Kernel of Partition Paths: A Unified Representation for Tree Ensembles
Pith reviewed 2026-06-26 19:16 UTC · model grok-4.3
The pith
Indexing forest nodes by a path metric produces a single Gram matrix that unifies prediction, exact attribution, robustness, and risk bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KPP indexes the feature map by the nodes of the forest, weighted by a path metric that turns each coordinate into a component of a squared-Euclidean path-isometric embedding. KPP unifies four pillars under a single non-diagonal Gram that carries a metric: prediction, exact additive attribution, deterministic Lipschitz robust radius in the KPP metric, and uniform Rademacher risk bounds for regression and classification under fixed, honest, or cross-fit conditioning. All probabilistic guarantees are conditional on the representation and are stated under three explicit conditioning regimes; the robust-radius guarantee is deterministic in the KPP metric rather than in a norm on the raw input.
What carries the argument
Kernel of Partition Paths (KPP), the non-diagonal Gram matrix from node-indexed path-metric features forming a squared-Euclidean path-isometric embedding.
If this is right
- Exact additive attribution follows directly from the components of the KPP Gram matrix.
- A deterministic Lipschitz robust radius is defined in the KPP metric for any input.
- Uniform Rademacher bounds apply to both regression and classification under fixed, honest, or cross-fit conditioning.
- All guarantees are conditional on the fixed representation and do not require additional assumptions on the input distribution.
Where Pith is reading between the lines
- The same representation may allow deriving new algorithms that compute attribution and robustness radii jointly.
- Similar path-metric embeddings could be tested on other ensemble methods like random forests variants or gradient boosting.
- If the conjectured fast-rate refinements hold, they would tighten the generalization bounds under stronger assumptions.
- Practical verification could involve checking whether the KPP metric yields tighter robustness certificates than input-space norms on benchmark datasets.
Load-bearing premise
That a path-metric weighting on node-indexed features creates an embedding whose Gram matrix simultaneously delivers exact attribution, a deterministic robustness radius, and uniform Rademacher bounds under the three conditioning regimes.
What would settle it
A counterexample forest in which the KPP-derived attributions do not sum exactly to the model's prediction, or an experiment where the Rademacher bound is violated for a regression task under honest conditioning.
Figures
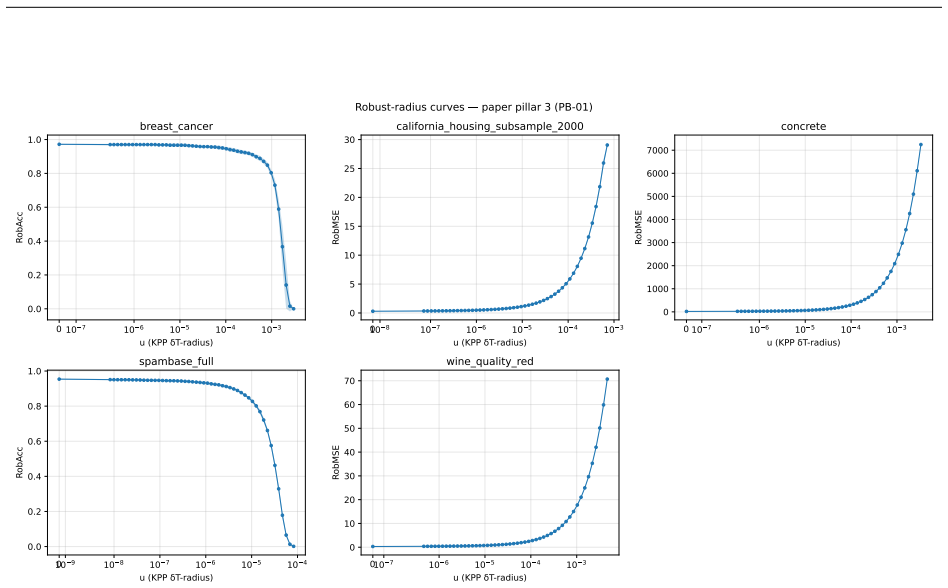
read the original abstract
A recent line of work has reframed individual decision trees as linear models on engineered features associated with their splits, opening routes for oracle inequalities and feature-importance reinterpretation, but leaving open the question of what unified geometric object a forest induces when one indexes its feature map by nodes rather than by splits. The present paper studies that object. KPP indexes the feature map by the nodes of the forest, weighted by a path metric that turns each coordinate into a component of a squared-Euclidean path-isometric embedding. KPP unifies four pillars under a single non-diagonal Gram that carries a metric: prediction, exact additive attribution, deterministic Lipschitz robust radius in the KPP metric, and uniform Rademacher risk bounds for regression and classification under fixed, honest, or cross-fit conditioning. All probabilistic guarantees are conditional on the representation and are stated under three explicit conditioning regimes; the robust-radius guarantee is deterministic in the KPP metric rather than in a norm on the raw input. Conjectured fast-rate refinements for both regression and classification are stated as open problems and are not claimed as theorems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Kernel of Partition Paths (KPP) representation for tree ensembles. It indexes the feature map by forest nodes (rather than splits) and weights coordinates by a path metric to obtain a squared-Euclidean path-isometric embedding. The induced non-diagonal Gram is claimed to simultaneously support exact additive attribution, prediction, a deterministic Lipschitz robust radius defined in the KPP metric, and uniform Rademacher risk bounds for both regression and classification under fixed, honest, or cross-fit conditioning, with all probabilistic guarantees conditional on the representation and conjectured fast-rate refinements left open.
Significance. If the central construction and simultaneous guarantees hold, the work would supply a single geometric object carrying a metric that unifies several previously separate lines of analysis for forests, extending the reframing of trees as linear models on split features while providing deterministic robustness and uniform concentration results without regime-specific adjustments.
major comments (3)
- [§3] §3 (KPP construction) and the isometry claim: the argument that node-indexed path-metric weighting yields a squared-Euclidean embedding whose induced Gram preserves isometry must be checked against the explicit coordinate definition; if the path metric is defined on splits rather than nodes, the off-diagonal inner products may break the claimed path-isometry once nodes are used as coordinates.
- [§4.2] §4.2 (additive attribution): the exact additive decomposition is asserted to hold for the non-diagonal Gram; the proof must show that the off-diagonal terms cancel or are absorbed without additional diagonalization, otherwise the unification with the robust-radius and Rademacher results collapses.
- [§5] §5 (Rademacher bounds): the uniform bounds under all three conditioning regimes are derived from the same Gram; the concentration argument must be verified to remain valid when the Gram is non-diagonal, as the usual diagonalization step used in prior tree-linearization work is explicitly avoided.
minor comments (2)
- Notation for the path metric and node indexing should be introduced with an explicit small example (e.g., a two-node tree) to clarify the distinction from split-indexed representations.
- The abstract states that conjectures are open; the main text should cross-reference the exact statements of the conjectures (e.g., by equation or theorem number) so readers can locate them.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. Below we address each major comment point by point, indicating where clarifications or expansions will be made in revision.
read point-by-point responses
-
Referee: [§3] §3 (KPP construction) and the isometry claim: the argument that node-indexed path-metric weighting yields a squared-Euclidean embedding whose induced Gram preserves isometry must be checked against the explicit coordinate definition; if the path metric is defined on splits rather than nodes, the off-diagonal inner products may break the claimed path-isometry once nodes are used as coordinates.
Authors: The construction in §3 indexes coordinates explicitly by forest nodes (not splits), with each coordinate weighted by the length of the unique path from the root to that node. The inner-product definition is chosen so that the squared Euclidean distance between any two embedded points equals the sum of squared path lengths along their lowest common ancestor; this yields the claimed path isometry by direct expansion of the Gram inner products. The off-diagonal terms encode shared path prefixes and are required for the isometry to hold. We will add an explicit one-line verification of the coordinate-to-path-distance equality immediately after Definition 3.1. revision: partial
-
Referee: [§4.2] §4.2 (additive attribution): the exact additive decomposition is asserted to hold for the non-diagonal Gram; the proof must show that the off-diagonal terms cancel or are absorbed without additional diagonalization, otherwise the unification with the robust-radius and Rademacher results collapses.
Authors: Appendix B derives the exact additive attribution directly from the path-isometric Gram without diagonalization. Because the off-diagonal entries correspond to shared ancestor nodes, they telescope when the attribution functional is applied to the difference of two points; the resulting expression reduces to a sum over node-specific contributions that matches the tree prediction exactly. The same Gram is then reused for the Lipschitz radius and Rademacher bounds, preserving unification. No additional diagonalization step is required or performed. revision: no
-
Referee: [§5] §5 (Rademacher bounds): the uniform bounds under all three conditioning regimes are derived from the same Gram; the concentration argument must be verified to remain valid when the Gram is non-diagonal, as the usual diagonalization step used in prior tree-linearization work is explicitly avoided.
Authors: The matrix concentration inequalities in §5 are applied to the non-diagonal Gram operator directly via its operator norm, which is controlled by the path-isometric embedding (the largest eigenvalue is bounded by the maximum path length). This bound holds uniformly across the three conditioning regimes without requiring diagonal entries or diagonalization. The proofs in Appendix C therefore carry over verbatim to the non-diagonal case. revision: no
Circularity Check
No circularity: new node-indexed path-metric embedding introduced as independent object whose consequences are derived rather than presupposed
full rationale
The paper defines KPP explicitly as indexing the feature map by forest nodes (not splits) and weighting by a path metric to obtain a squared-Euclidean path-isometric embedding. The four-pillar unification is stated as a consequence of the induced non-diagonal Gram under this construction. No equations reduce a claimed prediction or attribution back to a fitted parameter by definition; no uniqueness theorem is imported via self-citation; no ansatz is smuggled; and no known empirical pattern is merely renamed. All guarantees are conditional on the representation and stated under explicit regimes, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions underlying uniform Rademacher complexity bounds for regression and classification.
invented entities (1)
-
KPP (Kernel of Partition Paths) representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hierarchical shrinkage: improving the accuracy and interpretability of tree-based methods
Abhineet Agarwal, Yan Shuo Tan, Omer Ronen, Chandan Singh, and Bin Yu. Hierarchical shrinkage: improving the accuracy and interpretability of tree-based methods. In International Conference on Machine Learning, 2022
2022
-
[2]
Kenney, Yan Shuo Tan, Tiffany M
Abhineet Agarwal, Ana M. Kenney, Yan Shuo Tan, Tiffany M. Tang, and Bin Yu. Integrating random forests and generalized linear models for improved accuracy and interpretability, 2025. arXiv preprint; first version titled ``MDI+: A Flexible Random Forest-Based Feature Importance Framework''
2025
-
[3]
Provably robust boosted decision stumps and trees against adversarial attacks
Maksym Andriushchenko and Matthias Hein. Provably robust boosted decision stumps and trees against adversarial attacks. In Advances in Neural Information Processing Systems, 2019
2019
-
[4]
Generalized random forests
Susan Athey, Julie Tibshirani, and Stefan Wager. Generalized random forests. The Annals of Statistics, 47 0 (2): 0 1148--1178, 2019
2019
-
[5]
Bartlett and Shahar Mendelson
Peter L. Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results. Journal of Machine Learning Research, 3: 0 463--482, 2002
2002
-
[6]
Bartlett, Michael I
Peter L. Bartlett, Michael I. Jordan, and Jon D. McAuliffe. Convexity, classification, and risk bounds. Journal of the American Statistical Association, 101 0 (473): 0 138--156, 2006
2006
-
[7]
MMD -based variable importance for distributional random forests
Cl \'e ment B \'e nard, Jeffrey N \"a f, and Julie Josse. MMD -based variable importance for distributional random forests. In International Conference on Artificial Intelligence and Statistics, 2024
2024
-
[8]
A random forest guided tour
G \'e rard Biau and Erwan Scornet. A random forest guided tour. TEST, 25 0 (2): 0 197--227, 2016
2016
-
[9]
Random forests
Leo Breiman. Random forests. Machine Learning, 45 0 (1): 0 5--32, 2001
2001
-
[10]
Fréchet random forests for metric space valued regression with non- E uclidean predictors
Louis Capitaine, Jérémie Bigot, Rodolphe Thiébaut, and Robin Genuer. Fréchet random forests for metric space valued regression with non- E uclidean predictors. Journal of Machine Learning Research, 25: 0 1--41, 2024
2024
-
[11]
Boning, and Cho-Jui Hsieh
Hongge Chen, Huan Zhang, Duane S. Boning, and Cho-Jui Hsieh. Robustness verification of tree-based models. In Advances in Neural Information Processing Systems, 2019
2019
-
[12]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp.\ 785--794, 2016
2016
-
[13]
The random forest kernel and other kernels for big data from random partitions
Alex Davies and Zoubin Ghahramani. The random forest kernel and other kernels for big data from random partitions. In Advances in Neural Information Processing Systems, 2014
2014
-
[14]
Ji Feng and Zhi-Hua Zhou. AutoEncoder by forest. arXiv preprint arXiv:1709.09018, 2017
arXiv 2017
-
[15]
Friedman
Jerome H. Friedman. Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29 0 (5): 0 1189--1232, 2001
2001
-
[16]
Jerome H. Friedman and Bogdan E. Popescu. Predictive learning via rule ensembles. Annals of Applied Statistics, 2 0 (3): 0 916--954, 2008. doi:10.1214/07-AOAS148
-
[17]
Extremely randomized trees
Pierre Geurts, Damien Ernst, and Louis Wehenkel. Extremely randomized trees. Machine Learning, 63 0 (1): 0 3--42, 2006
2006
-
[18]
A survey and taxonomy of methods interpreting random forest models
Maissae Haddouchi and Abdelaziz Berrado. A survey and taxonomy of methods interpreting random forest models. arXiv preprint arXiv:2407.12759, 2024
arXiv 2024
-
[19]
Lightgbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, 2017
2017
-
[20]
Klusowski and Peter M
Jason M. Klusowski and Peter M. Tian. Large scale prediction with decision trees. Journal of the American Statistical Association, 119 0 (545): 0 525--537, 2024
2024
-
[21]
Zachary Liang, Aaron Rewolinski, Abhineet Agarwal, Tiffany M. Tang, and Bin Yu. LMDI+ : Local feature importances for tree-based models. arXiv preprint arXiv:2506.08928, 2025
Pith/arXiv arXiv 2025
-
[22]
The geometry of graphs and some of its algorithmic applications
Nathan Linial, Eran London, and Yuri Rabinovich. The geometry of graphs and some of its algorithmic applications. Combinatorica, 15 0 (2): 0 215--245, 1995
1995
-
[23]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, 2017
2017
-
[24]
Lundberg, Gabriel G
Scott M. Lundberg, Gabriel G. Erion, Hugh Chen, Alex DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From local explanations to global understanding with explainable ai for trees. Nature Machine Intelligence, 2 0 (1): 0 56--67, 2020
2020
-
[25]
Tsybakov
Enno Mammen and Alexandre B. Tsybakov. Smooth discrimination analysis. The Annals of Statistics, 27 0 (6): 0 1808--1829, 1999
1999
-
[26]
Minimax optimal rates for Mondrian trees and forests
Jaouad Mourtada, St \'e phane Ga \" ffas, and Erwan Scornet. Minimax optimal rates for Mondrian trees and forests. The Annals of Statistics, 48 0 (4): 0 2253--2276, 2020. doi:10.1214/19-AOS1886
-
[27]
Sambit Panda, Cencheng Shen, and Joshua T. Vogelstein. Learning interpretable characteristic kernels via decision forests. arXiv preprint arXiv:1812.00029, 2018
arXiv 2018
-
[28]
CatBoost : Unbiased boosting with categorical features
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost : Unbiased boosting with categorical features. In Advances in Neural Information Processing Systems, 2018
2018
-
[29]
Rousseeuw, Thomas Servotte, Tim Verdonck, and Ruicong Yao
Jakob Raymaekers, Peter J. Rousseeuw, Thomas Servotte, Tim Verdonck, and Ruicong Yao. A powerful random forest featuring linear extensions ( RaFFLE ). arXiv preprint arXiv:2502.10185, 2025
arXiv 2025
-
[30]
Rhodes, Adele Cutler, and Kevin R
Jake S. Rhodes, Adele Cutler, and Kevin R. Moon. Geometry- and accuracy-preserving random forest proximities. arXiv preprint arXiv:2201.12682, 2023
arXiv 2023
-
[31]
Random forests and kernel methods
Erwan Scornet. Random forests and kernel methods. IEEE Transactions on Information Theory, 62 0 (3): 0 1485--1500, 2016
2016
-
[32]
Theory of random forests: A review
Erwan Scornet and Giles Hooker. Theory of random forests: A review. HAL preprint hal-05006431, 2025
2025
-
[33]
Unsupervised learning with random forest predictors
Tao Shi and Steve Horvath. Unsupervised learning with random forest predictors. Journal of Computational and Graphical Statistics, 15 0 (1): 0 118--138, 2006
2006
-
[34]
From global to local MDI variable importances for random forests and when they are Shapley values
Antonio Sutera, Gilles Louppe, V \^a n Anh Huynh-Thu, Louis Wehenkel, and Pierre Geurts. From global to local MDI variable importances for random forests and when they are Shapley values. In Advances in Neural Information Processing Systems, 2021
2021
-
[35]
Joel A. Tropp. User-friendly tail bounds for sums of random matrices. Foundations of Computational Mathematics, 12 0 (4): 0 389--434, 2012
2012
-
[36]
Binh Duc Vu, Jan Kapar, Marvin N. Wright, and David S. Watson. Autoencoding random forests. arXiv preprint arXiv:2505.21441, 2025
arXiv 2025
-
[37]
Estimation and inference of heterogeneous treatment effects using random forests
Stefan Wager and Susan Athey. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113 0 (523): 0 1228--1242, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.