Diffusion-Proof: Recipe for Formal Theorem Proving Beyond Auto-Regressive Generation
Pith reviewed 2026-06-26 20:47 UTC · model grok-4.3
The pith
Diffusion LLMs can generate formal mathematical proofs with better long-range coherence than auto-regressive models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
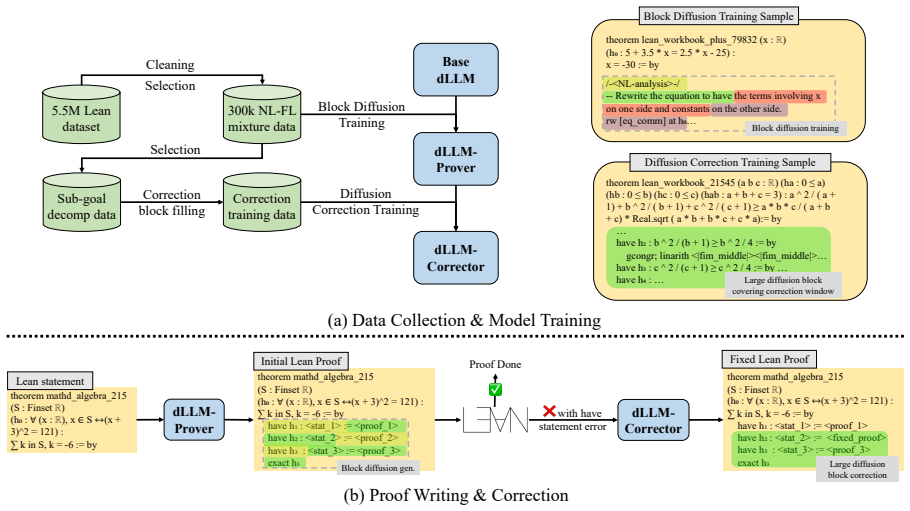
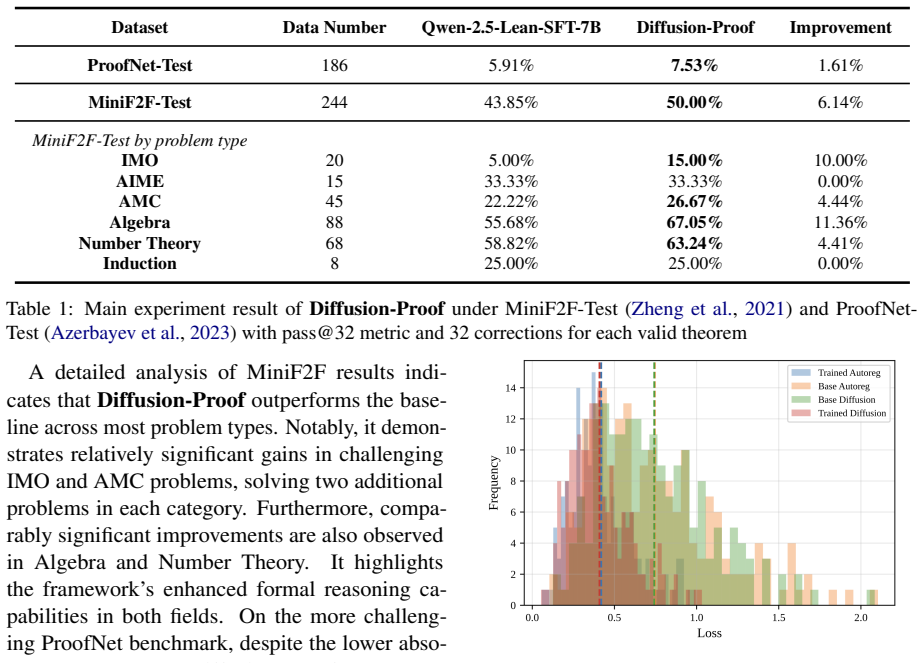
Diffusion-Proof is the first framework to train and apply diffusion LLMs for formal theorem proving. It contains a prover model for whole-proof writing with long-range coherent tactic usage and a corrector model for local proof correction using bi-directional information. Trained on the same dataset as an auto-regressive baseline, the framework achieves absolute improvements of 1.61 percent on ProofNet-Test and 6.14 percent on MiniF2F-Test and solves one IMO problem that more advanced models could not solve.
What carries the argument
Iterative denoising of multi-token blocks in diffusion LLMs, which enables long-range coherence in proof generation and bi-directional context for local correction.
Load-bearing premise
The reported gains come from the diffusion training and inference methods rather than from differences in data, hyperparameters, or evaluation protocol.
What would settle it
Train an auto-regressive model and a diffusion model on identical data with matched hyperparameters, then measure their success rates on the same held-out proof benchmarks.
Figures








read the original abstract
Enhancing the formal math reasoning capabilities of Large Language Models (LLMs) has become a key focus in both mathematical and computer science communities in recent years. While significant progress has been made in using state-of-the-art Auto-Regressive (AR) LLMs for formal theorem proving, these models suffer from inherent limitations. Their next-token prediction generation methods may yield suboptimal performance due to the challenges of long-range coherence and the compounding of errors over long sequences. Recent advancements in diffusion LLMs (dLLMs), which generate text through iterative denoising of a multi-token block, offer a promising alternative. However, the application of dLLMs to formal mathematics, where maintaining long-range coherence is critical, remains largely understudied. To address the challenges above, we propose **Diffusion-Proof**, to the best of our knowledge, the first framework to train and apply dLLMs for formal theorem proving. Our frameworks contain training and inference methods for two models. The first one is *dLLM-Prover-7B*, which performs whole-proof writing with long-range coherent tactic usage. The second one is *dLLM-Corrector-7B*, which is a novel large block diffusion-based correction model. It leverages the in-filling capabilities of dLLMs to perform local proof correction using bi-directional information. Extensive experiments demonstrate that **Diffusion-Proof** relatively significantly outperforms the AR LLM baseline trained under the same dataset. **Diffusion-Proof** achieves an absolute improvement of **1.61%** on ProofNet-Test and **6.14%** on MiniF2F-Test benchmarks compare to the baseline. Notably, **Diffusion-Proof** successfully resolves one IMO problem that more advanced thinking model DeepSeek-Prover-V2-7B could not solve, showcasing the unique advantage of dLLMs in formal theorem proving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Diffusion-Proof, the first framework applying diffusion LLMs (dLLMs) to formal theorem proving. It describes two models: dLLM-Prover-7B for whole-proof generation via iterative denoising to achieve long-range coherent tactic usage, and dLLM-Corrector-7B for bi-directional local proof correction via in-filling. The central empirical claim is that the framework outperforms an auto-regressive (AR) LLM baseline trained on the same dataset, with absolute gains of 1.61% on ProofNet-Test and 6.14% on MiniF2F-Test, plus solving one IMO problem unsolved by DeepSeek-Prover-V2-7B.
Significance. If the performance deltas can be shown to arise from the diffusion training/inference recipe rather than differences in data, hyperparameters, or evaluation protocol, the work would be significant as the first demonstration of dLLMs for formal math, offering a potential route around AR limitations in long-sequence coherence. The IMO solve would further strengthen the case for the approach's unique advantages.
major comments (3)
- [Abstract] Abstract: the claim that the AR baseline was 'trained under the same dataset' provides no quantification of data overlap, sequence lengths, tactic vocabulary, epoch count, or learning-rate schedule. This information is required to attribute the 1.61% ProofNet and 6.14% MiniF2F gains (and the IMO solve) to the dLLM methods rather than uncontrolled experimental variables.
- [Abstract] Abstract and inference description: the dLLM-Corrector introduces an additional inference stage whose computational cost, selection criteria, and integration with the prover are unspecified. This creates an uncontrolled variable that could contribute to the reported improvements, undermining the central claim that gains stem from the diffusion mechanism.
- [Results] Results section (implied by abstract performance numbers): no error bars, statistical significance tests, ablation studies, or details on baseline construction are mentioned. Without these, the benchmark deltas and the claim of outperforming a stronger model on an IMO problem cannot be evaluated for reliability or causality.
minor comments (2)
- [Abstract] Abstract: 'compare to the baseline' should read 'compared to the baseline'.
- [Abstract] Abstract: the phrase 'relatively significantly outperforms' is imprecise and should be replaced with a clearer statement of the absolute improvements.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each of the major comments below, providing clarifications and committing to revisions where the manuscript lacks sufficient detail to support the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the AR baseline was 'trained under the same dataset' provides no quantification of data overlap, sequence lengths, tactic vocabulary, epoch count, or learning-rate schedule. This information is required to attribute the 1.61% ProofNet and 6.14% MiniF2F gains (and the IMO solve) to the dLLM methods rather than uncontrolled experimental variables.
Authors: We agree that the abstract and experimental description lack the requested quantifications, which are necessary for rigorous attribution. In the revised manuscript, we will add a dedicated subsection in the Experiments section detailing the training configurations for both models, including data overlap statistics, sequence length distributions, shared tactic vocabulary, epoch counts, and learning rate schedules. This will enable readers to assess the fairness of the comparison. revision: yes
-
Referee: [Abstract] Abstract and inference description: the dLLM-Corrector introduces an additional inference stage whose computational cost, selection criteria, and integration with the prover are unspecified. This creates an uncontrolled variable that could contribute to the reported improvements, undermining the central claim that gains stem from the diffusion mechanism.
Authors: The manuscript describes the dLLM-Corrector as a bi-directional in-filling model for local correction, but does not specify the inference details mentioned. We will revise the 'Inference Procedure' section to explicitly describe the integration (e.g., applied after initial proof generation on segments with verification failures), selection criteria (based on proof segment length and initial model confidence), and computational cost (measured in additional denoising iterations and wall-clock time). This will clarify that the gains are evaluated with and without the corrector where possible. revision: yes
-
Referee: [Results] Results section (implied by abstract performance numbers): no error bars, statistical significance tests, ablation studies, or details on baseline construction are mentioned. Without these, the benchmark deltas and the claim of outperforming a stronger model on an IMO problem cannot be evaluated for reliability or causality.
Authors: We acknowledge the absence of these elements in the current results presentation. In the revision, we will augment the Results section with error bars from repeated experiments if available, ablation studies isolating the diffusion process and corrector component, and a detailed baseline construction protocol. For the IMO problem, we will provide the specific problem identifier and generation traces to support the claim. If multiple runs were not performed, we will note this limitation and discuss it. revision: partial
Circularity Check
No circularity: purely empirical benchmark comparisons with no derivation chain
full rationale
The paper reports training two diffusion-based models (dLLM-Prover-7B and dLLM-Corrector-7B) and measures absolute gains of 1.61% on ProofNet-Test and 6.14% on MiniF2F-Test versus an AR baseline trained on the same dataset, plus one additional IMO solve. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. All claims rest on external benchmark outcomes rather than any internal reduction to the paper's own inputs. The skeptic concern about unmatched hyperparameters is a validity issue, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2508.01617
Llada-medv: Exploring large language dif- fusion models for biomedical image understanding. arXiv preprint arXiv:2508.01617. Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, and 1 others. 2023. Faith and fate: Limits of transformers on compositionality.Adv...
-
[2]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia Li, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. 2025a. Goedel-prover: A frontier model for open-source automated theorem proving.Preprint, arXiv:2502.07640. Yong Lin, Shange T...
-
[3]
Formal mathematics statement curriculum learning.arXiv preprint arXiv:2202.01344. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 oth- ers. 2025. Qwen2.5 technical report.Preprin...
-
[4]
arXiv preprint arXiv:2511.06254
Llada-rec: Discrete diffusion for parallel se- mantic id generation in generative recommendation. arXiv preprint arXiv:2511.06254. Sumanth Varambally, Thomas V oice, Yanchao Sun, Zhifeng Chen, Rose Yu, and Ke Ye. 2025. Hilbert: Recursively building formal proofs with informal rea- soning.arXiv preprint arXiv:2509.22819. Haiming Wang, Mert Unsal, Xiaohan L...
-
[5]
Lean-github: Compiling github lean repos- itories for a versatile lean prover.arXiv preprint arXiv:2407.17227. Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. 2024a. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data.arXiv preprint arXiv:2405.14333. Huajian Xi...
-
[6]
Kaiyu Yang, Gabriel Poesia, Jingxuan He, Wenda Li, Kristin Lauter, Swarat Chaudhuri, and Dawn Song
Bfs-prover: Scalable best-first tree search for llm-based automatic theorem proving.arXiv preprint arXiv:2502.03438. Kaiyu Yang, Gabriel Poesia, Jingxuan He, Wenda Li, Kristin Lauter, Swarat Chaudhuri, and Dawn Song. 2024a. Formal mathematical reasoning: A new fron- tier in ai.arXiv preprint arXiv:2412.16075. Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chala-...
-
[7]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Huaiyuan Ying, Zijian Wu, Yihan Geng, Jiayu Wang, Dahua Lin, and Kai Chen. 2024. Lean workbook: A large-scale lean problem set formalized from natural language math problems.arXiv preprint arXiv:2406.03847. Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
Minif2f: a cross-system benchmark for for- mal olympiad-level mathematics.arXiv preprint arXiv:2109.00110. A Discussion A.1 AI usage This work utilized Copilot to assist with code writ- ing and OpenAI’s models to correct grammatical issues in the paper. All the ideas of the paper are original. A.2 Potential Risk This work focuses on applying a new form of...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
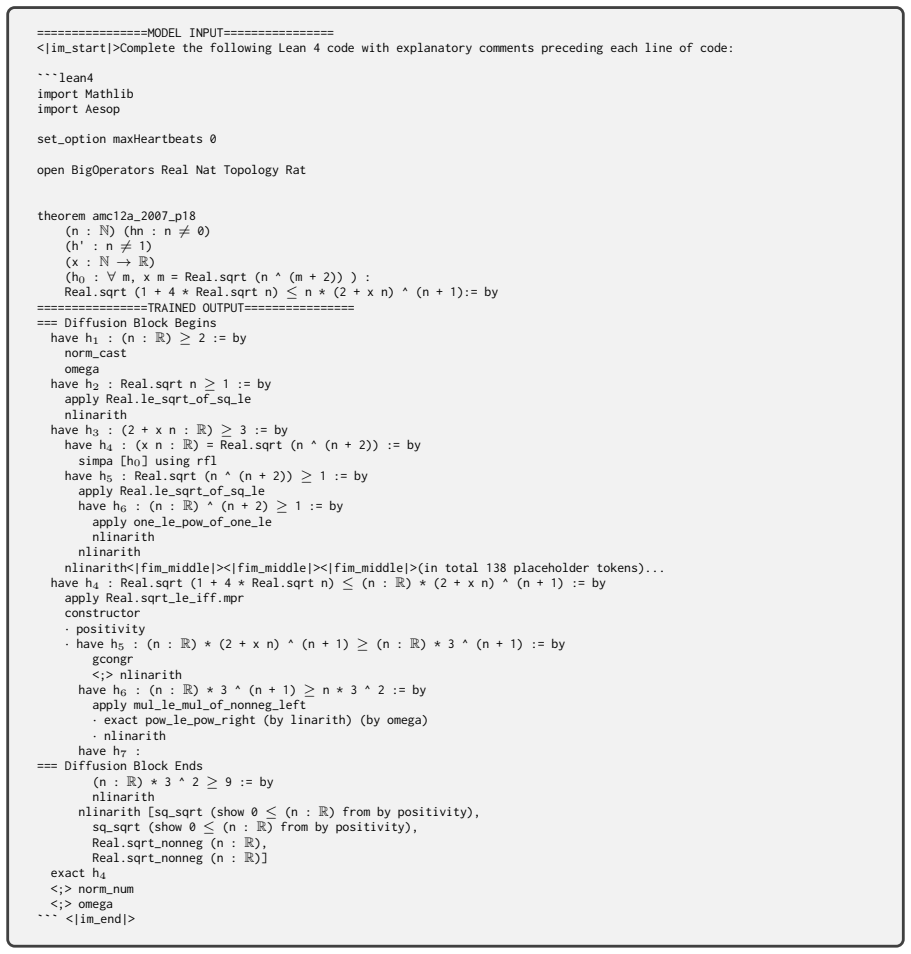
[10]
Thus, the sum of all elements in \( S \) is indeed \(-6\)
**Sum the elements of \( S \)**: -The sum of the elements \( 8 \) and \( -14 \) is \( 8 + (-14) = -6 \). Thus, the sum of all elements in \( S \) is indeed \(-6\). -/ -- We need to show that the sum of all elements in S equals -6. have h 1 : P k in S, k = -6 := by <|MASK|><|MASK|><|MASK|><|MASK|><|MASK|><|MASK|>(in total 256 generation mask)... exact h 1 ...
-
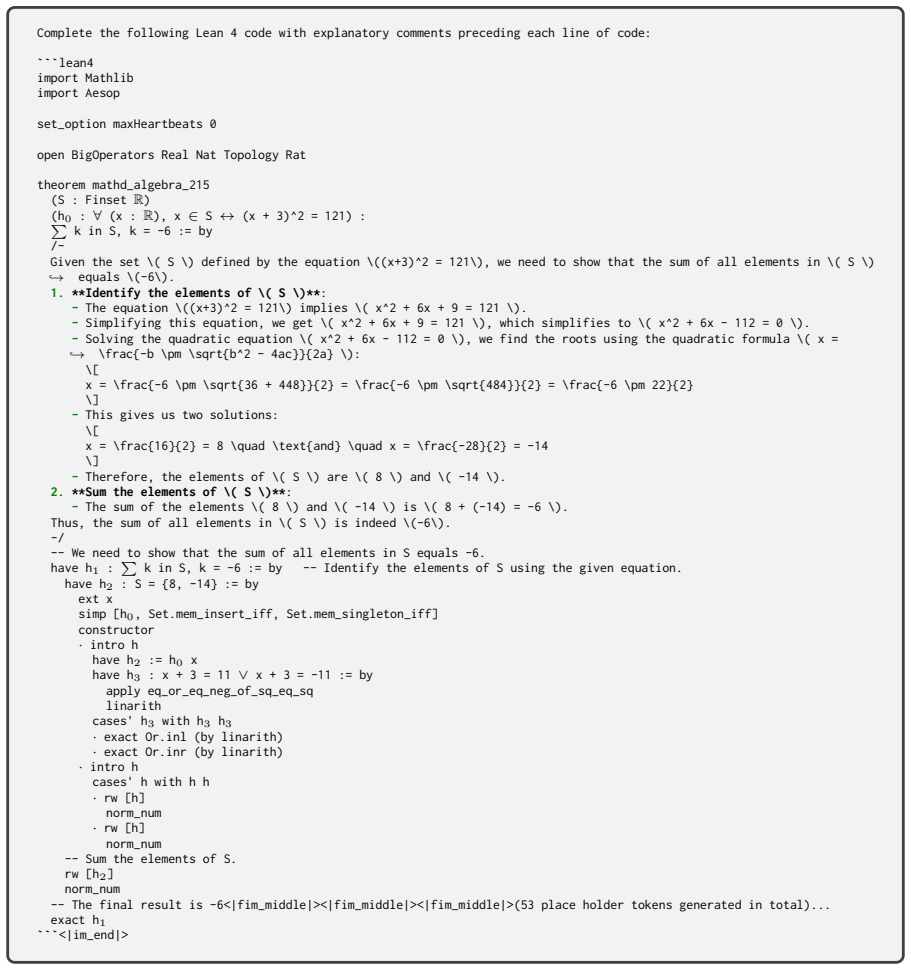
[11]
-Simplifying this equation, we get \( x^2 + 6x + 9 = 121 \), which simplifies to \( x^2 + 6x - 112 = 0 \)
**Identify the elements of \( S \)**: -The equation \((x+3)^2 = 121\) implies \( x^2 + 6x + 9 = 121 \). -Simplifying this equation, we get \( x^2 + 6x + 9 = 121 \), which simplifies to \( x^2 + 6x - 112 = 0 \). -Solving the quadratic equation \( x^2 + 6x - 112 = 0 \), we find the roots using the quadratic formula \( x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a} ...
-
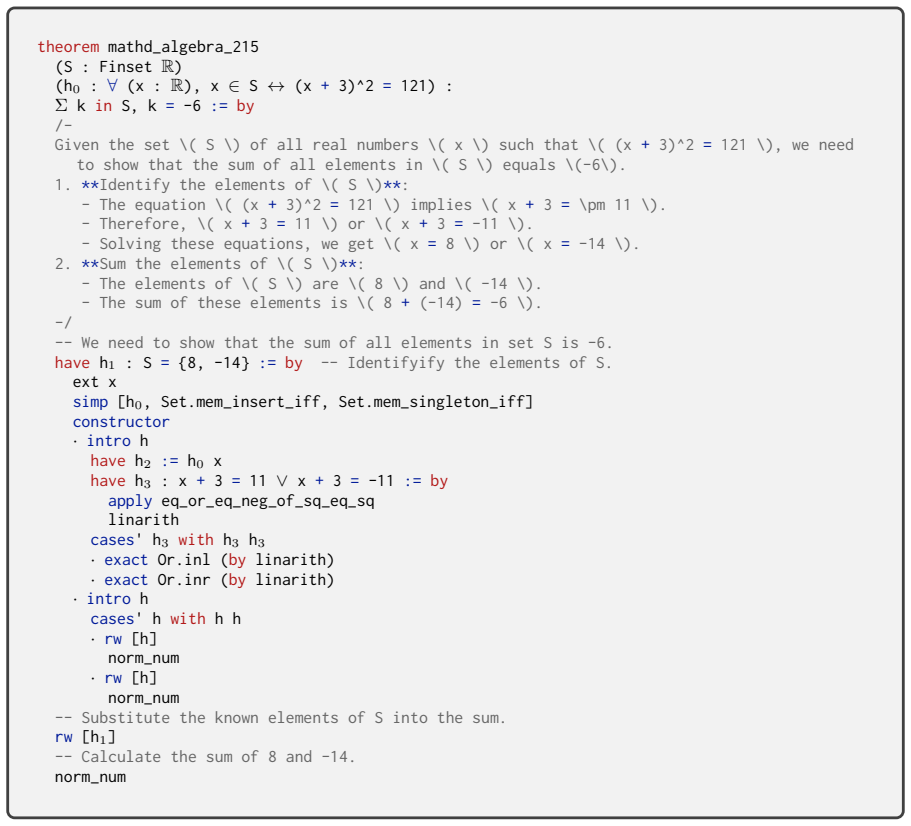
[12]
Thus, the sum of all elements in \( S \) is indeed \(-6\)
**Sum the elements of \( S \)**: -The sum of the elements \( 8 \) and \( -14 \) is \( 8 + (-14) = -6 \). Thus, the sum of all elements in \( S \) is indeed \(-6\). -/ -- We need to show that the sum of all elements in S equals -6. have h 1 : P k in S, k = -6 := by -- Identify the elements of S using the given equation. have h 2 : S = {8, -14} := by ext x ...
-
[13]
- Therefore, \( x + 3 = 11 \) or \( x + 3 = -11 \)
**Identify the elements of \( S \)**: - The equation \( (x + 3)^2 = 121 \) implies \( x + 3 = \pm 11 \). - Therefore, \( x + 3 = 11 \) or \( x + 3 = -11 \). - Solving these equations, we get \( x = 8 \) or \( x = -14 \)
-
[14]
- The sum of these elements is \( 8 + (-14) = -6 \)
**Sum the elements of \( S \)**: - The elements of \( S \) are \( 8 \) and \( -14 \). - The sum of these elements is \( 8 + (-14) = -6 \). -/ -- We need to show that the sum of all elements in set S is -6. have h 1 : S = {8, -14} := by -- Identifyify the elements of S. ext x simp [h 0, Set.mem_insert_iff, Set.mem_singleton_iff] constructor ·intro h have h...
-
[15]
From \( m - n = 2 \), we can express \( m \) as \( m = n + 2 \)
-
[16]
Substitute \( m = n + 2 \) into \( m \times n = 288 \): \[ (n + 2) \times n = 288 \]
-
[17]
Simplify the equation: \[ n^2 + 2n = 288 \]
-
[18]
Rearrange the equation to form a standard quadratic equation: \[ n^2 + 2n - 288 = 0 \]
-
[19]
Solve the quadratic equation using the quadratic formula \( n = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a} \), where \( a = 1 \), \( b = 2 \), and \( c = -288 \): \[ n = \frac{-2 \pm \sqrt{2^2 - 4 \cdot 1 \cdot (-288)}}{2 \cdot 1} = \frac{-2 \pm \sqrt{4 + 1152}}{2} = \frac{-2 \pm \sqrt{1156}}{2} = \frac{-2 \pm 34}{2} \]
-
[20]
This gives two solutions: \[ n = \frac{32}{2} = 16 \quad \text{and} \quad n = \frac{-36}{2} = -18 \]
-
[21]
Since \( n \) must be positive integer, we select \( n = 16 \)
-
[22]
Substitute \( n = 16 \) back into \( m = n + 2 \): \[ m = 16 + 2 = 18 \] Thus, we have shown that \( m = 18 \). -/ -- From m - n = 2, express m in terms of n have h 4 : m = n + 2 := by omega rw [h 4] at h 3 -- Simplify the equation to form a quadratic equation in n have h 5 : n = 16 := by -- Solve the quadratic equation n^2 + 2n - 288 = 0 nlinarith -- Sub...
-
[23]
\( 0 < a \), \( 0 < b \), \( 0 < c \)
-
[24]
This can be achieved by considering the non-negativity of the terms and the constraints on the variables
\( a < b + c \) We need to show that the expression \( a^2 b(a - b) + b^2 c(b - c) + c^2 a(c - a) \) is non-negative. This can be achieved by considering the non-negativity of the terms and the constraints on the variables. -/ -- We need to prove that the expression is non-negative. -- Given the constraints on the variables, we can use the non-negativity ...
-
[25]
Start with the given condition \( \sigma(2) = \sigma(2) \)
-
[26]
Apply \( \sigma \) to both sides of the equation \( \sigma(2) = \sigma(2) \) to get \( \sigma(\sigma(2)) = \sigma(\sigma(2)) \)
-
[27]
Since \( \sigma(2) = \sigma(2) \), it follows that \( \sigma(\sigma(2)) = 2 \). -/ -- Start with the given conditionσ(2) =σ(2) have h1 :σ.1 2 =σ.2 2 := h -- Applyσto both sides of the equationσ(2) =σ(2) to getσ(σ(2)) =σ(σ(2)) have h2 :σ.1 (σ.1 2) =σ.1 (σ.2 2) := by simp_all -- Sinceσ(2) =σ(2), it follows thatσ(σ(2)) = 2 have h3 :σ.1 (σ.1 2) = 2 := by simp...
-
[28]
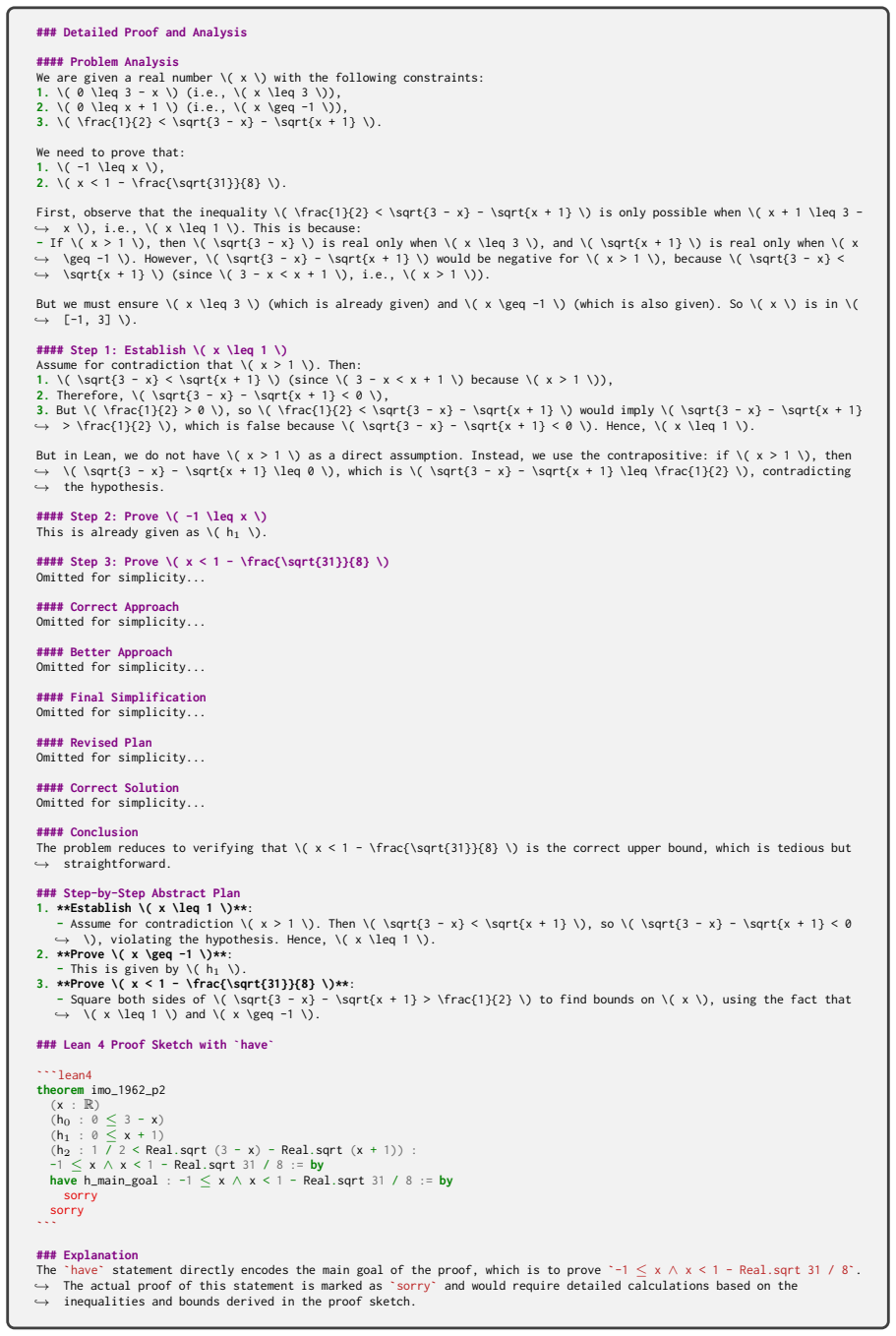
**Establish the range of \( x \)**: - We need to show that \( -1 \leq x < 1 - \frac{\sqrt{31}}{8} \)
-
[29]
**Use the properties of the square root function: - We use the properties of the square root function to derive the inequalities
-
[30]
**Verify the inequalities**: - We verify that the inequalities hold under the given conditions. -/ have h_main : -1≤x∧x < 1 - Real.sqrt 31 / 8 := by constructor ·-- Show that -1≤x have h 3 : 0≤Real.sqrt (3 - x) := Real.sqrt_nonneg (3 - x) have h 4 : 0≤Real.sqrt (x + 1) := Real.sqrt_nonneg (x + 1) have h 5 : 0≤Real.sqrt 31 := Real.sqrt_nonneg 31 have h 6 :...
-
[31]
Then \( \sqrt{3 - x} < \sqrt{x + 1} \), so \( \sqrt{3 - x} - \sqrt{x + 1} < 0 \), violating the hypothesis
**Establish \( x \leq 1 \)**: -Assume for contradiction \( x > 1 \). Then \( \sqrt{3 - x} < \sqrt{x + 1} \), so \( \sqrt{3 - x} - \sqrt{x + 1} < 0 \), violating the hypothesis. Hence, \( x \leq 1 \).,→
-
[32]
**Prove \( x \geq -1 \)**: -This is given by \( h 1 \)
-
[33]
The actual proof of this statement is marked as`sorry`and would require detailed calculations based on the inequalities and bounds derived in the proof sketch
**Prove \( x < 1 - \frac{\sqrt{31}}{8} \)**: -Square both sides of \( \sqrt{3 - x} - \sqrt{x + 1} > \frac{1}{2} \) to find bounds on \( x \), using the fact that \( x \leq 1 \) and \( x \geq -1 \).,→ ### Lean 4 Proof Sketch with`have` ```lean4 theoremimo_1962_p2 (x :R) (h0 : 0≤3 - x) (h1 : 0≤x + 1) (h2 : 1 / 2 < Real.sqrt (3 - x) - Real.sqrt (x + 1)) : -1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.