No Two Developers Think Alike: How Problem-Solving Styles and Experience Shape Needs in Conversational Interaction with Copilot
Pith reviewed 2026-06-26 20:11 UTC · model grok-4.3
The pith
Cognitive diversity in problem-solving styles and experience produces five distinct modes and ten needs when developers interact with Copilot chat.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
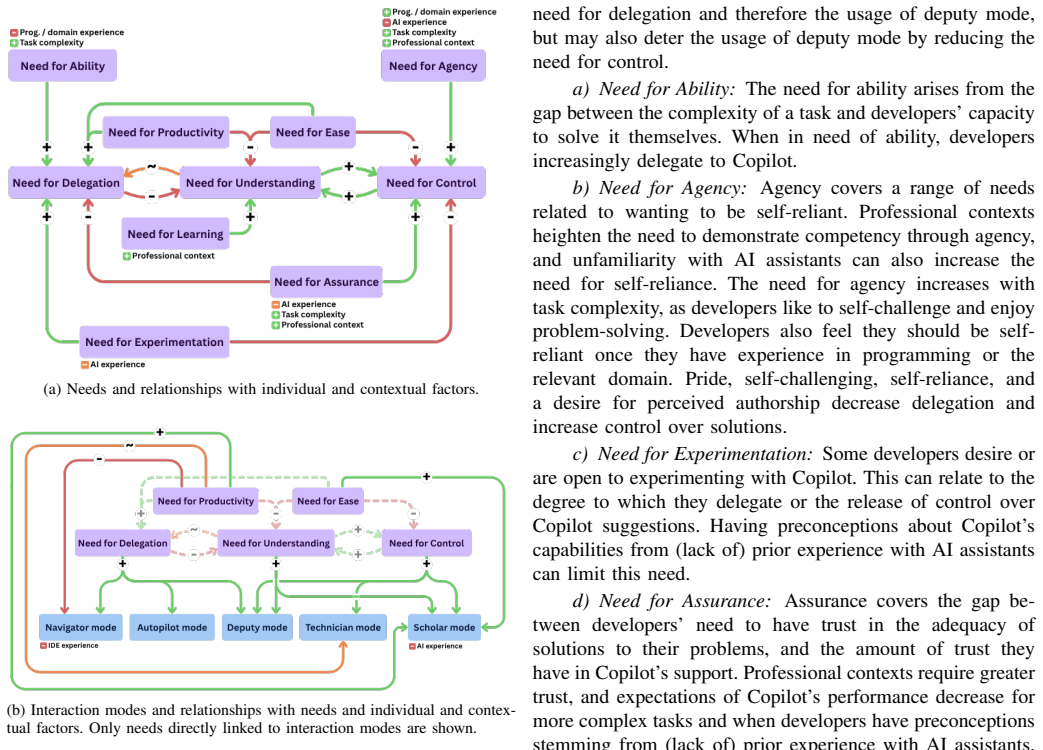
Cognitive diversity in problem-solving styles and experience shapes developers' needs and interaction modes with conversational programming assistants, as shown by five distinct modes and ten underlying needs identified in the study, forming a conceptual model that links these elements to developer profiles.
What carries the argument
Conceptual model connecting five interaction modes, ten needs, problem-solving styles, and experience profiles.
If this is right
- Designers of conversational assistants should support multiple interaction modes rather than a single workflow.
- Experience level influences which needs dominate, so onboarding or defaults can be adjusted by user background.
- Researchers can use the model to categorize future observations of developer-AI conversations.
- Practitioners can match tool features to the problem-solving styles present in their teams.
Where Pith is reading between the lines
- Detecting a developer's style from early chat turns could let the assistant adapt its response style on the fly.
- The same diversity patterns may appear in other conversational coding tools, suggesting a general principle for AI pair-programming interfaces.
Load-bearing premise
The sample of 27 participants and the think-aloud protocol produce representative observations of real interaction needs that generalize beyond the studied group.
What would settle it
A replication study with a larger and more varied developer sample that finds no systematic association between measured problem-solving styles or experience levels and the observed interaction modes would falsify the central claim.
Figures


read the original abstract
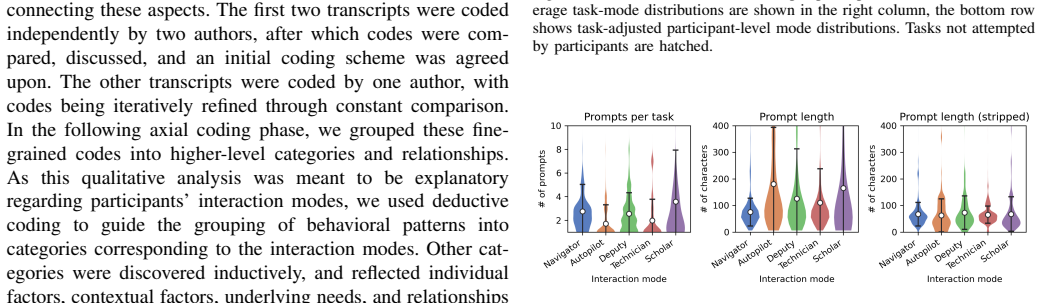
Conversational LLM-based ``programming assistants'' provide a range of benefits to developers. However, recent studies demonstrate the variety in individual developers' needs regarding programming assistants, and challenges encountered by only specific groups of developers. In this study, we explore the role of cognitive diversity in shaping interactions with GitHub Copilot chat. Through a mixed-methods think aloud study with 27 professional developers and students, we characterize 5 distinct ``interaction modes'' and 10 underlying needs in developers' interactions, forming a conceptual model. We characterize links between these modes, needs, and developers' problem-solving styles and experience profiles, showing how cognitive diversity may shape developers' interactions. We provide insights and recommendations for researchers and practitioners on how to design, research, and employ programming assistants to better account for diverse developer needs.
Editorial analysis
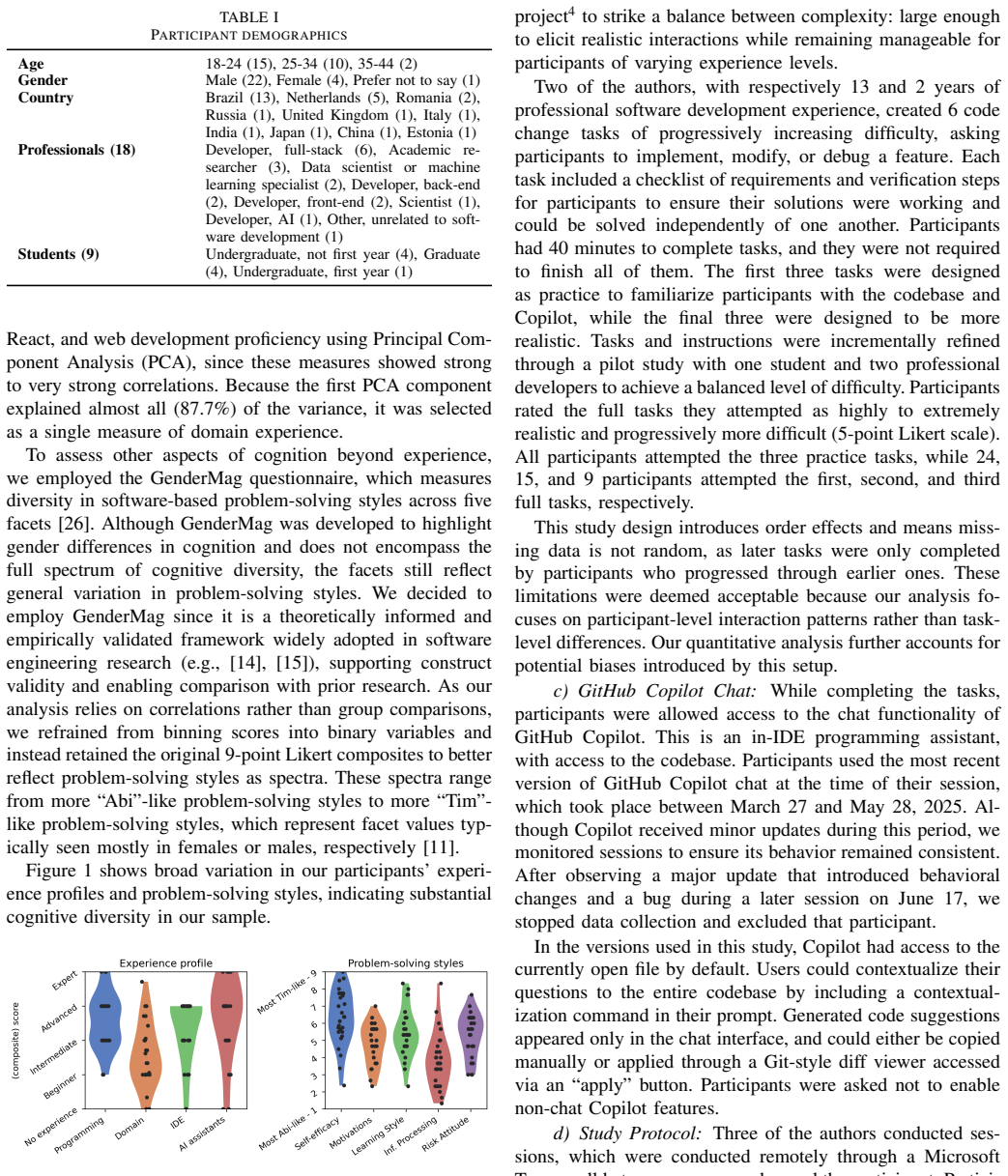
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a mixed-methods think-aloud study with 27 professional developers and students interacting with GitHub Copilot chat. It identifies five distinct interaction modes and ten underlying needs, presents a conceptual model linking these to problem-solving styles and experience profiles, and offers design recommendations for conversational programming assistants that account for cognitive diversity.
Significance. If the modes and needs are shown to be robust, the work provides empirical evidence that individual differences in problem-solving and experience materially affect how developers use LLM-based assistants. This supplies a concrete vocabulary (five modes, ten needs) that can guide future tool design and evaluation studies; the think-aloud data collection is a direct strength when the analysis is adequately documented.
major comments (3)
- [Methods] Methods section: the description of the qualitative analysis supplies no information on the coding process, inter-rater agreement, participant selection criteria, or validation steps. Because the five modes and ten needs are presented as direct empirical outcomes of this analysis, the absence of these details makes it impossible to assess whether the conceptual model is over-fitted to the observed cohort.
- [Results] Results / §4 (or equivalent): the reported links between interaction modes, needs, and experience profiles rest on a 27-participant non-probability sample without evidence of theoretical saturation or stratification by experience level. This directly affects the central claim that cognitive diversity shapes the observed modes and needs.
- [Discussion] Discussion: the reactivity of the think-aloud protocol (known to alter natural strategy and verbalization) is not addressed, yet the interaction modes are defined from these verbalized sessions; this is load-bearing for claims about unprompted developer behavior.
minor comments (2)
- [Abstract] Abstract: the phrase 'mixed-methods' is used but the quantitative component is not described; clarify whether any quantitative measures (e.g., frequency counts of modes) were collected and how they were analyzed.
- [Introduction] Notation: the terms 'interaction modes' and 'needs' are introduced without an early explicit definition or table summarizing the ten needs; a summary table would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods] Methods section: the description of the qualitative analysis supplies no information on the coding process, inter-rater agreement, participant selection criteria, or validation steps. Because the five modes and ten needs are presented as direct empirical outcomes of this analysis, the absence of these details makes it impossible to assess whether the conceptual model is over-fitted to the observed cohort.
Authors: We agree that the Methods section lacks sufficient detail on the qualitative analysis. In the revised manuscript we will expand this section to describe the iterative coding process (open coding followed by thematic grouping), inter-rater reliability procedures (including how disagreements were resolved), participant selection criteria (purposive sampling targeting diversity in roles and experience), and validation steps such as peer review of codes. These additions will allow readers to evaluate the derivation of the five modes and ten needs. revision: yes
-
Referee: [Results] Results / §4 (or equivalent): the reported links between interaction modes, needs, and experience profiles rest on a 27-participant non-probability sample without evidence of theoretical saturation or stratification by experience level. This directly affects the central claim that cognitive diversity shapes the observed modes and needs.
Authors: The referee is correct that the manuscript provides no formal evidence of theoretical saturation and does not describe stratification. In revision we will add an explicit limitations paragraph noting the convenience sample of 27 participants, the absence of a formal saturation assessment, and the non-stratified recruitment. We will reframe the central claims as exploratory patterns observed in a diverse but non-probability sample rather than generalizable conclusions about cognitive diversity. revision: yes
-
Referee: [Discussion] Discussion: the reactivity of the think-aloud protocol (known to alter natural strategy and verbalization) is not addressed, yet the interaction modes are defined from these verbalized sessions; this is load-bearing for claims about unprompted developer behavior.
Authors: We acknowledge that the potential reactivity of the think-aloud method is not discussed. In the revised Discussion we will add a paragraph addressing this issue, citing relevant HCI literature on think-aloud reactivity, noting its possible influence on verbalized strategies, and suggesting that future studies could triangulate with less intrusive methods such as silent observation or log analysis. revision: yes
Circularity Check
No circularity: empirical inductive model from qualitative data
full rationale
The paper reports a mixed-methods think-aloud study with 27 participants that inductively identifies five interaction modes and ten needs, then links them to problem-solving styles and experience. No equations, fitted parameters, predictions, or first-principles derivations exist. The conceptual model is presented as an outcome of direct observation and thematic analysis rather than any self-definitional loop, renamed known result, or load-bearing self-citation chain. The central claim therefore does not reduce to its own inputs by construction and remains self-contained as standard empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Think-aloud verbalizations accurately reflect participants' internal problem-solving processes without substantial distortion from the act of speaking.
invented entities (1)
-
Interaction modes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Software Engineering and Methodology33(8), 1–79 (2024)
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large Language Models for Software Engineering: A Systematic Literature Review,”ACM Transactions on Software Engineering and Methodology, p. 3695988, Sep. 2024. [Online]. Available: https://dl.acm.org/doi/10.1145/3695988
-
[2]
Program Synthesis with Large Language Models,
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton, “Program Synthesis with Large Language Models,” Aug. 2021, arXiv:2108.07732 [cs]. [Online]. Available: http://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[3]
S. I. Ross, F. Martinez, S. Houde, M. Muller, and J. D. Weisz, “The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development,” inProceedings of the 28th International Conference on Intelligent User Interfaces. Sydney NSW Australia: ACM, Mar. 2023, pp. 491–514. [Online]. Available: https://dl.acm.org/doi/10.11...
-
[4]
A Large-Scale Survey on the Usability of AI Programming Assistants: Successes and Challenges,
J. T. Liang, C. Yang, and B. A. Myers, “A Large-Scale Survey on the Usability of AI Programming Assistants: Successes and Challenges,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. New York, NY , USA: Association for Computing Machinery, Feb. 2024, pp. 1–13. [Online]. Available: https://dl.acm.org/doi/...
-
[5]
DevGPT: Studying Developer-ChatGPT Conversations,
T. Xiao, C. Treude, H. Hata, and K. Matsumoto, “DevGPT: Studying Developer-ChatGPT Conversations,” in2024 IEEE/ACM 21st International Conference on Mining Software Repositories (MSR), Apr. 2024, pp. 227–230. [Online]. Available: https://ieeexplore.ieee.org/ document/10555646/?arnumber=10555646
arXiv 2024
-
[6]
Cognitive Diversity in Teams: A Multidisciplinary Review,
A. L. Mello and J. R. Rentsch, “Cognitive Diversity in Teams: A Multidisciplinary Review,”Small Group Research, vol. 46, no. 6, pp. 623–658, Dec. 2015. [Online]. Available: https://journals.sagepub.com/ doi/10.1177/1046496415602558
-
[7]
Gender and Tenure Diversity in GitHub Teams,
B. Vasilescu, D. Posnett, B. Ray, M. G. Van Den Brand, A. Serebrenik, P. Devanbu, and V . Filkov, “Gender and Tenure Diversity in GitHub Teams,” inProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. Seoul Republic of Korea: ACM, Apr. 2015, pp. 3789–3798. [Online]. Available: https://dl.acm.org/doi/10.1145/2702123.2702549
-
[8]
Software engineering team diversity and performance,
V . Pieterse, D. G. Kourie, and I. P. Sonnekus, “Software engineering team diversity and performance,” inProceedings of the 2006 annual research conference of the South African institute of computer scientists and information technologists on IT research in developing countries. Somerset West South Africa: South African Institute for Computer Scientists a...
-
[9]
Why do we need personality diversity in software engineering?
L. F. Capretz and F. Ahmed, “Why do we need personality diversity in software engineering?”ACM SIGSOFT Software Engineering Notes, vol. 35, no. 2, pp. 1–11, Mar. 2010. [Online]. Available: https://dl.acm.org/doi/10.1145/1734103.1734111
-
[10]
Page,The difference: How the power of diversity creates better groups, firms, schools, and societies-new edition
S. Page,The difference: How the power of diversity creates better groups, firms, schools, and societies-new edition. Princeton University Press, 2008
2008
-
[11]
GenderMag: A Method for Evaluating Software’s Gender Inclusiveness,
M. Burnett, S. Stumpf, J. Macbeth, S. Makri, L. Beckwith, I. Kwan, A. Peters, and W. Jernigan, “GenderMag: A Method for Evaluating Software’s Gender Inclusiveness,”Interacting with Computers, vol. 28, no. 6, pp. 760–787, Nov. 2016. [Online]. Available: https://doi.org/10.1093/iwc/iwv046
-
[12]
Gender, Age, and Technology Education Influence the Adoption and Appropriation of LLMs,
F. Draxler, D. Buschek, M. Tavast, P. H ¨am¨al¨ainen, A. Schmidt, J. Kulshrestha, and R. Welsch, “Gender, Age, and Technology Education Influence the Adoption and Appropriation of LLMs,” Oct. 2023, arXiv:2310.06556 [cs]. [Online]. Available: http://arxiv.org/abs/ 2310.06556
arXiv 2023
-
[13]
Navigating the Complexity of Generative AI Adoption in Software Engineering,
D. Russo, “Navigating the Complexity of Generative AI Adoption in Software Engineering,”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 5, pp. 135:1–135:50, Jun. 2024. [Online]. Available: https://dl.acm.org/doi/10.1145/3652154
-
[14]
Using an LLM to Help With Code Understanding,
D. Nam, A. Macvean, V . Hellendoorn, B. Vasilescu, and B. Myers, “Using an LLM to Help With Code Understanding,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering. Lisbon Portugal: ACM, Apr. 2024, pp. 1–13. [Online]. Available: https://dl.acm.org/doi/10.1145/3597503.3639187
-
[15]
A. Anderson, D. Piorkowski, M. Burnett, and J. Weisz, “An LLM’s Attempts to Adapt to Diverse Software Engineers’ Problem-Solving Styles: More Inclusive & Equitable?” Mar. 2025, arXiv:2503.11018 [cs]. [Online]. Available: http://arxiv.org/abs/2503.11018
arXiv 2025
-
[16]
How Beginning Programmers and Code LLMs (Mis)read Each Other,
S. Nguyen, H. M. Babe, Y . Zi, A. Guha, C. J. Anderson, and M. Q. Feldman, “How Beginning Programmers and Code LLMs (Mis)read Each Other,” inProceedings of the CHI Conference on Human Factors in Computing Systems. Honolulu HI USA: ACM, May 2024, pp. 1–26. [Online]. Available: https://dl.acm.org/doi/10.1145/3613904.3642706
-
[17]
Studying the effect of AI Code Generators on Supporting Novice Learners in Introductory Programming,
M. Kazemitabaar, J. Chow, C. K. T. Ma, B. J. Ericson, D. Weintrop, and T. Grossman, “Studying the effect of AI Code Generators on Supporting Novice Learners in Introductory Programming,” inProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. Hamburg Germany: ACM, Apr. 2023, pp. 1–23. [Online]. Available: https://dl.acm.org/doi/10....
-
[18]
How Far Are We? The Triumphs and Trials of Generative AI in Learning Software Engineering,
R. Choudhuri, D. Liu, I. Steinmacher, M. Gerosa, and A. Sarma, “How Far Are We? The Triumphs and Trials of Generative AI in Learning Software Engineering,” inProceedings of the IEEE/ACM 46th International Conference on Software Engineering. Lisbon Portugal: ACM, Apr. 2024, pp. 1–13. [Online]. Available: https://dl.acm.org/doi/10.1145/3597503.3639201
-
[19]
Grounded Copilot: How Programmers Interact with Code-Generating Models,
S. Barke, M. B. James, and N. Polikarpova, “Grounded Copilot: How Programmers Interact with Code-Generating Models,”Proceedings of the ACM on Programming Languages, vol. 7, no. OOPSLA1, pp. 78:85– 78:111, Apr. 2023
2023
-
[20]
Cognition in Software Engineering: A Taxonomy and Survey of a Half-Century of Research,
F. Fagerholm, M. Felderer, D. Fucci, M. Unterkalmsteiner, B. Marculescu, M. Martini, L. G. W. Tengberg, R. Feldt, B. Lehtel ¨a, B. Nagyv ´aradi, and J. Khattak, “Cognition in Software Engineering: A Taxonomy and Survey of a Half-Century of Research,”ACM Computing Surveys, vol. 54, no. 11s, pp. 1–36, Jan. 2022. [Online]. Available: https://dl.acm.org/doi/1...
-
[21]
How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering,
C. Treude and M. A. Gerosa, “How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering,” in 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), Apr. 2025, pp. 236–240
2025
-
[22]
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice,
R. Khojah, M. Mohamad, P. Leitner, and F. G. De Oliveira Neto, “Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 1819–1840, Jul. 2024
2024
-
[23]
LLMs are Imperfect, Then What? An Empirical Study on LLM Failures in Software Engineering,
J. Tie, B. Yao, T. Li, S. I. Ahmed, D. Wang, and S. Zhou, “LLMs are Imperfect, Then What? An Empirical Study on LLM Failures in Software Engineering,” Nov. 2024, arXiv:2411.09916. [Online]. Available: http://arxiv.org/abs/2411.09916
Pith/arXiv arXiv 2024
-
[24]
Prompt Engineering or Fine-Tuning: An Empirical Assessment of LLMs for Code,
J. Shin, C. Tang, T. Mohati, M. Nayebi, S. Wang, and H. Hemmati, “Prompt Engineering or Fine-Tuning: An Empirical Assessment of LLMs for Code,” arXiv:2310.10508, Feb. 2025
arXiv 2025
-
[25]
Gender Differences in Personality Traits of Software Engineers,
D. Russo and K.-J. Stol, “Gender Differences in Personality Traits of Software Engineers,”IEEE Transactions on Software Engineering, vol. 48, no. 3, pp. 819–834, Mar. 2022, conference Name: IEEE Transactions on Software Engineering. [Online]. Available: https://ieeexplore.ieee.org/document/9120355/?arnumber=9120355
arXiv 2022
-
[26]
How to measure diversity actionably in technology,
M. M. Hamid, A. Chatterjee, M. Guizani, A. Anderson, F. Moussaoui, S. Yang, I. Escobar, A. Sarma, and M. Burnett, “How to measure diversity actionably in technology,” inEquity, diversity, and inclusion in software engineering: Best practices and insights. Apress Berkeley, CA, 2024, pp. 469–485
2024
-
[27]
The think aloud method: a practical approach to modelling cognitive processes,
M. W. Van Someren, Y . F. Barnard, and J. A. Sandberg, “The think aloud method: a practical approach to modelling cognitive processes,” London: AcademicPress, vol. 11, no. 6, 1994. [Online]. Available: https://pure.uva.nl/ws/files/716505/149552 Think aloud method.pdf
1994
-
[28]
Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology,
F. D. Davis, “Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology,”MIS Quarterly, vol. 13, no. 3, pp. 319–340, 1989. [Online]. Available: https: //www.jstor.org/stable/249008
1989
-
[29]
Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research,
S. G. Hart and L. E. Staveland, “Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research,” in Advances in Psychology, ser. Human Mental Workload, P. A. Hancock and N. Meshkati, Eds. North-Holland, Jan. 1988, vol. 52, pp. 139–183. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S0166411508623869
1988
-
[30]
J. Richards, B. Alves de Oliveira, I. Oliveira, I. Wiese, and M. Wessel, “Replication package for ”No Two Developers Think Alike: How Problem-Solving Styles and Experience Shape Needs in Conversational Interaction with Copilot”,” Jun. 2026. [Online]. Available: https://doi.org/10.5281/zenodo.20734142
-
[31]
J. M. Corbin and A. L. Strauss,Basics of qualitative research: techniques and procedures for developing grounded theory, 4th ed. Los Angeles: SAGE, 2015
2015
-
[32]
Discovery of activity patterns using topic models,
T. Huynh, M. Fritz, and B. Schiele, “Discovery of activity patterns using topic models,” inProceedings of the 10th international conference on Ubiquitous computing. Seoul Korea: ACM, Sep. 2008, pp. 10–19. [Online]. Available: https://dl.acm.org/doi/10.1145/1409635.1409638
-
[33]
Lecture Notes on Compositional Data Analysis
V . Pawlowsky-Glahn, J. J. Egozcue, and R. Tolosana-Delgado, “Lecture Notes on Compositional Data Analysis.”
-
[34]
Human- AI experience in integrated development environments: A systematic literature review,
A. Sergeyuk, I. Zakharov, E. Koshchenko, and M. Izadi, “Human- AI experience in integrated development environments: A systematic literature review,”Empirical Software Engineering, vol. 31, no. 3, p. 55, May 2026
2026
-
[35]
Affordances in HCI: toward a mediated action perspective,
V . Kaptelinin and B. Nardi, “Affordances in HCI: toward a mediated action perspective,” inProceedings of the SIGCHI Conference on Human Factors in Computing Systems. Austin Texas USA: ACM, May 2012, pp. 967–976. [Online]. Available: https://dl.acm.org/doi/10. 1145/2207676.2208541
arXiv 2012
-
[36]
S. Amershi, D. Weld, M. V orvoreanu, A. Fourney, B. Nushi, P. Collisson, J. Suh, S. Iqbal, P. N. Bennett, K. Inkpen, J. Teevan, R. Kikin-Gil, and E. Horvitz, “Guidelines for Human-AI Interaction,” inProceedings of the 2019 CHI Conference on Human Factors in Computing Systems. Glasgow Scotland Uk: ACM, May 2019, pp. 1–13. [Online]. Available: https://dl.ac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.