Output Vector Editing for Memorization Mitigation in Large Language Models
Pith reviewed 2026-06-26 21:21 UTC · model grok-4.3
The pith
Output vector editing on MLP neurons suppresses up to 87.9% of memorized sequences by redirecting residual stream contributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
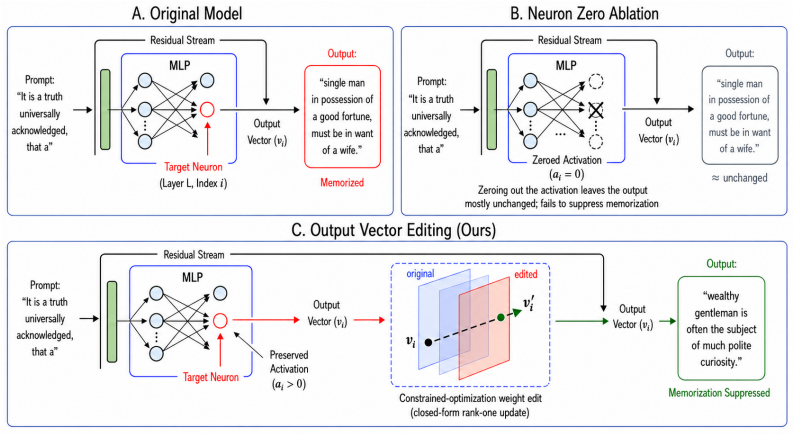
A constrained-optimization weight edit locates a small set of MLP neurons responsible for a memorized continuation and minimally modifies their output vectors to introduce a distractor in vocabulary space, redirecting their residual-stream contributions while leaving activations unchanged, achieving up to 87.9% suppression with a 2.7 times gap over zero ablation on the same located neurons.
What carries the argument
Output vector editing: a constrained-optimization procedure that identifies responsible MLP neurons and edits their output vectors to redirect contributions to the residual stream.
If this is right
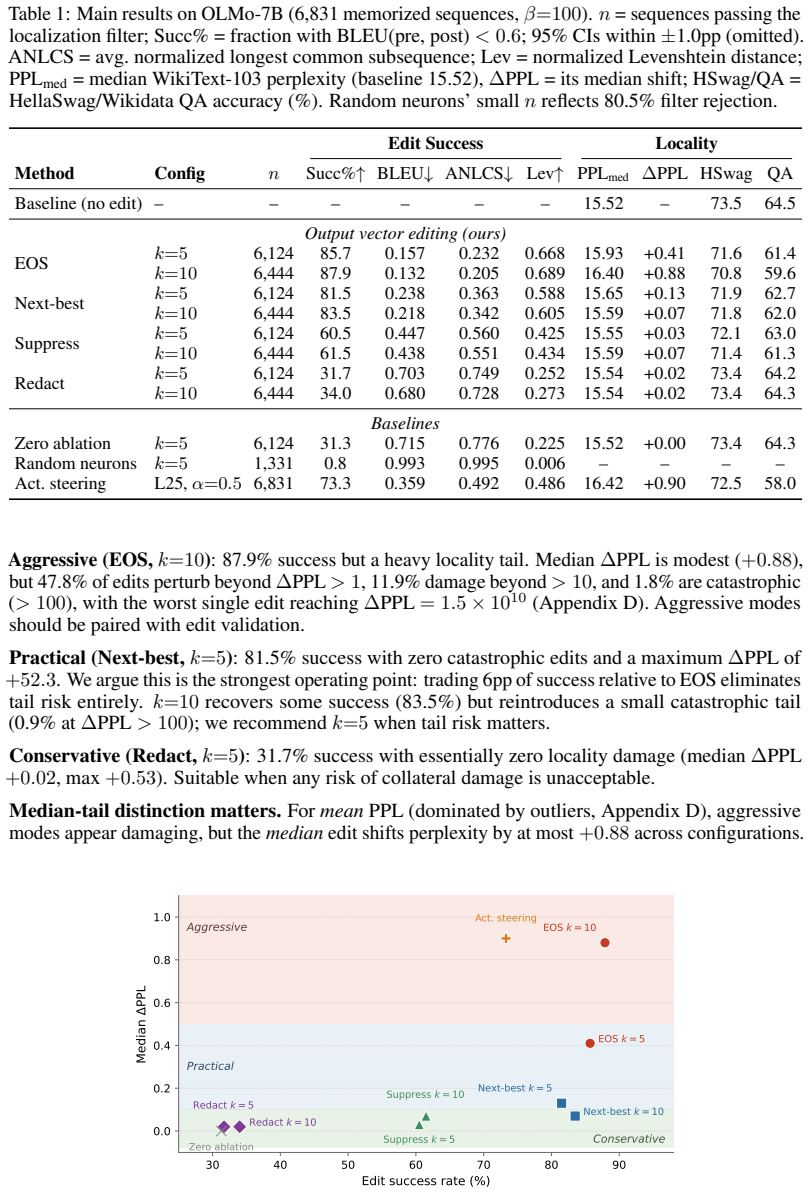
- Four edit modes span aggressive suppression to minimal redirection, with their ensemble covering 96.5% of memorized sequences.
- A single recommended mode reaches 81.5% success with no catastrophic locality failures.
- Success rates scale with model size rather than model family across 360M to 7B parameters.
- About 14% of sequences remain unreachable by MLP-only editing, though attention ablation recovers 60-64% of them.
Where Pith is reading between the lines
- Attention mechanisms could serve as a complementary fallback for the 14% of sequences that resist MLP editing.
- The same output-vector approach might apply to other unwanted model behaviors such as generating toxic text.
- Similar edits performed at inference time could avoid permanent changes to model weights.
Load-bearing premise
The neuron localization step reliably identifies the responsible neurons without post-hoc selection inflating the reported gap over zero ablation.
What would settle it
Zero ablation on the same located neurons produces suppression rates within 10-15% of the output vector edit rates, or attention head ablation fails to recover 60-64% of the sequences unreachable by MLP editing.
Figures

read the original abstract
Large language models memorize and reproduce sequences from their training data, creating privacy, copyright, and security risks. Existing neuron-level mitigation methods equate editing with zeroing out neuron activations, but the activation only controls whether a neuron engages; the output vector is what writes to the residual stream and, through superposition, encodes multiple features. We propose output vector editing, a constrained-optimization weight edit that locates a small set of MLP neurons responsible for a memorized continuation and minimally modifies their output vectors to introduce a distractor in vocabulary space, redirecting their residual-stream contributions while leaving activations unchanged. Evaluating on four models from 360M to 7B parameters (SmolLM-360M, OLMo-1B, OLMo-7B, Llama2-7B), we center on OLMo-7B (whose open weights and pretraining corpus enable systematic mining) and mine 6831 memorized sequences, achieving up to 87.9% suppression. The 2.7$\times$ gap over zero ablation on the same located neurons shows the suppression comes from the output-vector edit, not localization alone. Four edit modes span a spectrum from aggressive suppression to minimal redirection; in ensemble they cover 96.5% of memorized sequences, while our recommended single-mode configuration reaches 81.5% with no catastrophic locality failures. We further identify a mechanistic boundary at ${\sim}14%$ of sequences unreachable by MLP-only editing; while these failures are not attention-driven overall, ablating the top contributing attention heads recovers 60--64% of them, with stronger recovery on continuations that copy tokens from the prefix, positioning attention as a complementary fallback rather than a primary mechanism. Edit mode ordering and the success-locality trade-off transfer across all four models, with success rates scaling with model size rather than family.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes output vector editing, a constrained-optimization weight edit that identifies a small set of MLP neurons responsible for a memorized continuation and minimally modifies their output vectors to introduce a distractor in vocabulary space. This redirects residual-stream contributions while leaving activations unchanged. On OLMo-7B (and three other models), it reports up to 87.9% suppression on 6831 mined sequences, a 2.7× gap over zero ablation on the same neurons, 96.5% coverage via an ensemble of four edit modes, and a ~14% set of sequences better addressed by attention ablation as a complementary mechanism. The method is claimed to transfer across model sizes with success rates scaling with scale.
Significance. If the localization procedure is pre-specified and independent of edit outcomes, the work provides a targeted, activation-preserving alternative to zero-ablation for memorization mitigation that could improve locality-effectiveness trade-offs. The cross-model evaluation, explicit comparison to zero ablation, and identification of an MLP/attention boundary constitute concrete empirical contributions. The absence of error bars, sequence-mining details, and an explicit independence guarantee for neuron selection, however, limits the strength of the central attribution claim.
major comments (3)
- [Abstract] Abstract: The central claim that 'the 2.7× gap over zero ablation on the same located neurons shows the suppression comes from the output-vector edit, not localization alone' is load-bearing. The manuscript provides no explicit statement or procedure guaranteeing that neuron localization (via importance scores, gradients, or thresholds) was performed and fixed independently of observing edit success; post-hoc selection of neurons whose output vectors are easy to redirect would artifactually inflate the gap.
- [Abstract] Abstract: The evaluation rests on 6831 mined memorized sequences, yet no description is given of the mining/filtering algorithm, the exact criterion for deeming a continuation 'memorized,' the search procedure over the pretraining corpus, or any exclusion rules. This directly affects reproducibility of the 87.9% suppression figure and the claimed generality.
- [Abstract] Abstract: Key quantitative results (87.9% suppression, 2.7× gap, 96.5% ensemble coverage, 81.5% single-mode) are reported without error bars, standard deviations across runs or sequences, or statistical significance tests, making it impossible to assess whether the reported advantage over zero ablation is reliable.
minor comments (2)
- [Abstract] Abstract: The four edit modes are referenced as spanning 'aggressive suppression to minimal redirection' but are neither named nor briefly characterized, hindering reader understanding of the spectrum and the recommended single-mode configuration.
- The abstract states that edit-mode ordering and success-locality trade-offs transfer across models, but provides no quantitative transfer metrics or tables; a short summary table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The three major comments identify important gaps in documentation that affect reproducibility and the strength of our central claims. We address each point below and commit to revisions that will incorporate the requested details without altering the core methodology or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the 2.7× gap over zero ablation on the same located neurons shows the suppression comes from the output-vector edit, not localization alone' is load-bearing. The manuscript provides no explicit statement or procedure guaranteeing that neuron localization (via importance scores, gradients, or thresholds) was performed and fixed independently of observing edit success; post-hoc selection of neurons whose output vectors are easy to redirect would artifactually inflate the gap.
Authors: We agree that an explicit independence guarantee is required to support the claim. Neuron localization was performed using a fixed, pre-specified gradient-based importance scoring procedure applied to the loss on the target continuation; this scoring and threshold selection occurred for all sequences prior to any editing experiments, with the same neuron sets then used for both zero ablation and output vector editing. No post-hoc filtering based on edit success was applied. We will add a dedicated Methods subsection with a step-by-step description, pseudocode, and a diagram illustrating the separation between localization and editing phases. revision: yes
-
Referee: [Abstract] Abstract: The evaluation rests on 6831 mined memorized sequences, yet no description is given of the mining/filtering algorithm, the exact criterion for deeming a continuation 'memorized,' the search procedure over the pretraining corpus, or any exclusion rules. This directly affects reproducibility of the 87.9% suppression figure and the claimed generality.
Authors: We will include a complete description of the mining procedure in the revised manuscript. This will cover the search algorithm over the pretraining corpus, the exact memorization criterion (exact continuation match), all filtering steps, and exclusion rules. The details will appear in the Experimental Setup section with pseudocode to enable full reproducibility of the 6831-sequence set. revision: yes
-
Referee: [Abstract] Abstract: Key quantitative results (87.9% suppression, 2.7× gap, 96.5% ensemble coverage, 81.5% single-mode) are reported without error bars, standard deviations across runs or sequences, or statistical significance tests, making it impossible to assess whether the reported advantage over zero ablation is reliable.
Authors: We agree that statistical reporting is necessary. In the revision we will add standard deviations across the 6831 sequences (and across edit modes where relevant) to all reported figures and tables, include error bars in the main result plots, and report the outcome of a paired statistical test (Wilcoxon signed-rank) on the per-sequence suppression rates to establish the reliability of the 2.7× gap. revision: yes
Circularity Check
No circularity: empirical comparison to zero ablation provides independent benchmark
full rationale
The paper's central result is an empirical demonstration that output-vector editing on located neurons achieves 2.7× the suppression of zero ablation on the identical neurons. This comparison is external to the editing procedure itself and does not reduce any claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. No equations, ansatzes, or localization criteria are shown to be defined in terms of the final suppression metric, and the method is evaluated across multiple models with reported transfer of ordering and trade-offs. The derivation chain therefore remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- neuron selection threshold or count
- distractor strength or optimization constraint
Reference graph
Works this paper leans on
-
[1]
Extracting Training Data from Large Language Models , booktitle =
Nicholas Carlini and Florian Tram. Extracting Training Data from Large Language Models , booktitle =. 2021 , url =
2021
-
[2]
Quantifying Memorization Across Neural Language Models , booktitle =
Nicholas Carlini and Daphne Ippolito and Matthew Jagielski and Katherine Lee and Florian Tram. Quantifying Memorization Across Neural Language Models , booktitle =. 2023 , url =
2023
-
[3]
Valentin Hartmann and Anshuman Suri and Vincent Bindschaedler and David Evans and Shruti Tople and Robert West , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.18362 , eprinttype =. 2310.18362 , timestamp =
-
[4]
Adversarial Attacks and Defenses in Large Language Models: Old and New Threats , booktitle =
Leo Schwinn and David Dobre and Stephan G. Adversarial Attacks and Defenses in Large Language Models: Old and New Threats , booktitle =. 2023 , url =
2023
-
[5]
Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., and Carlini, N
Katherine Lee and Daphne Ippolito and Andrew Nystrom and Chiyuan Zhang and Douglas Eck and Chris Callison. Deduplicating Training Data Makes Language Models Better , booktitle =. 2022 , url =. doi:10.18653/V1/2022.ACL-LONG.577 , timestamp =
-
[6]
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs , booktitle =
Abhimanyu Hans and John Kirchenbauer and Yuxin Wen and Neel Jain and Hamid Kazemi and Prajwal Singhania and Siddharth Singh and Gowthami Somepalli and Jonas Geiping and Abhinav Bhatele and Tom Goldstein , editor =. Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs , booktitle =. 2024 , url =
2024
-
[7]
Alexander Xiong and Xuandong Zhao and Aneesh Pappu and Dawn Song , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.05578 , eprinttype =. 2507.05578 , timestamp =
-
[8]
Knowledge Neurons in Pretrained Transformers
Damai Dai and Li Dong and Yaru Hao and Zhifang Sui and Baobao Chang and Furu Wei , editor =. Knowledge Neurons in Pretrained Transformers , booktitle =. 2022 , url =. doi:10.18653/V1/2022.ACL-LONG.581 , timestamp =
-
[9]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , editor =. Locating and Editing Factual Associations in. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , year =
2022
-
[10]
Andonian and Yonatan Belinkov and David Bau , title =
Kevin Meng and Arnab Sen Sharma and Alex J. Andonian and Yonatan Belinkov and David Bau , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[11]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva and Roei Schuster and Jonathan Berant and Omer Levy , editor =. Transformer Feed-Forward Layers Are Key-Value Memories , booktitle =. 2021 , url =. doi:10.18653/V1/2021.EMNLP-MAIN.446 , timestamp =
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[12]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham and Aidan Ewart and Logan Riggs Smith and Robert Huben and Lee Sharkey , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2309.08600 , eprinttype =. 2309.08600 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600 2023
-
[13]
Information Flow Routes: Automatically Interpreting Language Models at Scale , booktitle =
Javier Ferrando and Elena Voita , editor =. Information Flow Routes: Automatically Interpreting Language Models at Scale , booktitle =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.965 , timestamp =
-
[14]
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs
Peter Hase and Mohit Bansal and Been Kim and Asma Ghandeharioun , editor =. Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models , booktitle =. 2023 , url =
2023
-
[15]
The Twelfth International Conference on Learning Representations,
Jingcheng Niu and Andrew Liu and Zining Zhu and Gerald Penn , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[16]
The butterfly effect of model editing: Few edits can trigger large language models collapse
Wanli Yang and Fei Sun and Xinyu Ma and Xun Liu and Dawei Yin and Xueqi Cheng , editor =. The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.322 , timestamp =
-
[17]
Demystifying Verbatim Memorization in Large Language Models , booktitle =
Jing Huang and Diyi Yang and Christopher Potts , editor =. Demystifying Verbatim Memorization in Large Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.598 , timestamp =
-
[18]
Ali Satvaty and Suzan Verberne and Fatih Turkmen , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.02650 , eprinttype =. 2410.02650 , timestamp =
-
[19]
Deduplicating Training Data Mitigates Privacy Risks in Language Models , booktitle =
Nikhil Kandpal and Eric Wallace and Colin Raffel , editor =. Deduplicating Training Data Mitigates Privacy Risks in Language Models , booktitle =. 2022 , url =
2022
-
[20]
Copyright Traps for Large Language Models , booktitle =
Matthieu Meeus and Igor Shilov and Manuel Faysse and Yves. Copyright Traps for Large Language Models , booktitle =. 2024 , url =
2024
-
[21]
Understanding Transformer Memorization Recall Through Idioms
Adi Haviv and Ido Cohen and Jacob Gidron and Roei Schuster and Yoav Goldberg and Mor Geva , editor =. Understanding Transformer Memorization Recall Through Idioms , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EACL-MAIN.19 , timestamp =
-
[22]
Niklas Stoehr and Mitchell Gordon and Chiyuan Zhang and Owen Lewis , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2403.19851 , eprinttype =. 2403.19851 , timestamp =
-
[23]
Ilya Lasy and Peter Knees and Stefan Woltran , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.21588 , eprinttype =. 2506.21588 , timestamp =
-
[24]
Zico Kolter and Chiyuan Zhang , editor =
Pratyush Maini and Michael Curtis Mozer and Hanie Sedghi and Zachary Chase Lipton and J. Zico Kolter and Chiyuan Zhang , editor =. Can Neural Network Memorization Be Localized? , booktitle =. 2023 , url =
2023
-
[25]
Do Localization Methods Actually Localize Memorized Data in LLM s? A Tale of Two Benchmarks
Ting. Do Localization Methods Actually Localize Memorized Data in. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.NAACL-LONG.176 , timestamp =
-
[26]
Manan Suri and Nishit Anand and Amisha Bhaskar , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.06040 , eprinttype =. 2503.06040 , timestamp =
-
[27]
Hudson and Caleb Geniesse and Kyle Chard and Yaoqing Yang and Ian T
Mansi Sakarvadia and Aswathy Ajith and Arham Mushtaq Khan and Nathaniel C. Hudson and Caleb Geniesse and Kyle Chard and Yaoqing Yang and Ian T. Foster and Michael W. Mahoney , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[28]
Zhenliang Zhang and Xinyu Hu and Xiaojun Wan , editor =. Fortieth. 2026 , url =. doi:10.1609/AAAI.V40I41.40793 , timestamp =
-
[29]
Dirk Groeneveld and Iz Beltagy and Evan Pete Walsh and Akshita Bhagia and Rodney Kinney and Oyvind Tafjord and Ananya Harsh Jha and Hamish Ivison and Ian Magnusson and Yizhong Wang and Shane Arora and David Atkinson and Russell Authur and Khyathi Raghavi Chandu and Arman Cohan and Jennifer Dumas and Yanai Elazar and Yuling Gu and Jack Hessel and Tushar Kh...
-
[30]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[31]
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Mor Geva and Avi Caciularu and Kevin Ro Wang and Yoav Goldberg , editor =. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , booktitle =. 2022 , url =. doi:10.18653/V1/2022.EMNLP-MAIN.3 , timestamp =
-
[32]
Bill Yuchen Lin and Wangchunshu Zhou and Ming Shen and Pei Zhou and Chandra Bhagavatula and Yejin Choi and Xiang Ren , editor =. CommonGen:. Findings of the Association for Computational Linguistics:. 2020 , url =. doi:10.18653/V1/2020.FINDINGS-EMNLP.165 , timestamp =
-
[33]
Arthur Wuhrmann and Andrei Kucharavy and Anastasiia Kucherenko , editor =. Low-Perplexity. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop),. 2025 , url =. doi:10.18653/V1/2025.ACL-SRW.51 , timestamp =
-
[34]
Andr. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.25941 , eprinttype =. 2510.25941 , timestamp =
-
[35]
Model editing at scale leads to gradual and catastrophic forgetting
Akshat Gupta and Anurag Rao and Gopala Anumanchipalli , editor =. Model Editing at Scale leads to Gradual and Catastrophic Forgetting , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.902 , timestamp =
-
[36]
Shiqi Wang and Qi Wang and Runliang Niu and He Kong and Yi Chang , editor =. MicroEdit: Neuron-level Knowledge Disentanglement and Localization in Lifelong Model Editing , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.1719 , timestamp =
-
[37]
GeoEdit: Geometric Knowledge Editing for Large Language Models , booktitle =
Yujie Feng and Li. GeoEdit: Geometric Knowledge Editing for Large Language Models , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.676 , timestamp =
-
[38]
Alaa and Thomas Hartvigsen and Gopala Anumanchipalli , editor =
Akshat Gupta and Phudish Prateepamornkul and Maochuan Lu and Ahmed M. Alaa and Thomas Hartvigsen and Gopala Anumanchipalli , editor =. Lifelong Knowledge Editing requires Better Regularization , booktitle =. 2025 , url =
2025
-
[39]
Wes Gurnee and Neel Nanda and Matthew Pauly and Katherine Harvey and Dmitrii Troitskii and Dimitris Bertsimas , title =. Trans. Mach. Learn. Res. , volume =. 2023 , url =
2023
-
[40]
Modality-Aware Neuron Pruning for Unlearning in Multimodal Large Language Models , booktitle =
Zheyuan Liu and Guangyao Dou and Xiangchi Yuan and Chunhui Zhang and Zhaoxuan Tan and Meng Jiang , editor =. Modality-Aware Neuron Pruning for Unlearning in Multimodal Large Language Models , booktitle =. 2025 , url =
2025
-
[41]
Wu and Virginia Smith , title =
Shengyuan Hu and Yiwei Fu and Steven Z. Wu and Virginia Smith , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[42]
Large Language Model Unlearning , booktitle =
Yuanshun Yao and Xiaojun Xu and Yang Liu , editor =. Large Language Model Unlearning , booktitle =. 2024 , url =
2024
-
[43]
2022 , url =
Neel Nanda and Joseph Bloom , title =. 2022 , url =
2022
-
[44]
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , editor =. HellaSwag: Can a Machine Really Finish Your Sentence? , booktitle =. 2019 , url =. doi:10.18653/V1/P19-1472 , timestamp =
-
[45]
MEMIT-Merge: Addressing
Zilu Dong and Xiangqing Shen and Rui Xia , editor =. MEMIT-Merge: Addressing. Findings of the Association for Computational Linguistics,. 2025 , url =
2025
-
[46]
Interpreting
Nostalgebraist , journal=. Interpreting
-
[47]
Daphne Ippolito and Florian Tram. Preventing Generation of Verbatim Memorization in Language Models Gives a False Sense of Privacy , booktitle =. 2023 , url =. doi:10.18653/V1/2023.INLG-MAIN.3 , timestamp =
-
[48]
Kassem and Omar Mahmoud and Sherif Saad , editor =
Aly M. Kassem and Omar Mahmoud and Sherif Saad , editor =. Preserving Privacy Through Dememorization: An Unlearning Technique For Mitigating Memorization Risks In Language Models , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.265 , timestamp =
-
[49]
Tong Chen and Faeze Brahman and Jiacheng Liu and Niloofar Mireshghallah and Weijia Shi and Pang Wei Koh and Luke Zettlemoyer and Hannaneh Hajishirzi , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.14452 , eprinttype =. 2504.14452 , timestamp =
-
[50]
Luca Soldaini and Rodney Kinney and Akshita Bhagia and Dustin Schwenk and David Atkinson and Russell Authur and Ben Bogin and Khyathi Raghavi Chandu and Jennifer Dumas and Yanai Elazar and Valentin Hofmann and Ananya Harsh Jha and Sachin Kumar and Li Lucy and Xinxi Lyu and Nathan Lambert and Ian Magnusson and Jacob Morrison and Niklas Muennighoff and Aaka...
-
[51]
Aarohi Srivastava and others , title =. Trans. Mach. Learn. Res. , volume =. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.