A Clinician-Centered Pipeline for Annotation and Evaluation in Ultrasound AI Studies
Pith reviewed 2026-06-26 19:19 UTC · model grok-4.3
The pith
A centralized server and lightweight browser interfaces enable clinicians to annotate ultrasound images and perform blinded AI model evaluations remotely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
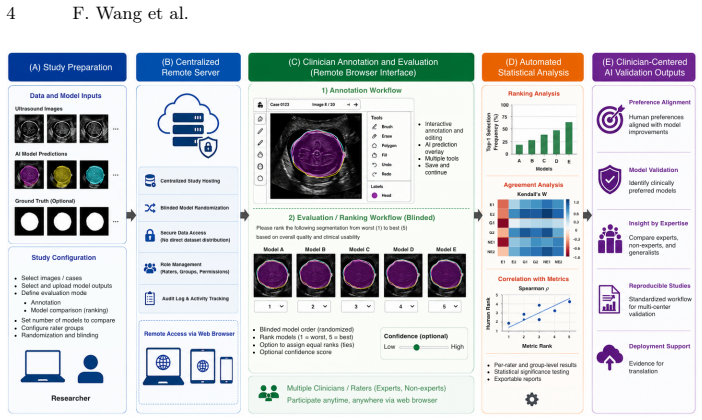
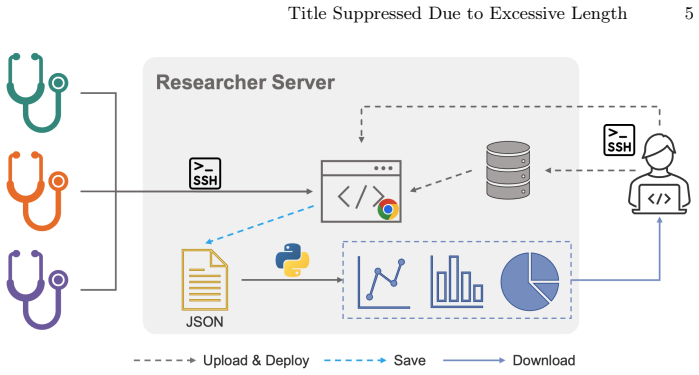
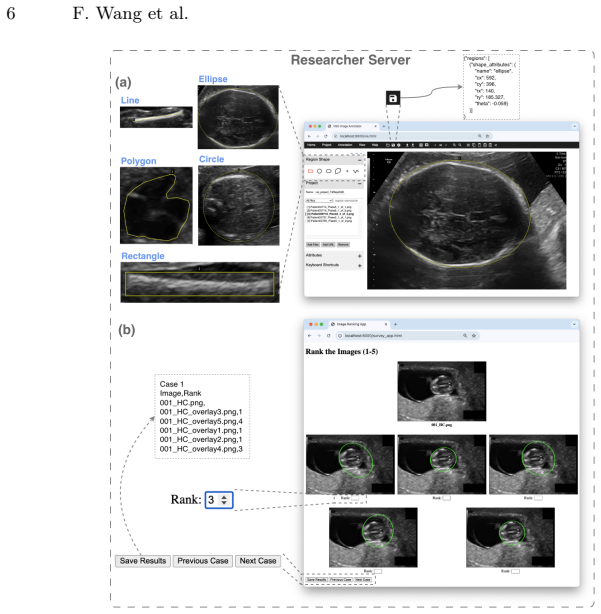
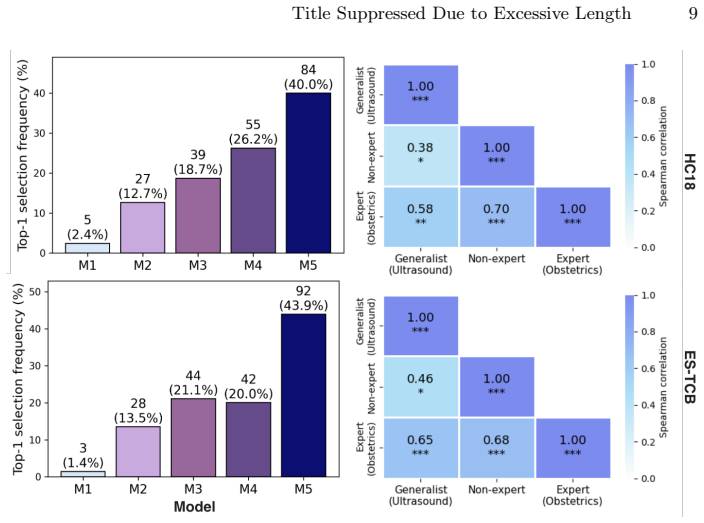
The pipeline uses a centralized server and lightweight browser interfaces to enable clinicians to perform annotation, blinded ranking, and review without local dataset downloads. It supports multi-rater participation, centralized result aggregation, and automated statistical analysis. In the fetal ultrasound segmentation study, the system generated agreement statistics showing moderate to strong agreement across raters of varying expertise and a tendency for later active learning models to be preferred in blinded evaluations.
What carries the argument
Centralized server with lightweight browser interfaces for remote annotation, blinded ranking, and review with automated result aggregation.
If this is right
- Automated computation of Spearman correlation, Kendall's tau, and top-1 selection statistics across raters.
- Support for blinded model comparisons that reveal preferences for active learning iterations.
- Participation by multiple raters spanning expert to non-expert levels in a single workflow.
- Centralized aggregation that produces reproducible human-AI evaluation outputs without data distribution.
Where Pith is reading between the lines
- The remote design could allow smaller research groups to recruit raters who lack access to high-bandwidth local data transfers.
- If the interface scales, it might enable repeated evaluation rounds on the same dataset as new models are developed.
- The separation of annotation and ranking tasks could be tested in other data-heavy medical imaging domains.
Load-bearing premise
That the browser interfaces and centralized server let clinicians of different expertise levels perform remote annotation and blinded ranking effectively without usability barriers or biases that would invalidate the generated agreement statistics.
What would settle it
A follow-up study in which clinicians report high interface friction or produce agreement statistics that differ substantially from those obtained with local annotation tools would indicate the pipeline does not support effective remote evaluation.
Figures

read the original abstract
Clinician-centered evaluation is critical for validating medical AI systems, especially in ultrasound imaging where quantitative metrics do not always capture clinical usability. Existing medical image platforms primarily focus on dataset labeling. They lack integrated support for blinded model comparison and reproducible evaluation workflows. We present a clinician-centered pipeline for remote annotation and evaluation in ultrasound AI studies. The proposed pipeline uses a centralized server and lightweight browser interfaces to enable clinicians to perform annotation, blinded ranking, and review without local dataset downloads. The pipeline also supports multi-rater participation, centralized result aggregation, and automated statistical analysis. We validate the pipeline in a fetal ultrasound segmentation study with six raters spanning expert, generalist, and non-expert experience levels. The system automatically generated Spearman correlation, Kendall's $\tau$, and top-1 selection statistics. Results indicated moderate to strong agreement across experts and other groups. The blinded evaluation results showed a tendency for later active learning models to be preferred. These outcomes suggest that the pipeline can support clinician-centered annotation and reproducible human-\ac{AI} evaluation studies in ultrasound imaging. The proposed pipeline is available on \href{https://github.com/13204942/SonoRate}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a clinician-centered pipeline using a centralized server and lightweight browser interfaces to support remote annotation, blinded model ranking, and review for ultrasound AI studies without requiring local data downloads. It enables multi-rater participation with centralized aggregation and automated statistics (Spearman correlation, Kendall’s τ, top-1 selection). The pipeline is validated in a fetal ultrasound segmentation study with six raters across expert, generalist, and non-expert levels, reporting moderate-to-strong agreement and a preference for later active-learning models; the system is released open-source on GitHub.
Significance. If the pipeline demonstrably supports effective remote clinician workflows, it would address a gap in existing medical-image platforms that focus primarily on labeling rather than integrated blinded evaluation and reproducible human-AI assessment. The open-source release is a concrete strength that enables reproducibility and extension by the community.
major comments (1)
- [Validation study / Results] Validation study (fetal ultrasound segmentation experiment): the reported moderate-to-strong agreement statistics (Spearman, Kendall’s τ) and model preferences are presented without any usability metrics, task-completion times, dropout rates, latency logs, or participant feedback on the browser interface. Because the central claim is that the centralized server and browser interfaces enable effective remote annotation and evaluation without introducing confounds, the absence of these data leaves open the possibility that observed statistics reflect interface artifacts or selection effects rather than clinical consensus.
minor comments (2)
- [Abstract / Methods] The abstract and methods description would benefit from an explicit statement of the total number of images, number of models compared, and exact blinding protocol used in the ranking task.
- [Pipeline description] No discussion of data-privacy or IRB considerations for the centralized server handling clinician annotations is provided; a brief statement would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation study. We address the major comment below.
read point-by-point responses
-
Referee: [Validation study / Results] Validation study (fetal ultrasound segmentation experiment): the reported moderate-to-strong agreement statistics (Spearman, Kendall’s τ) and model preferences are presented without any usability metrics, task-completion times, dropout rates, latency logs, or participant feedback on the browser interface. Because the central claim is that the centralized server and browser interfaces enable effective remote annotation and evaluation without introducing confounds, the absence of these data leaves open the possibility that observed statistics reflect interface artifacts or selection effects rather than clinical consensus.
Authors: We agree that the absence of explicit usability metrics (task times, dropout rates, latency logs, or participant feedback) is a limitation that weakens support for the claim of effective remote workflows without confounds. The validation study reports only that six raters completed the annotation and ranking tasks, producing the agreement statistics and model preferences; no interface-specific data were collected. In the revised manuscript we will add an explicit limitations paragraph acknowledging this gap and noting that the lack of dropouts and successful remote participation provide only indirect evidence of usability. We will also describe plans for future studies to incorporate such metrics. revision: partial
Circularity Check
No circularity: system description + direct empirical validation with no derivations or fitted predictions
full rationale
The paper presents a software pipeline for remote annotation/evaluation and reports agreement statistics (Spearman, Kendall’s τ, top-1 preferences) from a six-rater fetal ultrasound study. No equations, parameter fitting, predictions, or uniqueness theorems appear. The central claim rests on observed inter-rater agreement and model preferences, which are direct outputs of the described workflow rather than reductions to inputs by construction. No self-citations are load-bearing. This matches the default non-circular case for a system-description paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinicians across experience levels can effectively perform annotation and blinded ranking using lightweight browser interfaces without local dataset access.
Reference graph
Works this paper leans on
-
[1]
npj Digital Medicine4(1), 65 (Apr 2021)
Aggarwal, R., Sounderajah, V., Martin, G., Ting, D.S.W., Karthikesalingam, A., King, D., Ashrafian, H., Darzi, A.: Diagnostic accuracy of deep learning in medical imaging: a systematic review and meta-analysis. npj Digital Medicine4(1), 65 (Apr 2021)
2021
-
[2]
Data in Brief51, 109708 (Dec 2023)
Alzubaidi, M., Agus, M., Makhlouf, M., Anver, F., Alyafei, K., Househ, M.: Large- scale annotation dataset for fetal head biometry in ultrasound images. Data in Brief51, 109708 (Dec 2023)
2023
-
[3]
In: Medical Image Computing and Computer Assisted Intervention – MICCAI
Bano, S., Dromey, B., Vasconcelos, F., Napolitano, R., David, A.L., Peebles, D.M., Stoyanov, D.: AutoFB: Automating fetal biometry estimation from standard ultra- sound planes. In: Medical Image Computing and Computer Assisted Intervention – MICCAI. pp. 228–238. Springer International Publishing (2021) Title Suppressed Due to Excessive Length 11
2021
-
[4]
Radiology: Artificial Intelligence6(1), e230337 (Jan 2024)
Bell, L.C., Shimron, E.: Sharing data is essential for the future of AI in medical imaging. Radiology: Artificial Intelligence6(1), e230337 (Jan 2024)
2024
-
[5]
Scientific Reports15(1), 8376 (Mar 2025)
Boumeridja, H., Ammar, M., Alzubaidi, M., Mahmoudi, S., Benamer, L.N., Agus, M., Househ, M., Lekadir, K., El Habib Daho, M.: Enhancing fetal ultrasound im- age quality and anatomical plane recognition in low-resource settings using super- resolution models. Scientific Reports15(1), 8376 (Mar 2025)
2025
-
[6]
Scientific Reports10(1), 10200 (Dec 2020)
Burgos-Artizzu, X.P., Coronado-Gutiérrez, D., Valenzuela-Alcaraz, B., Bonet- Carne, E., Eixarch, E., Crispi, F., Gratacós, E.: Evaluation of deep convolutional neural networks for automatic classification of common maternal fetal ultrasound planes. Scientific Reports10(1), 10200 (Dec 2020)
2020
-
[7]
Medical Image Analysis79, 102444 (Jul 2022)
Chen, X., Wang, X., Zhang, K., Fung, K.M., Thai, T.C., Moore, K., Mannel, R.S., Liu, H., Zheng, B., Qiu, Y.: Recent advances and clinical applications of deep learning in medical image analysis. Medical Image Analysis79, 102444 (Jul 2022)
2022
-
[8]
CVAT.ai Corporation: Computer vision annotation tool (cvat) (Nov 2023),https: //github.com/cvat-ai/cvat
2023
-
[9]
arXiv e-prints (2022)
Diaz-Pinto, A., Alle, S., Ihsani, A., Asad, M., Nath, V., Pérez-García, F., Mehta, P., Li, W., Roth, H.R., Vercauteren, T., Xu, D., Dogra, P., Ourselin, S., Feng, A., Cardoso, M.J.: MONAI Label: A framework for AI-assisted Interactive Labeling of 3D Medical Images. arXiv e-prints (2022)
2022
-
[10]
In: MICCAI Workshop on Data Augmentation, Labelling, and Imperfections
Diaz-Pinto, A., Mehta, P., Alle, S., Asad, M., Brown, R., Nath, V., Ihsani, A., Antonelli, M., Palkovics, D., Pinter, C., et al.: DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images. In: MICCAI Workshop on Data Augmentation, Labelling, and Imperfections. pp. 11–21. Springer (2022)
2022
-
[11]
In: Proceedings of the 27th ACM International Conference on Multimedia
Dutta, A., Zisserman, A.: The VIA annotation software for images, audio and video. In: Proceedings of the 27th ACM International Conference on Multimedia. MM ’19, ACM, New York, NY, USA (2019).https://doi.org/10.1145/3343031. 3350535
-
[12]
Medical Image Analysis83, 102629 (2023).https://doi.org/10.1016/j.media.2022.102629
Fiorentino, M.C., Villani, F.P., Di Cosmo, M., Frontoni, E., Moccia, S.: A review on deep-learning algorithms for fetal ultrasound-image analysis. Medical Image Analysis83, 102629 (2023).https://doi.org/10.1016/j.media.2022.102629
-
[13]
The Lancet407(10527), 505–514 (Jan 2026)
Gommers, J., Hernström, V., Josefsson, V., Sartor, H., Schmidt, D., Hjelmgren, A., Larsson, A.M., Hofvind, S., Andersson, I., Rosso, A., Hagberg, O., Lång, K.: Interval cancer, sensitivity, and specificity comparing AI-supported mammography screening with standard double reading without AI in the MASAI study: a ran- domised, controlled, non-inferiority, s...
2026
-
[14]
Nature Medicine30(2), 573–583 (Feb 2024)
Groh, M., Badri, O., Daneshjou, R., Koochek, A., Harris, C., Soenksen, L.R., Doraiswamy, P.M., Picard, R.: Deep learning-aided decision support for diagnosis of skin disease across skin tones. Nature Medicine30(2), 573–583 (Feb 2024)
2024
-
[15]
Nature Biomedical Engineering (Jan 2026)
Guo, X., Alsharid, M., Zhao, H., Wang, Y., Lander, J., Papageorghiou, A.T., No- ble, J.A.: A visually grounded language model for fetal ultrasound understanding. Nature Biomedical Engineering (Jan 2026)
2026
-
[16]
In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024
Guo, X., Men, Q., Noble, J.A.: MMSummary: Multimodal Summary Generation for Fetal Ultrasound Video . In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024. vol. LNCS 15004. Springer Na- ture Switzerland (October 2024)
2024
-
[17]
van den Heuvel, T.L.A., de Bruijn, D., de Korte, C.L., van Ginneken, B.: Auto- mated measurement of fetal head circumference using 2d ultrasound images (Jul 2018).https://doi.org/10.5281/zenodo.1327317 12 F. Wang et al
-
[18]
BMJ Open15(12) (2025).https://doi.org/10.1136/bmjopen-2025-111360
Jassim, G., Otoom, O., Nair, B., Hashem, J.: Performance of artificial intelligence in breast cancer screening programmes: a systematic review. BMJ Open15(12) (2025).https://doi.org/10.1136/bmjopen-2025-111360
-
[19]
BMC Medical Imaging22(1), 69 (Apr 2022)
Kim, H.E., Cosa-Linan, A., Santhanam, N., Jannesari, M., Maros, M.E., Gans- landt, T.: Transfer learning for medical image classification: a literature review. BMC Medical Imaging22(1), 69 (Apr 2022)
2022
-
[20]
JAMIA Open8(3), ooaf054 (Jun 2025)
Livingston, L., Featherstone-Uwague, A., Barry, A., Barretto, K., Morey, T., Her- rmannova, D., Avula, V.: Reproducible generative artificial intelligence evaluation for health care: a clinician-in-the-loop approach. JAMIA Open8(3), ooaf054 (Jun 2025)
2025
-
[21]
Journal of Medical Artificial Intelligence8(2025)
Madan, Y., Perivolaris, A., Adams-McGavin, R.C., Jung, J.J.: Clinician interaction with artificial intelligence systems: a narrative review. Journal of Medical Artificial Intelligence8(2025)
2025
-
[22]
Nature Communications 9(1), 5217 (Dec 2018)
Maier-Hein, L., Eisenmann, M., Reinke, A., Onogur, S., Stankovic, M., Scholz, P., Arbel, T., Bogunovic, H., Bradley, A.P., Carass, A., Feldmann, C., Frangi, A.F., Full, P.M., van Ginneken, B., Hanbury, A., Honauer, K., Kozubek, M., Landman, B.A., März, K., Maier, O., Maier-Hein, K., Menze, B.H., Müller, H., Neher, P.F., Niessen, W., Rajpoot, N., Sharp, G....
2018
-
[23]
BMJ Open14(9) (2024).https://doi.org/10.1136/bmjopen-2024-086061
Novak, A., Hollowday, M., Espinosa Morgado, A.T., Oke, J., Shelmerdine, S., Woznitza, N., Metcalfe, D., Costa, M.L., Wilson, S., Kiam, J.S., Vaz, J., Limphai- bool, N., Ventre, J., Jones, D., Greenhalgh, L., Gleeson, F., Welch, N., Mistry, A., Devic, N., Teh, J., Ather, S.: Evaluating the impact of artificial intelligence-assisted image analysis on the di...
-
[24]
Obuchowski, N.A., Zepp, R.C.: Simple steps for improving multiple-reader studies in radiology. AJR. American journal of roentgenology166(3), 517–521 (1996)
1996
-
[25]
In: Neural Information Processing
Płotka, S., Włodarczyk, T., Klasa, A., Lipa, M., Sitek, A., Trzciński, T.: FetalNet: Multi-task deep learning framework for fetal ultrasound biometric measurements. In: Neural Information Processing. pp. 257–265. Springer (2021)
2021
-
[26]
American Journal of Obstetrics & Gynecology MFM 7(4) (Apr 2025)
Płotka, S., Pustelnik, K., Szenejko, P., Żebrowska, K., Rzucidło-Szymańska, I., Szymecka-Samaha, N., Łęgowik, T., Kosińska-Kaczyńska, K., Korzeniowski, P., Biliński, P., Khalil, A., Brawura-Biskupski-Samaha, R., Išgum, I., Sánchez, C.I., Sitek, A.: Direct estimation of fetal biometry measurements from ultrasound video scans through deep learning. American...
2025
-
[27]
Informatics in Medicine Unlocked47, 101504 (Jan 2024)
Rayed, M.E., Islam, S.M.S., Niha, S.I., Jim, J.R., Kabir, M.M., Mridha, M.F.: Deep learning for medical image segmentation: State-of-the-art advancements and challenges. Informatics in Medicine Unlocked47, 101504 (Jan 2024)
2024
-
[28]
European Urology Focus7(4), 710–712 (Jul 2021)
Reinke, A., Tizabi, M.D., Eisenmann, M., Maier-Hein, L.: Common pitfalls and recommendations for grand challenges in medical artificial intelligence. European Urology Focus7(4), 710–712 (Jul 2021)
2021
-
[29]
Tkachenko, M., Malyuk, M., Holmanyuk, A., Liubimov, N.: Label Studio: Data labeling software (2020-2025),https://github.com/HumanSignal/label-studio
2020
-
[30]
arXiv preprint arXiv:2509.06495 (2025) Title Suppressed Due to Excessive Length 13
Wang, F., Silvestre, G., Curran, K.M.: Leveraging information divergence for robust semi-supervised fetal ultrasound image segmentation. arXiv preprint arXiv:2509.06495 (2025) Title Suppressed Due to Excessive Length 13
arXiv 2025
-
[31]
Nature Cancer 7(3), 507–521 (Mar 2026)
Warren, L.M., Venton, J., Young, K.C., Halling-Brown, M., Kelly, C.J., Wilson, M., Morigami, M., Khoo, L., Cunningham, D., Sidebottom, R., Reddy, M., Pu- rushothaman, H., Khodabakhshi, D., Honeyfield, L., Hujan, A., Stoycheva, T., Joiner, A., Chopra, R., Sy, A., Ward, D., Yang, L., Sayres, R., Golden, D., Mal- hotra, N., Mallya, R., Xi, L., Ogunleye, D., ...
2026
-
[32]
Neuroimage31(3), 1116– 1128 (2006)
Yushkevich, P.A., Piven, J., Cody Hazlett, H., Gimpel Smith, R., Ho, S., Gee, J.C., Gerig, G.: User-guided 3D active contour segmentation of anatomical struc- tures: Significantly improved efficiency and reliability. Neuroimage31(3), 1116– 1128 (2006)
2006
-
[33]
Journal of Digital Imaging34(1), 134–148 (Feb 2021)
Zeng, Y., Tsui, P.H., Wu, W., Zhou, Z., Wu, S.: Fetal ultrasound image segmenta- tion for automatic head circumference biometry using deeply supervised Attention- Gated V-Net. Journal of Digital Imaging34(1), 134–148 (Feb 2021)
2021
-
[34]
Zhou, Z., Wang, Y., Guo, Y., Qi, Y., Yu, J.: Image quality improvement of hand- held ultrasound devices with a two-stage generative adversarial network. IEEE Transactions on Biomedical Engineering67(1), 298–311 (2020).https://doi.org/ 10.1109/TBME.2019.2912986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.