Performance Analysis and Optimization of 3D Generative Diffusion Models across GPU Architectures
Pith reviewed 2026-06-27 07:46 UTC · model grok-4.3
The pith
Two GPU optimizations cut SM cycles and instructions by 100x for 3D diffusion training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
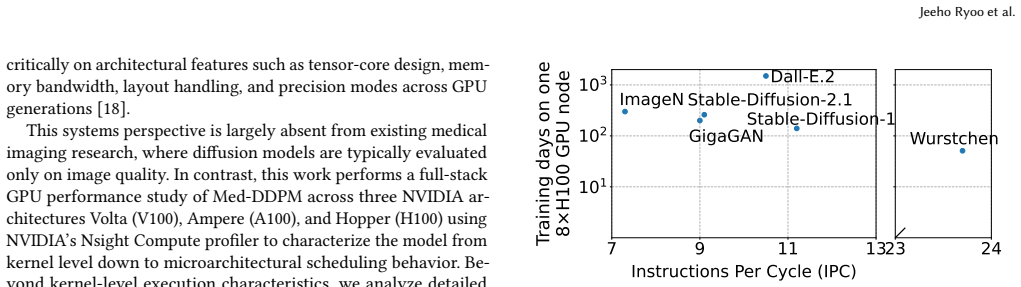
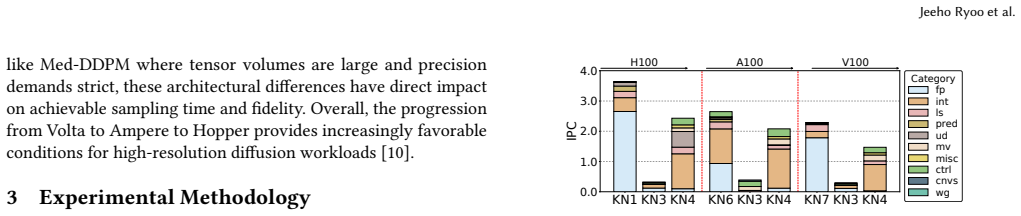
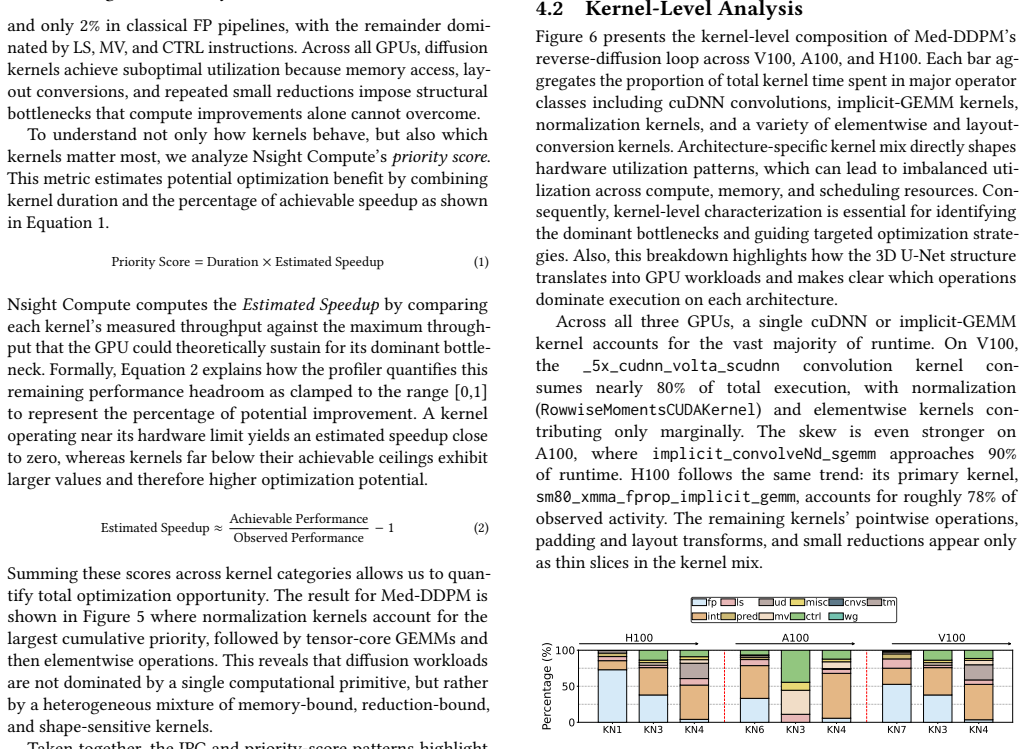
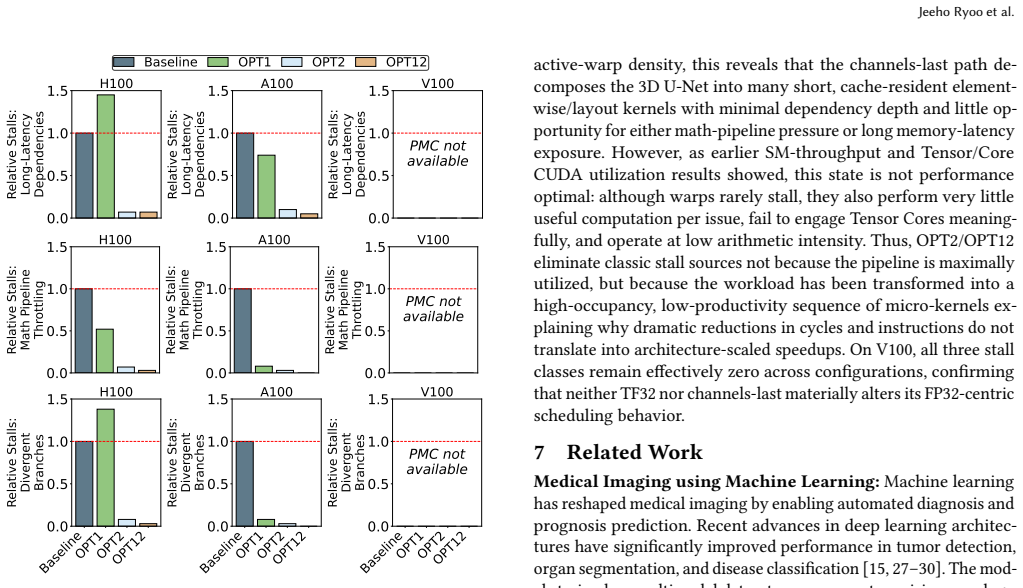
Training of the state-of-the-art 3D medical diffusion model Med-DDPM is overwhelmingly dominated by cuDNN convolution and implicit-GEMM kernels whose inefficiencies stem from memory-access patterns, tensor-layout conversions, and limited Tensor Core utilization. Activating TF32 Tensor Cores and adopting a 3D channels-last layout reduces SM cycles by up to 100x, cuts dynamic instructions by 100x, raises Tensor Core utilization from 1.45x to 9.98x, and increases IPC by 7 percent on A100, all without degrading synthesis quality.
What carries the argument
TF32 Tensor Core activation combined with a 3D channels-last memory layout, which together improve kernel efficiency inside the repeated U-Net evaluations of the diffusion process.
If this is right
- The same kernel inefficiencies and layout fixes are likely to appear in other U-Net-based 3D diffusion models.
- Lower per-sample training cost could allow larger batch sizes or more frequent retraining on new medical datasets.
- Improved Tensor Core utilization suggests the optimizations will scale to future NVIDIA architectures with stronger Tensor Core support.
- The profiler-driven breakdown of warp activity and priority scores provides a reusable template for analyzing other generative workloads.
Where Pith is reading between the lines
- If the layout change also speeds up the denoising sampling phase, end-to-end inference latency for new 3D volumes would drop as well.
- The memory-layout optimization might require different tuning when ported to non-NVIDIA GPUs or to multi-node distributed training.
- Extending the analysis to measure power draw and memory bandwidth saturation would clarify whether the cycle reductions translate into lower energy cost.
Load-bearing premise
The chosen quality metrics and test conditions fully capture any possible degradation in synthesis quality across datasets or diffusion sampling steps.
What would settle it
A statistically significant drop in FID, SSIM, or equivalent quality scores on a held-out 3D MRI test set after the optimizations would show that quality is not preserved.
Figures


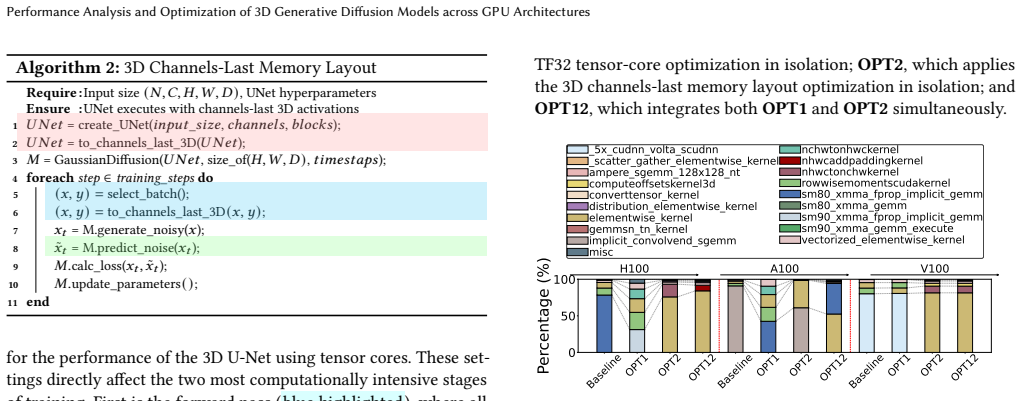
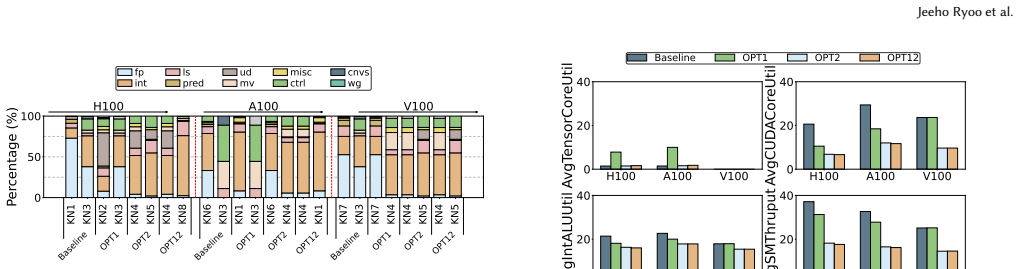
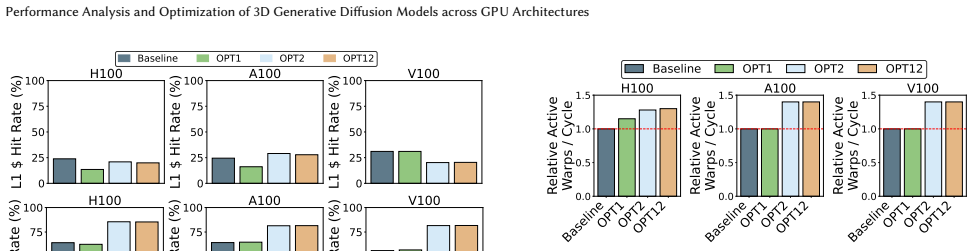
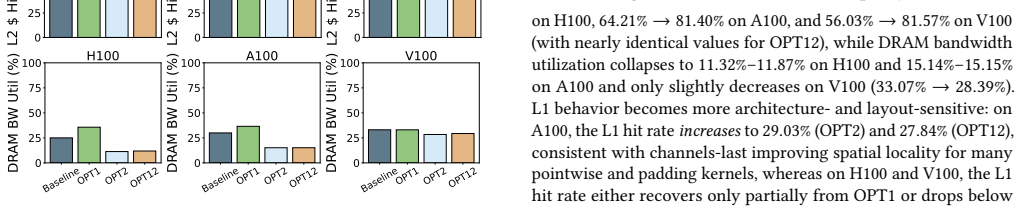
read the original abstract
Diffusion models have become essential for high-fidelity 3D MRI synthesis, yet their deployment remains constrained by substantial GPU resource demands arising from hundreds of U-Net evaluations per sample and a highly heterogeneous kernel behavior. This paper performs a comprehensive performance analysis of the state-of-the-art medical diffusion model, Med-DDPM, across three generations of NVIDIA architectures to study kernel-level runtime breakdowns, instruction-mix characteristics, memory system utilization, warp-level activities, and profiler priority-score estimates. We show that training is overwhelmingly dominated by cuDNN convolution and implicit-GEMM kernels, with inefficiencies arising from memory-access patterns, tensor-layout conversions, and limited Tensor Core utilization. Guided by these insights, we evaluate two architecture-aware optimizations TF32 Tensor Core activation and a 3D channels-last layout and demonstrate that they reduce SM cycles by up to 100x, cut dynamic instructions by 100x, raise Tensor Core utilization from 1.45 to 9.98x, and increase IPC by 7% on A100, all without degrading synthesis quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
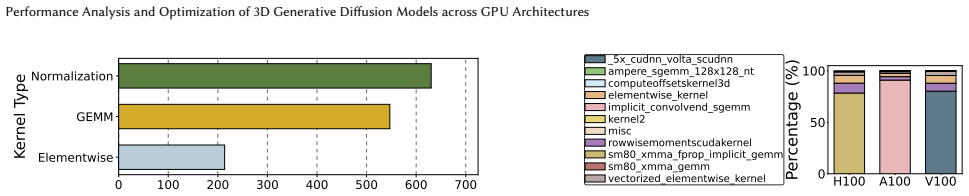
Summary. The paper performs a kernel-level performance analysis of the Med-DDPM 3D diffusion model for MRI synthesis across NVIDIA GPU generations. It reports that training is dominated by cuDNN convolutions and implicit-GEMM kernels, with bottlenecks from memory patterns, layout conversions, and low Tensor Core use. It then evaluates two optimizations (TF32 Tensor Core activation and 3D channels-last layout) that reduce SM cycles and dynamic instructions by up to 100x, raise Tensor Core utilization from 1.45x to 9.98x, and increase IPC by 7% on A100, claiming these gains occur without degrading synthesis quality.
Significance. The work's direct hardware measurements and applied optimizations (no self-referential fitted parameters) are a strength. If the performance claims and quality preservation hold under detailed scrutiny, the results would be useful for efficient deployment of 3D medical diffusion models on current and future GPUs.
major comments (2)
- [Abstract and optimization evaluation section] Quality preservation claim (abstract and § on optimizations): the assertion that TF32 and 3D channels-last preserve synthesis quality is load-bearing for the central contribution, yet the manuscript supplies no named metrics (FID, SSIM, 3D perceptual, or distribution distances), no evaluation across sampling step counts, no cross-dataset results, and no ablation showing that the chosen conditions bound possible degradation. Diffusion models are known to be sensitive to reduced precision and non-standard layouts; without these controls the claim cannot be evaluated.
- [Results and experimental methodology sections] Performance results (abstract and § reporting SM cycles, instructions, utilization, IPC): the up-to-100x reductions and 1.45x-to-9.98x utilization gains are presented without error bars, run-to-run variance, or explicit data-exclusion rules. This makes it impossible to judge whether the reported speedups are robust or whether they depend on particular profiler settings or kernel subsets.
minor comments (2)
- [Methodology] Define or cite all profiler-derived quantities (priority-score estimates, warp-level activities) with reference to the exact NVIDIA tool and version used.
- [Experimental setup] Clarify the exact cuDNN and PyTorch versions, batch sizes, and diffusion timestep schedules used for both baseline and optimized runs so that the measurements can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and optimization evaluation section] Quality preservation claim (abstract and § on optimizations): the assertion that TF32 and 3D channels-last preserve synthesis quality is load-bearing for the central contribution, yet the manuscript supplies no named metrics (FID, SSIM, 3D perceptual, or distribution distances), no evaluation across sampling step counts, no cross-dataset results, and no ablation showing that the chosen conditions bound possible degradation. Diffusion models are known to be sensitive to reduced precision and non-standard layouts; without these controls the claim cannot be evaluated.
Authors: We agree the quality claim requires explicit quantitative support. The revised manuscript will add FID, SSIM, and 3D perceptual metrics for both configurations, evaluated across sampling step counts on the primary dataset, with an ablation confirming no degradation under the tested conditions. revision: yes
-
Referee: [Results and experimental methodology sections] Performance results (abstract and § reporting SM cycles, instructions, utilization, IPC): the up-to-100x reductions and 1.45x-to-9.98x utilization gains are presented without error bars, run-to-run variance, or explicit data-exclusion rules. This makes it impossible to judge whether the reported speedups are robust or whether they depend on particular profiler settings or kernel subsets.
Authors: The measurements used fixed Nsight Compute settings on representative kernels. The revision will add error bars from multiple runs, state the exact profiler configuration, and clarify kernel inclusion criteria to demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical measurements and optimizations
full rationale
The paper reports direct hardware profiler measurements (cuDNN kernels, SM cycles, IPC, Tensor Core utilization) on Med-DDPM across GPU architectures, followed by empirical testing of TF32 and channels-last layout changes. No equations, derivations, or predictions are present that reduce by construction to fitted inputs, self-definitions, or self-citation chains. All load-bearing claims rest on external benchmark data and profiler outputs rather than internal redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption cuDNN convolution and implicit-GEMM kernels dominate the runtime of U-Net evaluations in Med-DDPM
Reference graph
Works this paper leans on
-
[1]
C. Chen, C. Giannoula, and A. Moshovos. 2024. Low-Bitwidth Floating Point Quantization for Efficient High-Quality Diffusion Models. InProceedings of the 2024 IEEE International Symposium on Workload Characterization (IISWC). IEEE, Vancouver, BC, Canada, 181–193. doi:10.1109/IISWC63097.2024.00025
-
[2]
Chen Chen, Chen Qin, Huaqi Qiu, Cheng Ouyang, Shuo Wang, and Daniel Rueckert. 2020. Realistic Adversarial Data Augmentation for MR Image Seg- mentation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI) (Lecture Notes in Computer Science, Vol. 12261). Springer, 667–677. doi:10.1007/978-3-030-59710-8_65
-
[3]
Hyungjin Chung, Eun Sun Lee, and Jong Chul Ye. 2023. MR Image Denoising and Super-Resolution Using Regularized Reverse Diffusion.IEEE Transactions on Medical Imaging42, 4 (2023), 922–934. doi:10.1109/TMI.2022.3220681
-
[4]
2017.NVIDIA Tesla V100 GPU Architecture
NVIDIA Corporation. 2017.NVIDIA Tesla V100 GPU Architecture. Technical Report. NVIDIA. https://images.nvidia.com/content/volta-architecture/pdf/ volta-architecture-whitepaper.pdf
2017
-
[5]
2020.NVIDIA A100 Tensor Core GPU Architecture
NVIDIA Corporation. 2020.NVIDIA A100 Tensor Core GPU Architecture. Technical Report. NVIDIA. https://www.nvidia.com/content/dam/en-zz/Solutions/data- center/nvidia-ampere-architecture-whitepaper.pdf
2020
-
[6]
2022.NVIDIA H100 Tensor Core GPU Architecture
NVIDIA Corporation. 2022.NVIDIA H100 Tensor Core GPU Architecture. Techni- cal Report. NVIDIA. https://resources.nvidia.com/en-us-hopper-architecture/ nvidia-h100-tensor-c
2022
-
[7]
2023.Nsight Compute Kernel Profiling Guide
NVIDIA Corporation. 2023.Nsight Compute Kernel Profiling Guide. Technical Report. NVIDIA Corporation. https://docs.nvidia.com/nsight-compute/2023.2/ pdf/ProfilingGuide.pdf v2023.2.2
2023
-
[8]
NVIDIA Corporation. 2023. NVIDIA Hopper H100 GPU: Scaling Performance. IEEE Micro43, 4 (2023), 56–65. doi:10.1109/MM.2023.10070122
-
[9]
2025.Nsight Compute Profiling Guide
NVIDIA Corporation. 2025.Nsight Compute Profiling Guide. https://docs.nvidia. com/nsight-compute/ProfilingGuide/index.html Version 2025.3.1
2025
-
[10]
Bill Dally. 2023. The Secret to NVIDIA’s AI Success.IEEE Spectrum(2023). https://spectrum.ieee.org/nvidia-gpu
2023
-
[11]
M. Dombrowski, H. Reynaud, J. P. Müller, M. Baugh, and B. Kainz. 2024. Trade- Offs in Fine-Tuned Diffusion Models between Accuracy and Interpretability. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. AAAI Press, 21037–21045. doi:10.1609/aaai.v38i19.30095
-
[12]
Z. Dorjsembe, H.-K. Pao, S. Odonchimed, and F. Xiao. 2024. Conditional Diffusion Models for Semantic 3D Brain MRI Synthesis.IEEE Journal of Biomedical and Health Informatics28, 7 (July 2024), 4084–4093. doi:10.1109/JBHI.2024.3385504
-
[13]
J. Ekelund, S. Markidis, and I. Peng. 2025. Boosting Performance of Iterative Applications on GPUs: Kernel Batching with CUDA Graphs. InProceedings of the 2025 33rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP). IEEE, Turin, Italy, 70–77. doi:10.1109/PDP66500. 2025.00019
-
[14]
N. Gaggion, L. Mansilla, C. Mosquera, D. H. Milone, and E. Ferrante. 2023. Improv- ing Anatomical Plausibility in Medical Image Segmentation via Hybrid Graph Neural Networks: Applications to Chest X-Ray Analysis.IEEE Transactions on Medical Imaging42, 2 (February 2023), 546–556. doi:10.1109/TMI.2022.3224660
-
[15]
Irena Galić, Marija Habijan, Hrvoje Leventić, and Krešimir Romić. 2023. Machine Learning Empowering Personalized Medicine: A Comprehensive Review of Medical Image Analysis Methods.Electronics12, 21, Article 4411 (2023). doi:10. 3390/electronics12214411
2023
-
[16]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. InAdvances in Neural Information Processing Systems
2014
-
[17]
P. Guo, Y. Mei, J. Zhou, S. Jiang, and V. M. Patel. 2024. ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer.IEEE Transactions on Medical Imaging43, 1 (January 2024), 582–593. doi:10.1109/TMI.2023.3314747
-
[18]
Bagus Hanindhito and Lizy K. John. 2024. Accelerating ML Workloads using GPU Tensor Cores: The Good, the Bad, and the Ugly. InProceedings of the 15th ACM/SPEC International Conference on Performance Engineering (ICPE ’24). ACM,
2024
-
[19]
doi:10.1145/3629526.3653835
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[21]
Leeman, Yue-Houng Hu, Raymond H
Shu-Hui Hsu, Zhaohui Han, Jonathan E. Leeman, Yue-Houng Hu, Raymond H. Mak, and Atchar Sudhyadhom. 2022. Synthetic CT generation for MRI-guided adaptive radiotherapy in prostate cancer.Frontiers in Oncology12 (2022). doi:10. 3389/fonc.2022.969463
arXiv 2022
-
[22]
I. Irmakci, Z. E. Unel, N. Ikizler-Cinbis, and U. Bagci. 2022. Multi-Contrast MRI Segmentation Trained on Synthetic Images. InProceedings of the 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). IEEE, Glasgow, Scotland, United Kingdom, 5030–5034. doi:10. 1109/EMBC48229.2022.9871119
arXiv 2022
-
[23]
Zhe Jia, Michael Garland, and Yuandong Tian. 2016. Dissecting GPU Memory Hierarchy Through Microbenchmarking.IEEE Transactions on Parallel and Distributed Systems27, 7 (2016), 1944–1957. doi:10.1109/TPDS.2016.2531642
-
[24]
Chutian Jiang. 2021. Efficient Quantization Techniques for Deep Neural Net- works. InProceedings of the 2021 International Conference on Signal Process- ing and Machine Learning (CONF-SPML). IEEE, 271–277. doi:10.1109/CONF- SPML54095.2021.00059
-
[25]
IEEE Journal of Biomedical and Health Informatics , author =
H. Jiang, Z. Wang, D. Liu, L. Guo, et al . 2025. Fast-DDPM: Fast Denoising Diffusion Probabilistic Models for Medical Image-to-Image Generation.IEEE Journal of Biomedical and Health Informatics29, 10 (October 2025), 7326–7335. doi:10.1109/JBHI.2025.3565183
-
[26]
Mingfeng Jiang, Peihang Jia, Xin Huang, Zihan Yuan, Dongsheng Ruan, Feng Liu, and Ling Xia. 2025. Frequency-Aware Diffusion Model for Multi-Modal MRI Im- age Synthesis.Journal of Imaging11, 5 (2025), 152. doi:10.3390/jimaging11050152
-
[27]
W. Kong et al. 2024. Cambricon-D: Full-Network Differential Acceleration for Diffusion Models. InProceedings of the 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, Buenos Aires, Argentina, 903–914. doi:10.1109/ISCA59077.2024.00070
-
[28]
R. R. Kumar, S. V. Shankar, R. Jaiswal, et al. 2025. Advances in Deep Learning for Medical Image Analysis: A Comprehensive Investigation.Journal of Statistical Theory and Practice19, 1 (2025), 9. doi:10.1007/s42519-024-00422-2
-
[29]
Rachel Lawrence, Emma Dodsworth, Efthalia Massou, Chris Sherlaw-Johnson, Angus I. G. Ramsay, Holly Walton, Tracy O’Regan, Fergus Gleeson, Nadia Crellin, Kevin Herbert, Pei Li Ng, Holly Elphinstone, Raj Mehta, Joanne Lloyd, Amanda Halliday, Stephen Morris, and Naomi J. Fulop. 2025. Artificial intelligence for diagnostics in radiology practice: a rapid syst...
-
[30]
H. Laçi, K. Sevrani, and S. Iqbal. 2025. Deep learning approaches for classification tasks in medical X-ray, MRI, and ultrasound images: a scoping review.BMC Medical Imaging25, 1 (2025), 156. doi:10.1186/s12880-025-01701-5
-
[31]
Mengfang Li, Yuanyuan Jiang, Yanzhou Zhang, and Haisheng Zhu. 2023. Medical image analysis using deep learning algorithms.Frontiers in Public Health11 (2023). doi:10.3389/fpubh.2023.1273253
-
[32]
D. Liu, Z. Wang, and L. Guo. 2025. A Plug-and-Play Diffusion-Styled Conversion Model for Domain Discrepancies in Medical Image Segmentation. InProceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Hyderabad, India, 1–5. doi:10.1109/ICASSP49660.2025.10889167
-
[33]
Y. Liu, Y. Feng, J. Cheng, H. Zhan, and Z. Zhu. 2025. MambaDiff: Mamba- Enhanced Diffusion Model for 3D Medical Image Segmentation.IEEE Transactions on Image Processing34 (2025), 5761–5775. doi:10.1109/TIP.2025.3607615
-
[34]
Yifan Liu and Xipeng Shen. 2021. Analyzing and Leveraging Decoupled L1 Caches in GPUs. InProceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 1–11. doi:10.1109/ISPASS48437. 2021.9407080
-
[35]
Z. Liu, A. Song, N. Sabar, and W. Li. 2024. Evolving a Better Scheduler for Diffusion Models. InPRICAI 2023: Trends in Artificial Intelligence (Lecture Notes in Computer Science, Vol. 14326), F. Liu, A. A. Sadanandan, D. N. Pham, P. Mursanto, and D. Lukose (Eds.). Springer, Singapore. doi:10.1007/978-981-99-7022-3_37
-
[36]
Y. Luo, Q. Yang, Y. Fan, H. Qi, and M. Xia. 2024. Measurement Guidance in Diffusion Models: Insight from Medical Image Synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (December 2024), 7983–7997. doi:10.1109/TPAMI.2024.3399098 Jeeho Ryoo et al
-
[37]
Alessio Luschi, Linda Tognetti, Alessandra Cartocci, Elisa Cinotti, Gio- vanni Rubegni, Laura Calabrese, Martina D’onghia, Martina Dragotto, Elvira Moscarella, Gabriella Brancaccio, Giulia Briatico, Camila Scharf, Dario Buononato, Vittorio Tancredi, Carmen Cantisani, Camilla Chello, Luca Ambro- sio, Pietro Scribani Rossi, Marco Virone, Giovanni Pellacani,...
-
[38]
Gustav Müller-Franzes, David Zimmerer, Fabian Isensee, and Klaus H. Maier- Hein. 2023. A Multimodal Comparison of Latent Denoising Diffusion Probabilis- tic Models and Generative Adversarial Networks for Medical Image Synthesis. Scientific Reports13, 1 (2023), 12456. doi:10.1038/s41598-023-39278-0
-
[39]
Maham Nazir, Muhammad Aqeel, and Francesco Setti. 2025. Diffusion-Based Data Augmentation for Medical Image Segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. IEEE, 1330–1339
2025
-
[40]
Nichol and Prafulla Dhariwal
Alexander Q. Nichol and Prafulla Dhariwal. 2021. Improved Denoising Diffu- sion Probabilistic Models. InProceedings of the 38th International Conference on Machine Learning
2021
-
[41]
IEEE Transactions on Medical Imaging. 2024. Special Issue on Score-Based Generative Models for Medical Imaging.IEEE Transactions on Medical Imaging (2024)
2024
-
[42]
Geon Yeong Park, Sang Wan Lee, and Jong Chul Ye. 2025. Inference-Time Diffu- sion Model Distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4049–4058
2025
-
[43]
J. Peng et al . 2022. Knowledge-Driven Generative Adversarial Network for Text-to-Image Synthesis.IEEE Transactions on Multimedia24 (2022), 4356–4366. doi:10.1109/TMM.2021.3116416
-
[44]
Matteo Pozzi, Shahryar Noei, Erich Robbi, Luca Cima, Monica Moroni, Enrico Munari, Evelin Torresani, and Giuseppe Jurman. 2024. Generating and evaluating synthetic data in digital pathology through diffusion models.Scientific Reports 14, 1 (November 2024), 28435. doi:10.1038/s41598-024-79602-w
-
[45]
Chen Qian, Haoyu Zhang, Dan Ruan, Yirong Zhou, and Xiaobo Qu. 2023. Physics- Informed Deep Diffusion MRI Reconstruction: Break the Bottleneck of Training Data in Artificial Intelligence. InProceedings of the IEEE International Symposium on Biomedical Imaging (ISBI). IEEE, 1–5. doi:10.1109/ISBI53787.2023.10230567
-
[46]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI). Springer, 234–241. doi:10.1007/978-3- 319-24574-4_28
-
[47]
Ravi K. Samala, Karen Drukker, Amita Shukla-Dave, Heang-Ping Chan, Berk- man Sahiner, Nicholas Petrick, Hayit Greenspan, Usman Mahmood, Ronald M. Summers, Georgia Tourassi, Thomas M. Deserno, Daniele Regge, Janne J. Näppi, Hiroyuki Yoshida, Zhimin Huo, Quan Chen, Daniel Vergara, Kenny H. Cha, Richard Mazurchuk, Kevin T. Grizzard, Henkjan Huisman, Lia Morr...
-
[48]
Vikash Sehwag, Xianghao Kong, Jingtao Li, Michael Spranger, and Lingjuan Lyu. 2025. Stretching Each Dollar: Diffusion Training from Scratch on a Micro- Budget. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 28596–28608
2025
-
[49]
Isabella Barbosa Silva, Elsa Oliveira, Ricardo Melo, Luís Rosado, César Gálvez- Barrón, Irene Bernadet Heijink, Sem Hoogteijling, and Iñigo Gabilondo. 2025. Designing for Qualitative Evaluation of Synthetic Medical Data. InExtended Abstracts of the 2025 CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machinery,...
-
[50]
Elena Sizikova, Andreu Badal, Jana G. Delfino, Miguel Lago, Brandon Nelson, Niloufar Saharkhiz, Berkman Sahiner, Ghada Zamzmi, and Aldo Badano. 2024. Synthetic data in radiological imaging: current state and future outlook.BJR Artificial Intelligence1, 1 (May 2024), ubae007. doi:10.1093/bjrai/ubae007
-
[51]
Jinzhuo Wang, Kai Wang, Yunfang Yu, Yuxing Lu, Wenchao Xiao, Zhuo Sun, Fei Liu, Zixing Zou, Yuanxu Gao, Lei Yang, Hong-Yu Zhou, Hanpei Miao, Wenting Zhao, Lisha Huang, Lingchao Zeng, Rui Guo, Ieng Chong, Boyu Deng, Linling Cheng, Xiaoniao Chen, Jing Luo, Meng-Hua Zhu, Daniel Baptista-Hon, Olivia Monteiro, Ming Li, Yu Ke, Jiahui Li, Simiao Zeng, Taihua Gua...
2025
-
[52]
Simoncelli, and Alan C
Zhou Wang, Eero P. Simoncelli, and Alan C. Bovik. 2003. Multi-Scale Structural Similarity for Image Quality Assessment. InProceedings of the 37th Asilomar Conference on Signals, Systems and Computers
2003
-
[53]
Asim Waqas, Aakash Tripathi, Ravi P. Ramachandran, Paul A. Stewart, and Ghulam Rasool. 2024. Multimodal data integration for oncology in the era of deep neural networks: a review.Frontiers in Artificial Intelligence7 (2024). doi:10.3389/frai.2024.1408843
-
[54]
George Webber and Andrew J. Reader. 2024. Diffusion Models for Medical Image Reconstruction.BJR|Artificial Intelligence1, 1 (2024), ubae013. doi:10.1093/bjrai/ ubae013
-
[55]
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cremers, Peter Vajda, and Jialiang Wang. 2024. Cache Me if You Can: Accelerating Diffusion Models through Block Caching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern...
2024
-
[56]
K. Xu, S. Lu, B. Huang, W. Wu, and Q. Liu. 2024. Stage-by-Stage Wavelet Optimization Refinement Diffusion Model for Sparse-View CT Reconstruc- tion.IEEE Transactions on Medical Imaging43, 10 (October 2024), 3412–3424. doi:10.1109/TMI.2024.3355455
-
[57]
Tony Xu, Sepehr Hosseini, Chris Anderson, Anthony Rinaldi, Rahul G. Krishnan, Anne L. Martel, and Maged Goubran. 2025. A generalizable 3D framework and model for self-supervised learning in medical imaging.npj Digital Medicine8, 1 (2025), 639. doi:10.1038/s41746-025-02035-w
-
[58]
Charlene Yang, Thorsten Kurth, and Samuel Williams. 2020. Hierarchical Roofline Analysis for GPUs: Accelerating Performance Optimization for the NERSC-9 Perlmutter System.Concurrency and Computation: Practice and Experience32, 24 (2020), e5547. doi:10.1002/cpe.5547
-
[59]
Charlene Yang, Yunsong Wang, Thorsten Kurth, Samuel Williams, and Steven Farrell. 2020. Hierarchical Roofline Performance Analysis for Deep Learning Ap- plications. InProceedings of SC ’20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE/ACM. doi:10.1109/SC41405. 2020.00045
-
[60]
Xin Yi, Ekta Walia, and Paul Babyn. 2019. Generative Adversarial Network in Medical Imaging: A Review.Medical Image Analysis(2019)
2019
-
[61]
Haoyu Zhang, Chen Qian, and Xiaobo Qu. 2023. A Reconfigurable Processing Element for Multiple-Precision Floating/Fixed-Point HPC.IEEE Transactions on Circuits and Systems II: Express Briefs70, 10 (2023), 3456–3460. doi:10.1109/TCSII. 2023.10272667
-
[62]
T. Zhang, X. Chen, C. Qu, A. Yuille, and Z. Zhou. 2024. Leveraging AI Predicted and Expert Revised Annotations in Interactive Segmentation: Continual Tuning or Full Training?. InProceedings of the 2024 IEEE International Symposium on Biomedical Imaging (ISBI). IEEE, Athens, Greece, 1–5. doi:10.1109/ISBI56570.2024. 10635518
-
[63]
J. Zhao and S. Li. 2025. Radiomics-Driven Diffusion Model and Monte Carlo Compression Sampling for Reliable Medical Image Synthesis.IEEE Journal of Biomedical and Health Informatics(2025). doi:10.1109/JBHI.2025.3602674
-
[64]
Z. Zhao, F. Zhou, K. Xu, Z. Zeng, C. Guan, and S. K. Zhou. 2023. LE-UDA: Label- Efficient Unsupervised Domain Adaptation for Medical Image Segmentation. IEEE Transactions on Medical Imaging42, 3 (March 2023), 633–646. doi:10.1109/ TMI.2022.3214766
arXiv 2023
-
[65]
Zhenyu Zhou, Defang Chen, Can Wang, Chun Chen, and Siwei Lyu. 2024. Simple and Fast Distillation of Diffusion Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 40831–40860. doi:10.52202/079017-1291
-
[66]
Lienkamp, Thomas Brox, and Olaf Ronneberger
Özgün Çiçek, Ahmed Abdulkadir, Soeren S. Lienkamp, Thomas Brox, and Olaf Ronneberger. 2016. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. InMedical Image Computing and Computer-Assisted Interven- tion – MICCAI
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.