TimeLAVA: Learning-Agnostic Valuation for Time Series Data
Pith reviewed 2026-06-30 11:24 UTC · model grok-4.3
The pith
TimeLAVA values time series segments by their marginal contribution to minimizing a selective wavelet-based Wasserstein discrepancy without training any model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
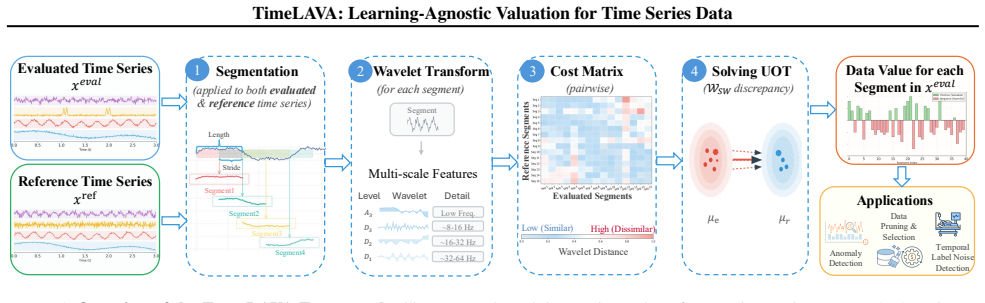
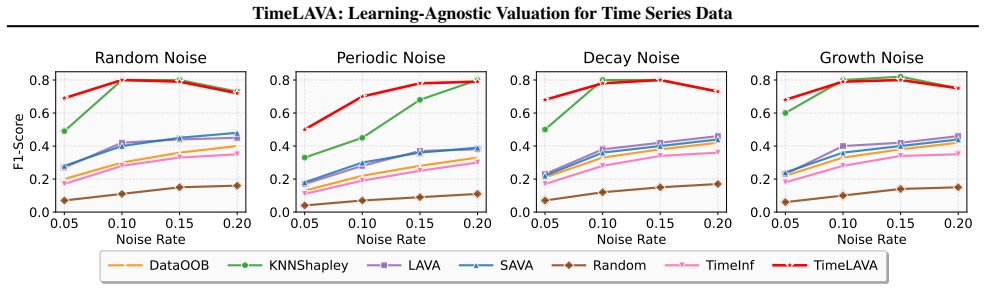
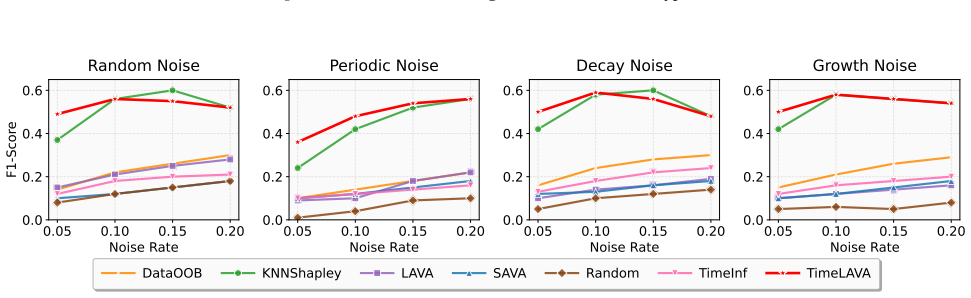
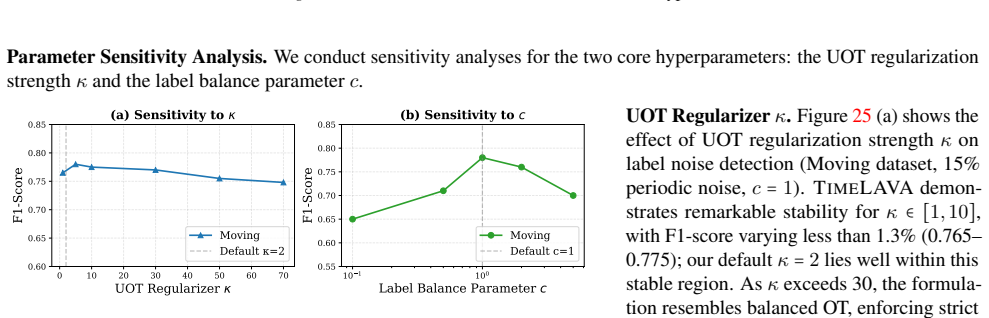
TimeLAVA is a learning-agnostic framework that values temporal segments by their marginal contribution to minimizing the Selective Wavelet-based Wasserstein discrepancy between evaluated and reference data. Segment values are computed efficiently via sensitivity analysis without requiring model training and aggregated into point-wise scores. The method supplies theoretical guarantees that link the resulting valuation to model-agnostic generalization and prove bounded sensitivity to outlier contamination.
What carries the argument
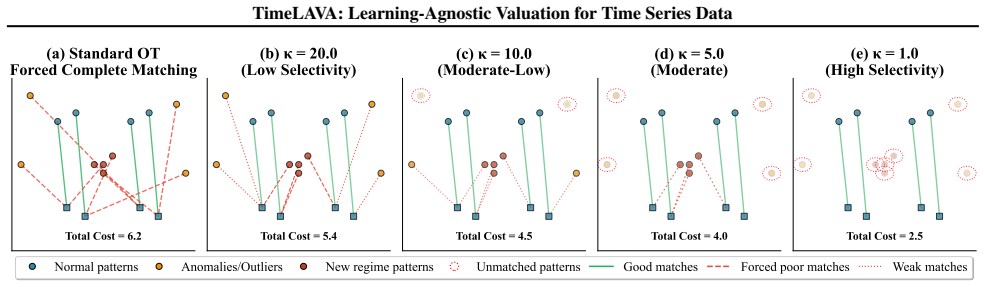
Selective Wavelet-based Wasserstein discrepancy, formed by combining multi-scale wavelet transforms for temporal localization with unbalanced optimal transport for robustness to shifts; values are extracted from sensitivity analysis on this measure.
If this is right
- Time series data curation and quality control become possible without dependence on any specific model architecture or training procedure.
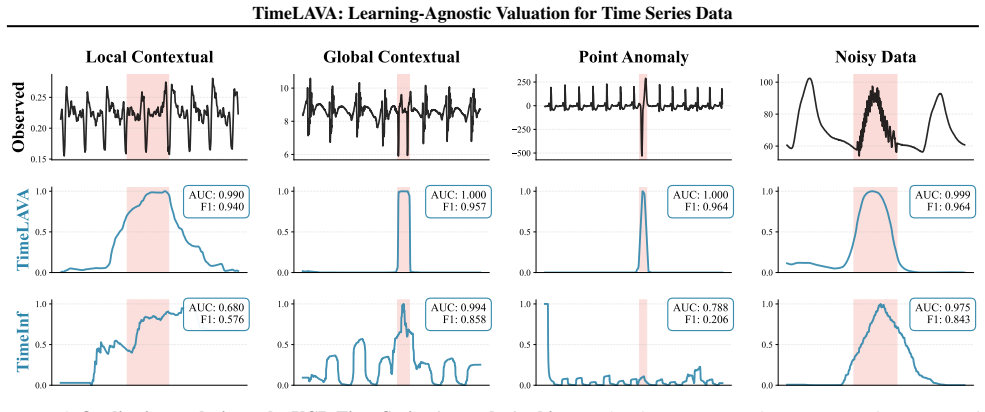
- Value scores support more effective anomaly detection by identifying segments that contribute least to distributional alignment.
- Data pruning guided by these scores yields higher performance on downstream tasks than pruning guided by existing valuation methods.
- Label noise detection improves because noisy segments produce larger increases in the wavelet-Wasserstein discrepancy.
- Valuation remains stable under moderate outlier contamination due to the bounded sensitivity result.
Where Pith is reading between the lines
- The wavelet component suggests straightforward extensions to other multi-scale sequential signals such as audio or video streams.
- Sensitivity analysis on the discrepancy could enable incremental valuation updates for streaming time series without recomputing from scratch.
- Direct comparisons between TimeLAVA scores and model-dependent valuation scores on identical datasets would clarify when the model-agnostic property is most advantageous.
- The framework may generalize to irregularly sampled or multivariate time series by adjusting the wavelet basis accordingly.
Load-bearing premise
The marginal contribution of a temporal segment to minimizing the Selective Wavelet-based Wasserstein discrepancy serves as a reliable proxy for its intrinsic quality or utility across downstream learning tasks.
What would settle it
A controlled experiment on a held-out time series dataset in which selecting or retaining segments ranked highest by TimeLAVA produces no improvement (or produces worse performance) on a downstream task such as forecasting or classification compared with selecting low-ranked segments or random subsets.
Figures


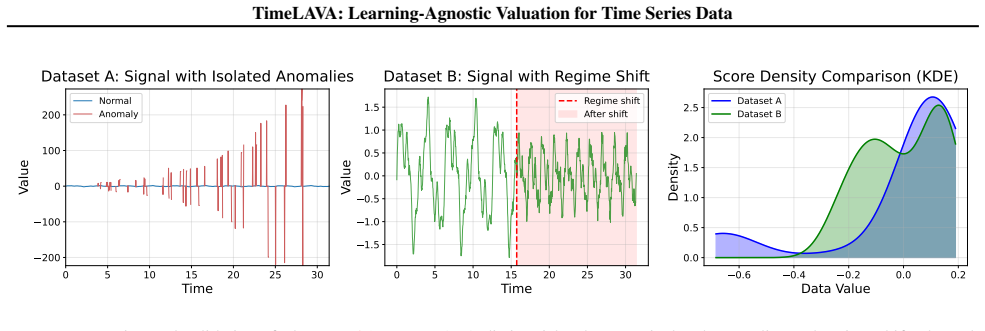
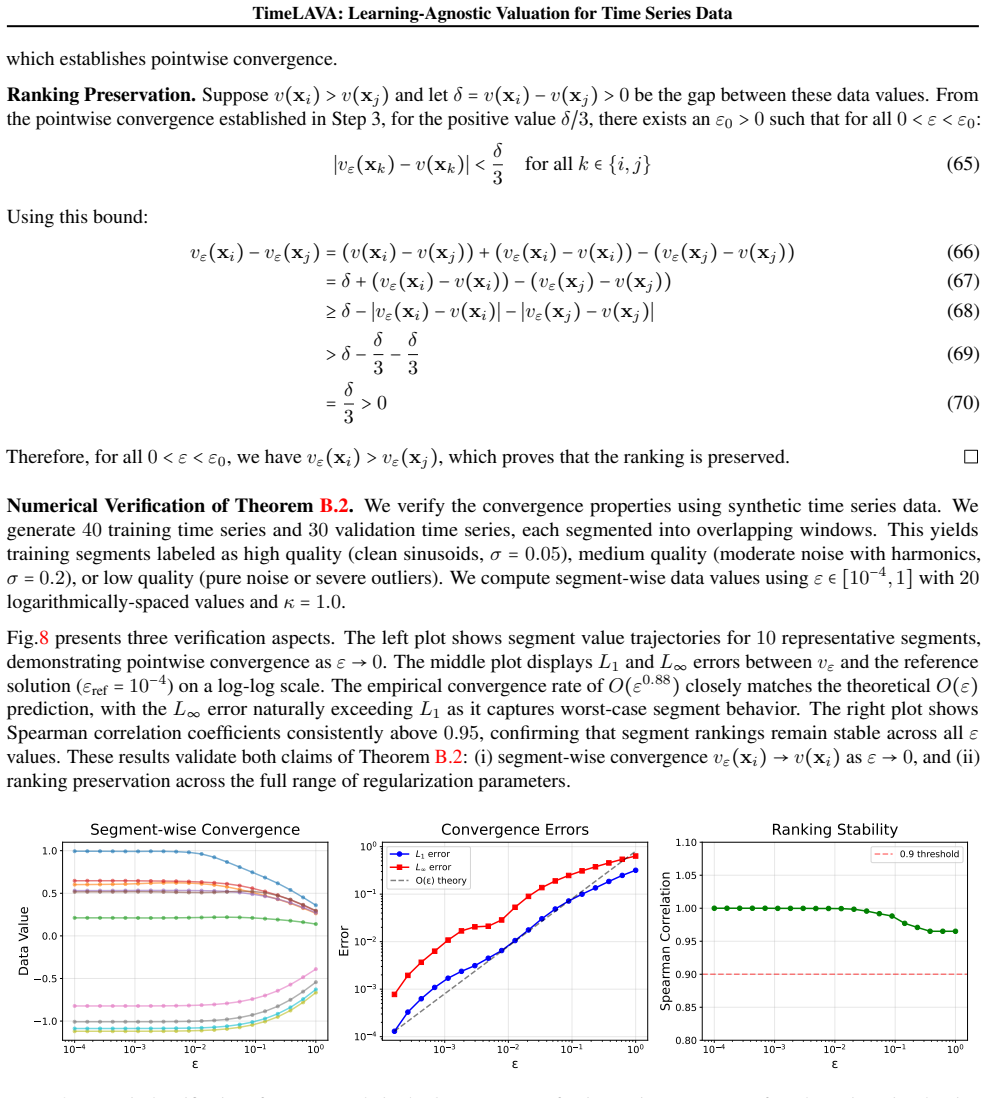
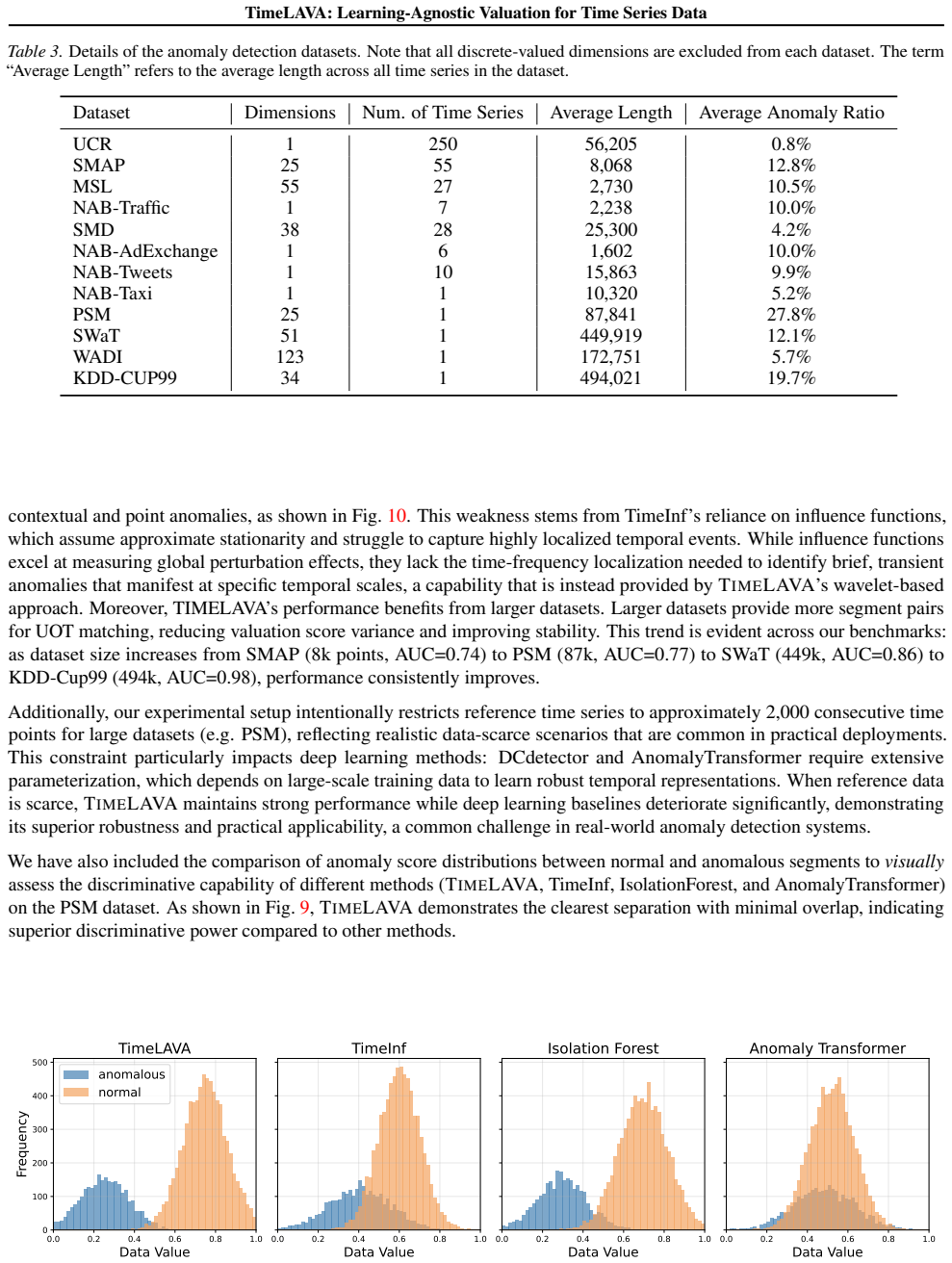
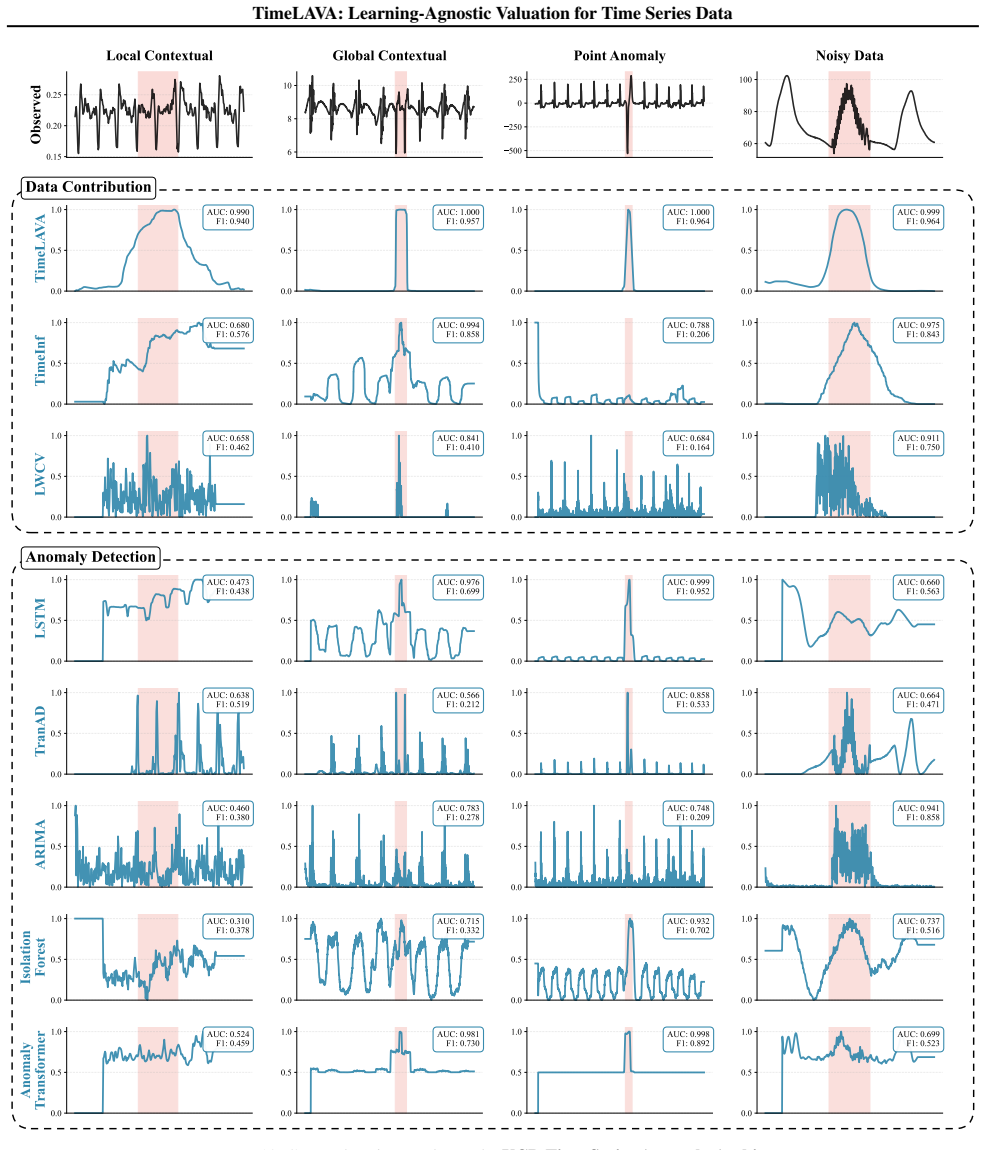


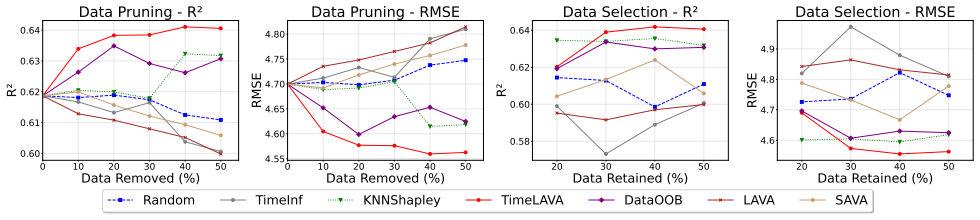
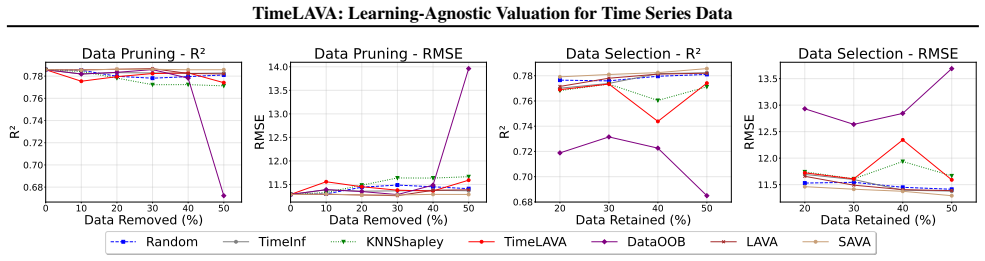
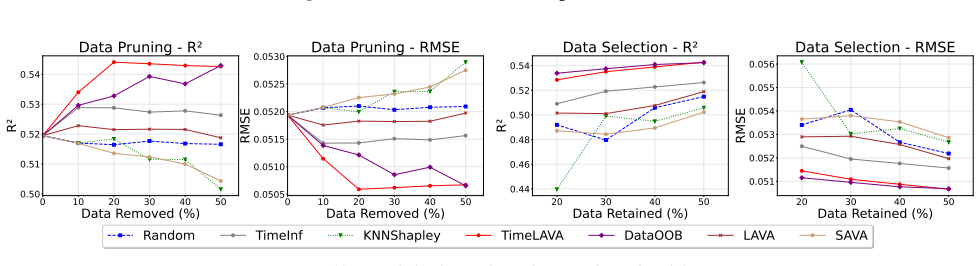

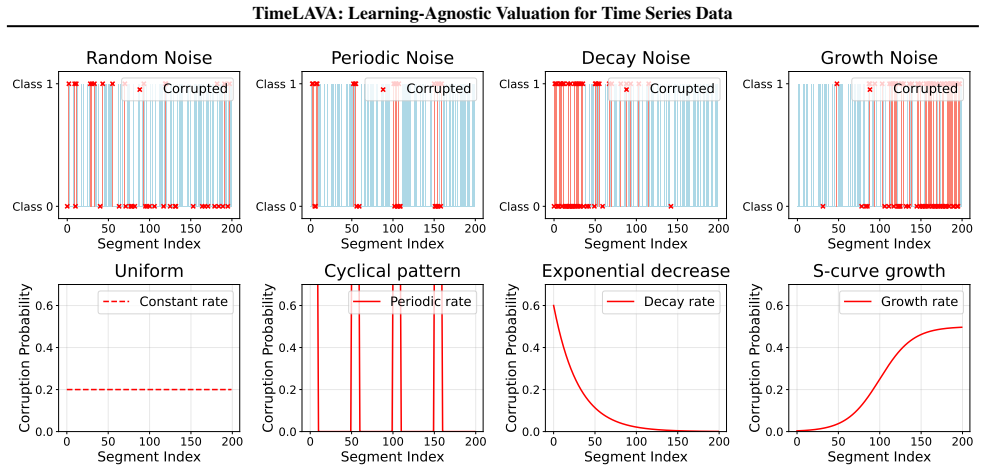
read the original abstract
Data valuation quantifies the intrinsic quality of individual samples to enable principled data curation, quality control, and robust learning. For time series in critical domains such as healthcare, finance, and industrial monitoring, effective valuation methods are essential yet fundamentally lacking. Existing approaches are either model-dependent, limiting their generalizability, or designed for i.i.d. data and thus fail to capture temporal dependencies, multi-scale patterns, and non-stationary dynamics inherent to sequential data. We introduce TimeLAVA, a learning-agnostic framework that values temporal segments by their marginal contribution to minimizing distributional discrepancy between evaluated and reference data. At its core is a novel Selective Wavelet-based Wasserstein discrepancy combining multi-scale wavelet transforms for temporal localization with unbalanced optimal transport for robustness to distributional shifts. Segment values are efficiently computed via sensitivity analysis without requiring model training and aggregated into point-wise scores. We provide theoretical guarantees linking valuation to model-agnostic generalization and prove bounded sensitivity to outlier contamination. Extensive experiments across anomaly detection, data pruning, and label noise detection demonstrate that TimeLAVA produces significantly more informative value scores than existing methods on diverse real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TimeLAVA, a learning-agnostic framework for time series data valuation. Temporal segments are valued by their marginal contribution to minimizing a novel Selective Wavelet-based Wasserstein discrepancy that combines multi-scale wavelet transforms with unbalanced optimal transport. The method requires no model training, supplies theoretical guarantees linking the scores to generalization and bounded outlier sensitivity, and is evaluated on anomaly detection, data pruning, and label noise detection tasks where it is claimed to outperform prior methods on real-world datasets.
Significance. If the theoretical links and empirical superiority hold, the work would address a clear gap in model-independent valuation methods that respect temporal structure, multi-scale patterns, and non-stationarity, with direct utility for data curation in healthcare, finance, and monitoring applications. The explicit positioning as learning-agnostic and the provision of sensitivity bounds are positive features.
major comments (3)
- [Abstract and §3] Abstract and §3 (Theoretical Analysis): the manuscript asserts 'theoretical guarantees linking valuation to model-agnostic generalization' and 'bounded sensitivity to outlier contamination,' yet the provided text contains no derivations, proof sketches, or statements of the relevant lemmas, which are load-bearing for the central contribution.
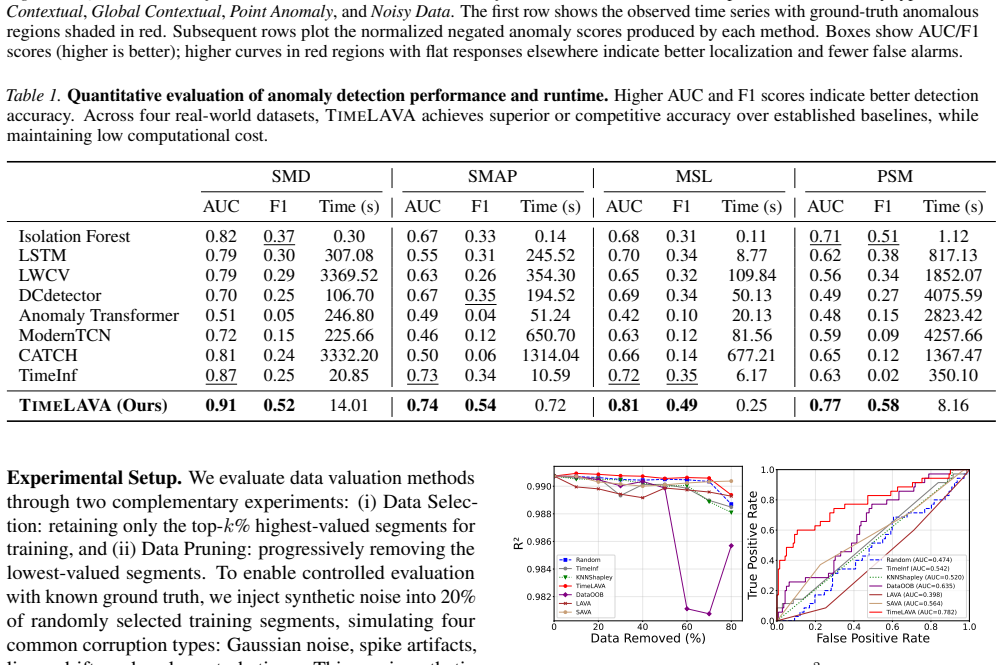
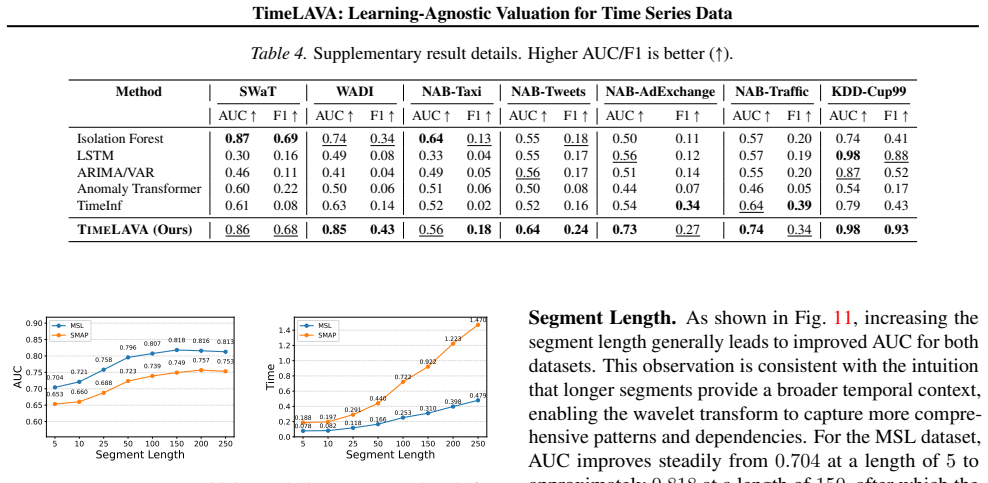
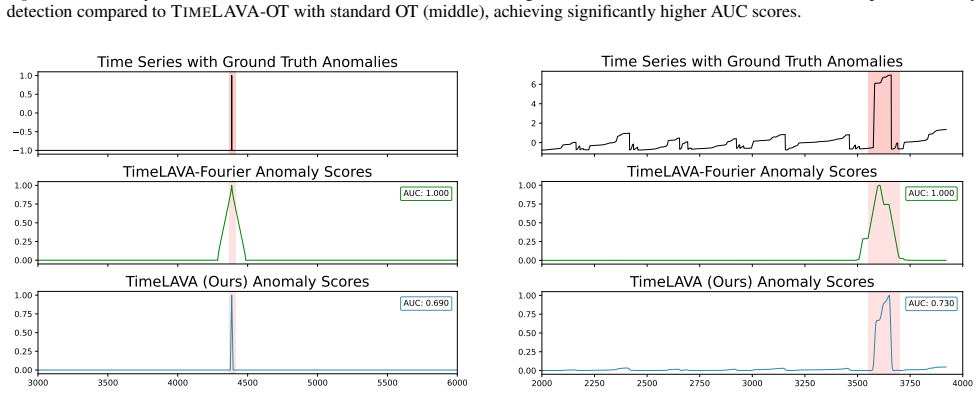
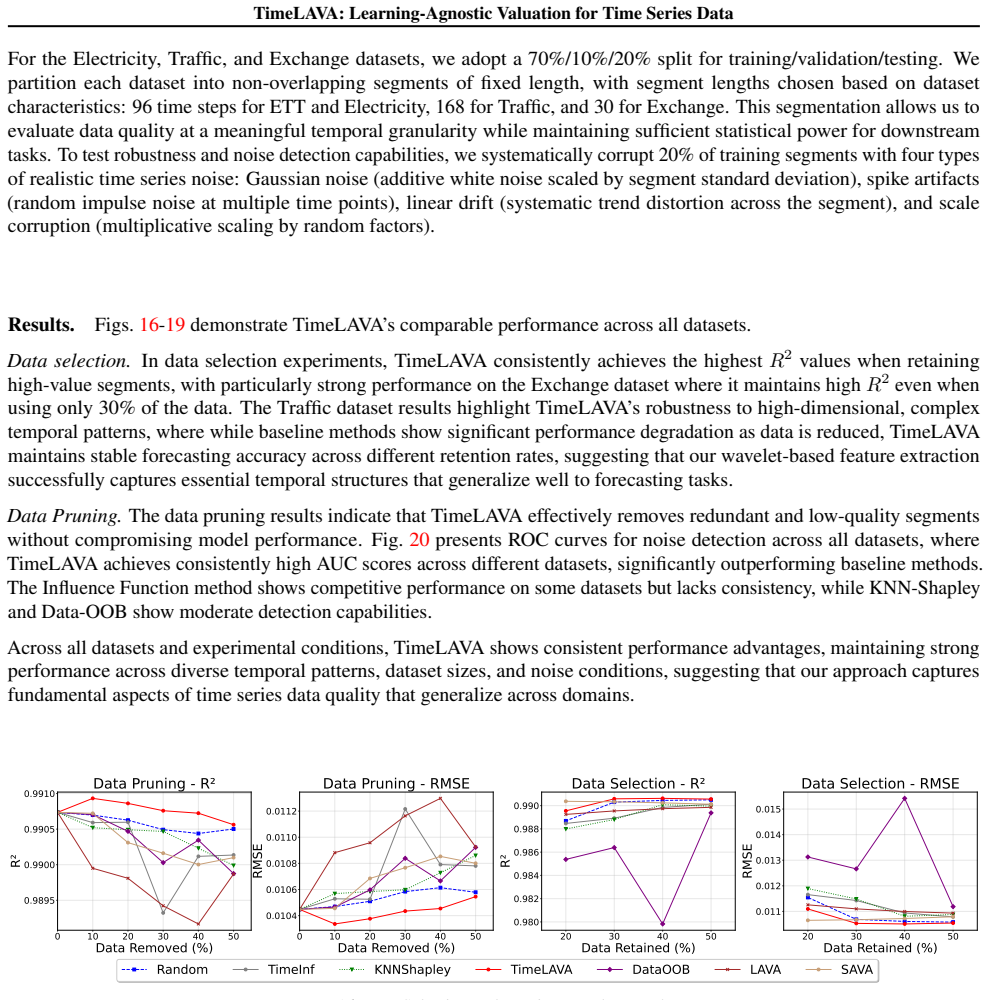
- [§5] §5 (Experiments): the claim that TimeLAVA 'produces significantly more informative value scores' is unsupported by any reported dataset sizes, error bars, ablation studies, or quantitative tables comparing value-score informativeness, rendering the superiority assertion impossible to assess.
- [§4] §4 (Method): the core modeling choice—that marginal contribution to the Selective Wavelet-based Wasserstein discrepancy serves as a reliable proxy for downstream utility—is load-bearing for all empirical claims but is not tested against direct task-specific utility or alternative discrepancy measures.
minor comments (2)
- [Abstract] Abstract: the phrase 'Selective Wavelet-based Wasserstein discrepancy' is introduced without a one-sentence gloss of its two constituent ideas (wavelet localization and unbalanced OT).
- [§4] Notation: the aggregation step from segment values to point-wise scores is described only at a high level; a short equation or pseudocode line would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness where the points are valid.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Theoretical Analysis): the manuscript asserts 'theoretical guarantees linking valuation to model-agnostic generalization' and 'bounded sensitivity to outlier contamination,' yet the provided text contains no derivations, proof sketches, or statements of the relevant lemmas, which are load-bearing for the central contribution.
Authors: We agree that the main text would benefit from explicit proof sketches. The full proofs appear in the appendix, but to address this, we will insert concise statements of the key lemmas and proof outlines directly into Section 3, making the theoretical links to generalization and outlier sensitivity self-contained in the body. revision: yes
-
Referee: [§5] §5 (Experiments): the claim that TimeLAVA 'produces significantly more informative value scores' is unsupported by any reported dataset sizes, error bars, ablation studies, or quantitative tables comparing value-score informativeness, rendering the superiority assertion impossible to assess.
Authors: The experimental section requires expanded reporting. In revision we will add explicit dataset sizes, standard-error bars from repeated trials, ablation tables, and quantitative comparisons of value-score informativeness to support the superiority claims. revision: yes
-
Referee: [§4] §4 (Method): the core modeling choice—that marginal contribution to the Selective Wavelet-based Wasserstein discrepancy serves as a reliable proxy for downstream utility—is load-bearing for all empirical claims but is not tested against direct task-specific utility or alternative discrepancy measures.
Authors: The choice is grounded in the theoretical connection between the discrepancy and generalization established in Section 3. While downstream-task results provide indirect validation, we will add targeted comparisons against alternative discrepancy measures in the revised experiments to further substantiate the modeling decision. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents TimeLAVA as a learning-agnostic framework that computes segment values via marginal contribution to a Selective Wavelet-based Wasserstein discrepancy, with aggregation into point-wise scores and theoretical guarantees on generalization and sensitivity. No equations, fitting procedures, or derivations are described that reduce a claimed result to its inputs by construction (e.g., no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations on uniqueness theorems). The method is explicitly positioned as independent of model training, with empirical validation on downstream tasks, rendering the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Selective Wavelet-based Wasserstein discrepancy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Annals of Applied Statistics , volume=
Compression of climate simulations with a nonstationary global SpatioTemporal SPDE model , author=. The Annals of Applied Statistics , volume=. 2020 , publisher=
2020
-
[2]
Spatial Statistics , volume=
Non-stationary spatio-temporal modeling using the stochastic advection--diffusion equation , author=. Spatial Statistics , volume=. 2024 , publisher=
2024
-
[3]
Spatial Statistics , volume=
Estimation of a non-stationary model for annual precipitation in southern Norway using replicates of the spatial field , author=. Spatial Statistics , volume=. 2015 , publisher=
2015
-
[4]
Journal of the American Statistical Association , volume=
Approximate likelihood for large irregularly spaced spatial data , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
2007
-
[5]
Statistica Sinica , pages=
Exploring a new class of non-stationary spatial Gaussian random fields with varying local anisotropy , author=. Statistica Sinica , pages=. 2015 , publisher=
2015
-
[6]
Spatial Statistics , volume=
Does non-stationary spatial data always require non-stationary random fields? , author=. Spatial Statistics , volume=. 2015 , publisher=
2015
-
[7]
Journal of the American Statistical Association , volume=
Statistical modeling for spatio-temporal data from stochastic convection-diffusion processes , author=. Journal of the American Statistical Association , volume=. 2022 , publisher=
2022
-
[8]
2023 , booktitle =
Kwon, Yongchan and Zou, James , title =. 2023 , booktitle =
2023
-
[9]
Hoang Anh Just and Feiyang Kang and Tianhao Wang and Yi Zeng and Myeongseob Ko and Ming Jin and Ruoxi Jia , booktitle=
-
[10]
The Thirteenth International Conference on Learning Representations , year=
Optimal Transport for Time Series Imputation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[11]
Ingredients
Data Valuation in Machine Learning: "Ingredients", Strategies, and Open Challenges , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =
2022
-
[12]
The Thirteenth International Conference on Learning Representations , year=
TimeInf: Time Series Data Contribution via Influence Functions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
2017 , booktitle =
Koh, Pang Wei and Liang, Percy , title =. 2017 , booktitle =
2017
-
[14]
Ingredients
Data Valuation in Machine Learning:" Ingredients", Strategies, and Open Challenges. , author=. IJCAI , pages=
-
[15]
The Twelfth International Conference on Learning Representations , year=
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
Mathematics of computation , volume=
Scaling algorithms for unbalanced optimal transport problems , author=. Mathematics of computation , volume=
-
[17]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[18]
Foundations and Trends
Computational optimal transport: With applications to data science , author=. Foundations and Trends. 2019 , publisher=
2019
-
[19]
2008 , publisher=
Optimal transport: old and new , author=. 2008 , publisher=
2008
-
[20]
Advances in Neural Information Processing Systems , volume=
Geometric dataset distances via optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Modeling long-and short-term temporal patterns with deep neural networks , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[22]
The 22nd international conference on artificial intelligence and statistics , pages=
Interpolating between optimal transport and mmd using sinkhorn divergences , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
2019
-
[23]
Journal of Machine Learning Research , volume=
Pot: Python optimal transport , author=. Journal of Machine Learning Research , volume=
-
[24]
Journal of the American Statistical Association , volume=
The influence curve and its role in robust estimation , author=. Journal of the American Statistical Association , volume=. 1974 , publisher=
1974
-
[25]
The Annals of Statistics , volume=
Infinitesimal robustness for autoregressive processes , author=. The Annals of Statistics , volume=. 1984 , publisher=
1984
-
[26]
The Annals of Statistics , volume=
Influence functionals for time series , author=. The Annals of Statistics , volume=. 1986 , publisher=
1986
-
[27]
International Conference on Machine Learning (ICML) , pages=
Data shapley: Equitable valuation of data for machine learning , author=. International Conference on Machine Learning (ICML) , pages=. 2019 , publisher=
2019
-
[28]
The 22nd International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
Towards efficient data valuation based on the shapley value , author=. The 22nd International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=. 2019 , series=
2019
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Validation free and replication robust volume-based data valuation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=. 2021 , editor=
2021
-
[30]
Probability Theory and Related Fields , volume=
Entropic optimal transport: Convergence of potentials , author=. Probability Theory and Related Fields , volume=. 2022 , publisher=
2022
-
[31]
International Conference on Machine Learning , pages=
On unbalanced optimal transport: An analysis of sinkhorn algorithm , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[32]
2015 , howpublished =
Trindade, Artur , title =. 2015 , howpublished =
2015
-
[33]
Advances in Neural Information Processing Systems , volume=
Softpatch: Unsupervised anomaly detection with noisy data , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the VLDB Endowment , volume=
Anomaly detection in time series: a comprehensive evaluation , author=. Proceedings of the VLDB Endowment , volume=. 2022 , publisher=
2022
-
[35]
IEEE transactions on knowledge and data engineering , volume=
Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress , author=. IEEE transactions on knowledge and data engineering , volume=. 2021 , publisher=
2021
-
[36]
Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding , author=. Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[37]
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Robust anomaly detection for multivariate time series through stochastic recurrent neural network , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[38]
Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
Practical approach to asynchronous multivariate time series anomaly detection and localization , author=. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
-
[39]
2016 international workshop on cyber-physical systems for smart water networks (CySWater) , pages=
SWaT: A water treatment testbed for research and training on ICS security , author=. 2016 international workshop on cyber-physical systems for smart water networks (CySWater) , pages=. 2016 , organization=
2016
-
[40]
International Conference on Learning Representations , year=
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy , author=. International Conference on Learning Representations , year=
-
[41]
Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Dcdetector: Dual attention contrastive representation learning for time series anomaly detection , author=. Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[42]
, title =
Tuli, Shreshth and Casale, Giuliano and Jennings, Nicholas R. , title =. Proc. VLDB Endow. , month = feb, pages =. 2022 , issue_date =
2022
-
[43]
Advances in neural information processing systems , volume=
Approximate cross-validation for structured models , author=. Advances in neural information processing systems , volume=
-
[44]
2008 eighth ieee international conference on data mining , pages=
Isolation forest , author=. 2008 eighth ieee international conference on data mining , pages=. 2008 , organization=
2008
-
[45]
Proceedings of the 3rd international conference on knowledge discovery and data mining , pages=
Using dynamic time warping to find patterns in time series , author=. Proceedings of the 3rd international conference on knowledge discovery and data mining , pages=
-
[46]
International conference on machine learning , pages=
Unbalanced minibatch optimal transport; applications to domain adaptation , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[47]
1994 , publisher=
Time series analysis , author=. 1994 , publisher=
1994
-
[48]
Scientific data , volume=
MIMIC-III, a freely accessible critical care database , author=. Scientific data , volume=. 2016 , publisher=
2016
-
[49]
Big data
“Big data” in the intensive care unit. Closing the data loop , author=. American journal of respiratory and critical care medicine , volume=
-
[50]
2000 , publisher=
Non-linear time series models in empirical finance , author=. 2000 , publisher=
2000
-
[51]
Computers & Industrial Engineering , volume=
A systematic literature review of machine learning methods applied to predictive maintenance , author=. Computers & Industrial Engineering , volume=. 2019 , publisher=
2019
-
[52]
ACM computing surveys (CSUR) , volume=
Deep learning for anomaly detection: A review , author=. ACM computing surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[53]
Applied soft computing , volume=
Financial time series forecasting with deep learning: A systematic literature review: 2005--2019 , author=. Applied soft computing , volume=. 2020 , publisher=
2005
-
[54]
Advances in Neural Information Processing Systems , volume=
Opendataval: a unified benchmark for data valuation , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
SIAM review , volume=
Continuous and discrete wavelet transforms , author=. SIAM review , volume=. 1989 , publisher=
1989
-
[56]
Unsupervised real-time anomaly detection for streaming data , journal =
Subutai Ahmad and Alexander Lavin and Scott Purdy and Zuha Agha , keywords =. Unsupervised real-time anomaly detection for streaming data , journal =. 2017 , note =
2017
-
[57]
, title =
Ahmed, Chuadhry Mujeeb and Palleti, Venkata Reddy and Mathur, Aditya P. , title =. Proceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks , pages =. 2017 , publisher =
2017
-
[58]
and Wei Fan and Wenke Lee and Prodromidis, A
Stolfo, S.J. and Wei Fan and Wenke Lee and Prodromidis, A. and Chan, P.K. , booktitle=. Cost-based modeling for fraud and intrusion detection: results from the JAM project , year=
-
[59]
Applied sciences , volume=
Wavelet transform application for/in non-stationary time-series analysis: A review , author=. Applied sciences , volume=. 2019 , publisher=
2019
-
[60]
2004 , publisher=
Fourier analysis of time series: an introduction , author=. 2004 , publisher=
2004
-
[61]
The Thirteenth International Conference on Learning Representations , year=
Learning under Temporal Label Noise , author=. The Thirteenth International Conference on Learning Representations , year=
-
[62]
2013 , howpublished =
Reyes-Ortiz, Jorge and Anguita, Davide and Ghio, Alessandro and Oneto, Luca and Parra, Xavier , title =. 2013 , howpublished =
2013
-
[63]
Logacjov, Aleksej and Ustad, Astrid , title =
-
[64]
2013 , howpublished =
Roesler, Oliver , title =. 2013 , howpublished =
2013
-
[65]
Proceedings of the 19th ACM conference on computer-supported cooperative work & social computing , pages=
You get who you pay for: The impact of incentives on participation bias , author=. Proceedings of the 19th ACM conference on computer-supported cooperative work & social computing , pages=
-
[66]
, author=
Seasonal variation in self-reports of recent alcohol consumption: racial and ethnic differences. , author=. Journal of Studies on Alcohol , volume=. 2003 , publisher=
2003
-
[67]
Journal of Functional Analysis , volume=
Unbalanced optimal transport: Dynamic and Kantorovich formulations , author=. Journal of Functional Analysis , volume=. 2018 , publisher=
2018
-
[68]
arXiv preprint arXiv:1910.12958 , year=
Sinkhorn divergences for unbalanced optimal transport , author=. arXiv preprint arXiv:1910.12958 , year=
-
[69]
International Conference on Artificial Intelligence and Statistics , year=
Beta Shapley: a Unified and Noise-reduced Data Valuation Framework for Machine Learning , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[70]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[71]
, journal=
Mallat, S.G. , journal=. A theory for multiresolution signal decomposition: the wavelet representation , year=
-
[72]
Transactions on Machine Learning Research , year=
Data Valuation in the Absence of a Reliable Validation Set , author=. Transactions on Machine Learning Research , year=
-
[73]
Samuel Kessler and Tam Le and Vu Nguyen , booktitle=
-
[74]
Machine Learning and Knowledge Discovery in Databases
Kraus, Maurice and Steinmann, David and Wüst, Antonia and Kokozinski, Andre and Kersting, Kristian , title =. Machine Learning and Knowledge Discovery in Databases. , year =
-
[75]
Luo, Donghao and Wang, Xue , booktitle=. Modern
-
[76]
Xingjian Wu and Xiangfei Qiu and Zhengyu Li and Yihang Wang and Jilin Hu and Chenjuan Guo and Hui Xiong and Bin Yang , booktitle=
-
[77]
arXiv preprint arXiv:1908.08619 , year=
Efficient task-specific data valuation for nearest neighbor algorithms , author=. arXiv preprint arXiv:1908.08619 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.