser, H., Renard, E., Kovatchev, B., Cobelli, C., Avogaro, A., Nimri, R., Magni, L., Buckingham, B. A., Chase, H. P., Doyle, 3rd, F. J., Lum, J., Calhoun, P., Kollman, C., Dassau, E., Farret, A., Place, J., Breton, M., Anderson, S. M., Dalla Man, C., Del Favero, S., Bruttomesso, D., Filippi, A., Scotton, R., Phillip, M.,...
-
[11]
# Not MDI
13 A Appendix - Datasets Table 3: Overview of all datasets included in the public release of the MetaboNet dataset (Wolff et al., 2026), showing the number of subjects per dataset. The column “# Not MDI” reports the number of subjects using continuous insulin pump therapy, i.e., not treated with Multiple Daily Injections (MDI). The MetaboNet consolidated ...
2026
-
[12]
If any of these carbs are nonzero we say the sample ispostprandial
Postprandial:For a given sample, we look at the current reported carbohydrates as well as the reported carbs every 5 minutes up until 30 minutes prior to the sample. If any of these carbs are nonzero we say the sample ispostprandial. Correction Bolus:If a sample has a CGM value > 250 mg/dL and an insulin value of > 2IU for any of the intervals until 30 mi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.