Sequential Kernel-based Conditional Independence Testing via Adaptive Betting
Pith reviewed 2026-06-26 19:07 UTC · model grok-4.3
The pith
A sequential conditional independence test using betting on an optimized kernel statistic tolerates small errors when the Model-X distribution must be estimated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
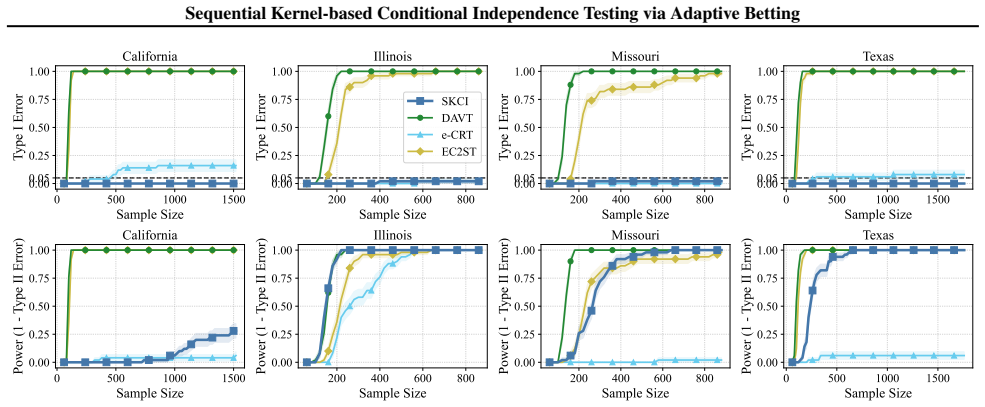
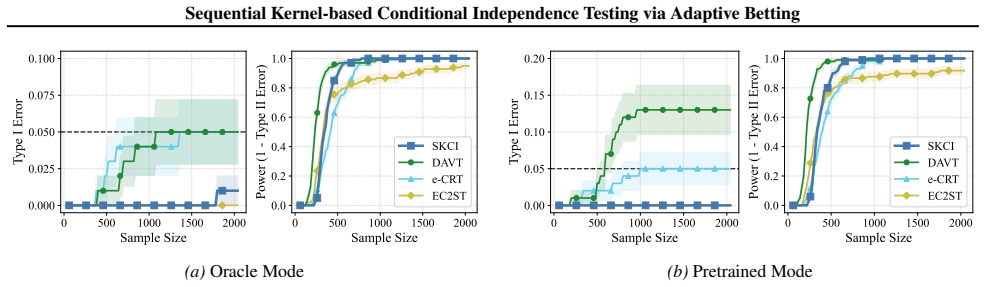
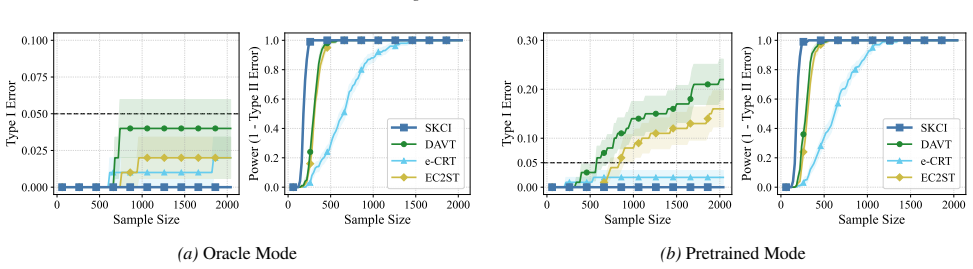
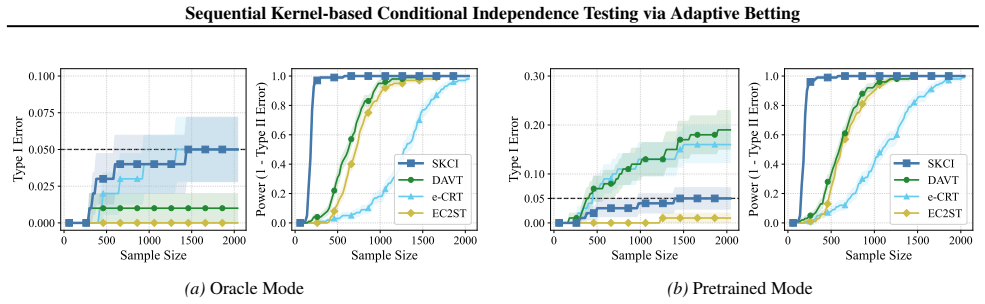
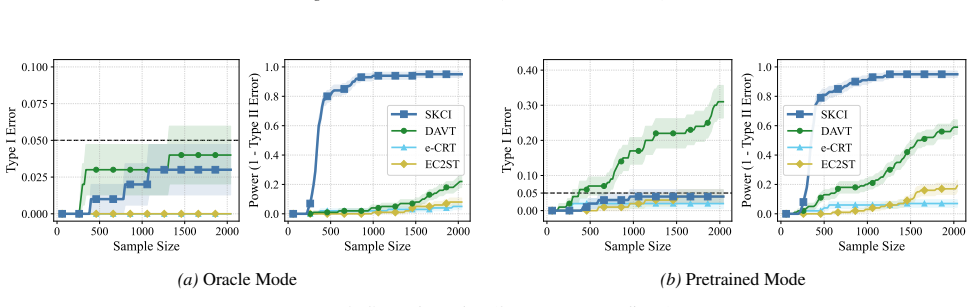
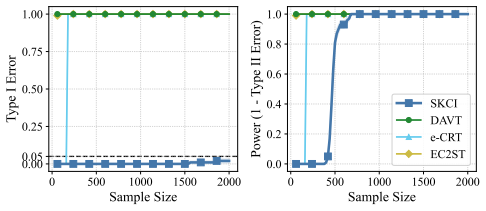
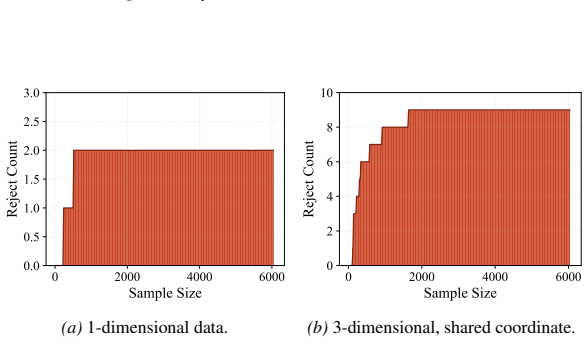
Applying testing-by-betting to an adaptively optimized Kernel Conditional Independence statistic, together with a normalization scheme and a truncate-and-shift calibration strategy, greatly reduces Type I error inflation while preserving high power across high-dimensional synthetic benchmarks and real-world fairness tasks, outperforming existing sequential Model-X approaches.
What carries the argument
Testing-by-betting applied to an adaptively optimized Kernel Conditional Independence statistic with normalization and truncate-and-shift calibration.
If this is right
- Sequential conditional independence testing becomes feasible when the Model-X conditional must be estimated from finite data.
- Type I error remains controlled in high-dimensional settings where prior sequential Model-X methods inflate false positives.
- Power stays competitive on fairness-related tasks that require repeated conditional independence checks.
- The method extends the range of problems where sequential testing can be applied without requiring exact knowledge of the null distribution.
Where Pith is reading between the lines
- Similar calibration tactics could improve robustness for other kernel-based sequential tests that rely on estimated null distributions.
- The framework may support online causal discovery pipelines in which conditional distributions are learned incrementally.
- Fairness auditing systems could run repeated conditional independence checks on streaming data with less risk of spurious rejections.
Load-bearing premise
The truncate-and-shift calibration together with adaptive optimization and normalization controls Type I error under small but unknown deviations from the exact Model-X conditional distribution.
What would settle it
A simulation in which the estimated conditional distribution deviates from the true one by a measurable amount and the observed Type I error rate exceeds the nominal level.
Figures
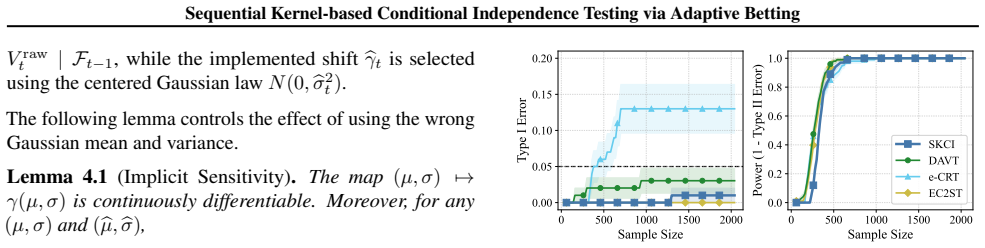
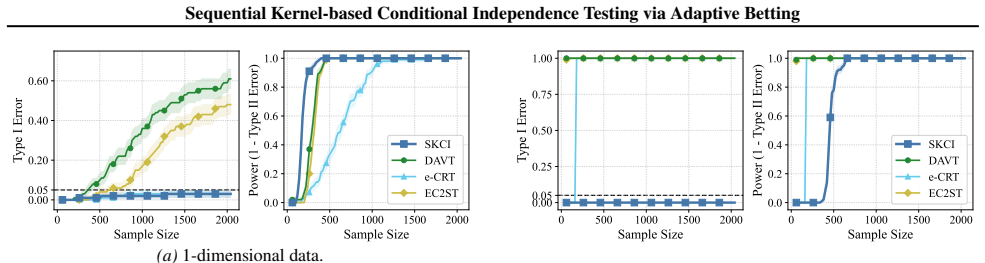
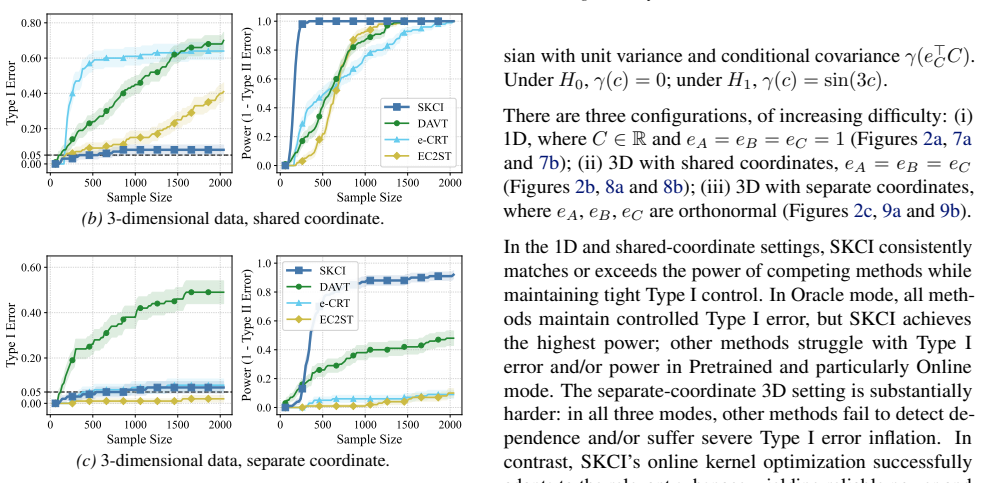
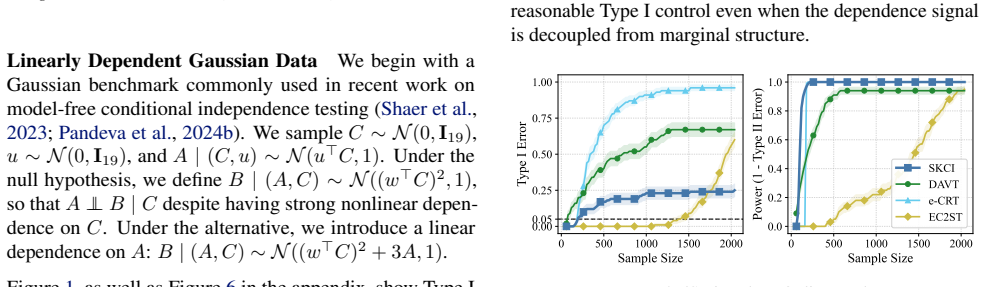
read the original abstract
Testing conditional independence is fundamental yet intrinsically difficult: without additional assumptions, Type I error control is impossible in general. The "Model-X'' paradigm addresses this difficulty by assuming exact knowledge of a relevant conditional distribution. While small deviations from this assumption can sometimes be tolerated in classical one-shot testing, existing sequential conditional independence tests typically require the Model-X conditional to be known exactly, making them fragile when it must instead be estimated. We propose a new approach that is substantially more robust to such estimation error. Our method applies testing-by-betting to an adaptively optimized Kernel Conditional Independence statistic, together with a normalization scheme and a truncate-and-shift calibration strategy. These modifications greatly reduce Type I error inflation while preserving high power across high-dimensional synthetic benchmarks and real-world fairness tasks, outperforming existing sequential Model-X approaches. Code is available at https://github.com/he-zh/SKCI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a sequential test for conditional independence that combines testing-by-betting with an adaptively optimized kernel CI statistic, a normalization scheme, and a truncate-and-shift calibration. The central claim is that these modifications yield a valid sequential test that is substantially more robust to small estimation errors in the Model-X conditional distribution than prior sequential Model-X methods, while retaining high power; this is supported by reduced Type I error inflation on high-dimensional synthetic benchmarks and real-world fairness tasks, with code released.
Significance. If the robustness claim holds, the work would meaningfully extend sequential nonparametric testing to practical Model-X settings where the conditional law must be estimated rather than known exactly. The release of reproducible code and the focus on both synthetic and fairness benchmarks are strengths that facilitate verification and adoption.
major comments (2)
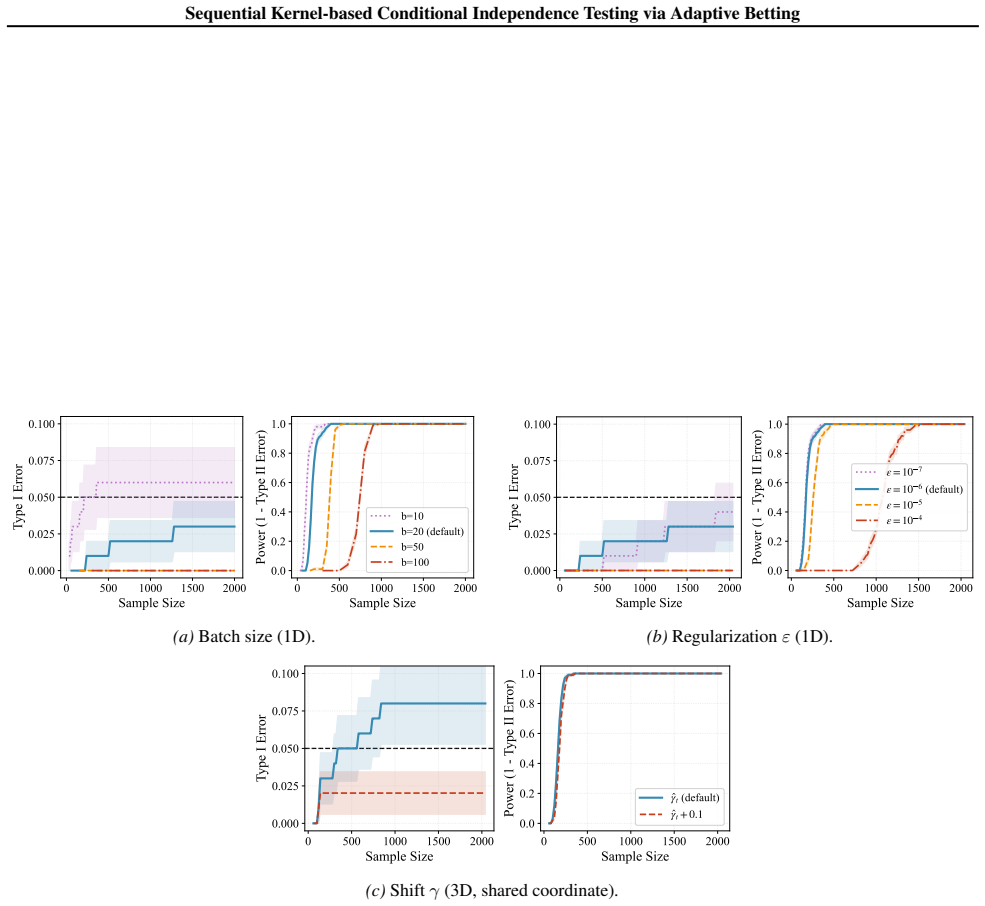
- [§3.3] §3.3 (Truncate-and-shift calibration): the manuscript presents the truncation threshold and shift as a practical modification that controls Type I error under approximate Model-X, yet provides no explicit argument or bound establishing that the resulting wealth process remains a supermartingale (i.e., E[bet_t | F_{t-1}] ≤ 1) when the plugged-in conditional distribution deviates from the true law by an unknown but small total-variation or Wasserstein distance. This is load-bearing for the robustness claim.
- [§4.2] §4.2 (Adaptive optimization of the kernel statistic): the normalization scheme is introduced to stabilize the betting fraction, but the derivation does not quantify how the adaptive choice of kernel parameters interacts with the truncation operator to preserve the supermartingale property under perturbations; the empirical Type I control on the reported benchmarks therefore rests on the specific regimes tested rather than a general guarantee.
minor comments (2)
- [Abstract] The abstract and §1 would benefit from a one-sentence statement of the precise sense in which the Model-X assumption is relaxed (e.g., bounded total variation).
- [Figure 3] Figure 3 caption should explicitly state the number of Monte Carlo repetitions and the exact perturbation magnitude used for the robustness panels.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of robustness in practical Model-X settings. We address the two major comments below, agreeing that additional clarification is warranted.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Truncate-and-shift calibration): the manuscript presents the truncation threshold and shift as a practical modification that controls Type I error under approximate Model-X, yet provides no explicit argument or bound establishing that the resulting wealth process remains a supermartingale (i.e., E[bet_t | F_{t-1}] ≤ 1) when the plugged-in conditional distribution deviates from the true law by an unknown but small total-variation or Wasserstein distance. This is load-bearing for the robustness claim.
Authors: We agree that the manuscript does not supply an explicit non-asymptotic bound showing the wealth process remains a supermartingale under small but unknown deviations from the Model-X law. The truncate-and-shift procedure is presented as a practical calibration whose validity is supported by the exact-Model-X supermartingale property together with empirical evidence that Type I error inflation is substantially reduced. In the revision we will add a clarifying paragraph in §3.3 stating the precise scope of the theoretical guarantee (exact Model-X) and include a short continuity argument: when the total-variation distance between the plugged-in and true conditional distributions is small, the kernel statistic changes continuously, so the expected bet remains close to 1; the truncation then caps any excess. We will also note that a fully rigorous bound for arbitrary small deviations would require further assumptions on the kernel bandwidth or deviation magnitude and flag this as future work. revision: partial
-
Referee: [§4.2] §4.2 (Adaptive optimization of the kernel statistic): the normalization scheme is introduced to stabilize the betting fraction, but the derivation does not quantify how the adaptive choice of kernel parameters interacts with the truncation operator to preserve the supermartingale property under perturbations; the empirical Type I control on the reported benchmarks therefore rests on the specific regimes tested rather than a general guarantee.
Authors: We concur that the manuscript does not provide a quantitative analysis of how the data-driven kernel-parameter selection interacts with truncation to preserve the supermartingale property under Model-X perturbations. The normalization is constructed so that the betting fraction remains in [0,1] and the exact-Model-X supermartingale property holds by design; under approximate Model-X the control is empirical. In the revision we will expand §4.2 with a short discussion explaining that the adaptive optimization is performed over a compact parameter grid and that the resulting statistic is bounded, thereby limiting the effect of small perturbations. We will also add a sentence noting that the reported Type I error control is demonstrated on the specific high-dimensional regimes in the benchmarks and will include an additional simulation panel that varies the estimation error level to make this dependence more transparent. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and provided text describe a method that extends existing testing-by-betting and kernel conditional independence frameworks via adaptive optimization, normalization, and a truncate-and-shift strategy. No equations, self-citations, or claims are shown that reduce any reported performance or validity result to a quantity fitted from the evaluation data itself or to a self-referential definition. The central claims rest on external synthetic benchmarks and real-world tasks rather than any derivation that loops back to its inputs by construction. This is the expected outcome for a methods paper whose validation is benchmark-driven and whose modifications are presented as practical extensions rather than tautological renamings or fitted predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Small deviations from the exact Model-X conditional distribution can be handled by the truncate-and-shift calibration without inflating Type I error beyond acceptable levels.
Reference graph
Works this paper leans on
-
[1]
Minority neighborhoods pay higher car insurance premiums than white areas with the same risk
Angwin, J., Larson, J., Kirchner, L., and Mattu, S. Minority neighborhoods pay higher car insurance premiums than white areas with the same risk. ProPublica, April 2017
2017
-
[2]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Candès, E., Fan, Y., Janson, L., and Lv, J. Panning for gold: ` Model-X ' knockoffs for high dimensional controlled variable selection. Journal of the Royal Statistical Society Series B: Statistical Methodology, 80 0 (3): 0 551--577, 01 2018. doi:10.1111/rssb.12265
-
[3]
H., Goldstein, L., and Shao, Q.-M
Chen, L. H., Goldstein, L., and Shao, Q.-M. Normal Approximation by Stein's Method. Springer, 2010
2010
-
[4]
fishing expedition
Gelman, A. and Loken, E. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypothesis was posited ahead of time, 2013
2013
-
[5]
M., Rastogi, M., de Cothi, W., Clopath, C., Stachenfeld, K., and Barry, C
George, T. M., Rastogi, M., de Cothi, W., Clopath, C., Stachenfeld, K., and Barry, C. RatInABox , a toolkit for modelling locomotion and neuronal activity in continuous environments. eLife, 13: 0 e85274, 2024. doi:10.7554/eLife.85274
-
[6]
M., Rasch, M
Gretton, A., Borgwardt, K. M., Rasch, M. J., Sch \"o lkopf, B., and Smola, A. A kernel two-sample test. Journal of Machine Learning Research, 13 0 (25): 0 723--773, 2012
2012
-
[7]
Anytime-valid tests of conditional independence under model- X
Gr \"u nwald, P., Henzi, A., and Lardy, T. Anytime-valid tests of conditional independence under model- X . Journal of the American Statistical Association, 119 0 (546): 0 1554--1565, 2024
2024
-
[8]
Gy \"o rfi, L. and Walk, H. Strongly consistent nonparametric tests of conditional independence. Statistics & Probability Letters, 82 0 (6): 0 1145--1150, 2012. doi:10.1016/j.spl.2012.02.023
-
[9]
Equality of opportunity in supervised learning
Hardt, M., Price, E., and Srebro, N. Equality of opportunity in supervised learning. In Advances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[10]
He, Z., Pogodin, R., Li, Y., Deka, N., Gretton, A., and Sutherland, D. J. On the hardness of conditional independence testing in practice. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[11]
and Veitch, V
Jiang, Y. and Veitch, V. Invariant and transportable representations for anti-causal domain shifts. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[12]
Kim, I. and Ramdas, A. Dimension-agnostic inference using cross U -statistics. Bernoulli, 30 0 (1): 0 683 -- 711, 2024. doi:10.3150/23-BEJ1613
-
[13]
Optimal rates for regularized conditional mean embedding learning
Li, Z., Meunier, D., Mollenhauer, M., and Gretton, A. Optimal rates for regularized conditional mean embedding learning. In Advances in Neural Information Processing Systems, 2022
2022
-
[14]
Towards optimal sobolev norm rates for the vector-valued regularized least-squares algorithm
Li, Z., Meunier, D., Mollenhauer, M., and Gretton, A. Towards optimal sobolev norm rates for the vector-valued regularized least-squares algorithm. Journal of Machine Learning Research, 25 0 (181): 0 1--51, 2024
2024
-
[15]
dsprites: Disentanglement testing sprites dataset
Matthey, L., Higgins, I., Hassabis, D., and Lerchner, A. dsprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset/, 2017
2017
-
[16]
Integral Probability Metrics and Their Generating Classes of Functions , journal =
Müller, A. Integral probability metrics and their generating classes of functions. Advances in Applied Probability, 29 0 (2): 0 429–443, 1997. doi:10.2307/1428011
-
[17]
A., and Forr \'e , P
Pandeva, T., Bakker, T., Naesseth, C. A., and Forr \'e , P. E-valuating classifier two-sample tests. Transactions on Machine Learning Research, 2024 a . ISSN 2835-8856
2024
-
[18]
Deep anytime-valid hypothesis testing
Pandeva, T., Forr \'e , P., Ramdas, A., and Shekhar, S. Deep anytime-valid hypothesis testing. In International Conference on Artificial Intelligence and Statistics (AISTATS), pp.\ 622--630. PMLR, 2024 b
2024
-
[19]
Sequential kernelized independence testing
Podkopaev, A., Bl \"o baum, P., Kasiviswanathan, S., and Ramdas, A. Sequential kernelized independence testing. In International Conference on Machine Learning (ICML), pp.\ 27957--27993. PMLR, 2023
2023
-
[20]
J., and Gretton, A
Pogodin, R., Schrab, A., Li, Y., Sutherland, D. J., and Gretton, A. Practical kernel tests of conditional independence, 2024
2024
-
[21]
M., Sun, Y., and Banerjee, M
Polo, F. M., Sun, Y., and Banerjee, M. Conditional independence testing under misspecified inductive biases. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[22]
and Wang, R
Ramdas, A. and Wang, R. Hypothesis testing with e-values. Foundations and Trends in Statistics , 1 0 (1-2): 0 1--390, 2025
2025
-
[23]
Model- X sequential testing for conditional independence via testing by betting
Shaer, S., Maman, G., and Romano, Y. Model- X sequential testing for conditional independence via testing by betting. In International Conference on Artificial Intelligence and Statistics (AISTATS), pp.\ 2054--2086. PMLR, 2023
2054
-
[24]
Shah, R. and Peters, J. The hardness of conditional independence testing and the generalised covariance measure. Annals of Statistics, 48 0 (3): 0 1514--1538, 2020. doi:10.1214/19-AOS1857
-
[25]
and Ramdas, A
Shekhar, S. and Ramdas, A. Nonparametric two-sample testing by betting. IEEE Transactions on Information Theory, 70 0 (2): 0 1178--1203, 2023
2023
-
[26]
\'E tude critique de la notion de collectif
Ville, J. \'E tude critique de la notion de collectif. 1939
1939
-
[27]
and Ramdas, A
Waudby-Smith, I. and Ramdas, A. Distribution-uniform anytime-valid inference. In 2023 IMS International Conference on Statistics and Data Science (ICSDS), pp.\ 445, 2023
2023
-
[28]
Kernel-based conditional independence test and application in causal discovery
Zhang, K., Peters, J., Janzing, D., and Sch \"o lkopf, B. Kernel-based conditional independence test and application in causal discovery. In 27th Conference on Uncertainty in Artificial Intelligence (UAI), pp.\ 804--813. AUAI Press, 2011
2011
-
[29]
Testing conditional mean independence using generative neural networks
Zhang, Y., Huang, L., Yang, Y., and Shao, X. Testing conditional mean independence using generative neural networks. In International Conference on Machhine Learning, 2025
2025
-
[30]
J., and Dao Duc, K
Zhao, W., Sutherland, D. J., and Dao Duc, K. Fast and interpretable quantification of biological shape heterogeneity via stratified W asserstein kernel. PLOS Computational Biology, 22 0 (5): 0 e1014254, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.