Monocular 3D Occupancy Perception for Robots on Sidewalks via Hybrid 2D-3D Learning
Pith reviewed 2026-06-26 20:44 UTC · model grok-4.3
The pith
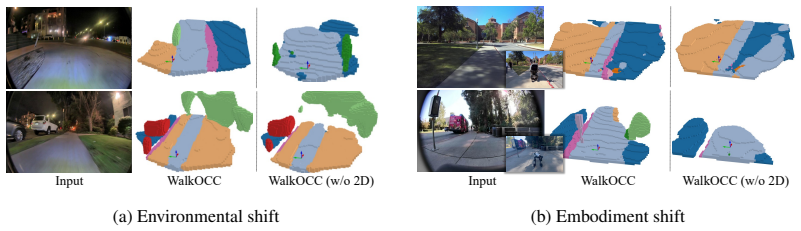
WalkOCC trains accurate monocular 3D occupancy models for sidewalk robots by mixing limited paired LiDAR data with large volumes of unpaired single images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
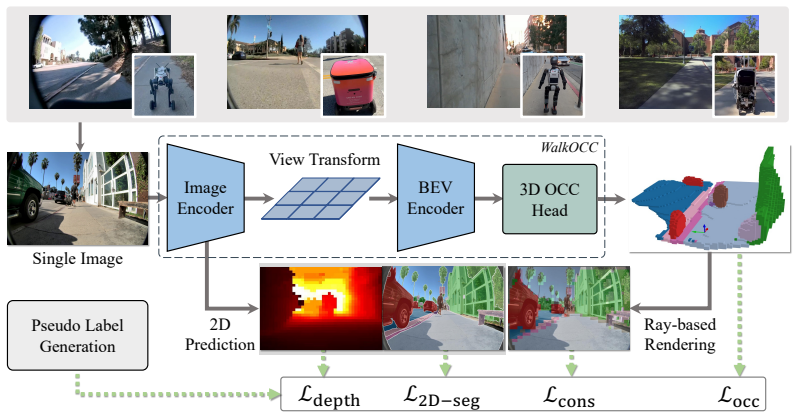
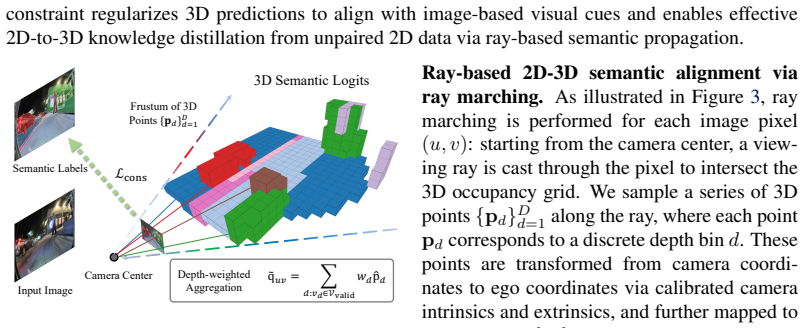
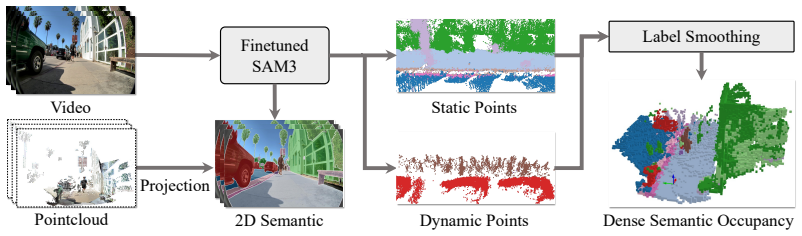
WalkOCC explicitly couples geometric grounding from LiDAR-RGB paired data with scalable learning from large-scale unpaired monocular images. It bootstraps pseudo occupancy supervision from paired sequences and jointly learns image-level representations on additional 2D-only data, yielding stable optimization and improved generalization without requiring costly 3D occupancy annotations.
What carries the argument
WalkOCC, the hybrid Ray-marching monocular 3D occupancy perception framework that transfers geometric information via bootstrapped pseudo labels from paired sequences to unpaired monocular training.
Load-bearing premise
Pseudo occupancy labels generated from paired LiDAR-RGB sequences provide reliable geometric grounding that transfers to improve performance when the model is also trained on large amounts of unpaired monocular sidewalk images.
What would settle it
An experiment in which a model trained only on unpaired monocular images without the paired pseudo-supervision step matches or exceeds WalkOCC accuracy on Sidewalk3D evaluation metrics would falsify the value of the hybrid coupling.
Figures




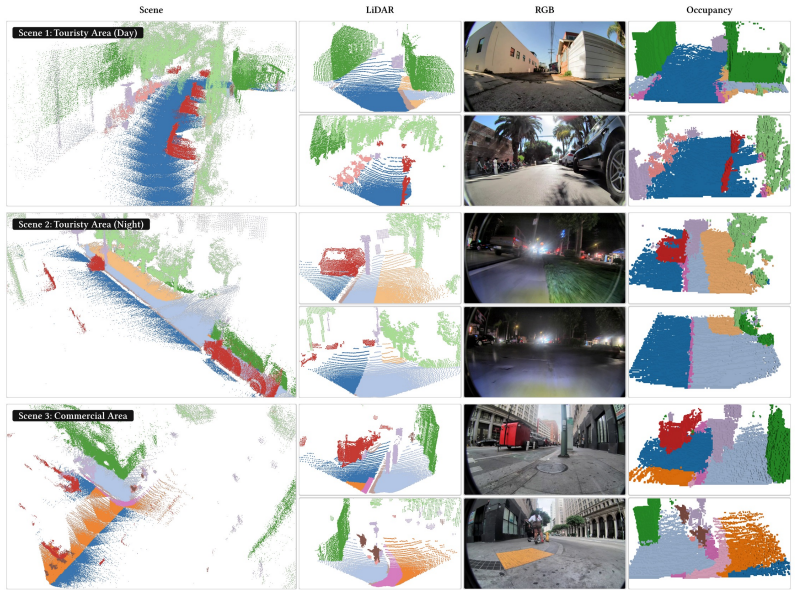
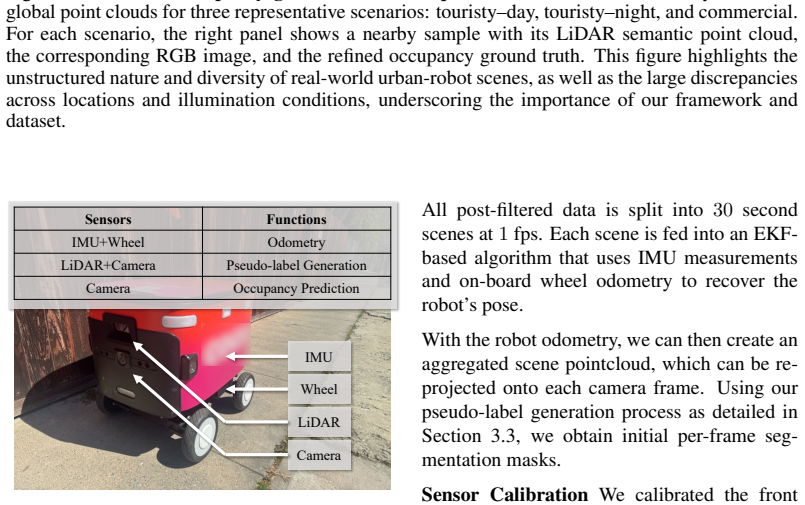
read the original abstract
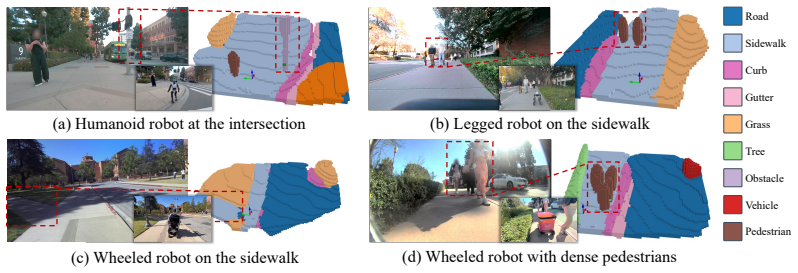
Sidewalks in the real world are crowded, cluttered, and less structured than roads, making 3D occupancy prediction a key ingredient for the safe navigation of mobile robots such as delivery bots and electric wheelchairs. Existing occupancy learning pipelines are largely designed for on-road autonomous driving and often train on large-scale paired LiDAR-RGB datasets with dense 3D supervision and multiple camera inputs, which are costly to collect and do not adequately capture sidewalk-specific characteristics. We propose WalkOCC, a hybrid Ray-marching monocular 3D occupancy perception framework for robots operating on sidewalks. WalkOCC explicitly couples geometric grounding from LiDAR-RGB paired data with scalable learning from large-scale unpaired monocular images. It bootstraps pseudo occupancy supervision from paired sequences and jointly learns image-level representations on additional 2D-only data. It yields stable optimization and improved generalization without requiring costly 3D occupancy annotations. Extensive experiments demonstrate consistent gains in prediction accuracy, fine-grained segmentation of subtle urban structures such as curbs and gutters, and robustness to environmental and cross-embodiment shifts compared with self-supervised image-based baselines. To facilitate evaluation and benchmarking, we also introduce Sidewalk3D, a large-scale sidewalk perception dataset with LiDAR-camera paired sequences collected across multiple locations and time periods, along with 3D semantic occupancy annotations for evaluation. Code and data will be made available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
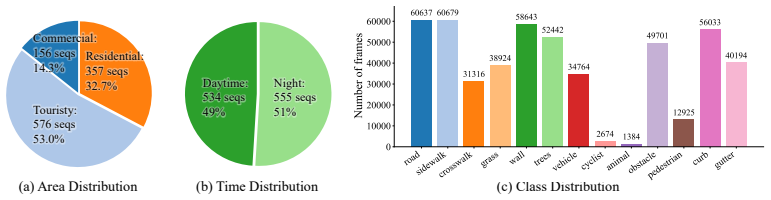
Summary. The paper proposes WalkOCC, a hybrid Ray-marching monocular 3D occupancy perception framework for sidewalk robots. It couples geometric grounding from limited paired LiDAR-RGB sequences (via bootstrapped pseudo occupancy labels) with scalable learning from large-scale unpaired monocular images, without requiring dense 3D annotations. The approach is claimed to yield stable optimization and improved generalization; a new Sidewalk3D dataset with paired sequences and 3D semantic occupancy annotations is introduced to support evaluation and benchmarking.
Significance. If the hybrid training pipeline proves effective, the work could meaningfully advance monocular 3D perception for unstructured, cluttered environments where full 3D supervision is expensive. The Sidewalk3D dataset contribution provides a concrete resource for sidewalk-specific benchmarking, which is currently underrepresented relative to on-road driving datasets.
major comments (2)
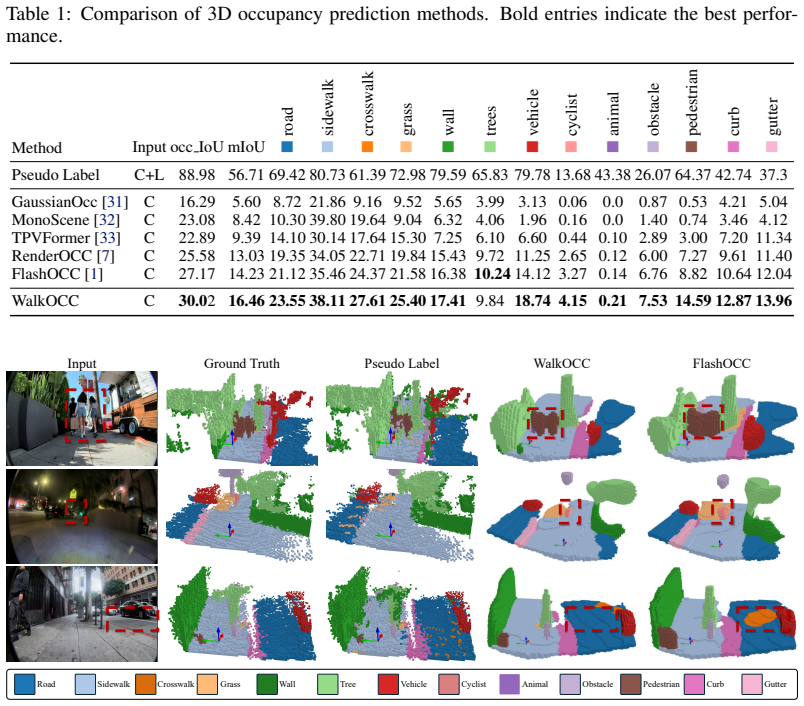
- [Abstract] Abstract: the central claims of 'consistent gains in prediction accuracy', 'fine-grained segmentation of subtle urban structures such as curbs and gutters', and 'robustness to environmental and cross-embodiment shifts' are asserted without any quantitative metrics, error bars, ablation results, or baseline comparisons. This absence directly undermines evaluation of the core claim that the hybrid pseudo-label + 2D-only training improves generalization.
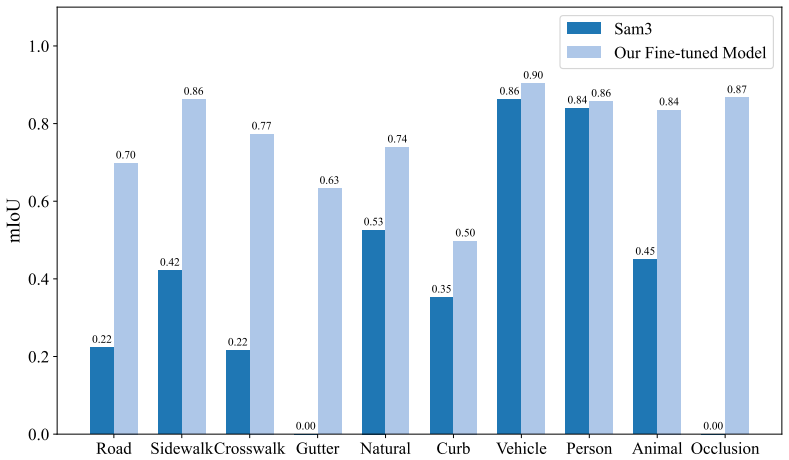
- [Abstract] Abstract: the description of how pseudo occupancy supervision is 'bootstrapped from paired sequences' provides no detail on the generation process, geometric consistency checks, or filtering steps. This is load-bearing for the weakest assumption that the resulting labels reliably transfer geometric grounding to the unpaired monocular data.
minor comments (2)
- [Abstract] The abstract states 'Code and data will be made available' but supplies no repository link, license, or access instructions; this should be added for reproducibility.
- Clarify the precise meaning of 'Ray-marching' in the framework description and how it differs from standard volumetric or BEV occupancy methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract can be strengthened by incorporating key quantitative results and additional details on the pseudo-label generation process. We will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'consistent gains in prediction accuracy', 'fine-grained segmentation of subtle urban structures such as curbs and gutters', and 'robustness to environmental and cross-embodiment shifts' are asserted without any quantitative metrics, error bars, ablation results, or baseline comparisons. This absence directly undermines evaluation of the core claim that the hybrid pseudo-label + 2D-only training improves generalization.
Authors: We agree that the abstract would benefit from including specific quantitative support for these claims. In the revised version, we will add key metrics from our experiments (e.g., mIoU gains over baselines, with error bars where reported in the main results) to better substantiate the improvements in accuracy, fine-grained segmentation, and robustness. revision: yes
-
Referee: [Abstract] Abstract: the description of how pseudo occupancy supervision is 'bootstrapped from paired sequences' provides no detail on the generation process, geometric consistency checks, or filtering steps. This is load-bearing for the weakest assumption that the resulting labels reliably transfer geometric grounding to the unpaired monocular data.
Authors: We agree that the abstract's brevity leaves the bootstrapping process underspecified. We will revise the abstract to include a concise description of the pseudo-label generation, highlighting the geometric consistency checks and filtering steps applied to the paired LiDAR-RGB sequences. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents WalkOCC as a hybrid training pipeline that generates pseudo occupancy labels from paired LiDAR-RGB sequences and then trains jointly on additional unpaired monocular images. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is an empirical statement about improved generalization from this data mixture, which does not reduce to any input quantity by construction and remains externally falsifiable via the introduced Sidewalk3D benchmark. This is a standard data-driven ML proposal whose derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.Advances in Neural Information Processing Systems, 36:64318–64330, 2023
2023
-
[3]
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21729–21740, 2023
2023
-
[4]
Y . Ma, J. Mei, X. Yang, L. Wen, W. Xu, J. Zhang, X. Zuo, B. Shi, and Y . Liu. Licrocc: Teach radar for accurate semantic occupancy prediction using lidar and camera.IEEE Robotics and Automation Letters, 10(1):852–859, 2024
2024
-
[5]
R. Wang, Y . Ma, Y . Yao, S. Tao, H. Li, Z. Zhu, Y . Liu, and X. Zuo. L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 716–723. IEEE, 2025
2025
-
[6]
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang. Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17850– 17859, 2023
2023
-
[7]
M. Pan, J. Liu, R. Zhang, P. Huang, X. Li, H. Xie, B. Wang, L. Liu, and S. Zhang. Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision. In2024 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 12404–12411. IEEE, 2024
2024
-
[8]
Jevti ´c, C
A. Jevti ´c, C. Reich, F. Wimbauer, O. Hahn, C. Rupprecht, S. Roth, and D. Cremers. Feed- forward scenedino for unsupervised semantic scene completion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6784–6796, 2025
2025
-
[9]
Karnan, A
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[10]
R. Mart ´ın-Mart´ın, H. Rezatofighi, A. Shenoi, M. Patel, J. Gwak, N. Dass, A. Federman, P. Goebel, and S. Savarese. Jrdb: A dataset and benchmark for visual perception for navi- gation in human environments.arXiv preprint arXiv:1910.11792, 2019
-
[11]
Carlevaris-Bianco, A
N. Carlevaris-Bianco, A. K. Ushani, and R. M. Eustice. University of michigan north campus long-term vision and lidar dataset.The International Journal of Robotics Research, 35(9): 1023–1035, 2016
2016
-
[12]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Behley, M
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall. Se- mantickitti: A dataset for semantic scene understanding of lidar sequences. InProceedings of the IEEE/CVF international conference on computer vision, pages 9297–9307, 2019
2019
-
[14]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 9
2020
-
[15]
Martin-Martin, M
R. Martin-Martin, M. Patel, H. Rezatofighi, A. Shenoi, J. Gwak, E. Frankel, A. Sadeghian, and S. Savarese. Jrdb: A dataset and benchmark of egocentric robot visual perception of humans in built environments.IEEE transactions on pattern analysis and machine intelligence, 45(6): 6748–6765, 2021
2021
-
[16]
Wigness, S
M. Wigness, S. Eum, J. G. Rogers, D. Han, and H. Kwon. A rugd dataset for autonomous navigation and visual perception in unstructured outdoor environments. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5000–5007. IEEE, 2019
2019
-
[17]
Jiang, P
P. Jiang, P. Osteen, M. Wigness, and S. Saripalli. Rellis-3d dataset: Data, benchmarks and analysis. In2021 IEEE international conference on robotics and automation (ICRA), pages 1110–1116. IEEE, 2021
2021
-
[18]
J. Jiao, H. Wei, T. Hu, X. Hu, Y . Zhu, Z. He, J. Wu, J. Yu, X. Xie, H. Huang, et al. Fu- sionportable: A multi-sensor campus-scene dataset for evaluation of localization and mapping accuracy on diverse platforms. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3851–3856. IEEE, 2022
2022
-
[19]
Zhang, C
A. Zhang, C. Eranki, C. Zhang, J.-H. Park, R. Hong, P. Kalyani, L. Kalyanaraman, A. Gamare, A. Bagad, M. Esteva, et al. Toward robust robot 3-d perception in urban environments: The ut campus object dataset.IEEE Transactions on Robotics, 40:3322–3340, 2024
2024
-
[20]
H. He, Y . Ma, B. Squicciarini, W. Wu, and B. Zhou. Learning sidewalk autopilot from multi- scale imitation with corrective behavior expansion. InProceedings of the International Con- ference on Robotics and Automation (ICRA), 2026
2026
- [21]
-
[22]
J. Hou, X. Li, W. Guan, G. Zhang, D. Feng, Y . Du, X. Xue, and J. Pu. Fastocc: Accelerating 3d occupancy prediction by fusing the 2d bird’s-eye view and perspective view. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16425–16431. IEEE, 2024
2024
-
[23]
P. Tang, Z. Wang, G. Wang, J. Zheng, X. Ren, B. Feng, and C. Ma. Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15035–15044, 2024
2024
- [24]
-
[25]
Zhang, X
H. Zhang, X. Yan, D. Bai, J. Gao, P. Wang, B. Liu, S. Cui, and Z. Li. Radocc: Learning cross-modality occupancy knowledge through rendering assisted distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7060–7068, 2024
2024
-
[26]
Zhang, J
C. Zhang, J. Yan, Y . Wei, J. Li, L. Liu, Y . Tang, Y . Duan, and J. Lu. Occnerf: Advancing 3d occupancy prediction in lidar-free environments.IEEE Transactions on Image Processing, 2025
2025
-
[27]
Huang, W
Y . Huang, W. Zheng, B. Zhang, J. Zhou, and J. Lu. Selfocc: Self-supervised vision-based 3d occupancy prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19946–19956, 2024
2024
-
[28]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 10
2016
-
[29]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view.arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Y . Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y . Shi, J. Sun, and Z. Li. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 1477–1485, 2023
2023
-
[31]
W. Gan, F. Liu, H. Xu, N. Mo, and N. Yokoya. Gaussianocc: Fully self-supervised and ef- ficient 3d occupancy estimation with gaussian splatting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 28980–28990, 2025
2025
-
[32]
Cao and R
A.-Q. Cao and R. De Charette. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3991–4001, 2022
2022
-
[33]
occlusion
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu. Tri-perspective view for vision-based 3d semantic occupancy prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9223–9232, 2023. 11 Appendix Abstract:This supplementary material presents additional evidence and compre- hensive implementation details. It ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.