Image Prompt Reconstruction Attacks on Distributed MLLM Inference Frameworks
Pith reviewed 2026-06-26 20:42 UTC · model grok-4.3
The pith
Intermediate embeddings in distributed MLLM inference frameworks leak enough information to reconstruct input images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
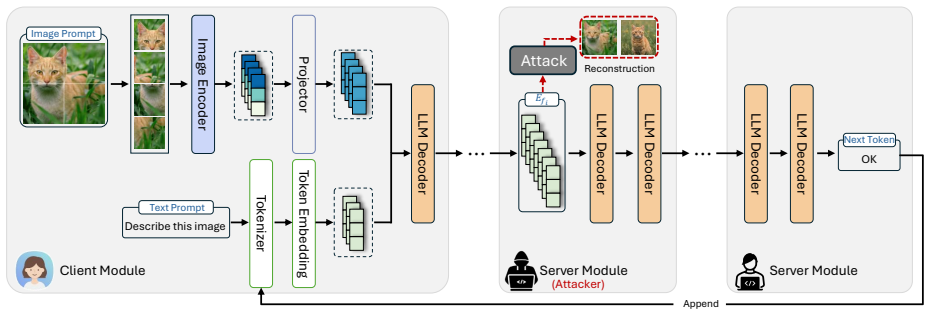
The central discovery is that an image embedding extraction algorithm can isolate visual information with 100% accuracy in nearly all layers of MLLMs, enabling two passive black-box attacks—MPAA for patch-wise pixel reconstruction and IEDA for diffusion-based semantic reconstruction—from intermediate embeddings shared among participants.
What carries the argument
The image embedding extraction algorithm, which serves as the prerequisite for separating image information from intertwined text-image embeddings across MLLM layers.
Load-bearing premise
The intermediate embeddings transmitted in distributed MLLM frameworks contain sufficient recoverable information about the input image to allow reconstruction by a passive participant.
What would settle it
A test in which the image embedding extraction algorithm fails to achieve high accuracy or the reconstruction attacks produce outputs no better than random guesses on real distributed MLLM runs.
Figures








read the original abstract
Distributed large language model (LLM) inference frameworks connect isolated consumer-grade devices for large-scale model inference, substantially reducing hardware constraints. However, recent studies show that intermediate embeddings transmitted among participants can leak private prompts. As LLMs evolve into multimodal LLMs (MLLMs), this risk extends beyond text: image prompts contain rich visual and semantic information, making their intermediate embeddings highly privacy-sensitive. Yet, image-prompt leakage in distributed MLLM inference remains largely unexplored. In this paper, we investigate privacy risks to input images caused by intermediate embeddings in distributed MLLM frameworks. We first analyze the information flow from image pixels to intermediate representations. Since image and text embeddings are often intertwined across MLLM layers, we design an image embedding extraction algorithm as a prerequisite for reconstruction attacks, achieving 100% extraction accuracy across almost all MLLM layers in our experiments. Building on this, we develop two passive black-box image reconstruction attacks, MPAA and IEDA, reflecting realistic threats from normal participants with limited knowledge and capability. MPAA performs fine-grained pixel-level reconstruction via patch-wise information extraction and assembly, while IEDA performs coarse-grained semantic reconstruction through embedding-guided diffusion generation. We evaluate our attacks on four representative MLLM families: Gemma 3, Phi 4 Multimodal, Qwen 2.5 VL, and Llama 4 Scout. Results show consistently superior reconstruction performance in various settings. We further analyze the effects of MoE architecture, image preprocessing, model size, and text-image dependency on attack performance. To our knowledge, this is the first study of image reconstruction attacks on MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
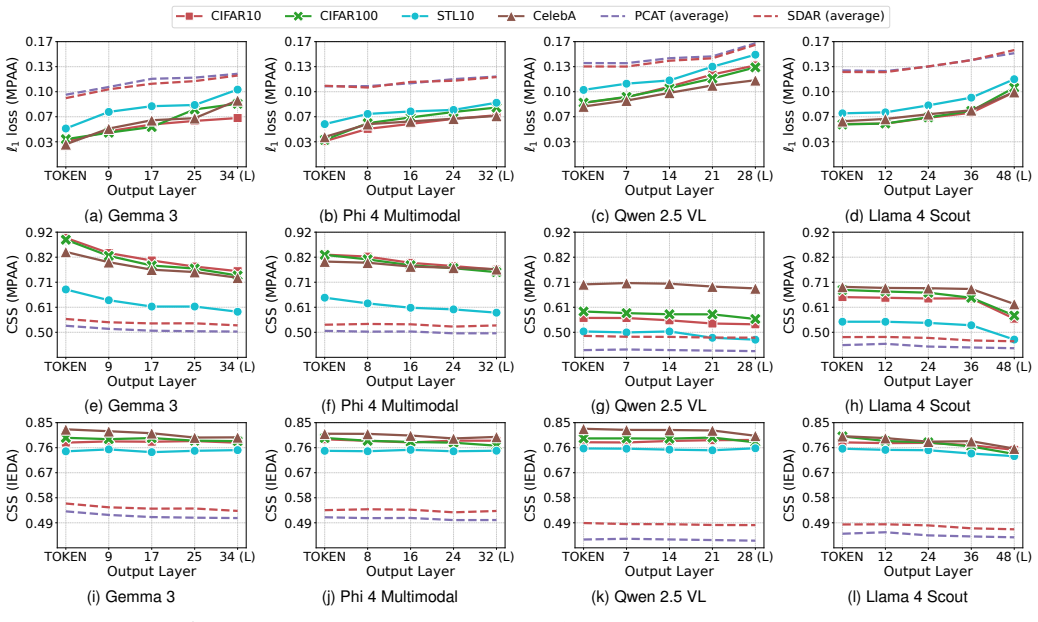
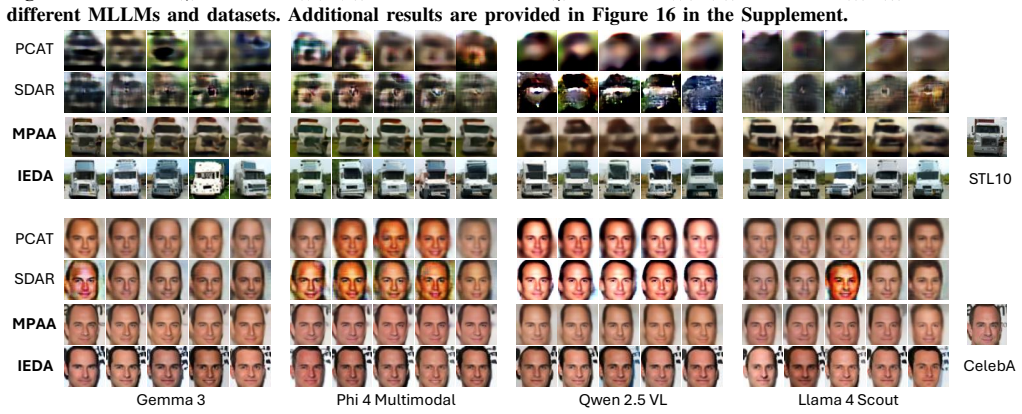
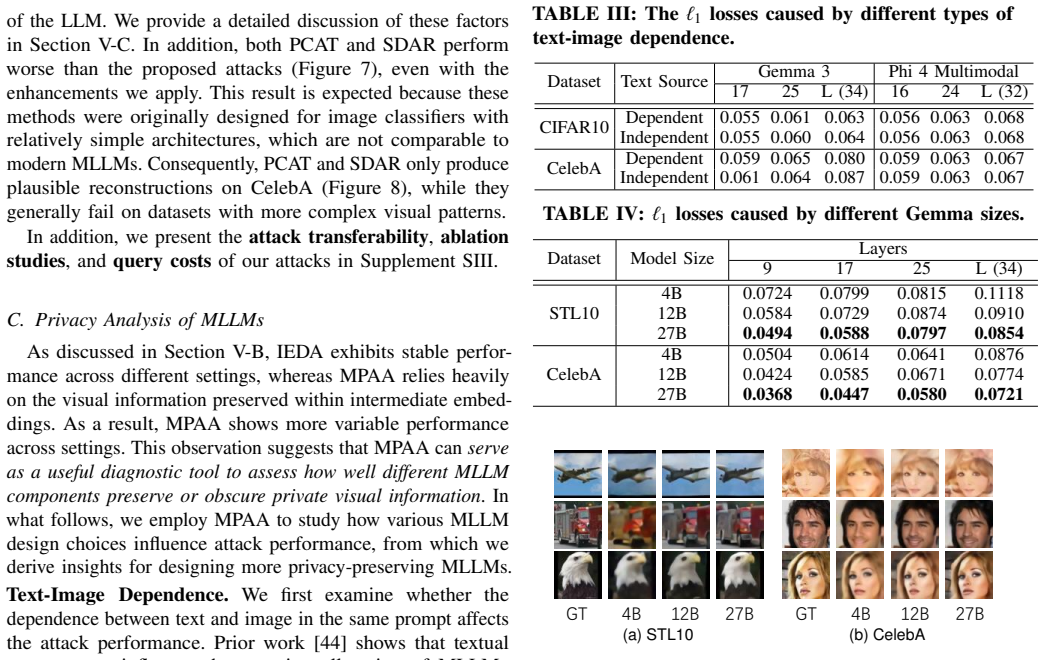
Summary. The manuscript investigates privacy risks to image prompts in distributed MLLM inference frameworks arising from transmitted intermediate embeddings. It introduces an image embedding extraction algorithm claimed to achieve 100% accuracy across almost all layers of four MLLM families (Gemma 3, Phi 4 Multimodal, Qwen 2.5 VL, Llama 4 Scout), then builds two passive black-box attacks—MPAA for fine-grained pixel-level reconstruction via patch-wise extraction and IEDA for coarse-grained semantic reconstruction via embedding-guided diffusion—reporting superior performance over baselines while analyzing effects of MoE, preprocessing, model size, and text-image dependency.
Significance. If the extraction algorithm and attacks can be realized strictly within the stated passive black-box threat model (normal participants with limited knowledge and capability), the work would constitute the first systematic study of image-prompt reconstruction in distributed MLLMs and would usefully extend prior text-prompt leakage results to the multimodal setting, with direct implications for the security of consumer-grade distributed inference systems.
major comments (2)
- [Abstract] Abstract: the central prerequisite claim of an image embedding extraction algorithm achieving 100% accuracy 'across almost all MLLM layers' is load-bearing for both MPAA and IEDA, yet the abstract (and by extension the methods) provides no description of experimental controls, layer-selection criteria, or how image-specific embeddings are isolated from intertwined text embeddings using only the transmitted tensors available to a normal participant.
- [Threat Model / Extraction Algorithm] Threat model and extraction algorithm description: the assumption that a passive participant with 'limited knowledge and capability' can reliably separate image embeddings without per-family architecture analysis, forward-pass simulation, or model-specific knowledge is not shown to hold; if the extraction procedure requires such knowledge, the 100% accuracy figure and the downstream reconstruction claims cannot be realized under the stated attacker constraints.
minor comments (1)
- The abstract states that effects of MoE architecture, image preprocessing, model size, and text-image dependency were analyzed, but these results are not cross-referenced to specific sections, tables, or figures, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the importance of clearly documenting the extraction algorithm's assumptions. We address each major comment below with clarifications drawn from the manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central prerequisite claim of an image embedding extraction algorithm achieving 100% accuracy 'across almost all MLLM layers' is load-bearing for both MPAA and IEDA, yet the abstract (and by extension the methods) provides no description of experimental controls, layer-selection criteria, or how image-specific embeddings are isolated from intertwined text embeddings using only the transmitted tensors available to a normal participant.
Authors: We agree the abstract is concise and omits these operational details. Section 3.2 of the manuscript specifies that image embeddings are isolated by matching the known patch-sequence length (determined from input resolution) against the shape of transmitted tensors and by selecting layers prior to full cross-modal fusion, using only positional and dimensional cues present in the tensors themselves. Layer-selection criteria were determined by measuring reconstruction fidelity across layers on held-out images from each model family; controls consisted of verifying that text-only sequences produce no matching patches. We will revise the abstract to include a one-sentence summary of the isolation procedure and the empirical layer range. revision: yes
-
Referee: [Threat Model / Extraction Algorithm] Threat model and extraction algorithm description: the assumption that a passive participant with 'limited knowledge and capability' can reliably separate image embeddings without per-family architecture analysis, forward-pass simulation, or model-specific knowledge is not shown to hold; if the extraction procedure requires such knowledge, the 100% accuracy figure and the downstream reconstruction claims cannot be realized under the stated attacker constraints.
Authors: The extraction procedure relies only on publicly observable properties of the inference protocol: the fixed number of image patches for a given resolution and the ordering of embeddings in the transmitted sequence. No weight access, forward-pass simulation, or family-specific tuning is performed; the same rule set is applied uniformly to all four evaluated families. The 100% accuracy is measured by exact recovery of the image-patch subset from the transmitted tensors under these constraints. We will add an explicit paragraph in Section 2.2 enumerating the minimal protocol-level information assumed to be available to any participant. revision: partial
Circularity Check
Empirical attack evaluation with no derivation chain or self-referential reductions
full rationale
The paper presents an empirical security analysis: it describes designing an image embedding extraction algorithm (achieving reported 100% accuracy in experiments across MLLM layers) and two passive black-box reconstruction attacks (MPAA, IEDA), then evaluates them on four model families. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental results rather than any chain that reduces to its own inputs by construction. This matches the default expectation of no significant circularity for an empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Petals: Collaborative inference and fine-tuning of large models,
A. Borzunov, D. Baranchuk, T. Dettmers, M. Riabinin, Y . Belkada, A. Chumachenko, P. Samygin, and C. Raffel, “Petals: Collaborative inference and fine-tuning of large models,” inProc. ACL, 2023, pp. 558–568. 12
2023
-
[2]
Distributed inference and fine-tuning of large language models over the internet,
A. Borzunov, M. Ryabinin, A. Chumachenko, D. Baranchuk, T. Dettmers, Y . Belkada, P. Samygin, and C. A. Raffel, “Distributed inference and fine-tuning of large language models over the internet,”NeurIPS, 2024
2024
-
[3]
Cake: a rust framework for distributed inference of large models based on candle,
Evilsocket, “Cake: a rust framework for distributed inference of large models based on candle,” https://github.com/evilsocket/cake, 2025
2025
-
[4]
Edgeshard: Efficient llm inference via collaborative edge computing,
M. Zhang, J. Cao, X. Shen, and Z. Cui, “Edgeshard: Efficient llm inference via collaborative edge computing,”arXiv:2405.14371, 2024
arXiv 2024
-
[5]
Hexgen: Generative inference of large language model over heterogeneous environment,
Y . Jiang, R. Yan, X. Yao, Y . Zhou, B. Chen, and B. Yuan, “Hexgen: Generative inference of large language model over heterogeneous environment,” inICML 2024, 2024
2024
-
[6]
Lingualinked: A distributed large language model inference system for mobile devices,
J. Zhao, Y . Song, S. Liu, I. G. Harris, and S. A. Jyothi, “Lingualinked: A distributed large language model inference system for mobile devices,” CoRR, vol. abs/2312.00388, 2023
arXiv 2023
-
[7]
Poster: Pipellm: Pipeline LLM inference on heterogeneous devices with sequence slicing,
R. Ma, J. Wang, Q. Qi, X. Yang, H. Sun, Z. Zhuang, and J. Liao, “Poster: Pipellm: Pipeline LLM inference on heterogeneous devices with sequence slicing,” inProc. ACM SIGCOMM 2023. ACM, 2023, pp. 1126–1128
2023
-
[8]
The ai acceleration cloud,
T. AI, “The ai acceleration cloud,” https://www.together.ai/, 2025
2025
-
[9]
Find compute. train models. co-own intelligence,
P. Intellect, “Find compute. train models. co-own intelligence,” https: //www.primeintellect.ai/, 2025, online; accessed 22-August-2025
2025
-
[10]
Ai infrastructure that developers love,
Modal, “Ai infrastructure that developers love,” https://modal.com/, 2025
2025
-
[11]
Prompt inference attack on distributed large language model inference frameworks,
X. Luo, T. Yu, and X. Xiao, “Prompt inference attack on distributed large language model inference frameworks,”arXiv:2503.09291, 2025
arXiv 2025
-
[12]
Prompt Inversion Attack against Collaborative Inference of Large Language Models ,
W. Qu, Y . Zhou, Y . Wu, T. Xiao, B. Yuan, Y . Li, and J. Zhang, “ Prompt Inversion Attack against Collaborative Inference of Large Language Models ,” inSP 2025, 2025, pp. 1602–1619
2025
-
[13]
Distributed learning of deep neural network over multiple agents,
O. Gupta and R. Raskar, “Distributed learning of deep neural network over multiple agents,”J. Netw. Comput. Appl., vol. 116, pp. 1–8, 2018
2018
-
[14]
Split learning for health: Distributed deep learning without sharing raw patient data,
P. Vepakomma, O. Gupta, T. Swedish, and R. Raskar, “Split learning for health: Distributed deep learning without sharing raw patient data,” arXiv preprint arXiv:1812.00564, 2018
Pith/arXiv arXiv 2018
-
[15]
{PCAT}: Functionality and data stealing from split learning by {Pseudo-Client} attack,
X. Gao and L. Zhang, “ {PCAT}: Functionality and data stealing from split learning by {Pseudo-Client} attack,” inProc. USENIX Security, 2023, pp. 5271–5288
2023
-
[16]
Unleashing the tiger: Inference attacks on split learning,
D. Pasquini, G. Ateniese, and M. Bernaschi, “Unleashing the tiger: Inference attacks on split learning,” inACM CCS, 2021, pp. 2113–2129
2021
-
[17]
Passive inference attacks on split learning via adversarial regularization,
X. Zhu, X. Luo, Y . Wu, Y . Jiang, X. Xiao, and B. C. Ooi, “Passive inference attacks on split learning via adversarial regularization,”arXiv preprint arXiv:2310.10483, 2023
arXiv 2023
-
[18]
Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning,
E. Erdo ˘gan, A. K ¨upc ¸¨u, and A. E. C ¸ic ¸ek, “Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning,” inProc. WPES, 2022, pp. 115–124
2022
-
[19]
G. Team, A. Kamath, J. Ferretet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
Pith/arXiv arXiv 2025
-
[20]
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture- of-loras,
A. Abouelenin, A. Ashfaq, A. Atkinson, H. Awadalla, N. Bach, J. Bao, A. Benhaim, M. Cai, V . Chaudhary, C. Chenet al., “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture- of-loras,”arXiv preprint arXiv:2503.01743, 2025
Pith/arXiv arXiv 2025
-
[21]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[22]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,
Meta, “The llama 4 herd: The beginning of a new era of natively multimodal ai innovation,” https://ai.meta.com/blog/ llama-4-multimodal-intelligence/, 2025
2025
-
[23]
A fusion-denoising attack on instahide with data augmentation,
X. Luo, X. Xiao, Y . Wu, J. Liu, and B. C. Ooi, “A fusion-denoising attack on instahide with data augmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1899–1907
2022
-
[24]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[25]
An analysis of single-layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” inAISTATS, 2011, pp. 215–223
2011
-
[26]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inICCV, 2015, pp. 3730–3738
2015
-
[27]
Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning,
P. Sharma, N. Ding, S. Goodman, and R. Soricut, “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning,” inProc. ACL, 2018, pp. 2556–2565
2018
-
[28]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Doll ´ar, “Microsoft coco: Common objects in context,” 2015
2015
-
[29]
Imagenette: A smaller subset of 10 easily classified classes from imagenet
J. Howard, “Imagenette: A smaller subset of 10 easily classified classes from imagenet.” [Online]. Available: https://github.com/fastai/imagenette
-
[30]
midjourney-prompts,
S. AI, “midjourney-prompts,” https://huggingface.co/datasets/succinctly/ midjourney-prompts, 2025, online; accessed 21-October-2025
2025
-
[31]
Understanding deep learning requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understanding deep learning requires rethinking generalization,” inICLR, 2017
2017
-
[32]
Coding theorems for a discrete source with a fidelity criterion,
C. E. Shannonet al., “Coding theorems for a discrete source with a fidelity criterion,”IRE Nat. Conv. Rec, vol. 4, no. 142-163, p. 1, 1959
1959
-
[33]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” NeurIPS, vol. 33, pp. 6840–6851, 2020
2020
-
[34]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF CVPR, 2022, pp. 10 684–10 695
2022
-
[35]
T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,” inProc. AAAI, vol. 38, no. 5, 2024
2024
-
[36]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProc. ICCV, 2023, pp. 3836–3847
2023
-
[37]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” inIEEE CVPR, 2016, pp. 2818–2826
2016
-
[38]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[39]
Improved training of wasserstein gans,
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. C. Courville, “Improved training of wasserstein gans,”Proc. NeurIPS, vol. 30, 2017
2017
-
[40]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[41]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inProc. IEEE CVPR. Ieee, 2009, pp. 248–255
2009
-
[42]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[43]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE CVPR, 2016, pp. 770–778
2016
-
[44]
Mllms know where to look: Training-free perception of small visual details with multimodal llms,
J. Zhang, M. Khayatkhoei, P. Chhikara, and F. Ilievski, “Mllms know where to look: Training-free perception of small visual details with multimodal llms,”arXiv preprint arXiv:2502.17422, 2025
arXiv 2025
-
[45]
Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models,
Q. Guo, S. Pang, X. Jia, Y . Liu, and Q. Guo, “Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models,”IEEE TIFS, 2024
2024
-
[46]
MP-SPDZ: A versatile framework for multi-party computa- tion,
M. Keller, “MP-SPDZ: A versatile framework for multi-party computa- tion,” inACM CCS 2020. ACM, 2020, pp. 1575–1590
2020
-
[47]
Trusted execution environments: properties, applications, and challenges,
P. Jauernig, A.-R. Sadeghi, and E. Stapf, “Trusted execution environments: properties, applications, and challenges,”IEEE S&P, 2020
2020
-
[48]
Bumblebee: Secure two-party inference framework for large transformers,
W.-j. Lu, Z. Huang, Z. Gu, J. Li, J. Liu, C. Hong, K. Ren, T. Wei, and W. Chen, “Bumblebee: Secure two-party inference framework for large transformers,”Cryptology ePrint Archive, 2023
2023
-
[49]
Information leakage in embedding models,
C. Song and A. Raghunathan, “Information leakage in embedding models,” inACM CCS 2020. ACM, 2020, pp. 377–390
2020
-
[50]
Context-aware membership inference attacks against pre-trained large language models,
H. Chang, A. Shahin Shamsabadi, K. Katevas, H. Haddadi, and R. Shokri, “Context-aware membership inference attacks against pre-trained large language models,” inEMNLP 2025. Association for Computational Linguistics, Nov. 2025, pp. 7299–7321
2025
-
[51]
Thieves on sesame street! model extraction of bert-based apis,
K. Krishna, G. S. Tomar, A. P. Parikh, N. Papernot, and M. Iyyer, “Thieves on sesame street! model extraction of bert-based apis,” inICLR 2020, 2020
2020
-
[52]
Grey-box extraction of natural language models,
S. Zanella-Beguelin, S. Tople, A. Paverd, and B. K ¨opf, “Grey-box extraction of natural language models,” inICML. PMLR, 2021, pp. 12 278–12 286
2021
-
[53]
Effective prompt extraction from language models,
Y . Zhang, N. Carlini, and D. Ippolito, “Effective prompt extraction from language models,” inFirst Conference on Language Modeling, 2024
2024
-
[54]
Sentence embedding leaks more information than you expect: Generative embedding inversion attack to recover the whole sentence,
H. Li, M. Xu, and Y . Song, “Sentence embedding leaks more information than you expect: Generative embedding inversion attack to recover the whole sentence,” inACL 2023, 2023, pp. 14 022–14 040
2023
-
[55]
Text embeddings reveal (almost) as much as text,
J. X. Morris, V . Kuleshov, V . Shmatikov, and A. M. Rush, “Text embeddings reveal (almost) as much as text,” inProc. EMNLP 2023, 2023, pp. 12 448–12 460
2023
-
[56]
Extracting prompts by inverting LLM outputs,
C. Zhang, J. X. Morris, and V . Shmatikov, “Extracting prompts by inverting LLM outputs,” inProc. EMNLP 2024, 2024, pp. 14 753–14 777
2024
-
[57]
Transferable adversarial attacks on black-box vision- language models,
K. Hu, W. Yu, L. Zhang, A. Robey, A. Zou, C. Xu, H. Hu, and M. Fredrikson, “Transferable adversarial attacks on black-box vision- language models,”arXiv preprint arXiv:2505.01050, 2025
arXiv 2025
-
[58]
Leakyclip: Extracting training data from clip,
Y . Chen, S. Wang, X. Wang, and X. Ma, “Leakyclip: Extracting training data from clip,”arXiv preprint arXiv:2508.00756, 2025
Pith/arXiv arXiv 2025
-
[59]
Drag: Data reconstruction attack using guided diffusion,
W.-K. Lei, J.-C. Chen, and S.-T. Chen, “Drag: Data reconstruction attack using guided diffusion,”arXiv preprint arXiv:2509.11724, 2025
arXiv 2025
-
[60]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”Proc. NeurIPS, vol. 35, pp. 25 278–25 294, 2022. 13
2022
-
[61]
The convolution inequality for entropy powers,
N. Blachman, “The convolution inequality for entropy powers,”IEEE Transactions on Information theory, vol. 11, no. 2, pp. 267–271, 2003
2003
-
[62]
Gersho and R
A. Gersho and R. M. Gray,Vector quantization and signal compression. Springer Science & Business Media, 2012, vol. 159
2012
-
[63]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023
2023
-
[64]
Gpt aip pricing,
OpenAI, “Gpt aip pricing,” https://openai.com/api/pricing/, 2025, online; accessed 14-November-2025
2025
-
[65]
Gemini api pricing,
Google, “Gemini api pricing,” https://ai.google.dev/gemini-api/docs/ pricing, 2025, online; accessed 14-November-2025
2025
-
[66]
Calibrating noise for group privacy in subsampled mechanisms,
Y . Jiang, X. Luo, Y . Yang, and X. Xiao, “Calibrating noise for group privacy in subsampled mechanisms,”arXiv preprint arXiv:2408.09943, 2024
arXiv 2024
-
[67]
Feature inference attack on model predictions in vertical federated learning,
X. Luo, Y . Wu, X. Xiao, and B. C. Ooi, “Feature inference attack on model predictions in vertical federated learning,” in2021 IEEE 37th international conference on data engineering (ICDE). IEEE, 2021, pp. 181–192. 14 SUPPLEMENTARYMATERIAL SI. DESIGNREMARKS ONMPAA Below, we provide several remarks on MPAA. Lightweight. In MPAA, we employ a shared patch ex...
2021
-
[68]
and host it on a server with an AMD EPYC 9654 processor (192 cores), two NVIDIA A100-SXM4 40GB GPUs, and 750 GB of RAM, under Ubuntu 22.04. In our setup, three participants are distributed across the two local GPUs, with the second participant designated as the attacker. Note that the number of participants does not affect the attack mechanism; the primar...
arXiv 2055
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.