HT-Bench: Benchmarking and Learning Dexterous Full-Hand Tactile Representations with Egocentric Vision
Pith reviewed 2026-06-26 20:39 UTC · model grok-4.3
The pith
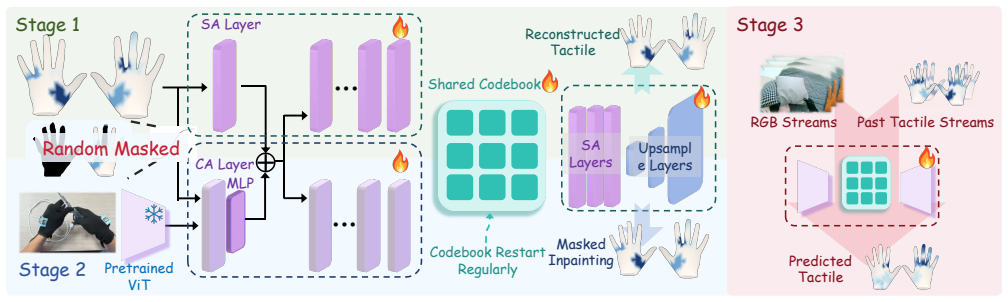
HandTouch learns better full-hand tactile representations than baselines by training a vector-quantized vision-tactile encoder progressively on spatial, cross-modal, and temporal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
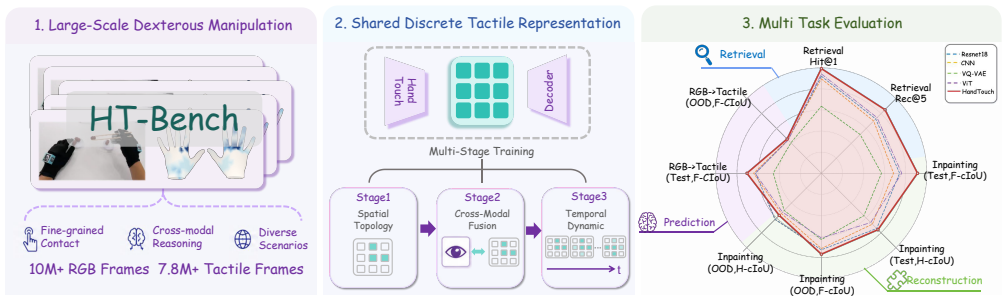
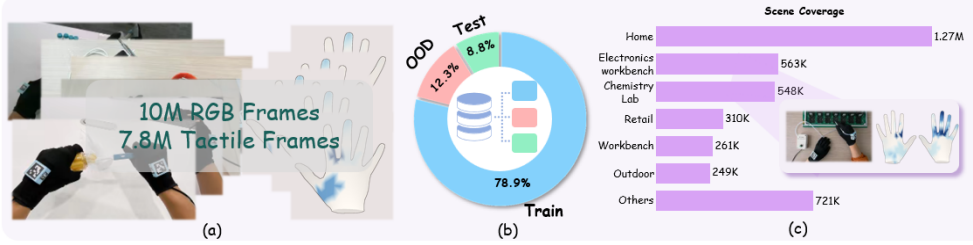
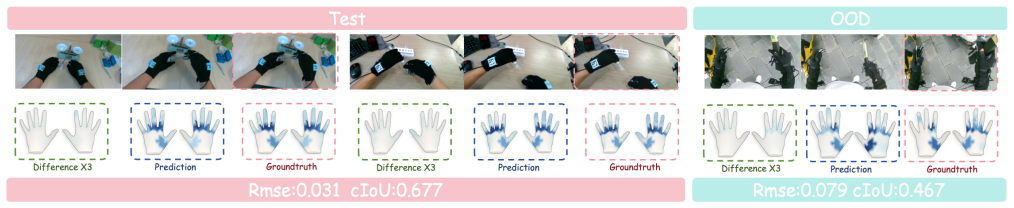
HandTouch, a vector-quantized vision-tactile encoder trained in progressive spatial, cross-modal, and temporal stages, produces representations that outperform prior tactile encoders on fine-grained similarity retrieval, masked inpainting, vision-to-tactile synthesis, and multimodal frame prediction when measured on the HT-Bench collection of 10M RGB frames and 7.8M tactile frames from 226 tasks.
What carries the argument
HandTouch, a vector-quantized vision-tactile encoder trained progressively on spatial, cross-modal, and temporal objectives.
If this is right
- Tactile encoders can be compared and improved at scale using paired vision and full-hand sensor streams rather than isolated tactile datasets.
- Progressive training that moves from spatial structure to cross-modal alignment to temporal modeling yields measurable gains on retrieval, reconstruction, and prediction metrics.
- Large collections spanning many tasks allow direct measurement of out-of-distribution performance on vision-to-tactile synthesis.
- Representations that succeed on the four tasks are expected to support finer contact-aware manipulation once transferred to control policies.
Where Pith is reading between the lines
- The same progressive training schedule might be applied to other paired sensor streams such as force-torque and depth to test whether the gains generalize beyond vision-tactile pairs.
- If the benchmark tasks prove predictive of real-world manipulation performance, future tactile models could be selected primarily by their HT-Bench scores rather than by hand-designed loss functions.
- Expanding the number of robot embodiments in future data collection would reveal whether the learned representations remain useful when the hand geometry changes.
- The reported improvements suggest that vector quantization helps compress tactile signals while preserving geometry information that vision alone cannot supply.
Load-bearing premise
The four selected tasks are enough to determine whether a representation encodes useful contact geometry and generalizes beyond the training distribution.
What would settle it
A controlled experiment in which an alternative encoder matches or exceeds HandTouch on the four benchmark tasks yet produces lower success rates when used as input to a downstream dexterous grasping policy on tasks outside the 226-task set would falsify the claim that the benchmark adequately tests generalization.
Figures
read the original abstract
Establishing a universal benchmark for tactile representation learning in robotic manipulation remains challenging due to the diversity of tactile sensor designs, data formats, and robot embodiments. Rather than seeking to establish such, we explore a scalable and promising direction for future development: egocentric vision paired with full-hand tactile data. To this end, we introduce \textbf{HT-Bench}, a large-scale multi-task benchmark for dexterous full-hand tactile sensing, comprising 10M RGB frames and 7.8M tactile frames collected across 226 tasks. HT-Bench evaluates tactile representations from three key perspectives: whether they encode meaningful contact geometry, whether they can align tactile observations with visual information, and whether they generalize to unseen tasks. To assess these capabilities, HT-Bench includes four tasks: fine-grained tactile similarity retrieval, masked tactile inpainting, vision-to-tactile synthesis, and multimodal tactile frame prediction. We further propose \textbf{HandTouch}, a vector-quantized vision--tactile encoder that learns tactile representations through progressive spatial, cross-modal, and temporal training. Across HT-Bench, HandTouch consistently outperforms representative tactile encoder baselines, improving Recall@5 on fine-grained tactile similarity retrieval from 74.65\% to 85.23\%, reducing RMSE on masked tactile inpainting from 0.022 to 0.010, and increasing OOD cIoU on vision-to-tactile synthesis from 0.628 to 0.705. These results demonstrate the effectiveness of HandTouch and suggest that large-scale egocentric full-hand tactile data provides a scalable basis for evaluating and advancing tactile representation learning in dexterous manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HT-Bench, a large-scale benchmark for dexterous full-hand tactile sensing paired with egocentric vision, containing 10M RGB frames and 7.8M tactile frames collected across 226 tasks. It defines three evaluation perspectives (encoding of contact geometry, vision-tactile alignment, and generalization to unseen tasks) and implements them via four proxy tasks: fine-grained tactile similarity retrieval, masked tactile inpainting, vision-to-tactile synthesis, and multimodal tactile frame prediction. The authors propose HandTouch, a vector-quantized vision-tactile encoder trained progressively in spatial, cross-modal, and temporal stages, and report that it outperforms representative baselines on the benchmark tasks with specific metric gains.
Significance. If the proxy tasks prove predictive of real-world dexterous manipulation performance, the work supplies a scalable dataset and evaluation protocol for tactile representation learning together with an encoder that delivers concrete improvements (Recall@5 lifted from 74.65% to 85.23%, RMSE lowered from 0.022 to 0.010, OOD cIoU raised from 0.628 to 0.705). The scale of the collected data and the consistent numerical gains across multiple tasks constitute the primary strengths.
major comments (1)
- [Abstract] Abstract: the central interpretive claim that success on the four tasks demonstrates that representations 'encode meaningful contact geometry' and 'generalize to unseen tasks' rests on the untested premise that the chosen proxies are sufficient; no downstream robotic manipulation experiments, correlation with explicit contact-geometry metrics, or ablation showing that low-level statistical patterns cannot solve the tasks are provided. This assumption is load-bearing for the paper's conclusion that the results establish the effectiveness of HandTouch beyond benchmark scores.
minor comments (1)
- [Abstract] The abstract lists four tasks but reports quantitative results for only three; the outcome of multimodal tactile frame prediction is omitted.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the proxy tasks are central to our claims and will revise the abstract to moderate the interpretive language and explicitly frame the tasks as proxies.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central interpretive claim that success on the four tasks demonstrates that representations 'encode meaningful contact geometry' and 'generalize to unseen tasks' rests on the untested premise that the chosen proxies are sufficient; no downstream robotic manipulation experiments, correlation with explicit contact-geometry metrics, or ablation showing that low-level statistical patterns cannot solve the tasks are provided. This assumption is load-bearing for the paper's conclusion that the results establish the effectiveness of HandTouch beyond benchmark scores.
Authors: The four tasks are deliberately constructed as operational proxies for the three evaluation perspectives stated in the paper: fine-grained retrieval and masked inpainting probe contact-geometry encoding, vision-to-tactile synthesis probes cross-modal alignment, and multimodal OOD frame prediction probes generalization. HandTouch's consistent gains over baselines (e.g., +10.58 pp Recall@5, -0.012 RMSE, +0.077 OOD cIoU) indicate that the learned representations capture structural and semantic information beyond trivial statistical patterns. We nevertheless accept that these remain proxies and that downstream manipulation validation or explicit geometry correlations are absent. We will revise the abstract to replace 'demonstrate the effectiveness' with 'provide evidence for the effectiveness', add an explicit statement that the tasks serve as proxies for the stated perspectives, and note the absence of direct robotic validation as a limitation. This revision directly addresses the load-bearing interpretive claim. revision: yes
Circularity Check
No circularity; empirical benchmark results are self-contained
full rationale
The paper introduces HT-Bench dataset and HandTouch model, then reports empirical performance metrics (Recall@5, RMSE, OOD cIoU) on four defined tasks against baselines. No derivation chain, equations, or predictions are described that reduce by construction to fitted parameters or self-citations. Evaluation relies on external data collection and standard benchmark comparisons, qualifying as independent empirical evidence rather than self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
TouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video , author=. 2026 , eprint=
2026
-
[2]
2025 , eprint=
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction , author=. 2025 , eprint=
2025
-
[3]
2026 , eprint=
OmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
TaF-VLA: Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation , author=. 2026 , eprint=
2026
-
[5]
2024 , eprint=
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
PP-Tac: Paper Picking Using Tactile Feedback in Dexterous Robotic Hands , author=. 2025 , eprint=
2025
-
[7]
The Fourteenth International Conference on Learning Representations , year=
DexMove: Learning Tactile-Guided Non-Prehensile Manipulation with Dexterous Hands , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
2026 , eprint=
Multi-Modal Manipulation via Multi-Modal Policy Consensus , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
Simultaneous Tactile-Visual Perception for Learning Multimodal Robot Manipulation , author=. 2026 , eprint=
2026
-
[10]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[11]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[12]
2023 , eprint=
Sigmoid Loss for Language Image Pre-Training , author=. 2023 , eprint=
2023
-
[13]
2015 , eprint=
ImageNet Large Scale Visual Recognition Challenge , author=. 2015 , eprint=
2015
-
[14]
2015 , eprint=
Microsoft COCO: Common Objects in Context , author=. 2015 , eprint=
2015
-
[15]
2026 , eprint=
Tactile-based Multimodal Fusion in Embodied Intelligence: A Survey of Vision, Language, and Contact-Driven Paradigms , author=. 2026 , eprint=
2026
-
[16]
2026 , eprint=
UniVTAC: A Unified Simulation Platform for Visuo-Tactile Manipulation Data Generation, Learning, and Benchmarking , author=. 2026 , eprint=
2026
-
[17]
2025 , eprint=
Tactile MNIST: Benchmarking Active Tactile Perception , author=. 2025 , eprint=
2025
-
[18]
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations , year=
Yang, Fengyu and Feng, Chao and Chen, Ziyang and Park, Hyoungseob and Wang, Daniel and Dou, Yiming and Zeng, Ziyao and Chen, Xien and Gangopadhyay, Rit and Owens, Andrew and Wong, Alex , booktitle=. Binding Touch to Everything: Learning Unified Multimodal Tactile Representations , year=
-
[19]
2025 , eprint=
Universal Visuo-Tactile Video Understanding for Embodied Interaction , author=. 2025 , eprint=
2025
-
[20]
Frontiers in Robotics and AI , volume=
Visuo-tactile feedback policies for terminal assembly facilitated by reinforcement learning , author=. Frontiers in Robotics and AI , volume=. 2025 , publisher=
2025
-
[21]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Masked visual-tactile pre-training for robot manipulation , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[25]
The Thirteenth International Conference on Learning Representations , year=
VTDexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Multi-modal representation learning with tactile data , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
2024
-
[28]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[29]
Advances in neural information processing systems , volume=
Generating diverse high-fidelity images with vq-vae-2 , author=. Advances in neural information processing systems , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Universal visuo-tactile video understanding for embodied interaction , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
2024 , eprint=
Sparsh: Self-supervised touch representations for vision-based tactile sensing , author=. 2024 , eprint=
2024
-
[33]
and Levine, Sergey , journal=
Calandra, Roberto and Owens, Andrew and Jayaraman, Dinesh and Lin, Justin and Yuan, Wenzhen and Malik, Jitendra and Adelson, Edward H. and Levine, Sergey , journal=. More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch , year=
-
[34]
2025 , eprint=
UniT: Data Efficient Tactile Representation with Generalization to Unseen Objects , author=. 2025 , eprint=
2025
-
[35]
IEEE/ASME Transactions on Mechatronics , year=
Tactile-Guided Exploration and Positioning for High-Precision Robotic Peg-in-Hole Tasks , author=. IEEE/ASME Transactions on Mechatronics , year=
-
[38]
2026 , eprint=
EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data , author=. 2026 , eprint=
2026
-
[39]
2026 , eprint =
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos , author =. 2026 , eprint =
2026
-
[40]
2012 , publisher=
The new handbook of multisensory processing , author=. 2012 , publisher=
2012
-
[41]
2002 , publisher=
Synesthesia: A union of the senses , author=. 2002 , publisher=
2002
-
[42]
Bao, H.; Dong, L.; Piao, S.; and Wei, F. 2021. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254
Pith/arXiv arXiv 2021
-
[43]
H.; and Levine, S
Calandra, R.; Owens, A.; Jayaraman, D.; Lin, J.; Yuan, W.; Malik, J.; Adelson, E. H.; and Levine, S. 2018. More than a feeling: Learning to grasp and regrasp using vision and touch. IEEE Robotics and Automation Letters 3(4):3300--3307
2018
-
[44]
Cao, Z.; Tian, D.; Guan, R.; Mu, Y.; Sun, X.; Liang, S.; Liu, D.; Huang, T.; Yue, Y.; Ding, H.; Fang, B.; Zhou, A.; Han, Q.-L.; and Xiong, H. 2026. Tactile-based multimodal fusion in embodied intelligence: A survey of vision, language, and contact-driven paradigms
2026
-
[45]
Chen, B.; Wan, W.; Chen, T.; Guo, X.; Xu, C.; Qi, Y.; Zhang, H.; Wu, L.; Xu, T.; Li, Z.; Wu, Y.; Li, R.; Yang, X.; Luo, P.; Sui, W.; and Mu, Y. 2026a. Univtac: A unified simulation platform for visuo-tactile manipulation data generation, learning, and benchmarking
-
[46]
Chen, H.; Xu, J.; Chen, H.; Hong, K.; Huang, B.; Liu, C.; Mao, J.; Li, Y.; Du, Y.; and Driggs-Campbell, K. 2026b. Multi-modal manipulation via multi-modal policy consensus
-
[47]
Chi, H.-G.; Barreiros, J.; Mercat, J.; Ramani, K.; and Kollar, T. 2024. Multi-modal representation learning with tactile data. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 9660--9667. IEEE
2024
-
[48]
Cytowic, R. E. 2002. Synesthesia: A union of the senses . MIT press
2002
-
[49]
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N. 2021. An image is worth 16x16 words: Transformers for image recognition at scale
2021
-
[50]
Feng, R.; Hu, J.; Xia, W.; Gao, T.; Shen, A.; Sun, Y.; Fang, B.; and Hu, D. 2025. Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. arXiv preprint arXiv:2502.12191
arXiv 2025
-
[51]
Feng, R.; Zhou, Y.; Mei, S.; Zhou, D.; Wang, P.; Cui, S.; Fang, B.; Yao, G.; and Hu, D. 2026. Anytouch 2: General optical tactile representation learning for dynamic tactile perception. arXiv preprint arXiv:2602.09617
arXiv 2026
-
[52]
K.; Fan, T.; Lancaster, P.; Kalakrishnan, M.; Kaess, M.; Boots, B.; Lambeta, M.; Wu, T.; and Mukadam, M
Higuera, C.; Sharma, A.; Bodduluri, C. K.; Fan, T.; Lancaster, P.; Kalakrishnan, M.; Kaess, M.; Boots, B.; Lambeta, M.; Wu, T.; and Mukadam, M. 2024. Sparsh: Self-supervised touch representations for vision-based tactile sensing
2024
-
[53]
Huang, Y.; Lin, P.; Li, W.; Li, D.; Li, J.; Jiang, J.; Xiao, C.; and Jiao, Z. 2026. Taf-vla: Tactile-force alignment in vision-language-action models for force-aware manipulation
2026
-
[54]
Huang, Y.; Li, W.; and Jiao, Z. 2026. Tactile-guided exploration and positioning for high-precision robotic peg-in-hole tasks. IEEE/ASME Transactions on Mechatronics
2026
-
[55]
Lee, W.; Grimaldi, M.; and Yu, T. 2026. Symmetry-aware fusion of vision and tactile sensing via bilateral force priors for robotic manipulation. arXiv preprint arXiv:2602.13689
arXiv 2026
-
[56]
Li, Y.; Jin, Z.; Liu, J.; and Ma, D. 2025. Visuo-tactile feedback policies for terminal assembly facilitated by reinforcement learning. Frontiers in Robotics and AI 12:1660244
2025
-
[57]
Li, Y.; Chen, Y.; Zhao, Z.; Li, P.; Liu, T.; Huang, S.; and Zhu, Y. 2026. Simultaneous tactile-visual perception for learning multimodal robot manipulation
2026
-
[58]
L.; and Dollár, P
Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C. L.; and Dollár, P. 2015. Microsoft coco: Common objects in context
2015
-
[59]
Lin, P.; Huang, Y.; Li, W.; Ma, J.; Xiao, C.; and Jiao, Z. 2025. Pp-tac: Paper picking using tactile feedback in dexterous robotic hands
2025
-
[60]
Liu, Q.; Ye, Q.; Sun, Z.; Cui, Y.; Li, G.; and Chen, J. 2024. Masked visual-tactile pre-training for robot manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA) , 13859--13875. IEEE
2024
-
[61]
Liu, Q.; Cui, Y.; Sun, Z.; Li, G.; Chen, J.; and Ye, Q. 2025. Vtdexmanip: A dataset and benchmark for visual-tactile pretraining and dexterous manipulation with reinforcement learning. In The Thirteenth International Conference on Learning Representations
2025
-
[62]
Luo, S.; Li, Y.; Hu, Y.; Yu, C.; Xu, C.; Zhang, J.; Yao, G.; Huang, T.; He, R.; and Wang, Z. 2026. Omniumi: Towards physically grounded robot learning via human-aligned multimodal interaction
2026
-
[63]
Pei, L.; Yuzhe, H.; Wanlin, L.; Chenxi, X.; and Ziyuan, J. 2026. Dexmove: Learning tactile-guided non-prehensile manipulation with dexterous hands. In The Fourteenth International Conference on Learning Representations
2026
-
[64]
W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I
Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; Krueger, G.; and Sutskever, I. 2021. Learning transferable visual models from natural language supervision
2021
-
[65]
Razavi, A.; Van den Oord, A.; and Vinyals, O. 2019. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems 32
2019
-
[66]
C.; and Fei-Fei, L
Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; Berg, A. C.; and Fei-Fei, L. 2015. Imagenet large scale visual recognition challenge
2015
-
[67]
Schneider, T.; Duret, G.; de Farias, C.; Calandra, R.; Chen, L.; and Peters, J. 2025. Tactile mnist: Benchmarking active tactile perception
2025
-
[68]
R.; Li, J.; Fu, R.; Murphy, D.; Zhou, K.; Shiv, R.; Li, Y.; Xiong, H.; Owens, C
Song, Y. R.; Li, J.; Fu, R.; Murphy, D.; Zhou, K.; Shiv, R.; Li, Y.; Xiong, H.; Owens, C. E.; Du, Y.; Luo, Y.; Cheng, X.; Torralba, A.; Matusik, W.; and Liang, P. P. 2025. Opentouch: Bringing full-hand touch to real-world interaction
2025
-
[69]
Van Den Oord, A.; Vinyals, O.; et al. 2017. Neural discrete representation learning. Advances in neural information processing systems 30
2017
-
[70]
Wang, Z.; He, B.; Yu, K.; Lee, S.; Gao, R.; Huang, F.; and Aloimonos, Y. 2026. Humanego: Zero-shot robot learning from minutes of human egocentric videos
2026
-
[71]
Wu, Y.; Lin, Y.; Lao, W.; Lin, Y.; Wei, Y.-L.; Zheng, W.-S.; and Wu, A. 2026. Dexgrasp-zero: A morphology-aligned policy for zero-shot cross-embodiment dexterous grasping. arXiv preprint arXiv:2603.16806
arXiv 2026
-
[72]
R.; and Ding, W
Xie, Y.; Li, M.; Li, S.; Li, X.; Chen, G.; Ma, F.; Yu, F. R.; and Ding, W. 2025. Universal visuo-tactile video understanding for embodied interaction
2025
-
[73]
Xie, Y.; Li, M.; Li, S.; Li, X.; Chen, G.; Ma, F.; Yu, F.; and Ding, W. 2026. Universal visuo-tactile video understanding for embodied interaction. Advances in Neural Information Processing Systems 38:127864--127883
2026
-
[74]
G.; Shou, W.; Wang, D.; and She, Y
Xu, Z.; Uppuluri, R.; Zhang, X.; Fitch, C.; Crandall, P. G.; Shou, W.; Wang, D.; and She, Y. 2025. Unit: Data efficient tactile representation with generalization to unseen objects
2025
-
[75]
Yang, F.; Feng, C.; Chen, Z.; Park, H.; Wang, D.; Dou, Y.; Zeng, Z.; Chen, X.; Gangopadhyay, R.; Owens, A.; and Wong, A. 2024a. Binding touch to everything: Learning unified multimodal tactile representations
-
[76]
Yang, F.; Feng, C.; Chen, Z.; Park, H.; Wang, D.; Dou, Y.; Zeng, Z.; Chen, X.; Gangopadhyay, R.; Owens, A.; and Wong, A. 2024b. Binding touch to everything: Learning unified multimodal tactile representations. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 26330--26343
2024
-
[77]
Zhai, X.; Mustafa, B.; Kolesnikov, A.; and Beyer, L. 2023. Sigmoid loss for language image pre-training
2023
-
[78]
Zhao, J.; Ma, Y.; Wang, L.; and Adelson, E. H. 2024. Transferable tactile transformers for representation learning across diverse sensors and tasks. arXiv preprint arXiv:2406.13640
arXiv 2024
-
[79]
L.; Fu, L.; Darrell, T.; Huang, F.; Zhu, Y.; Xu, D.; and Fan, L
Zheng, R.; Niu, D.; Xie, Y.; Wang, J.; Xu, M.; Jiang, Y.; Castañeda, F.; Hu, F.; Tan, Y. L.; Fu, L.; Darrell, T.; Huang, F.; Zhu, Y.; Xu, D.; and Fan, L. 2026. Egoscale: Scaling dexterous manipulation with diverse egocentric human data
2026
-
[80]
Zhou, J.; Gao, Z.; Hong, F.; Liu, Z.; Zhang, G.; Dai, W.; Zhen, R.; Lyu, C.; Wu, H.; Mao, Y.; Wang, X.; Jiang, Y.; Ding, W.; and Yang, S. 2026. Touchanything: A dataset and framework for bimanual tactile estimation from egocentric video
2026
-
[81]
J.; Park, Y.-L.; Kroemer, O.; et al
Zorin, A.; Si, Z.; Park, M.; Park, J.; Buynitsky, A.; Bhadang, S.; Park, T.; Yoon, S. J.; Park, Y.-L.; Kroemer, O.; et al. 2026. Taco: Benchmarking tactile sensors for object manipulation. arXiv preprint arXiv:2605.21976
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.