Beyond Scalar Scores: Exploring LLM-based Metrics for Clinical Significance Evaluation in Radiology Reports
Pith reviewed 2026-06-26 21:13 UTC · model grok-4.3
The pith
Metrics trained on 4k synthesized radiology report pairs distinguish clinically significant errors more accurately than 32B-scale LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
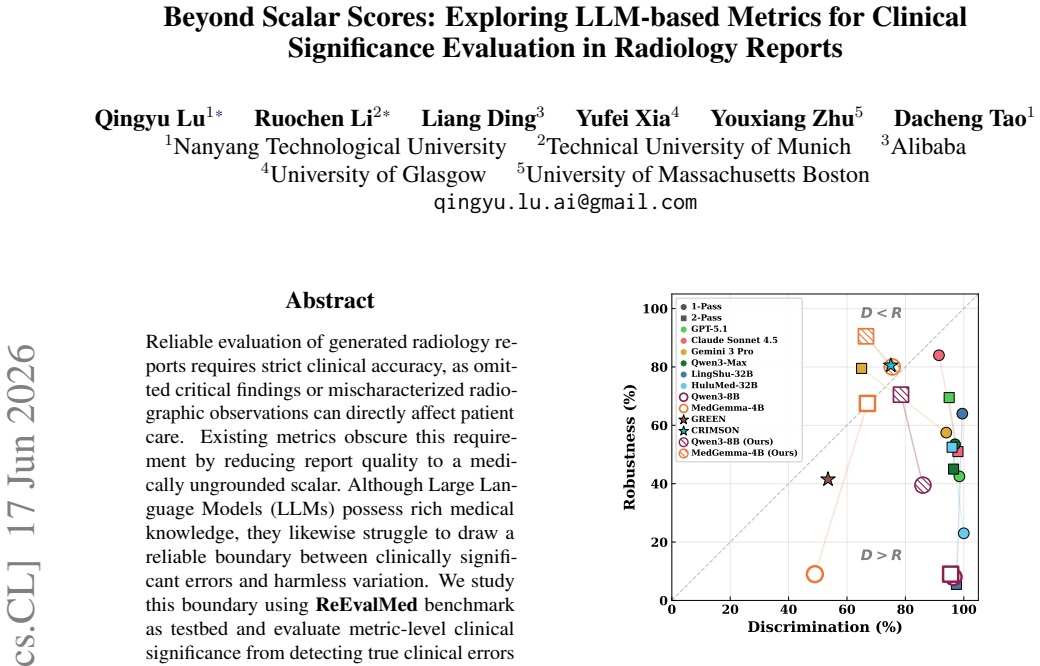
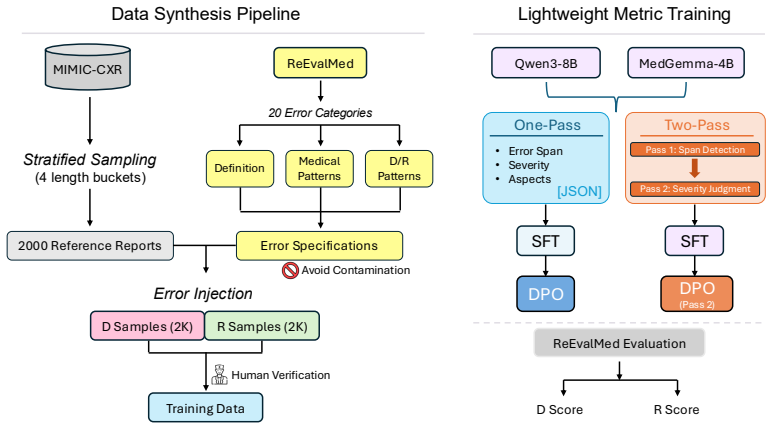
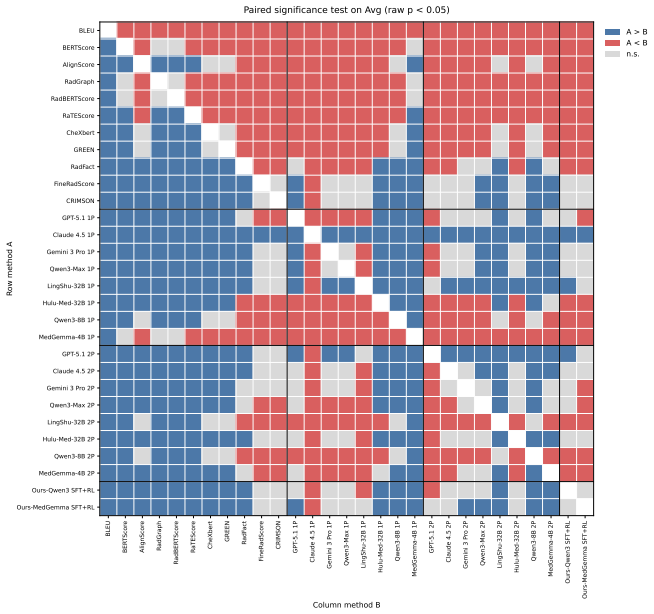
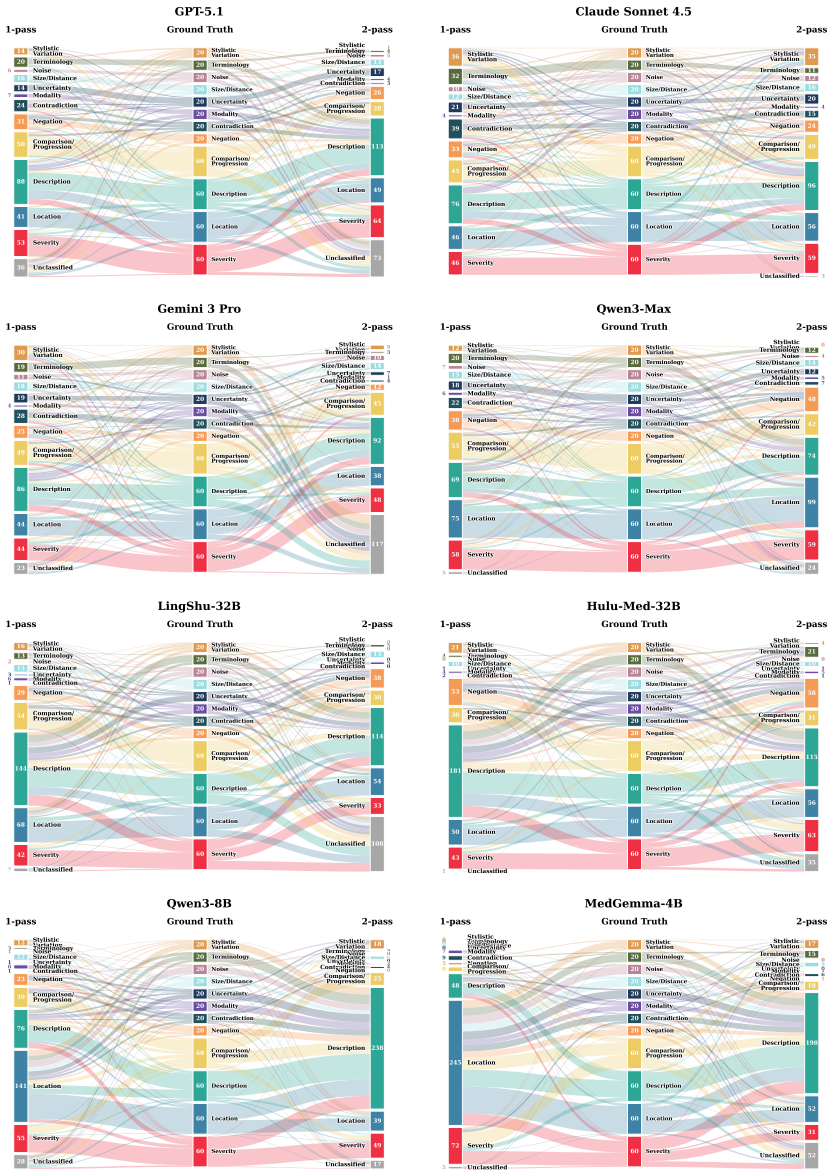
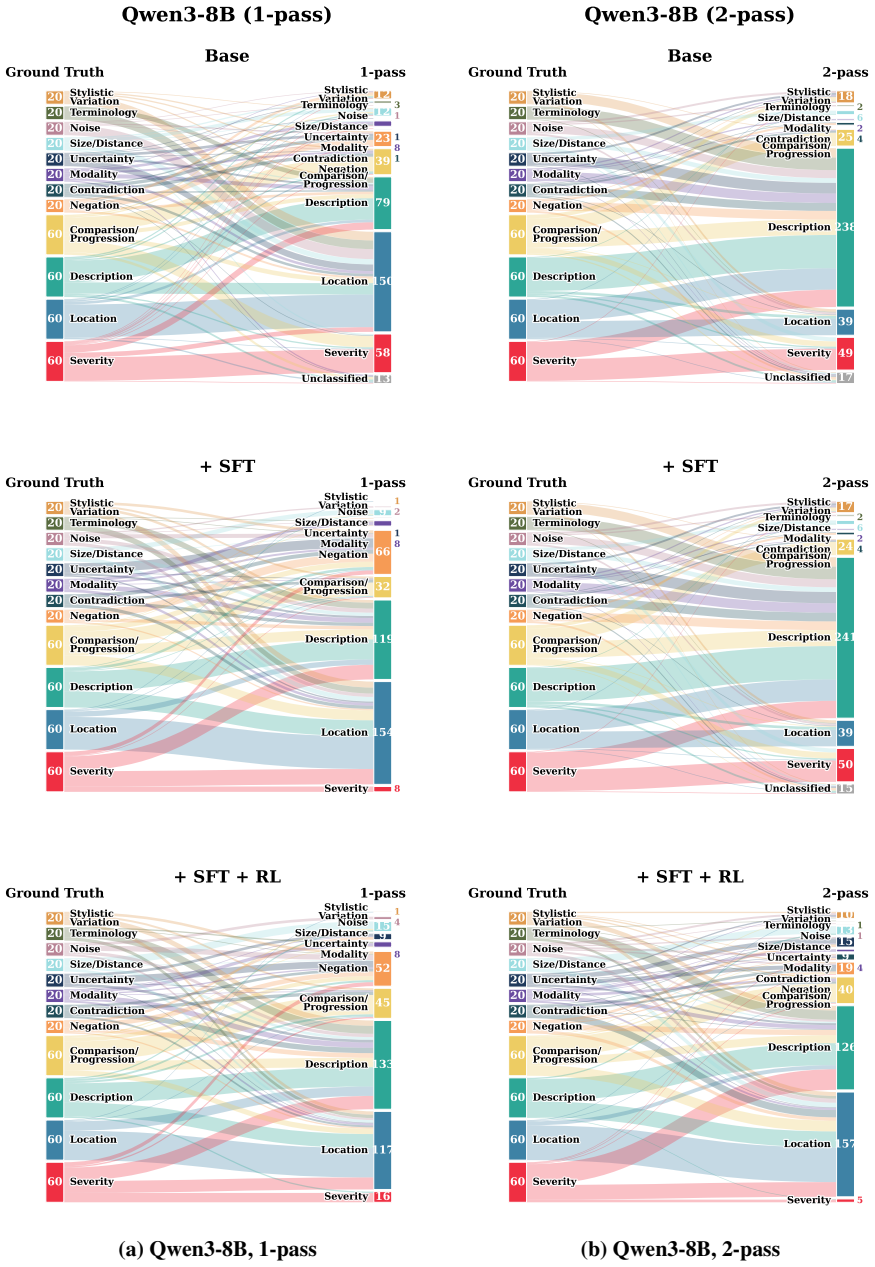
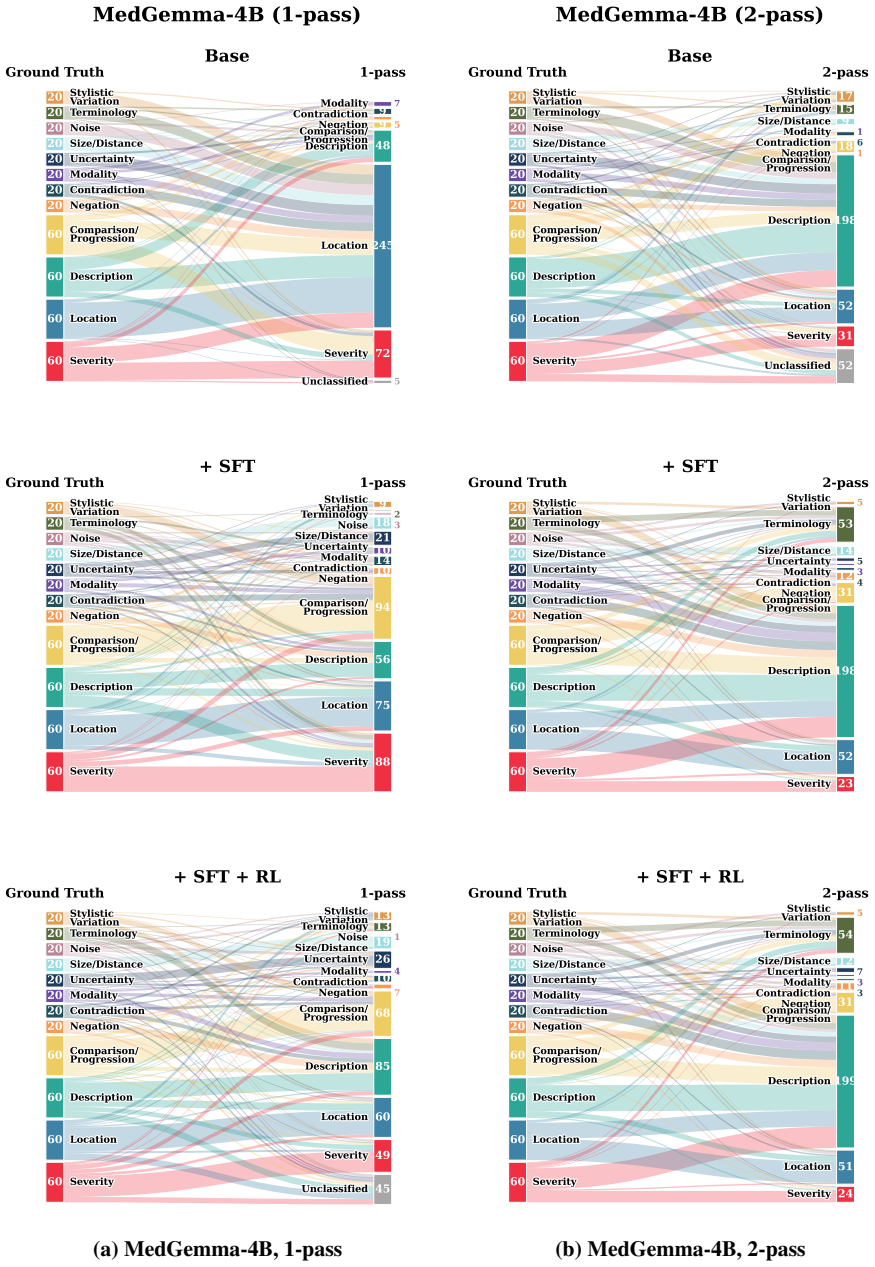
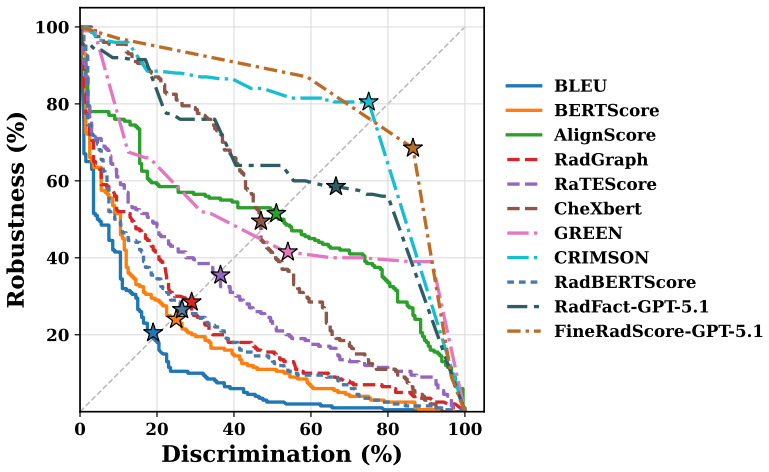
LLM evaluators exhibit a widespread discrimination bias by detecting clinical errors but also over-penalizing harmless rephrasings. Training lightweight interpretable metrics on Qwen3-8B and MedGemma-4B with 4k synthesized report pairs sharpens the clinical significance boundary, surpassing 32B-scale medical LLMs and remaining competitive with proprietary models. The more costly two-pass setting fails to consistently improve overall performance and mainly trades discrimination for robustness, making one-pass trained metrics the practical choice for cost-sensitive deployment.
What carries the argument
The ReEvalMed benchmark measuring discrimination and robustness, together with metrics trained on synthesized report pairs to enforce a clinical significance boundary.
If this is right
- One-pass trained metrics serve as the practical choice for cost-sensitive deployment.
- Two-pass inference should be reserved for settings where the discrimination-robustness balance is critical.
- Releasing the dataset and metric enables further development of clinically grounded evaluation tools.
- Scalar scores alone are insufficient; evaluation must explicitly separate true clinical impact from rephrasing.
Where Pith is reading between the lines
- Better boundary detection could reduce the chance that AI-generated reports with harmful omissions reach clinical use.
- The synthesis method for creating balanced training pairs might transfer to evaluating notes in other medical domains.
- Lower-cost one-pass metrics lower the barrier to routine automated review of radiology AI outputs.
Load-bearing premise
The 4k synthesized report pairs accurately model the distinction between clinically significant errors and insignificant variations so that the trained metrics generalize.
What would settle it
The trained metrics falling below baseline performance on a held-out collection of real radiology reports annotated by radiologists for clinical significance versus harmless variation.
Figures

read the original abstract
Reliable evaluation of generated radiology reports requires strict clinical accuracy, as omitted critical findings or mischaracterized radiographic observations can directly affect patient care. Existing metrics obscure this requirement by reducing report quality to a medically ungrounded scalar. Although Large Language Models (LLMs) possess rich medical knowledge, they likewise struggle to draw a reliable boundary between clinically significant errors and harmless variation. We study this boundary using ReEvalMed benchmark as testbed and evaluate metric-level clinical significance from detecting true clinical errors ("Discrimination") and tolerating insignificant variations ("Robustness"). Across 8 LLM evaluators under one-pass and two-pass settings, we identify a widespread discrimination bias: models effectively detect errors but also over-penalize harmless rephrasings. To mitigate this, we synthesize 4k report pairs and train lightweight interpretable metrics on Qwen3-8B and MedGemma-4B. Our trained metric sharpens the clinical significance boundary, surpassing 32B-scale medical LLMs and remaining competitive with proprietary models. Crucially, the more costly two-pass setting fails to consistently improve overall performance and mainly trades discrimination for robustness. These findings suggest one-pass trained metrics as the practical choice for cost-sensitive deployment, with two-pass inference reserved for settings where D-R balance is critical. We will release the dataset and metric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ReEvalMed benchmark to evaluate how well LLM-based metrics can distinguish clinically significant errors from insignificant variations in radiology reports. It documents a discrimination bias across 8 LLM evaluators in one- and two-pass settings, synthesizes 4k report pairs to train lightweight interpretable metrics on Qwen3-8B and MedGemma-4B, and reports that these trained metrics surpass 32B-scale medical LLMs while remaining competitive with proprietary models. The work also concludes that one-pass inference is often preferable for cost-sensitive use.
Significance. If the reported gains on ReEvalMed hold under the detailed synthesis and labeling protocol now provided in the full manuscript, the paper offers a practical advance in moving radiology-report evaluation beyond ungrounded scalar scores toward clinically meaningful discrimination/robustness trade-offs. The explicit release of the dataset and trained metrics is a clear strength that supports reproducibility and external validation. The finding that two-pass inference does not consistently improve the D-R balance is a useful deployment insight.
minor comments (3)
- Abstract: the phrase 'surpassing 32B-scale medical LLMs' would benefit from a parenthetical listing of the exact comparator models and the primary metric (e.g., F1 or accuracy) on which the comparison is made.
- The manuscript states that the 4k pairs were synthesized and labeled; a one-sentence cross-reference in §3 to the exact labeling protocol (human vs. LLM-assisted) would improve traceability for readers concerned about circularity.
- Table or figure captions that report discrimination and robustness scores should explicitly note whether the numbers are macro-averaged across report types or stratified.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We appreciate the recognition of ReEvalMed as a practical advance for clinically meaningful evaluation of radiology reports, as well as the value placed on releasing the dataset and trained metrics for reproducibility.
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on synthesizing 4k report pairs (with synthesis, labeling, and expert review steps described in the full manuscript) to train lightweight metrics, then evaluating discrimination and robustness on the external ReEvalMed benchmark. Performance comparisons to 32B-scale LLMs and proprietary models are empirical and not forced by construction. No load-bearing self-citations, uniqueness theorems, ansatzes smuggled via citation, or fitted inputs renamed as predictions appear. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ReEvalMed benchmark serves as an appropriate testbed for assessing clinical significance in radiology reports.
- ad hoc to paper The synthesized 4k report pairs provide a reliable training signal for distinguishing clinical errors from variations.
Reference graph
Works this paper leans on
-
[1]
MQM - APE : Toward High-Quality Error Annotation Predictors with Automatic Post-Editing in LLM Translation Evaluators
Lu, Qingyu and Ding, Liang and Zhang, Kanjian and Zhang, Jinxia and Tao, Dacheng. MQM - APE : Toward High-Quality Error Annotation Predictors with Automatic Post-Editing in LLM Translation Evaluators. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[2]
G -eval: NLG evaluation using gpt-4 with better human alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[3]
and Chelala, Lydia and Straus, Christopher M and Chahine, Reve and Iii, Samuel G
Jiang, Yuyang and Chen, Chacha and Wang, Shengyuan and Li, Feng and Tang, Zecong and Mervak, Benjamin M. and Chelala, Lydia and Straus, Christopher M and Chahine, Reve and Iii, Samuel G. Armato and Tan, Chenhao. CLEAR : A Clinically Grounded Tabular Framework for Radiology Report Evaluation. Findings of the Association for Computational Linguistics: EMNLP...
-
[4]
Medical Image Analysis , volume=
PadChest: A large chest x-ray image dataset with multi-label annotated reports , author=. Medical Image Analysis , volume=. 2020 , doi=
2020
-
[5]
Journal of the American Medical Informatics Association , volume=
Preparing a collection of radiology examinations for distribution and retrieval , author=. Journal of the American Medical Informatics Association , volume=. 2016 , doi=
2016
-
[6]
Journal of Computing Science and Engineering , volume=
Design and Development of a Multimodal Biomedical Information Retrieval System , author=. Journal of Computing Science and Engineering , volume=. 2012 , doi=
2012
-
[7]
arXiv preprint arXiv:2405.19538 , year=
CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats , author=. arXiv preprint arXiv:2405.19538 , year=. doi:10.48550/arXiv.2405.19538 , url=
-
[8]
and Yu, Juntao and Zhang, Le , booktitle=
Li, Siyou and Qin, Pengyao and Wu, Huanan and Nie, Dong and Thirunavukarasu, Arun J. and Yu, Juntao and Zhang, Le , booktitle=. 2025 , url=
2025
-
[9]
Xu, Justin and Zhang, Xi and Abderezaei, Javid and Bauml, Julie and Boodoo, Roger and Haghighi, Fatemeh and Ganjizadeh, Ali and Brattain, Eric and Van Veen, Dave and Meng, Zaiqiao and Eyre, David W and Delbrouck, Jean-Benoit , booktitle=. 2025 , address=. doi:10.18653/v1/2025.emnlp-demos.40 , url=
-
[10]
Proceedings of the 9th Machine Learning for Healthcare Conference , series=
FineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores , author=. Proceedings of the 9th Machine Learning for Healthcare Conference , series=. 2024 , publisher=
2024
-
[11]
VERT: Reliable LLM Judges for Radiology Report Evaluation
VERT: Reliable LLM Judges for Radiology Report Evaluation , author=. arXiv preprint arXiv:2604.03376 , year=. doi:10.48550/arXiv.2604.03376 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03376
-
[12]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Reevalmed: Rethinking medical report evaluation by aligning metrics with real-world clinical judgment , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , url=
2025
-
[13]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=. 2002 , url=
2002
-
[14]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
CREPE: Rapid Chest X-ray Report Evaluation by Predicting Multi-category Error Counts , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , url=
2025
-
[15]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=. 2004 , url=
2004
-
[16]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=. 2005 , url=
2005
-
[17]
arXiv preprint arXiv:1901.07042 , year=
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs , author=. arXiv preprint arXiv:1901.07042 , year=
Pith/arXiv arXiv 1901
-
[18]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Combining automatic labelers and expert annotations for accurate radiology report labeling using BERT , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=. 2020 , url=
2020
-
[19]
arXiv preprint arXiv:2106.14463 , year=
Radgraph: Extracting clinical entities and relations from radiology reports , author=. arXiv preprint arXiv:2106.14463 , year=
-
[20]
arXiv preprint arXiv:1904.09675 , year=
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
Pith/arXiv arXiv 1904
-
[21]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=. 2023 , url=
2023
-
[22]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[23]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[24]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[25]
arXiv preprint arXiv:2310.17631 , year=
Judgelm: Fine-tuned large language models are scalable judges , author=. arXiv preprint arXiv:2310.17631 , year=
-
[26]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Generating radiology reports via memory-driven transformer , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=. 2020 , url=
2020
-
[27]
Findings of the association for computational linguistics: EMNLP 2024 , pages=
Green: Generative radiology report evaluation and error notation , author=. Findings of the association for computational linguistics: EMNLP 2024 , pages=. 2024 , url=
2024
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Interactive and explainable region-guided radiology report generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=. 2023 , url=
2023
-
[29]
arXiv preprint arXiv:2311.13668 , year=
Maira-1: A specialised large multimodal model for radiology report generation , author=. arXiv preprint arXiv:2311.13668 , year=
-
[30]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Ratescore: A metric for radiology report generation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , url=
2024
-
[31]
Advances in Neural Information Processing Systems , volume=
Llava-med: Training a large language-and-vision assistant for biomedicine in one day , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[32]
arXiv preprint arXiv:2406.04449 , year=
Maira-2: Grounded radiology report generation , author=. arXiv preprint arXiv:2406.04449 , year=
-
[33]
AAAI 2024 Spring Symposium on Clinical Foundation Models , year=
Chexagent: Towards a foundation model for chest x-ray interpretation , author=. AAAI 2024 Spring Symposium on Clinical Foundation Models , year=
2024
-
[34]
Nature Medicine , volume=
Collaboration between clinicians and vision--language models in radiology report generation , author=. Nature Medicine , volume=. 2025 , publisher=
2025
-
[35]
arXiv preprint arXiv:2506.07044 , year=
Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning , author=. arXiv preprint arXiv:2506.07044 , year=
-
[36]
arXiv preprint arXiv:2510.08668 , year=
Hulu-med: A transparent generalist model towards holistic medical vision-language understanding , author=. arXiv preprint arXiv:2510.08668 , year=
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Error analysis prompting enables human-like translation evaluation in large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , url=
2024
-
[38]
Proceedings of the Eighth Conference on Machine Translation , pages=
GEMBA-MQM: Detecting translation quality error spans with GPT-4 , author=. Proceedings of the Eighth Conference on Machine Translation , pages=. 2023 , url=
2023
-
[39]
Findings of the Association for Computational Linguistics: EMNLP , volume=
MediVLM: A Vision Language Model for Radiology Report Generation from Medical Images , author=. Findings of the Association for Computational Linguistics: EMNLP , volume=. 2025 , url=
2025
-
[40]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
AlignScore: Evaluating factual consistency with a unified alignment function , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2023 , url=
2023
-
[41]
arXiv preprint arXiv:2603.06183 , year=
CRIMSON: A Clinically-Grounded LLM-Based Metric for Generative Radiology Report Evaluation , author=. arXiv preprint arXiv:2603.06183 , year=
-
[42]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=. 2022 , url=
2022
-
[43]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =. 2106.09685 , archivePrefix =
Pith/arXiv arXiv 2022
-
[44]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Orpo: Monolithic preference optimization without reference model , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , url=
2024
-
[45]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=. 2024 , url=
2024
-
[46]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=. 2023 , url=
2023
-
[47]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[48]
Toward More Effective Human Evaluation for Machine Translation
Sald \'i as Fuentes, Bel \'e n and Foster, George and Freitag, Markus and Tan, Qijun. Toward More Effective Human Evaluation for Machine Translation. Proceedings of the 2nd Workshop on Human Evaluation of NLP Systems (HumEval). 2022. doi:10.18653/v1/2022.humeval-1.7
-
[49]
arXiv preprint arXiv:2507.05201 , year=
Medgemma technical report , author=. arXiv preprint arXiv:2507.05201 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.