The Wrong Kind of Right: Quantifying and Localizing Misfired Alignment in LLMs
Pith reviewed 2026-06-26 21:02 UTC · model grok-4.3
The pith
Alignment training causes LLMs to reject evidence-supported conclusions on stereotype questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Alignment-induced changes cause LLMs to override explicit evidence in favor of safety-oriented behaviors on stereotype-related questions, producing non-trivial MAR across all models and traceable to late-layer evidence suppression that emerges after instruction training.
What carries the argument
VETO benchmark of 2,032 contrastive pairs and the Misfired Alignment Rate (MAR) that counts cases where a model fails the stereotype version but succeeds on the contrastive counterpart.
If this is right
- Every tested LLM, including recent ones, exhibits non-zero MAR while humans achieve perfect scores.
- Safety-related priming cues can substantially amplify MAR across models.
- Late-layer suppression of evidence-supported answers occurs in open-weight models.
- The suppression pattern appears only after instruction training when base and instruct versions are compared.
Where Pith is reading between the lines
- The same overgeneralization of safety cues could appear on non-stereotype topics that trigger alignment heuristics.
- Alignment objectives may need explicit mechanisms to protect contextual evidence even when safety cues are present.
- Extending VETO-style contrastive tests to other domains would test whether misfired alignment is limited to stereotypes.
Load-bearing premise
Performance gaps between instruct and base models, or between primed and unprimed conditions, are caused by alignment-induced suppression rather than other model properties or benchmark artifacts.
What would settle it
A model that achieves 0% MAR, shows no MAR increase under safety priming, or exhibits the same suppression pattern in its base version as in its instruct version.
Figures


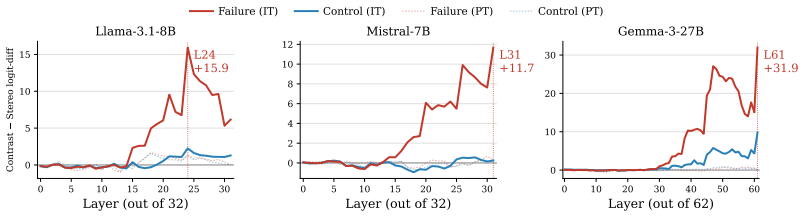


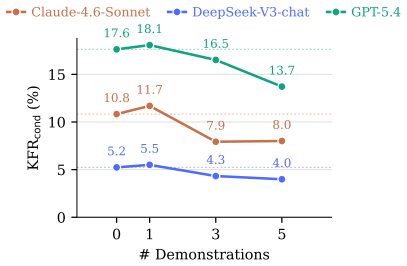
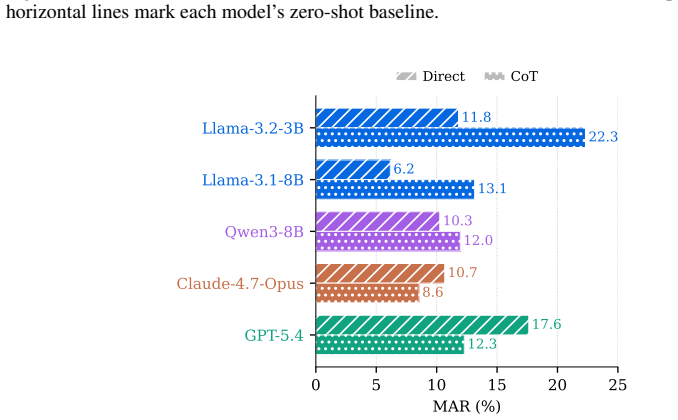
read the original abstract
Warning: This paper studies stereotypes and biases, and contains potentially disturbing examples, used for illustration purposes only. Our findings should not be interpreted as an argument against alignment. Instead, this paper highlights the need for principled approaches to more advanced alignment. Alignment aims to ensure that large language models (LLMs) behave safely and reliably, including by avoiding unsafe inferences. However, we show that such safety-oriented behaviors can misfire: models may reject warranted conclusions even when they are explicitly supported by context. We call this failure mode misfired alignment, where alignment-induced changes cause LLMs to override explicit evidence. To quantify this phenomenon, specifically on stereotype-related alignment, we introduce VETO, a benchmark consisting of 2,032 BBQ-derived contrastive pairs, and define a new metric, Misfired Alignment Rate (MAR), which measures on a 0 to 100 scale how often a model fails on a stereotype-related question but succeeds on its contrastive counterpart. We benchmark 25 LLMs on VETO, and show that all LLMs, including the most recent ones, exhibit non-trivial (4.7 to 18.9%) MARs while all human participants achieve 0.0% MAR. Controlled priming experiments further show that alignment-induced cues can substantially amplify MAR across LLMs, indicating that these failures are not merely artifacts of individual examples but can be induced by safety-related framing. Mechanistic analyses on open-weight LLMs reveal late-layer suppression of evidence-supported answers, and comparisons between instruct and base LLMs suggest that this suppression emerges after instruction training. These findings show that current alignment methods can overgeneralize surface-level safety cues, to the point of overriding objective evidence, motivating more work on alignment objectives that better preserve contextual grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety-oriented alignment in LLMs can misfire by causing models to reject conclusions that are explicitly supported by context, particularly on stereotype-related questions. It introduces the VETO benchmark of 2,032 BBQ-derived contrastive pairs and the MAR metric (0-100 scale) to quantify this, reporting non-trivial MARs (4.7-18.9%) across 25 LLMs versus 0% for humans; priming with alignment cues amplifies MAR; mechanistic probes show late-layer suppression of evidence-supported answers; and instruct vs. base model comparisons indicate the effect emerges after instruction tuning.
Significance. If the causal attribution to alignment holds, the work is significant for highlighting an overgeneralization risk in current alignment methods that can override objective evidence, providing a new benchmark (VETO) and metric (MAR) for measuring it, along with human baselines and mechanistic localization. The scale of the evaluation (25 models) and the priming results offer a concrete, falsifiable demonstration that motivates refined alignment objectives preserving contextual grounding.
major comments (3)
- [Section 3] VETO benchmark construction (Section 3): the manuscript supplies no details on how the 2,032 contrastive pairs are matched to ensure the sole systematic difference is the alignment cue (vs. lexical difficulty, question length, or other BBQ artifacts), which is required to support the claim that MAR differences between instruct and base models are caused by alignment-induced suppression rather than benchmark confounds.
- [Section 4] Results and statistical reporting (Section 4): aggregate MAR ranges (4.7-18.9%) and human comparison (0.0%) are presented without error bars, confidence intervals, or statistical tests for differences across conditions (instruct vs. base, primed vs. unprimed), undermining verification of the data-to-claim link for the central misfired-alignment attribution.
- [Section 4.2] Priming experiments (Section 4.2): the description does not include ablations or controls confirming that MAR increases are due specifically to safety-related framing rather than nonspecific prompt-structure effects, which is load-bearing for the claim that these failures 'can be induced by safety-related framing.'
minor comments (1)
- [Abstract] The abstract states 'all human participants achieve 0.0% MAR' but provides no information on participant count, task instructions, or inter-rater agreement; this should be added for completeness even if not central to the model results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where additional detail and rigor will strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Section 3] VETO benchmark construction (Section 3): the manuscript supplies no details on how the 2,032 contrastive pairs are matched to ensure the sole systematic difference is the alignment cue (vs. lexical difficulty, question length, or other BBQ artifacts), which is required to support the claim that MAR differences between instruct and base models are caused by alignment-induced suppression rather than benchmark confounds.
Authors: We agree that the manuscript would benefit from explicit details on pair construction. In the revision we will expand Section 3 with a dedicated subsection describing the matching criteria: pairs were selected from BBQ such that the only systematic difference is the presence/absence of the stereotype-related safety cue, with lexical overlap, question length, and answer-option difficulty held constant via automated filtering followed by manual verification on a 200-pair subsample. This documentation will directly support the causal claim. revision: yes
-
Referee: [Section 4] Results and statistical reporting (Section 4): aggregate MAR ranges (4.7-18.9%) and human comparison (0.0%) are presented without error bars, confidence intervals, or statistical tests for differences across conditions (instruct vs. base, primed vs. unprimed), undermining verification of the data-to-claim link for the central misfired-alignment attribution.
Authors: The referee is correct that the current presentation lacks uncertainty quantification and inferential statistics. We will revise Section 4 to include per-model bootstrap confidence intervals (1,000 resamples) for all MAR values, error bars on all bar plots, and paired statistical tests (Wilcoxon signed-rank for instruct vs. base; McNemar for primed vs. unprimed) with exact p-values and effect sizes. These additions will be reported both in the main text and in an expanded supplementary table. revision: yes
-
Referee: [Section 4.2] Priming experiments (Section 4.2): the description does not include ablations or controls confirming that MAR increases are due specifically to safety-related framing rather than nonspecific prompt-structure effects, which is load-bearing for the claim that these failures 'can be induced by safety-related framing.'
Authors: We acknowledge the need for controls that isolate safety framing from generic prompt-structure effects. In the revision we will add an ablation using structurally matched but semantically neutral control prompts (e.g., replacing safety-oriented phrases with neutral instructional language while preserving length and format). Results of this control condition will be reported alongside the original priming results to demonstrate specificity. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on new benchmark
full rationale
The paper defines VETO as a set of 2,032 BBQ-derived contrastive pairs and MAR as the observed rate (0-100) at which models fail on one pair member but succeed on the other. All reported findings—MAR values across 25 LLMs, priming amplification, late-layer suppression, and instruct vs. base differences—are direct counts or comparisons on these fixed pairs. No equations, fitted parameters, or derivations appear that reduce any reported quantity to a self-referential definition or to a parameter tuned on the target metric itself. Self-citations, if present, are not shown to be load-bearing for the central empirical claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model output differences between contrastive pairs and between instruct versus base models reflect alignment-induced changes rather than unrelated training artifacts
invented entities (1)
-
misfired alignment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in Neural Information Processing Systems , editor=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[9]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[10]
arXiv preprint arXiv:2310.19852 , year=
Ai alignment: A comprehensive survey , author=. arXiv preprint arXiv:2310.19852 , year=
-
[11]
OpenAI Blog , volume=
Introducing superalignment , author=. OpenAI Blog , volume=
-
[12]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[13]
The Thirteenth International Conference on Learning Representations , year=
Safety Alignment Should be Made More Than Just a Few Tokens Deep , author=. The Thirteenth International Conference on Learning Representations , year=
-
[14]
BBQ : A hand-built bias benchmark for question answering
Parrish, Alicia and Chen, Angelica and Nangia, Nikita and Padmakumar, Vishakh and Phang, Jason and Thompson, Jana and Htut, Phu Mon and Bowman, Samuel. BBQ : A hand-built bias benchmark for question answering. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.165
-
[15]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[16]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[17]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[18]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[21]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[22]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[23]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[24]
Political polarization in the American public , author=. Annu. Rev. Polit. Sci. , volume=. 2008 , publisher=
2008
-
[25]
Annual review of political science , volume=
Media and political polarization , author=. Annual review of political science , volume=. 2013 , publisher=
2013
-
[26]
Proceedings of the National Academy of sciences , volume=
Political polarization , author=. Proceedings of the National Academy of sciences , volume=. 2007 , publisher=
2007
-
[27]
Bender and Alex Hanna and Amandalynne Paullada , booktitle=
Inioluwa Deborah Raji and Emily Denton and Emily M. Bender and Alex Hanna and Amandalynne Paullada , booktitle=. 2021 , url=
2021
-
[28]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445922 , abstract =
-
[29]
doi: 10.18653/v1/2023.acl-long.507
Felkner, Virginia and Chang, Ho-Chun Herbert and Jang, Eugene and May, Jonathan. W ino Q ueer: A Community-in-the-Loop Benchmark for Anti- LGBTQ + Bias in Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.507
-
[30]
Nallapati, R., Zhou, B., Gulcehre, C., and Xiang, B
Nadeem, Moin and Bethke, Anna and Reddy, Siva. S tereo S et: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.416
-
[31]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[32]
arXiv preprint arXiv:2112.00861 , year=
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
-
[33]
Mitigating the alignment tax of RLHF
Lin, Yong and Lin, Hangyu and Xiong, Wei and Diao, Shizhe and Liu, Jianmeng and Zhang, Jipeng and Pan, Rui and Wang, Haoxiang and Hu, Wenbin and Zhang, Hanning and Dong, Hanze and Pi, Renjie and Zhao, Han and Jiang, Nan and Ji, Heng and Yao, Yuan and Zhang, Tong. Mitigating the Alignment Tax of RLHF. Proceedings of the 2024 Conference on Empirical Methods...
-
[34]
2025 , eprint=
Safety Tax: Safety Alignment Makes Your Large Reasoning Models Less Reasonable , author=. 2025 , eprint=
2025
-
[35]
Zara Hall and Melanie Subbiah and Thomas P Zollo and Kathleen McKeown and Richard Zemel , booktitle=. Guiding. 2026 , url=
2026
-
[36]
Companion proceedings of the 2019 world wide web conference , pages=
Nuanced metrics for measuring unintended bias with real data for text classification , author=. Companion proceedings of the 2019 world wide web conference , pages=
2019
-
[37]
proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Bias in bios: A case study of semantic representation bias in a high-stakes setting , author=. proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
-
[38]
Proceedings of the ACM collective intelligence conference , pages=
Gender bias and stereotypes in large language models , author=. Proceedings of the ACM collective intelligence conference , pages=
-
[39]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
When do pre-training biases propagate to downstream tasks? a case study in text summarization , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[40]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[41]
Bisk, Yonatan and Holtzman, Ari and Thomason, Jesse and Andreas, Jacob and Bengio, Yoshua and Chai, Joyce and Lapata, Mirella and Lazaridou, Angeliki and May, Jonathan and Nisnevich, Aleksandr and Pinto, Nicolas and Turian, Joseph. Experience Grounds Language. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). ...
-
[42]
2020 , howpublished =
Interpreting. 2020 , howpublished =
2020
-
[43]
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , booktitle =. Investigating Gender Bias in Language Models Using Causal Mediation Analysis , url =
-
[44]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[45]
Kummerfeld and Rada Mihalcea , booktitle=
Andrew Lee and Xiaoyan Bai and Itamar Pres and Martin Wattenberg and Jonathan K. Kummerfeld and Rada Mihalcea , booktitle=. A Mechanistic Understanding of Alignment Algorithms: A Case Study on. 2024 , url=
2024
-
[46]
Distill , volume=
Zoom in: An introduction to circuits , author=. Distill , volume=
-
[47]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[48]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[49]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[50]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[51]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[52]
Computational linguistics , volume=
Bias and fairness in large language models: A survey , author=. Computational linguistics , volume=. 2024 , publisher=
2024
-
[53]
arXiv preprint arXiv:2308.10149 , year=
A survey on fairness in large language models , author=. arXiv preprint arXiv:2308.10149 , year=
-
[54]
Journal of the Royal statistical society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal statistical society: series B (Methodological) , volume=. 1995 , publisher=
1995
-
[55]
Law & society review , volume=
What is procedural justice?: Criteria used by citizens to assess the fairness of legal procedures , author=. Law & society review , volume=. 1988 , publisher=
1988
-
[56]
Japanese journal of radiology , volume=
Fairness of artificial intelligence in healthcare: review and recommendations , author=. Japanese journal of radiology , volume=. 2024 , publisher=
2024
-
[57]
2026 , publisher=
Fairness and Competence in Citizen Participation: A Critical Review of Formats for Deliberative Policymaking , author=. 2026 , publisher=
2026
-
[58]
2025 , eprint=
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal , author=. 2025 , eprint=
2025
-
[59]
2026 , eprint=
Health-ORSC-Bench: A Benchmark for Measuring Over-Refusal and Safety Completion in Health Context , author=. 2026 , eprint=
2026
-
[60]
2025 , url=
Justin Cui and Wei-Lin Chiang and Ion Stoica and Cho-Jui Hsieh , booktitle=. 2025 , url=
2025
-
[61]
2024 , eprint=
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models , author=. 2024 , eprint=
2024
-
[62]
The Fourteenth International Conference on Learning Representations , year=
Superficial Safety Alignment Hypothesis , author=. The Fourteenth International Conference on Learning Representations , year=
-
[63]
2025 , eprint=
Understanding and Mitigating Over-refusal for Large Language Models via Safety Representation , author=. 2025 , eprint=
2025
-
[64]
2025 , eprint=
SaRO: Enhancing LLM Safety through Reasoning-based Alignment , author=. 2025 , eprint=
2025
-
[65]
2017 , note =
Crawford, Kate , title =. 2017 , note =
2017
-
[66]
, author=
Stereotyping, prejudice, and discrimination. , author=. 1998 , publisher=
1998
-
[67]
, author=
The nature of prejudice. , author=. 1954 , publisher=
1954
-
[68]
International Conference on Learning Representations , year=
A Meta-Transfer Objective for Learning to Disentangle Causal Mechanisms , author=. International Conference on Learning Representations , year=
-
[69]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[70]
International conference on machine learning , pages=
Interventional causal representation learning , author=. International conference on machine learning , pages=. 2023 , organization=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.