Stalls and Spequlation: Pipelined Execution for Fault Tolerant Quantum Computation
Pith reviewed 2026-06-26 20:14 UTC · model grok-4.3
The pith
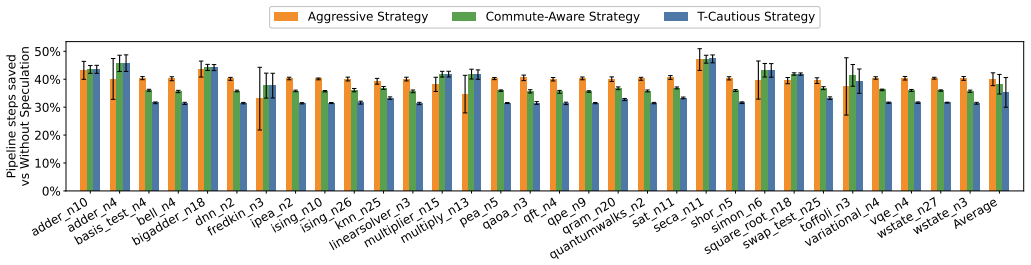
Speculation in pipelined fault-tolerant quantum computation reduces total pipeline steps by 20-40 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
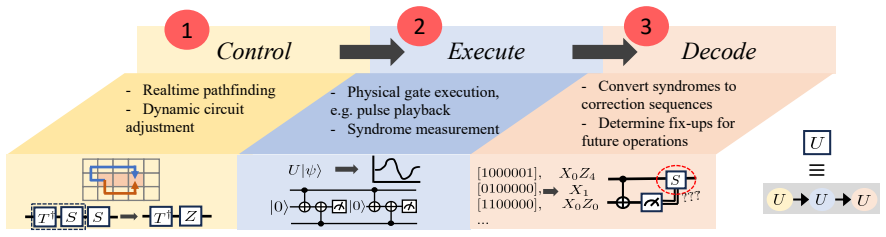
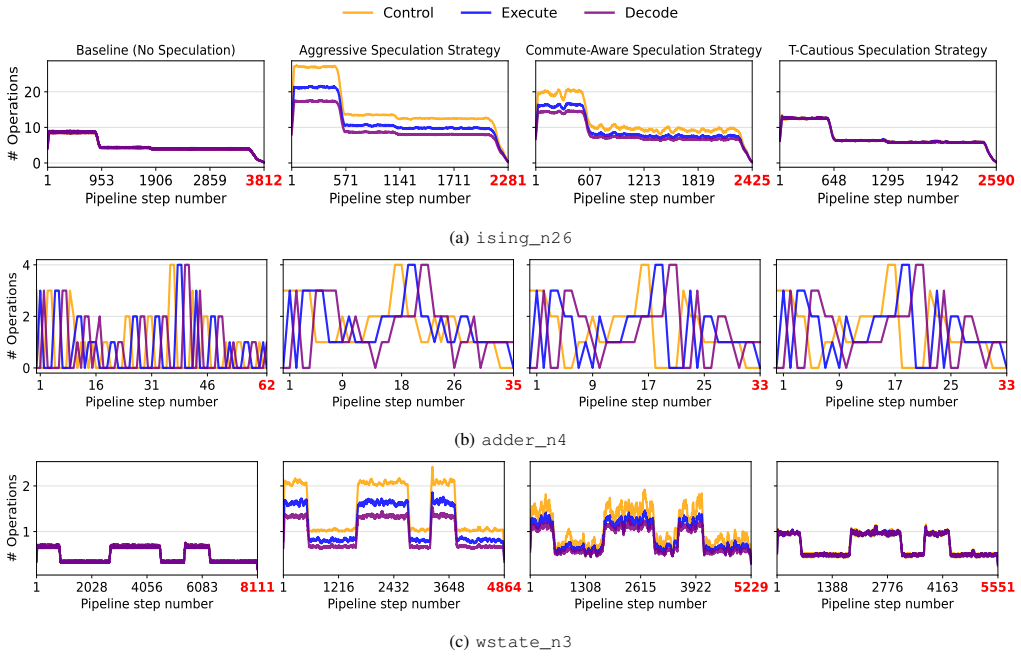
Decomposing logical operations into Control, Execute, and Decode stages and allowing speculation so that successor operations begin before predecessors complete decoding reduces total pipeline steps by 20-40% on common benchmarks, with the most aggressive strategy performing best because rollback costs remain low relative to the parallelism obtained, while also enabling better load balancing across heterogeneous subsystems.
What carries the argument
A pipelined execution framework that decomposes logical operations into Control, Execute, and Decode stages together with speculation strategies that permit successor operations to begin before decoding of predecessors finishes.
If this is right
- Total pipeline steps drop 20-40% relative to no-speculation baselines.
- Aggressive speculation outperforms conservative variants despite occasional partial rollbacks.
- Work distributes more evenly across classical control, quantum hardware, and decoders.
- Idle time in one subsystem converts into useful computation in others.
- Overall execution time decreases.
Where Pith is reading between the lines
- Hardware designers might prioritize low-cost rollback mechanisms in decoders to maximize these gains.
- The technique could extend to other systems where control and verification loops create idle periods.
- Simulations with varying error rates would test how speculation benefits scale with decoding difficulty.
- Benchmarking against real quantum device latencies would reveal whether the 20-40% savings hold in practice.
Load-bearing premise
Rollback costs from incorrect speculations remain small enough relative to the parallelism gained that net performance improves on realistic workloads.
What would settle it
Running the framework on a workload where a single incorrect speculation triggers a rollback whose time cost exceeds the entire parallelism benefit from overlapping operations.
Figures

read the original abstract
Fault-tolerant quantum computation requires the coordinated action of three distinct systems: classical control logic, quantum hardware, and classical error decoders. Current scheduling models treat logical operations as atomic, hiding the fact that these subsystems operate sequentially and spend significant time idle. We present a pipelined execution framework that decomposes each logical operation into its component stages i.e. Control, Execute, and Decode. Building on this, we discuss some speculation strategies that allow successor operations to begin processing before their predecessors have completed decoding. We evaluate our framework on several common benchmarks and show that pipelining with speculation reduces total pipeline steps by 20-40% compared to a no-speculation baseline. The most aggressive strategy consistently outperforms conservative alternatives, even though partial rollback is needed at times, because the per-rollback penalty is small relative to the parallelism gained. We further show that speculation facilitates load balancing by distributing work more evenly across the heterogeneous subsystems of a fault-tolerant quantum computer, converting idle time into useful computation while also saving on execution time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a pipelined execution framework for fault-tolerant quantum computation that decomposes each logical operation into Control, Execute, and Decode stages. It introduces speculation strategies allowing successor operations to begin before predecessor decoding completes, and reports that this reduces total pipeline steps by 20-40% versus a no-speculation baseline on common benchmarks. The most aggressive speculation strategy is claimed to outperform others because the per-rollback penalty remains small relative to parallelism gains, while also improving load balancing across classical control, quantum hardware, and decoders.
Significance. If the performance claims hold under a well-specified error model and benchmark set, the work would be significant for practical FTQC control systems: it directly targets idle time in the three heterogeneous subsystems and converts it into useful work via speculation and load balancing. The approach is a concrete scheduling improvement rather than an asymptotic asymptotic result, with potential to reduce execution time on near-term fault-tolerant hardware.
major comments (2)
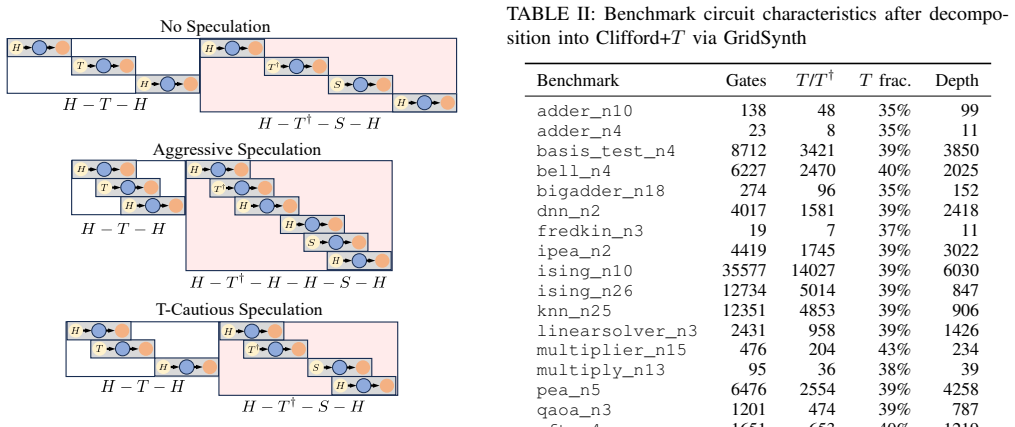
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim of a 20-40% reduction in pipeline steps is presented without any description of the benchmarks used, the underlying error model, how the three-stage pipeline and speculation are implemented in simulation, or the quantitative measurement of rollback costs; this leaves the performance result unsupported by visible evidence and is load-bearing for the paper's main contribution.
- [Speculation strategies] Speculation strategies discussion: the assertion that 'the per-rollback penalty is small relative to the parallelism gained' is stated without a sensitivity analysis on decoder latency, error rates, or circuit depth; if rollback cost scales with these parameters the reported advantage can reverse, yet no such test or timing model breakdown is supplied.
minor comments (2)
- [Title] The title uses the neologism 'Spequlation'; a brief clarification of the intended pun would aid readers.
- [Framework description] Notation for the three stages (Control, Execute, Decode) is introduced but not consistently cross-referenced to any timing diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The two major points highlight areas where the manuscript requires additional detail to support its claims. We address each below and commit to revisions that will strengthen the evaluation and analysis sections without altering the core contribution.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim of a 20-40% reduction in pipeline steps is presented without any description of the benchmarks used, the underlying error model, how the three-stage pipeline and speculation are implemented in simulation, or the quantitative measurement of rollback costs; this leaves the performance result unsupported by visible evidence and is load-bearing for the paper's main contribution.
Authors: We agree that the abstract and Evaluation section lack the necessary supporting details. The manuscript text references 'several common benchmarks' and reports the 20-40% reduction but does not enumerate the specific circuits, specify the error model (e.g., noise rates or code family), describe the simulation implementation of the Control-Execute-Decode stages and speculation logic, or quantify rollback overheads. In the revised version we will expand the Evaluation section with: (1) explicit list of benchmarks and their sizes, (2) the error model and decoder assumptions, (3) pseudocode or timing diagrams for the pipeline and speculation mechanisms, and (4) measured rollback costs. This will make the performance claims traceable to concrete evidence. revision: yes
-
Referee: [Speculation strategies] Speculation strategies discussion: the assertion that 'the per-rollback penalty is small relative to the parallelism gained' is stated without a sensitivity analysis on decoder latency, error rates, or circuit depth; if rollback cost scales with these parameters the reported advantage can reverse, yet no such test or timing model breakdown is supplied.
Authors: We concur that the claim lacks supporting sensitivity analysis. The current text asserts the advantage of aggressive speculation on the basis of the reported benchmarks but provides no sweeps over decoder latency, physical error rate, or circuit depth, nor a breakdown of the timing model. The revised manuscript will add a dedicated sensitivity study (new figure or subsection) that varies these parameters, reports the resulting pipeline-step savings, and identifies the regime in which the per-rollback penalty remains small relative to parallelism gains. Where the advantage reverses, we will note the boundary conditions explicitly. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a pipelined execution framework for fault-tolerant quantum computation and evaluates it empirically on common benchmarks, reporting 20-40% reductions in pipeline steps with speculation strategies. No mathematical derivations, equations, fitted parameters, or self-citation chains are described that reduce any claimed result to the paper's own inputs by construction. The central claims rest on stated evaluation outcomes rather than quantities defined in terms of the framework's own definitions, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in fault-tolerant quantum computation regarding error rates, decoding latency, and subsystem coordination
invented entities (1)
-
Speculation strategies for overlapping quantum logical operations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Assessing requirements to scale to practical quantum advantage,
M. E. Beverland, P. Murali, M. Troyer, K. M. Svore, T. Hoefler, V . Kliuchnikov, G. H. Low, M. Soeken, A. Sundaram, and A. Vaschillo, “Assessing requirements to scale to practical quantum advantage,”arXiv preprint arXiv:2211.07629, 2022
Pith/arXiv arXiv 2022
-
[2]
Universal quantum computation with ideal clifford gates and noisy ancillas,
S. Bravyi and A. Kitaev, “Universal quantum computation with ideal clifford gates and noisy ancillas,”Physical Review A, vol. 71, no. 2, Feb. 2005. [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.71. 022316
-
[3]
Applied Physics Reviews6(2), 021314 (2019) https://doi.org/10.1063/1.5088164
C. D. Bruzewicz, J. Chiaverini, R. McConnell, and J. M. Sage, “Trapped-ion quantum computing: Progress and challenges,”Applied Physics Reviews, vol. 6, no. 2, May 2019. [Online]. Available: http://dx.doi.org/10.1063/1.5088164
-
[4]
One-time compilation of device- level instructions for quantum subroutines,
A. S. Dalvi, J. Whitlow, M. D’Onofrio, L. Riesebos, T. Chen, S. Phiri, K. R. Brown, and J. M. Baker, “One-time compilation of device- level instructions for quantum subroutines,” in2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2024, pp. 873–884
2024
-
[5]
Low overhead quantum computation using lattice surgery,
A. G. Fowler and C. Gidney, “Low overhead quantum computation using lattice surgery,” 2019. [Online]. Available: https://arxiv.org/abs/ 1808.06709
arXiv 2019
-
[6]
Surface codes: Towards practical large-scale quantum computation,
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, “Surface codes: Towards practical large-scale quantum computation,” Physical Review A, vol. 86, no. 3, Sep. 2012. [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.86.032324
-
[7]
Surface code quantum computing by lattice surgery,
D. Horsman, A. G. Fowler, S. Devitt, and R. Van Meter, “Surface code quantum computing by lattice surgery,”New Journal of Physics, vol. 14, no. 12, p. 123011, 2012
2012
-
[8]
P. Krantz, M. Kjaergaard, F. Yan, T. P. Orlando, S. Gustavsson, and W. D. Oliver, “A quantum engineer’s guide to superconducting qubits,” Applied Physics Reviews, vol. 6, no. 2, Jun. 2019. [Online]. Available: http://dx.doi.org/10.1063/1.5089550
-
[9]
Qasmbench: A low-level qasm benchmark suite for nisq evaluation and simulation,
A. Li, S. Stein, S. Krishnamoorthy, and J. Ang, “Qasmbench: A low-level qasm benchmark suite for nisq evaluation and simulation,”
-
[10]
Available: https://arxiv.org/abs/2005.13018
[Online]. Available: https://arxiv.org/abs/2005.13018
arXiv 2005
-
[11]
A game of surface codes: Large-scale quan- tum computing with lattice surgery,
D. Litinski, “A game of surface codes: Large-scale quantum computing with lattice surgery,”Quantum, vol. 3, p. 128, Mar. 2019. [Online]. Available: http://dx.doi.org/10.22331/q-2019-03-05-128
-
[12]
Magic State Distillation: Not as Costly as You Think , volume=
——, “Magic state distillation: Not as costly as you think,” Quantum, vol. 3, p. 205, Dec. 2019. [Online]. Available: http: //dx.doi.org/10.22331/q-2019-12-02-205
-
[13]
FPGA-Based Distributed Union-Find Decoder for Surface Codes,
N. Liyanage, Y . Wu, S. Tagare, and L. Zhong, “Fpga-based distributed union-find decoder for surface codes,”IEEE Transactions on Quantum Engineering, vol. 5, p. 1–18, 2024. [Online]. Available: http://dx.doi.org/10.1109/TQE.2024.3467271
-
[14]
Better than worst-case decoding for quantum error correction,
G. S. Ravi, J. M. Baker, A. Fayyazi, S. F. Lin, A. Javadi- Abhari, M. Pedram, and F. T. Chong, “Better than worst-case decoding for quantum error correction,” 2022. [Online]. Available: https://arxiv.org/abs/2208.08547
arXiv 2022
-
[15]
Optimal ancilla-free clifford+t approximation of z-rotations,
N. J. Ross and P. Selinger, “Optimal ancilla-free clifford+t approximation of z-rotations,” 2016. [Online]. Available: https://arxiv.org/abs/1403.2975
Pith/arXiv arXiv 2016
-
[16]
Rescq: Realtime scheduling for continuous angle quantum error correction architectures,
S. Sethi and J. M. Baker, “Rescq: Realtime scheduling for continuous angle quantum error correction architectures,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’25. ACM, Mar. 2025, p. 1028–1043. [Online]. Available: http://dx.doi.org/10.1145/3676641.3716018
-
[17]
Parallel window decoding enables scalable fault tolerant quantum computation,
L. Skoric, D. E. Browne, K. M. Barnes, N. I. Gillespie, and E. T. Campbell, “Parallel window decoding enables scalable fault tolerant quantum computation,”Nature Communications, vol. 14, no. 1, Nov
-
[18]
Available: http://dx.doi.org/10.1038/s41467-023-42482- 1
[Online]. Available: http://dx.doi.org/10.1038/s41467-023-42482- 1
-
[19]
Photonic quantum information processing: A concise review,
S. Slussarenko and G. J. Pryde, “Photonic quantum information processing: A concise review,”Applied Physics Reviews, vol. 6, no. 4, Oct. 2019. [Online]. Available: http://dx.doi.org/10.1063/1.5115814
-
[20]
Quantum error correction for quantum memories,
B. M. Terhal, “Quantum error correction for quantum memories,” Reviews of Modern Physics, vol. 87, no. 2, pp. 307–346, 2015
2015
-
[21]
Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,
J. Viszlai, J. D. Chadwick, S. Joshi, G. S. Ravi, Y . Li, and F. T. Chong, “Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1386–1401. [Online]. Avai...
-
[22]
Optimizing ftqc programs through qec transpiler and architecture codesign,
M. Wang, C. Liu, S. Stein, Y . Ding, P. Das, P. J. Nair, and A. Li, “Optimizing ftqc programs through qec transpiler and architecture codesign,”arXiv preprint arXiv:2412.15434, 2024
Pith/arXiv arXiv 2024
-
[23]
Fusion blossom: Fast mwpm decoders for qec,
Y . Wu and L. Zhong, “Fusion blossom: Fast mwpm decoders for qec,”
-
[24]
Available: https://arxiv.org/abs/2305.08307
[Online]. Available: https://arxiv.org/abs/2305.08307
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.