RegMix-D: Dynamic Data Mixing via Proxy Training Trajectories
Pith reviewed 2026-06-26 20:59 UTC · model grok-4.3
The pith
Loss trajectories from small proxy models enable dynamic data mixing that outperforms static mixtures for LLM pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
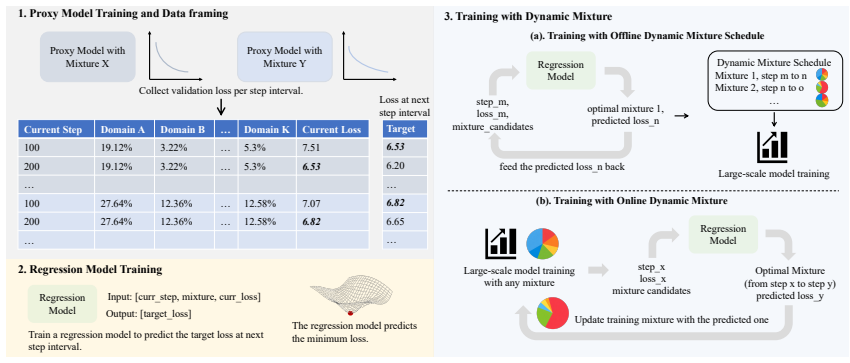
RegMix-D trains a regression model on the complete loss trajectories observed in small proxy runs, rather than endpoint losses alone. This model then predicts the data mixture that minimizes loss at each stage of target-model training. The approach supports an offline mode that outputs a full schedule before target training begins and an online mode that adjusts the mixture on the fly using observed losses. On the Pile dataset with a 1B target model, the resulting schedules improve downstream performance over both the static RegMix baseline and DoReMi while requiring only 25 percent of the proxy compute budget used by RegMix.
What carries the argument
Regression model trained on proxy loss trajectories to predict stage-specific optimal data mixtures.
If this is right
- Dynamic mixtures yield higher downstream accuracy than a single static mixture chosen from the same proxies.
- The method remains proxy-efficient, delivering gains even when the number of proxy runs is cut to 25 percent of the static baseline budget.
- Both a fixed schedule computed in advance and an adaptive schedule updated during target training are viable.
- The same regression-on-trajectories idea extends the original RegMix framework from one-time selection to time-varying selection.
Where Pith is reading between the lines
- Trajectory-based regression could be applied to other training decisions such as learning-rate schedules or model-size scaling.
- If proxy trajectories remain predictive across model scales, the approach might shrink the compute needed for hyperparameter search in general.
- Online adaptation could serve as a safeguard that corrects an initial mixture once early target losses deviate from proxy predictions.
- Splitting trajectories into finer-grained stages or predicting continuous mixture weights might further tighten the schedule.
Load-bearing premise
Loss trajectories seen on small proxy models are sufficiently predictive of the loss surface that the same mixtures will produce on a large target model at corresponding stages.
What would settle it
Run a large target model with the dynamic mixture schedule predicted from proxy trajectories and compare its downstream scores to a model trained with the static mixture from the same proxies; absence of improvement or lack of correlation between proxy and target trajectories would falsify the claim.
Figures
read the original abstract
Data mixture selection is critical for Large Language Model pretraining. Existing methods such as RegMix select a single static mixture by fitting a regression model on small-scale proxy runs. We propose RegMix-D, a simple extension of RegMix to dynamic mixing. Our key observation is that proxy runs produce not only endpoint losses, but also full loss trajectories, which can be used to further improve data mixture. By training regression model on these trajectories, we can predict optimal mixtures at multiple training stages. RegMix-D supports two deployment modes: an offline variant that generates a complete mixture schedule before target training, and an online variant that adapts the mixture during training using observed loss. Experiments on 25B tokens of the Pile dataset with a 1B parameter target model show that RegMix-D consistently improves over RegMix and DoReMi across 13 downstream tasks while remaining proxy-efficient: it surpasses RegMix even with only 128 proxy models (25% of RegMix's proxy compute budget).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RegMix-D as a dynamic extension of RegMix for LLM pretraining data mixture selection. It trains regression models on full loss trajectories (rather than endpoint losses) from small proxy runs to predict time-varying optimal mixtures at multiple training stages. The method offers offline (precomputed schedule) and online (adaptive during target training) modes. Experiments train a 1B target model on 25B tokens from the Pile and report consistent gains over RegMix and DoReMi across 13 downstream tasks while using only 25% of RegMix's proxy compute budget (128 proxy models).
Significance. If the proxy-to-target trajectory transfer holds, RegMix-D would provide a practical route to dynamic data mixing that improves downstream performance with substantially lower proxy overhead than static regression baselines. The proxy-efficiency result and the use of trajectory information rather than single-point losses are the primary contributions.
major comments (3)
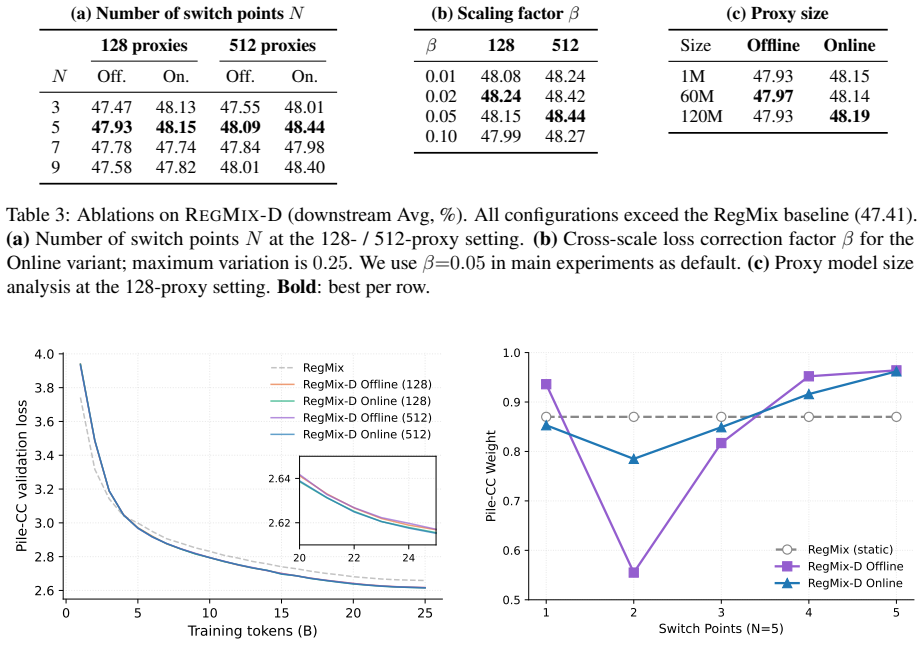
- [Abstract / Experiments] Abstract and Experiments: The central claim that proxy-derived dynamic mixtures improve over RegMix relies on the untested assumption that loss trajectories observed on small proxies are sufficiently predictive of the loss surface experienced by the 1B target at corresponding token counts. No ablation or scaling check measuring prediction error or schedule fidelity between proxy and target is reported.
- [Method] Method: The regression model choice, feature construction from trajectories, and how targets are defined at multiple stages are not described. Without these details it is impossible to assess whether the reported gains are robust or sensitive to modeling decisions.
- [Experiments] Experiments: The claim of consistent gains "across 13 downstream tasks" and the proxy-efficiency comparison (128 vs. RegMix's budget) lack reported statistical significance tests, variance across runs, or controls for multiple testing, weakening the strength of the empirical conclusion.
minor comments (1)
- [Method] The distinction between offline and online deployment modes is described at a high level; a concrete pseudocode or diagram would clarify how the online mode uses observed loss to adapt the regressor output.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, indicating where we agree revisions are needed and what changes will be made in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The central claim that proxy-derived dynamic mixtures improve over RegMix relies on the untested assumption that loss trajectories observed on small proxies are sufficiently predictive of the loss surface experienced by the 1B target at corresponding token counts. No ablation or scaling check measuring prediction error or schedule fidelity between proxy and target is reported.
Authors: We agree that the manuscript does not include an explicit ablation or scaling study that directly measures prediction error or schedule fidelity between proxy trajectories and the 1B target. The reported gains on the target model provide indirect support for the transfer, but this does not substitute for a direct check. In the revised version we will add an analysis (new subsection or appendix) that evaluates proxy-target fidelity, for example by comparing mixtures predicted from proxies against those that would be optimal on partial target runs or additional proxy scales. This addresses the concern while preserving the core empirical results. revision: yes
-
Referee: [Method] Method: The regression model choice, feature construction from trajectories, and how targets are defined at multiple stages are not described. Without these details it is impossible to assess whether the reported gains are robust or sensitive to modeling decisions.
Authors: The referee correctly identifies that the Method section omits key implementation details. We will expand this section to specify the regression model (including type and hyperparameters), the exact feature construction process from loss trajectories (e.g., which time points or summary statistics are used), and the procedure for defining targets at multiple training stages. These additions will allow assessment of robustness and will be placed in the main text or a dedicated subsection. revision: yes
-
Referee: [Experiments] Experiments: The claim of consistent gains "across 13 downstream tasks" and the proxy-efficiency comparison (128 vs. RegMix's budget) lack reported statistical significance tests, variance across runs, or controls for multiple testing, weakening the strength of the empirical conclusion.
Authors: We acknowledge the absence of statistical significance tests, run-to-run variance, and multiple-testing controls in the current Experiments section. In the revision we will add error bars or standard deviations (where multiple runs exist), perform appropriate significance tests on the downstream improvements, and apply a correction for multiple comparisons. The proxy-efficiency comparison will be clarified with explicit compute accounting. Full variance reporting on all 1B runs may be limited by compute cost, so we will note this limitation and supplement with proxy-run statistics where possible. revision: partial
Circularity Check
No significant circularity; derivation uses independent proxy data for regression
full rationale
The paper's core method trains a regression model on full loss trajectories obtained from independent small-scale proxy runs, then applies the resulting model to predict time-varying mixtures for the target. This is a standard predictive pipeline with no self-definitional loop, no renaming of fitted quantities as predictions, and no load-bearing self-citation chain. Proxy trajectories serve as external training inputs rather than being derived from the target or the regressor itself. Both offline schedule generation and online adaptation initialize from this proxy-trained regressor without closing any loop back to the target losses. The experimental claims rest on downstream task improvements rather than any tautological equivalence between inputs and outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question an- swering? try arc, the ai2 reasoning challenge.ArXiv, abs/1803.05457. Simin Fan, Matteo Pagliardini, and Martin Jaggi
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Maximize your data’s po- tential: Enhancing llm accuracy with two-phase pre- training.Preprint, arXiv:2412.15285. Leo Gao, Stella Biderman, Sid Black, Laurence Gold- ing, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy
-
[3]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The pile: An 800gb dataset of diverse text for language modeling. Preprint, arXiv:2101.00027. Leo Gao, Jonathan Tow, Baber Abbasi, Stella Bider- man, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Sk...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Scaling Laws for Neural Language Models
Scaling laws for neural language models.Preprint, arXiv:2001.08361. Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[5]
Looking beyond the surface: A challenge set for reading com- prehension over multiple sentences. InProceedings of the 2018 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Pa- pers), pages 252–262, New Orleans, Louisiana. As- sociation for Computational Linguistics. Gu...
2018
-
[6]
In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785– 794, Copenhagen, Denmark
RACE: Large-scale ReAd- ing comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785– 794, Copenhagen, Denmark. Association for Compu- tational Linguistics. Shengrui Li, Fei Zhao, Kaiyan Zhao, Jieying Ye, Haifeng Liu, Fangcheng Shi, Zheyong Xie, Yao Hu, and Shaosheng Cao
2017
-
[7]
Decouple searching from training: Scaling data mixing via model merging for large language model pre-training.arXiv preprint arXiv:2602.00747. Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Logiqa: A chal- lenge dataset for machine reading comprehension with logical reasoning.Preprint, arXiv:2007.08124. Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guang- tao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin
-
[9]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal
Actor- critic based online data mixing for language model pre-training.Preprint, arXiv:2505.23878. Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal
-
[10]
Mid-training of large language models: A survey. Preprint, arXiv:2510.06826. Yonatan Oren, Shiori Sagawa, Tatsunori B. Hashimoto, and Percy Liang
-
[11]
Distributionally robust lan- guage modeling. InProceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4227–4237, Hong Kong, China. Association for Computational Linguistics. Denis Paperno, Germán Kruszewski, Angeliki Lazari- ...
2019
-
[12]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Winogrande: An ad- versarial winograd schema challenge at scale.arXiv preprint arXiv:1907.10641. Paul-Edouard Sarlin, Daniel DeTone, Tomasz Mal- isiewicz, and Andrew Rabinovich
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[13]
InProceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium
GLUE: A multi-task benchmark and analysis platform for nat- ural language understanding. InProceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Com- putational Linguistics. Jiapeng Wang, Changxin Tian, Kunlong Chen, Ziqi Liu, Jiaxin Mao, Wayne Xin Zhao, Zh...
2018
-
[14]
Mergemix: Optimizing mid-training data mixtures via learnable model merging.Preprint, arXiv:2601.17858. Yifan Wang, Binbin Liu, Fengze Liu, Yuanfan Guo, Jiyao Deng, Xuecheng Wu, Weidong Zhou, Xiao- huan Zhou, and Taifeng Wang
-
[15]
Tikmix: Take data influence into dynamic mixture for language model pre-training.Preprint, arXiv:2508.17677. Johannes Welbl, Nelson F. Liu, and Matt Gardner
-
[16]
TinyLlama: An Open-Source Small Language Model
Tinyllama: An open-source small language model.Preprint, arXiv:2401.02385. A Appendix A.1 Implementation Details The hyperparameters we used are: AdamW opti- mizer (Loshchilov and Hutter,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proxy models are trained on 1 H800 GPU for 1,000 steps (1M tokens per step) and the target model is trained on 8 GPUs for 25,000 steps, totaling 25B tokens
with weight decay 0.1, learning rate 4e-4, context length 2048, and global batch size 512 (achieved via gradient ac- cumulation). Proxy models are trained on 1 H800 GPU for 1,000 steps (1M tokens per step) and the target model is trained on 8 GPUs for 25,000 steps, totaling 25B tokens. Human stands for the original Pile token distribution. The adjusted 17...
2048
-
[18]
We use the Pile-CC validation loss as the target predicted loss
as the regres- sion model, matching the choice in RegMix. We use the Pile-CC validation loss as the target predicted loss. Predictions over candidate mixtures are made by Dirichlet sampling 100K candidates and averaging the top-128 lowest predicted valida- tion loss. The full list of our evaluated tasks: Hel- laSwag (Zellers et al., 2019), PIQA (Bisk et a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.