OpenRath: Session-Centered Runtime State for Agent Systems
Pith reviewed 2026-06-26 20:16 UTC · model grok-4.3
The pith
Session provides agent systems with a first-class runtime value for auditable composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
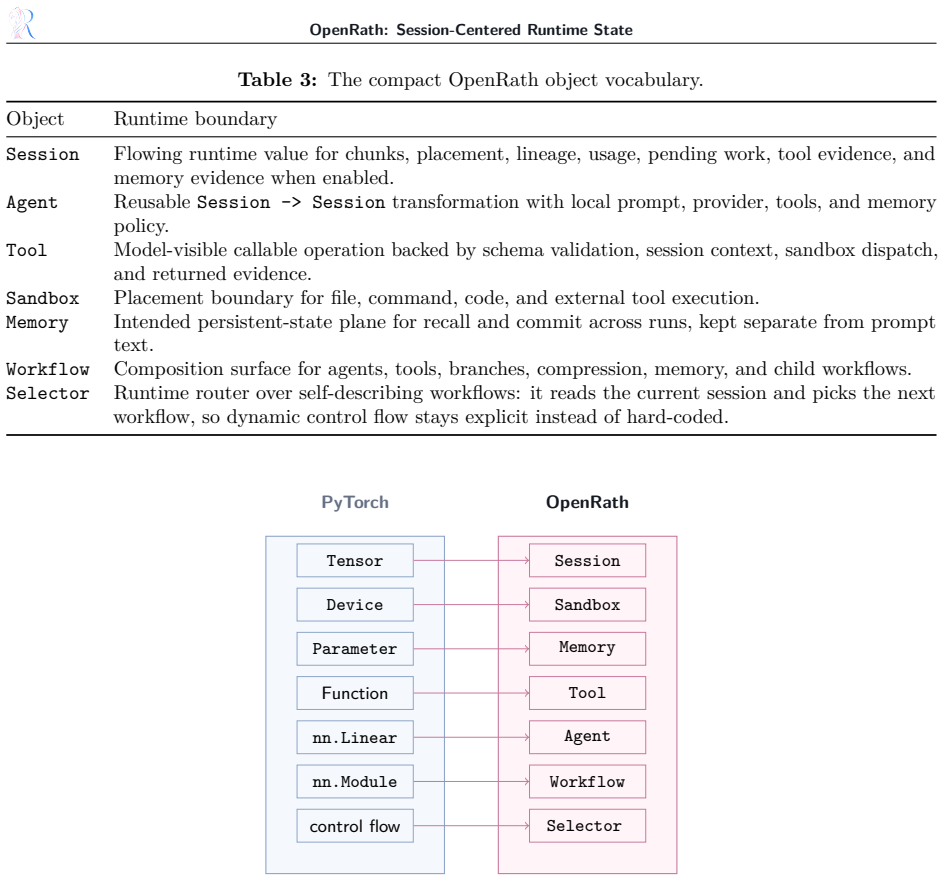
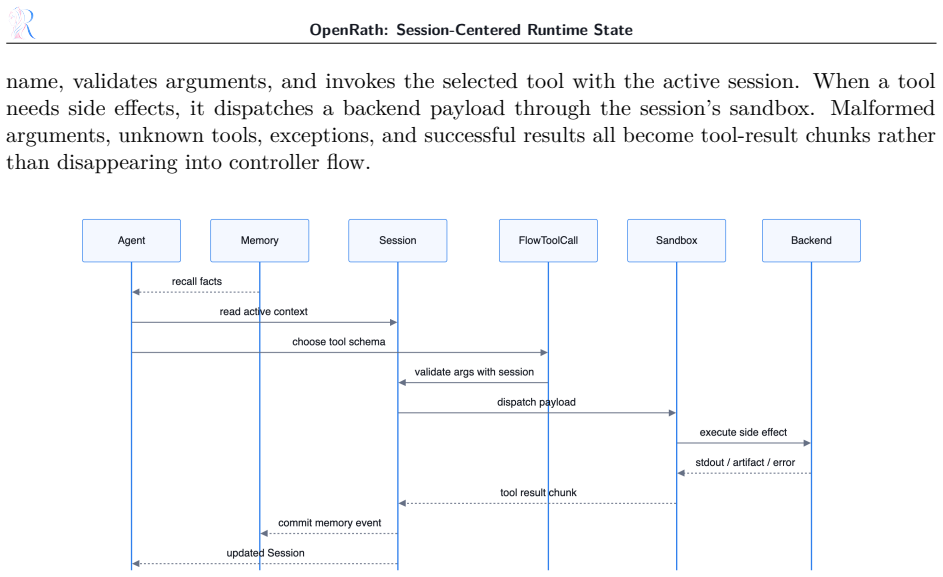
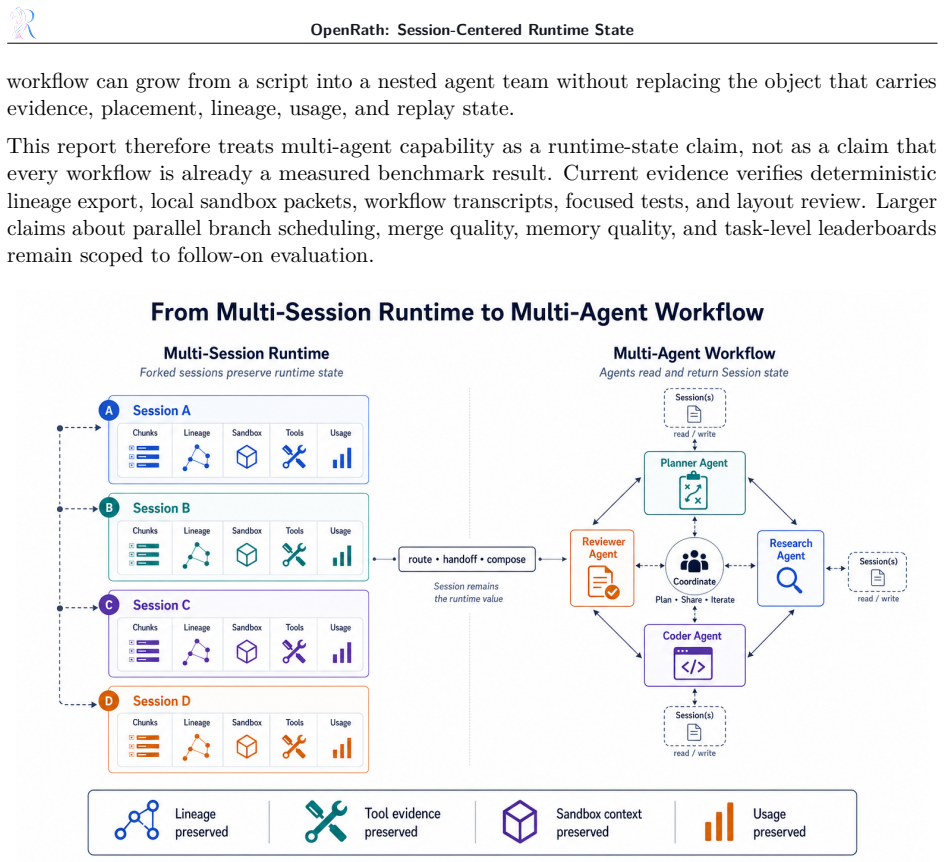
The central claim is that Session provides agent systems with a first-class runtime value for auditable composition. Session is branchable, inspectable, replayable, backend-aware, and composable. It records conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence while defining where memory interactions enter the runtime record. This makes fork, merge, and replay explicit runtime operations rather than states reconstructed from external traces. The model further defines Sandbox, Tool, Agent, Memory, Workflow, and Selector abstractions, with Selector turning control flow into runtime-routed decisions.
What carries the argument
Session, the runtime value passed between agents and workflows that is branchable, inspectable, replayable, backend-aware, and composable while recording conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence.
If this is right
- Fork, merge, and replay become explicit runtime operations.
- Control flow decisions are routed at runtime through the Selector abstraction.
- Memory interactions enter the runtime record at explicitly defined points.
- The overall system gains a unified value for carrying state across multi-session executions.
Where Pith is reading between the lines
- Existing agent frameworks could adopt Session to reduce reliance on separate tracing tools for reproducibility.
- Branching sessions might support parallel exploration of agent behaviors without duplicating external logs.
- The model could extend to non-agent workflows where state provenance must remain tied to execution.
Load-bearing premise
That recording conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence inside the same runtime value passed during execution will make fork, merge, and replay explicit operations rather than states reconstructed from external traces.
What would settle it
An implementation of the Session model in which fork or replay still requires reconstructing state from external traces or logs would falsify the central claim.
Figures



read the original abstract
Modern agent systems often suffer from fragmented runtime state: transcripts, tool effects, memory events, workspace placement, branch provenance, and replay evidence are recorded separately and become difficult to inspect or reproduce. OpenRath addresses this issue with a PyTorch-like programming model for multi-agent, multi-session systems. The analogy concerns the role of a central first-class runtime abstraction, not tensor computation. Its core abstraction is Session, the runtime value passed between agents and workflows. A Session is branchable, inspectable, replayable, backend-aware, and composable. It records conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence, while defining where memory interactions enter the runtime record. Since this state is carried by the same value used in program execution, fork, merge, and replay become explicit runtime operations rather than states reconstructed from external traces. OpenRath further defines Sandbox, Tool, Agent, Memory, Workflow, and Selector, with Selector turning control flow into runtime-routed decisions. This report presents the programming model, architecture, audited milestones, and evidence protocol. Its claims are limited to controlled runtime properties, while broad quantitative comparisons, live-provider quality, optional-backend availability, and memory quality are left for follow-on evaluation. The central thesis is that Session provides agent systems with a first-class runtime value for auditable composition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OpenRath, a PyTorch-analogous programming model for multi-agent, multi-session systems whose core abstraction is the Session: a first-class, branchable, inspectable, replayable, backend-aware, and composable runtime value passed between agents and workflows. Session records conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence while defining memory interaction points; this design is claimed to turn fork, merge, and replay into explicit runtime operations. The model further defines Sandbox, Tool, Agent, Memory, Workflow, and Selector (the latter routing control flow at runtime). The report presents the programming model, architecture, audited milestones, and evidence protocol, with all claims explicitly limited to controlled runtime properties.
Significance. If the Session-centered model can be realized without hidden external dependencies, it would offer a unified mechanism for state management that directly supports auditability and reproducibility in agent systems. The explicit treatment of fork/merge/replay and the evidence protocol constitute concrete strengths that could serve as a reference point for subsequent implementations, even though the current manuscript supplies no code, data, or formal semantics.
major comments (2)
- [Abstract] Abstract: the central thesis that carrying conversation chunks, sandbox placement, lineage, token usage, pending work, and tool evidence inside the same Session value makes fork, merge, and replay 'explicit runtime operations rather than states reconstructed from external traces' is load-bearing yet rests solely on the definitional claim; no pseudocode, workflow fragment, or operation signature is supplied to show how an agent would invoke these operations on the Session object.
- [Abstract] Abstract / architecture description: Selector is said to turn control flow into runtime-routed decisions, but the manuscript supplies no account of how Selector consults the recorded pending work and tool evidence to guarantee replay determinism; this interaction is essential to the claim that all listed state elements remain inside the runtime value.
minor comments (1)
- [Abstract] The PyTorch analogy is stated but never elaborated (e.g., which tensor-like operations or autograd-style tracking are being paralleled), leaving the intended developer interface unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central thesis that carrying conversation chunks, sandbox placement, lineage, token usage, pending work, and tool evidence inside the same Session value makes fork, merge, and replay 'explicit runtime operations rather than states reconstructed from external traces' is load-bearing yet rests solely on the definitional claim; no pseudocode, workflow fragment, or operation signature is supplied to show how an agent would invoke these operations on the Session object.
Authors: We agree that the manuscript supplies no pseudocode, workflow fragments, or operation signatures. The presentation centers on the architectural role of Session as a first-class, branchable runtime value that unifies state elements, thereby rendering fork, merge, and replay explicit by definition rather than through external reconstruction. To make this claim more concrete, we will add pseudocode examples and a workflow fragment illustrating the relevant Session operations in the revised version. revision: yes
-
Referee: [Abstract] Abstract / architecture description: Selector is said to turn control flow into runtime-routed decisions, but the manuscript supplies no account of how Selector consults the recorded pending work and tool evidence to guarantee replay determinism; this interaction is essential to the claim that all listed state elements remain inside the runtime value.
Authors: We acknowledge that the manuscript does not detail the mechanism by which Selector consults pending work and tool evidence. Selector is defined at the architectural level as the component that routes control flow using runtime state carried in the Session. In revision we will expand this section to describe the consultation process and its role in preserving replay determinism while ensuring all state elements remain within the Session value. revision: yes
Circularity Check
No significant circularity; definitional proposal of new abstraction
full rationale
The manuscript proposes Session as a first-class runtime value that carries conversation chunks, sandbox placement, lineage metadata, token usage, pending work, and tool evidence. This is presented as a programming model definition (PyTorch-like analogy for state passing), not a derivation from equations or fitted parameters. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core claim. Fork/merge/replay are defined as explicit operations precisely because the state is carried by the Session value passed at runtime; this is definitional rather than a reduction to prior inputs. The paper explicitly limits claims to controlled runtime properties and leaves quantitative evaluation for follow-on work. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fragmented runtime state in agent systems is a problem that a single first-class runtime value can solve
invented entities (3)
-
Session
no independent evidence
-
Sandbox
no independent evidence
-
Selector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models, 2023. URL https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[2]
PyTorch: An Imperative Style, High-Performance Deep Learning Library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Performa...
Pith/arXiv arXiv 2019
-
[3]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation,
-
[4]
URLhttps://arxiv.org/abs/2308.08155
-
[5]
LangGraph: Persistence, 2025
LangChain. LangGraph: Persistence, 2025. URL https://docs.langchain.com/oss/ python/langgraph/persistence
2025
-
[6]
OpenAI Agents SDK: Tracing, 2025
OpenAI. OpenAI Agents SDK: Tracing, 2025. URL https://openai.github.io/ openai-agents-python/tracing/
2025
-
[7]
What is the Model Context Protocol (MCP)?, 2025
Model Context Protocol. What is the Model Context Protocol (MCP)?, 2025. URLhttps: //modelcontextprotocol.io/docs/getting-started/intro
2025
-
[8]
Introducing the Model Context Protocol, 2024
Anthropic. Introducing the Model Context Protocol, 2024. URLhttps://www.anthropic. com/news/model-context-protocol
2024
-
[9]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2023
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2023. URLhttps://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[10]
Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2023
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2023. URLhttps://arxiv.org/abs/2203.11171
Pith/arXiv arXiv 2023
-
[11]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. MRKL Systems: A Modular, Neuro-Symbolic Architecture that Combines Large Language Models, External Knowledg...
Pith/arXiv arXiv 2022
-
[12]
Toolformer: Language Models Can Teach Themselves to Use Tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools, 2023. URLhttps://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[13]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, 2023
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, 2023. URL https://arxiv.org/abs/2303.17580
Pith/arXiv arXiv 2023
-
[14]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large Language Model Connected with Massive APIs, 2023. URLhttps://arxiv.org/abs/2305.15334. 16 OpenRath: Session-Centered Runtime State
Pith/arXiv arXiv 2023
-
[15]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, 2023. URLhttps://arxiv.org/abs/2307.16789
Pith/arXiv arXiv 2023
-
[16]
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs,
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs,
-
[17]
URLhttps://arxiv.org/abs/2304.08244
-
[18]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, 2023
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, 2023. URLhttps://arxiv.org/abs/2306.05301
Pith/arXiv arXiv 2023
-
[19]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models, 2023. URLhttps://arxiv.org/abs/2305.10601
Pith/arXiv arXiv 2023
-
[20]
CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society, 2023
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative Agents for “Mind” Exploration of Large Language Model Society, 2023. URLhttps://arxiv.org/abs/2303.17760
Pith/arXiv arXiv 2023
-
[21]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, 2024
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, 2024. URLhttps://arxiv.org/abs/2308.00352
Pith/arXiv arXiv 2024
-
[22]
ChatDev: Communicative Agents for Software Development, 2024
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative Agents for Software Development, 2024. URLhttps://arxiv.org/abs/2307. 07924
2024
-
[23]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors, 2023
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors, 2023. URLhttps://arxiv.org/abs/2308.10848
Pith/arXiv arXiv 2023
-
[24]
LangGraph: Use Time Travel, 2025
LangChain. LangGraph: Use Time Travel, 2025. URLhttps://docs.langchain.com/oss/ python/langgraph/use-time-travel
2025
-
[25]
OpenAI Agents SDK: Agents, 2025
OpenAI. OpenAI Agents SDK: Agents, 2025. URL https://openai.github.io/ openai-agents-python/agents/
2025
-
[26]
Traces, 2025
OpenTelemetry. Traces, 2025. URLhttps://opentelemetry.io/docs/concepts/signals/ traces/
2025
-
[27]
OpenAPI Specification Version 3.1.0, 2021
OpenAPI Initiative. OpenAPI Specification Version 3.1.0, 2021. URLhttps://swagger.io/ specification/
2021
-
[28]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: A System for Large...
Pith/arXiv arXiv 2016
-
[29]
Reflexion: Language Agents with Verbal Reinforcement Learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language Agents with Verbal Reinforcement Learning, 2023. URL https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[30]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior, 2023. URLhttps://arxiv.org/abs/2304.03442
Pith/arXiv arXiv 2023
-
[31]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as Operating Systems, 2024. URLhttps: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[32]
Voyager: An Open-Ended Embodied Agent with Large Language Models, 2023
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An Open-Ended Embodied Agent with Large Language Models, 2023. URLhttps://arxiv.org/abs/2305.16291
Pith/arXiv arXiv 2023
-
[33]
AgentBench: Evaluating LLMs as Agents, 2025
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as Agents, 2025. URLhttps://arxiv.org/ abs/2308.03688
Pith/arXiv arXiv 2025
-
[34]
URLhttps://arxiv.org/ abs/2406.12045
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains, 2024. URLhttps://arxiv.org/ abs/2406.12045
Pith/arXiv arXiv 2024
-
[35]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?,
-
[36]
URLhttps://arxiv.org/abs/2310.06770
-
[37]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[38]
SWE-bench Verified, 2024
OpenAI. SWE-bench Verified, 2024. URLhttps://www.swebench.com/verified.html
2024
-
[39]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, et al. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, 2026. URLhttps://arxiv. org/abs/2601.11868
Pith/arXiv arXiv 2026
-
[40]
Barr, Mark Harman, Federica Sarro, and He Ye
Zhaoyang Chu, Jiarui Hu, Xingyu Jiang, Pengyu Zou, Han Li, Chao Peng, Peter O’Hearn, Earl T. Barr, Mark Harman, Federica Sarro, and He Ye. TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks, 2026. URLhttps://arxiv.org/abs/2605.22535
Pith/arXiv arXiv 2026
-
[41]
No More, No Less: Task Alignment in Terminal Agents, 2026
Sina Mavali, David Pape, Jonathan Evertz, Samira Abedini, Devansh Srivastav, Thorsten Eisenhofer, Sahar Abdelnabi, and Lea Schönherr. No More, No Less: Task Alignment in Terminal Agents, 2026. URLhttps://arxiv.org/abs/2605.12233
Pith/arXiv arXiv 2026
-
[42]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents, 2024. URLhttps://arxiv. org/abs/2307.13854. 18 OpenRath: Session-Centered Runtime State
Pith/arXiv arXiv 2024
-
[43]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks, 2024
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks, 2024. URLhttps://arxiv. org/abs/2401.13649
Pith/arXiv arXiv 2024
-
[44]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?, 2024. URLhttps://arxiv.org/abs/2403.07718
Pith/arXiv arXiv 2024
-
[45]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, 2024. URL https://arxiv.org/abs/2404.07972
Pith/arXiv arXiv 2024
-
[46]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, 2023. URLhttps: //arxiv.org/abs/2207.01206
arXiv 2023
-
[47]
Mind2Web: Towards a Generalist Agent for the Web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a Generalist Agent for the Web, 2023. URL https: //arxiv.org/abs/2306.06070
Pith/arXiv arXiv 2023
-
[48]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, 2021
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, 2021. URLhttps://arxiv.org/abs/2010.03768
Pith/arXiv arXiv 2021
-
[49]
Science- World: Is your Agent Smarter than a 5th Grader?, 2022
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Science- World: Is your Agent Smarter than a 5th Grader?, 2022. URLhttps://arxiv.org/abs/ 2203.07540
arXiv 2022
-
[50]
GAIA: a Benchmark for General AI Assistants, 2023
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a Benchmark for General AI Assistants, 2023. URLhttps://arxiv.org/ abs/2311.12983
Pith/arXiv arXiv 2023
-
[51]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, 2025....
Pith/arXiv arXiv 2025
-
[52]
Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection, 2023
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection, 2023. URL https://arxiv.org/abs/2302. 12173
2023
-
[53]
Agent-SafetyBench: Evaluating the Safety of LLM Agents, 2025
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-SafetyBench: Evaluating the Safety of LLM Agents, 2025. URL https://arxiv.org/abs/2412.14470
Pith/arXiv arXiv 2025
-
[54]
SafeArena: Evaluating the Safety of Autonomous Web Agents, 2025
Ada Defne Tur, Nicholas Meade, Xing Han Lù, Alejandra Zambrano, Arkil Patel, Esin Durmus, Spandana Gella, Karolina Stańczak, and Siva Reddy. SafeArena: Evaluating the Safety of Autonomous Web Agents, 2025. URLhttps://arxiv.org/abs/2503.04957. 19 OpenRath: Session-Centered Runtime State
arXiv 2025
-
[55]
SafeAgentBench: A Benchmark for Safe Task Planning of Embodied LLM Agents, 2025
Sheng Yin, Xianghe Pang, Yuanzhuo Ding, Menglan Chen, Yutong Bi, Yichen Xiong, Wenhao Huang, Zhen Xiang, Jing Shao, and Siheng Chen. SafeAgentBench: A Benchmark for Safe Task Planning of Embodied LLM Agents, 2025. URLhttps://arxiv.org/abs/2412.13178. 20 OpenRath: Session-Centered Runtime State Appendix A Case Studies The case studies are used as scoped ap...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.