Comparing Linear Probes with Mahalanobis Cosine Similarity
Pith reviewed 2026-06-26 20:37 UTC · model grok-4.3
The pith
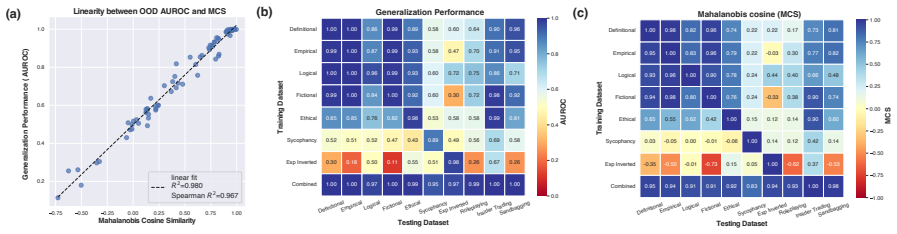
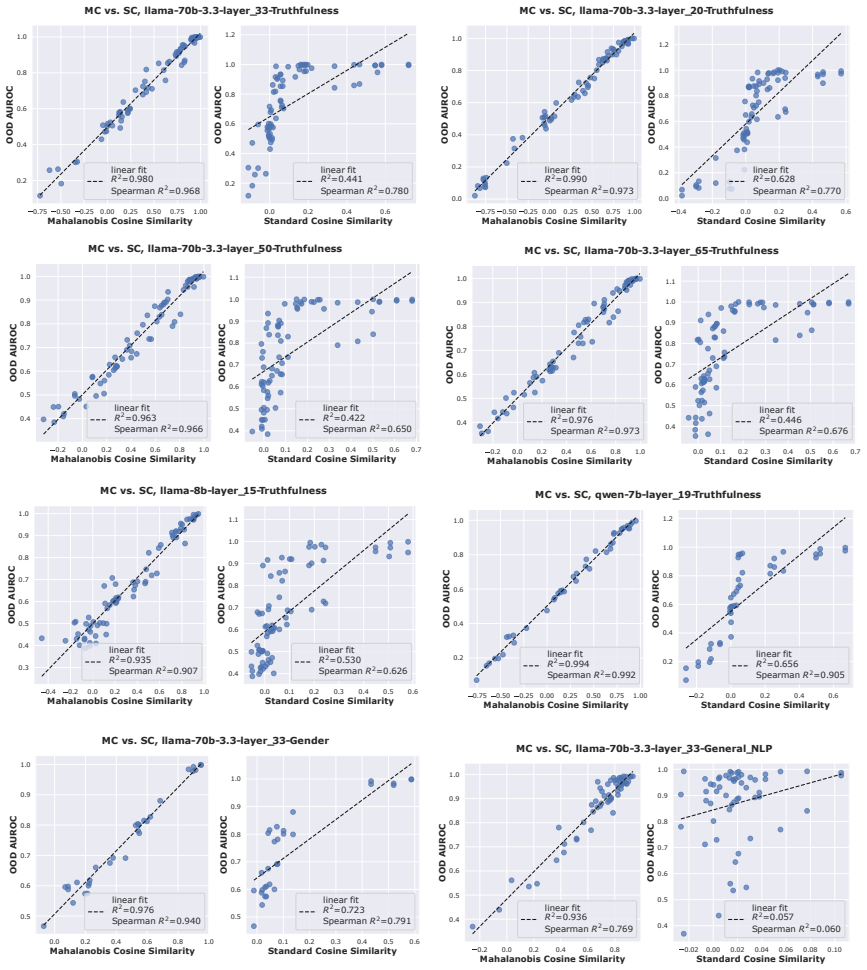
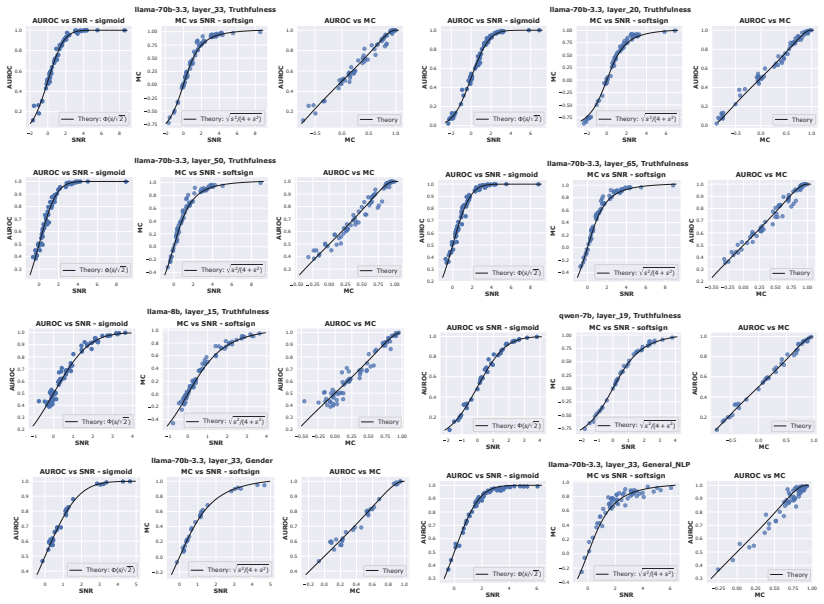
For balanced Gaussian class projections, Mahalanobis cosine similarity to a reference probe is linearly related to a linear probe's OOD AUROC because both are sigmoid functions of the same signal-to-noise ratio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
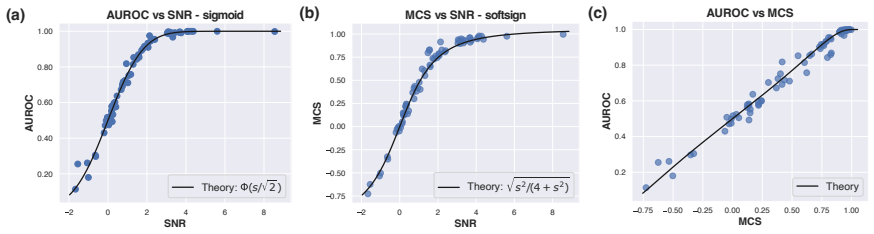
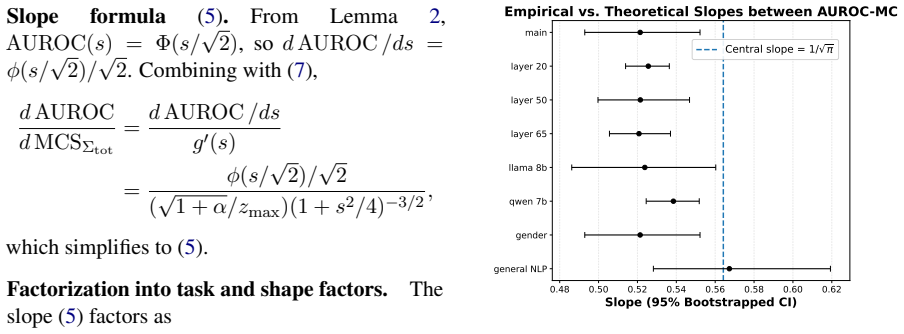
For balanced classes whose projections are Gaussian, OOD AUROC and MCS to the reference probe are linear because both are sigmoid-shaped functions of the probe's signal-to-noise ratio (SNR) on the test data.
What carries the argument
Mahalanobis cosine similarity, which reweights the inner product of two probe directions by the inverse of the test-data covariance matrix.
If this is right
- MCS supplies a theoretically justified replacement for Euclidean cosine when ranking linear probes by expected OOD performance.
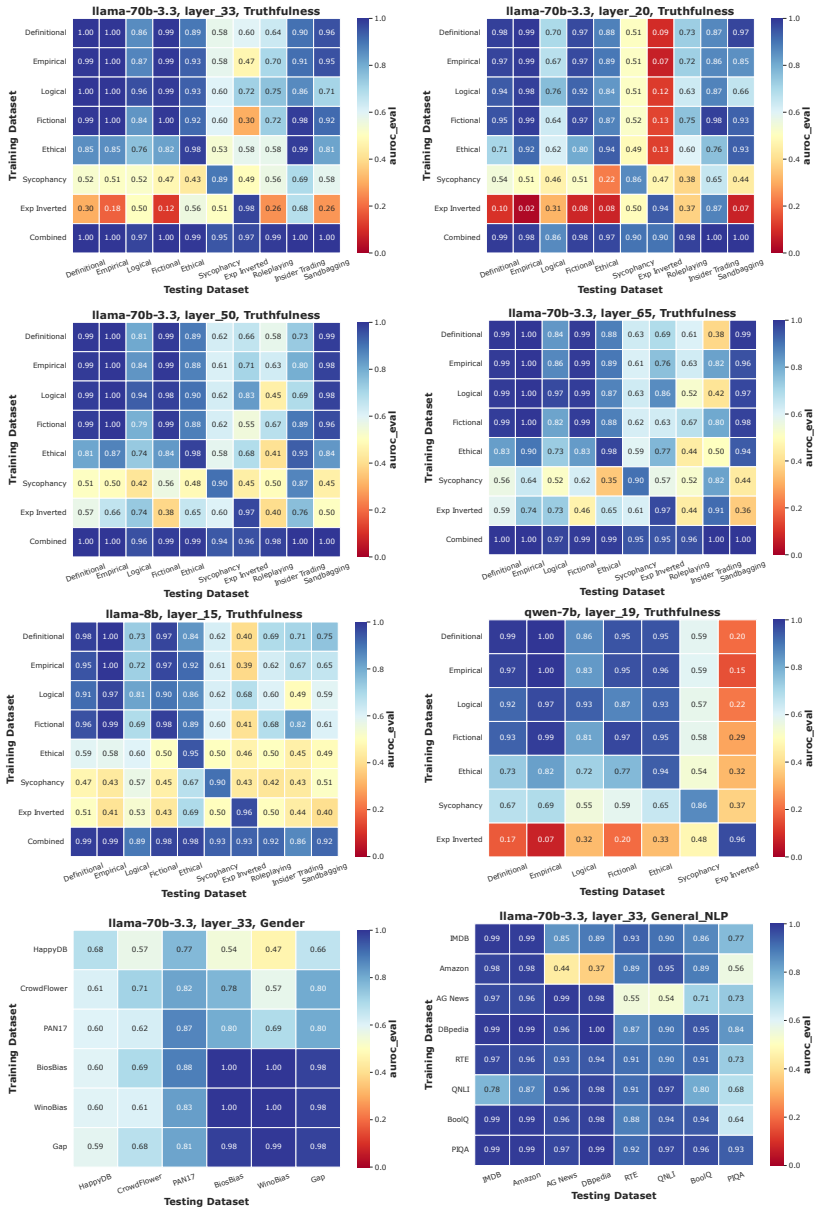
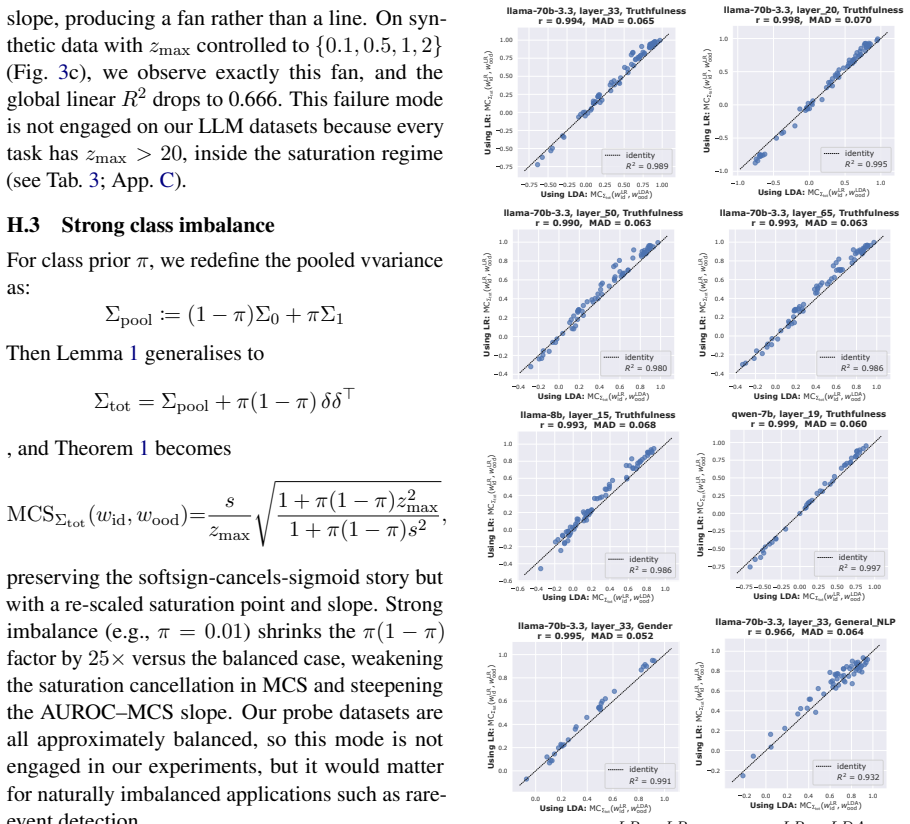
- The linear relation holds across models, layers, and concept domains as long as the Gaussian and balance conditions are met.
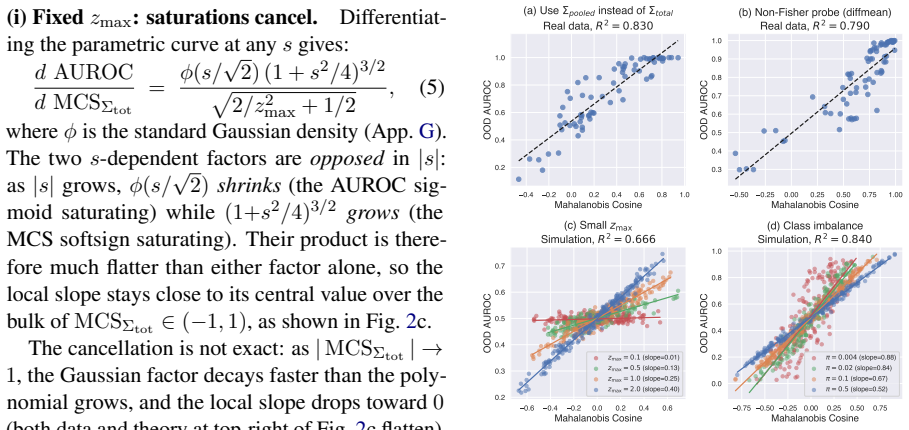
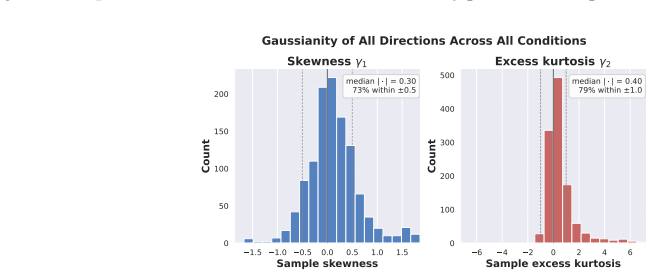
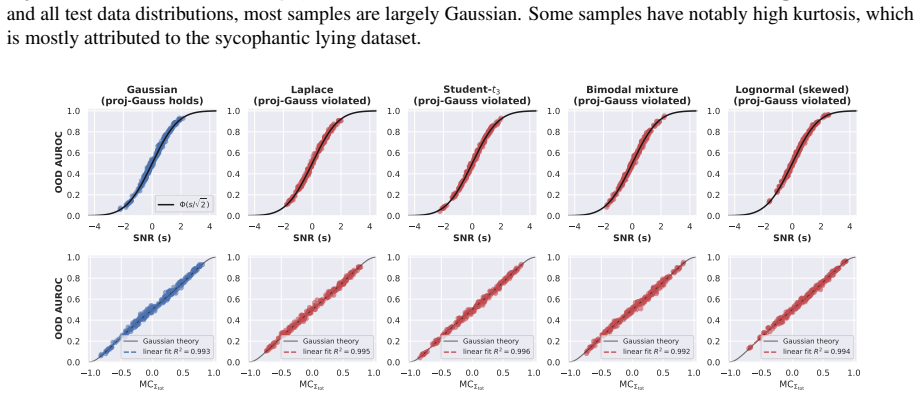
- Linearity fails exactly when the Gaussian or balance assumptions are violated, which can be checked by inspecting projection histograms or class counts.
- The SNR itself becomes the single sufficient statistic that governs both probe quality and inter-probe similarity under the stated model.
Where Pith is reading between the lines
- MCS could be computed on a small held-out set to rank many candidate probes without running full OOD AUROC evaluations on each.
- The result suggests that covariance-adjusted similarities may improve other comparison tasks that currently rely on Euclidean inner products in high-dimensional spaces.
- A direct test would apply the same SNR derivation to non-linear probes or to multi-class settings to see whether analogous closed-form relations appear.
- The theory offers a way to predict, before training, how much a change in probe direction will move its OOD performance.
Load-bearing premise
The projections of the data onto the probe directions are Gaussian distributed and the two classes are balanced in size.
What would settle it
An experiment on data whose projections onto the probe directions are visibly non-Gaussian or whose class sizes are markedly unequal, showing that the linear correlation between MCS and OOD AUROC drops substantially.
Figures
read the original abstract
Linear probes are widely used in interpretability research and often compared by cosine similarity. The Mahalanobis cosine similarity (MCS) between two directions, which reweights the inner product by test data covariance, is a natural task-aware refinement. Ying et al. (2026) report that a probe's MCS to a reference probe trained on the out-of-distribution (OOD) data near-perfectly linearly predicts the probe's OOD AUROC (R^2 = 0.98). Here, we extend this empirical finding across models, layers, and concept domains, and prove this general phenomenon in closed form: For balanced classes whose projections are Gaussian, OOD AUROC and MCS to the reference probe are linear because both are sigmoid-shaped functions of the probe's signal-to-noise ratio (SNR) on the test data. The theory also predicts when this linearity fails, which we verify empirically. MCS offers a theoretically grounded and empirically effective alternative to Euclidean cosine similarity for comparing linear probes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for balanced classes with Gaussian projections onto probe directions, OOD AUROC and Mahalanobis cosine similarity (MCS) to a reference probe are linearly related because both quantities are sigmoid-shaped functions of the probe's signal-to-noise ratio (SNR) on the test data. It extends the empirical observation from Ying et al. (2026) of near-perfect linearity (R²=0.98) across models, layers, and concept domains, supplies a closed-form derivation under the stated assumptions, identifies regimes where linearity is predicted to break, and verifies those predictions empirically. MCS is positioned as a theoretically grounded alternative to Euclidean cosine similarity for comparing linear probes.
Significance. If the result holds, the work supplies a mechanistic, parameter-free explanation for the high observed correlation between MCS and OOD performance, thereby strengthening the case for task-aware similarity measures in interpretability research. The explicit closed-form derivation, the absence of fitted parameters or invented entities, and the empirical verification of predicted failure regimes are concrete strengths that make the central claim falsifiable and reproducible.
major comments (1)
- [Theoretical derivation (likely §3 or §4)] The central claim rests on the closed-form demonstration that both AUROC and MCS reduce to sigmoid functions of the same SNR quantity under Gaussian projections and class balance. The manuscript states this derivation explicitly, but the algebraic steps connecting the Gaussian assumption to the sigmoid form should be presented with equation numbers so that readers can verify the reduction without ambiguity.
minor comments (2)
- [References] The abstract and introduction cite Ying et al. (2026) for the original R²=0.98 result; the reference list should contain the full bibliographic entry.
- [Discussion or Limitations] While the paper states the assumptions of balanced classes and Gaussian projections, a short paragraph discussing the robustness of the linearity result to modest violations of these assumptions (beyond the already-reported empirical checks) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Theoretical derivation (likely §3 or §4)] The central claim rests on the closed-form demonstration that both AUROC and MCS reduce to sigmoid functions of the same SNR quantity under Gaussian projections and class balance. The manuscript states this derivation explicitly, but the algebraic steps connecting the Gaussian assumption to the sigmoid form should be presented with equation numbers so that readers can verify the reduction without ambiguity.
Authors: We agree that numbering the equations will improve verifiability. In the revised manuscript we will assign equation numbers to each algebraic step in the derivation that reduces the Gaussian class-conditional projections and class balance to the sigmoid forms of AUROC and MCS as functions of SNR. revision: yes
Circularity Check
No significant circularity; derivation is self-contained mathematical identity
full rationale
The paper states that under the explicit assumptions of balanced classes and Gaussian projections, both OOD AUROC and MCS are sigmoid functions of the same SNR quantity on test data, which algebraically implies their linear relationship. This is presented as a closed-form derivation with stated regimes of validity, without any fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the central claim to unverified inputs. The prior empirical report (Ying et al. 2026) is cited only as motivation; the linearity proof stands independently on the SNR dependence. No steps reduce by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Projections of the data onto the probe directions are Gaussian distributed
- domain assumption The two classes are balanced
Reference graph
Works this paper leans on
-
[1]
First Conference on Language Modeling , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. First Conference on Language Modeling , year=
-
[2]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
The Internal State of an LLM Knows When It’s Lying , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[3]
2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024) , pages=
On the Universal Truthfulness Hyperplane Inside LLMs , author=. 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024) , pages=. 2024 , organization=
2024
-
[4]
The Neuroscientist , volume=
How the brain shapes deception: An integrated review of the literature , author=. The Neuroscientist , volume=. 2011 , publisher=
2011
-
[5]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[6]
Forty-second International Conference on Machine Learning , year=
Detecting strategic deception with linear probes , author=. Forty-second International Conference on Machine Learning , year=
-
[7]
arXiv preprint arXiv:2507.12691 , year=
Benchmarking deception probes via black-to-white performance boosts , author=. arXiv preprint arXiv:2507.12691 , year=
-
[8]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
The Curious Case of Hallucinatory (Un) answerability: Finding Truths in the Hidden States of Over-Confident Large Language Models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[9]
The Eleventh International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. The Eleventh International Conference on Learning Representations , year=
-
[10]
ICLR 2024 Workshop on Large Language Model (LLM) Agents , year=
Large Language Models can Strategically Deceive their Users when Put Under Pressure , author=. ICLR 2024 Workshop on Large Language Model (LLM) Agents , year=
2024
-
[11]
arXiv preprint arXiv:2410.21514 , year=
Sabotage evaluations for frontier models , author=. arXiv preprint arXiv:2410.21514 , year=
-
[12]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[15]
Findings of the association for computational linguistics: ACL 2023 , pages=
Discovering language model behaviors with model-written evaluations , author=. Findings of the association for computational linguistics: ACL 2023 , pages=
2023
-
[16]
arXiv preprint arXiv:2509.21305 , year=
Sycophancy Is Not One Thing: Causal Separation of Sycophantic Behaviors in LLMs , author=. arXiv preprint arXiv:2509.21305 , year=
-
[17]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[18]
The Twelfth International Conference on Learning Representations , year=
Towards Understanding Sycophancy in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the National Academy of Sciences , volume=
Deception abilities emerged in large language models , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[21]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
International conference on machine learning , pages=
Do the rewards justify the means? measuring trade-offs between rewards and ethical behavior in the machiavelli benchmark , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[23]
CoRR , year=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. CoRR , year=
-
[24]
Steering Language Models With Activation Engineering
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2510.14318 , year =
Marwa Abdulhai and Ryan Cheng and Aryansh Shrivastava and Natasha Jaques and Yarin Gal and Sergey Levine , title =. arXiv preprint arXiv:2510.14318 , year =
-
[26]
Advances in Neural Information Processing Systems , volume=
Truth is universal: Robust detection of lies in llms , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
2025 , eprint=
Preference Learning with Lie Detectors can Induce Honesty or Evasion , author=. 2025 , eprint=
2025
-
[29]
Cerebral cortex , volume=
Neural correlates of different types of deception: an fMRI investigation , author=. Cerebral cortex , volume=. 2003 , publisher=
2003
-
[30]
arXiv preprint arXiv:2511.16035 , year=
Liars' Bench: Evaluating Lie Detectors for Language Models , author=. arXiv preprint arXiv:2511.16035 , year=
-
[31]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[32]
Simple synthetic data reduces sycophancy in large language models
Simple synthetic data reduces sycophancy in large language models , author=. arXiv preprint arXiv:2308.03958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
CoRR , year=
The MASK Benchmark: Disentangling Honesty From Accuracy in AI Systems , author=. CoRR , year=
-
[34]
International Conference on Machine Learning , pages=
Linear Adversarial Concept Erasure , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[35]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[36]
Advances in Neural Information Processing Systems , volume=
Leace: Perfect linear concept erasure in closed form , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
ICLR , year=
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , author=. ICLR , year=
-
[38]
Philosophical Studies , year=
Still no lie detector for language models: probing empirical and conceptual roadblocks , author=. Philosophical Studies , year=
-
[39]
ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
The Geometries of Truth Are Orthogonal Across Tasks , author=. ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
2025
-
[40]
International Conference on Learning Representations , year=
Aligning AI With Shared Human Values , author=. International Conference on Learning Representations , year=
-
[41]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Emergence of Linear Truth Encodings in Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[42]
Proceedings of the 41st International Conference on Machine Learning , pages=
Representation surgery: theory and practice of affine steering , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2509.07968 , year=
Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge , author=. arXiv preprint arXiv:2509.07968 , year=
-
[45]
Proceedings of the ACM on Web Conference 2025 , pages=
Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[46]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[47]
The Thirteenth International Conference on Learning Representations , year=
NNsight and NDIF: Democratizing Access to Open-Weight Foundation Model Internals , author=. The Thirteenth International Conference on Learning Representations , year=
-
[48]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Do androids know they’re only dreaming of electric sheep? , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[49]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
When Truthful Representations Flip Under Deceptive Instructions? , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[50]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Steering llama 2 via contrastive activation addition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
arXiv preprint arXiv:2506.00823 , year=
Probing the Geometry of Truth: Consistency and Generalization of Truth Directions in LLMs Across Logical Transformations and Question Answering Tasks , author=. arXiv preprint arXiv:2506.00823 , year=
-
[52]
arXiv preprint arXiv:2509.23024 , year=
Tracing the representation geometry of language models from pretraining to post-training , author=. arXiv preprint arXiv:2509.23024 , year=
-
[53]
Transactions of the association for computational linguistics , volume=
A primer in BERTology: What we know about how BERT works , author=. Transactions of the association for computational linguistics , volume=
-
[54]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[55]
Language models as knowledge bases? , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[56]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[57]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[58]
Advances in Neural Information Processing Systems , volume=
The geometry of hidden representations of large transformer models , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Neurons, Behavior, Data analysis, and Theory , volume=
Comparing representational geometries using whitened unbiased-distance-matrix similarity , author=. Neurons, Behavior, Data analysis, and Theory , volume=. 2021 , publisher=
2021
-
[60]
International conference on machine learning , pages=
Leep: A new measure to evaluate transferability of learned representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[61]
International conference on machine learning , pages=
Logme: Practical assessment of pre-trained models for transfer learning , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[62]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Second Conference on Language Modeling , year=
How Post-Training Reshapes LLMs: A Mechanistic View on Knowledge, Truthfulness, Refusal, and Confidence , author=. Second Conference on Language Modeling , year=
-
[64]
the Journal of machine Learning research , volume=
Scikit-learn: Machine learning in Python , author=. the Journal of machine Learning research , volume=. 2011 , publisher=
2011
-
[65]
arXiv preprint arXiv:2310.18512 , year=
Preventing language models from hiding their reasoning , author=. arXiv preprint arXiv:2310.18512 , year=
-
[66]
arXiv preprint arXiv:2602.20273 , year=
The Truthfulness Spectrum Hypothesis , author=. arXiv preprint arXiv:2602.20273 , year=
-
[67]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
2004 , publisher=
Discriminant analysis and statistical pattern recognition , author=. 2004 , publisher=
2004
-
[69]
International Conference on Computer Vision Systems , pages=
The CSU face identification evaluation system: its purpose, features, and structure , author=. International Conference on Computer Vision Systems , pages=. 2003 , organization=
2003
-
[70]
Annals of eugenics , volume=
The use of multiple measurements in taxonomic problems , author=. Annals of eugenics , volume=. 1936 , publisher=
1936
-
[71]
1966 , publisher=
Signal detection theory and psychophysics , author=. 1966 , publisher=
1966
-
[72]
, author=
The meaning and use of the area under a receiver operating characteristic (ROC) curve. , author=. Radiology , volume=
-
[73]
2018 , publisher=
Introduction to multivariate analysis , author=. 2018 , publisher=
2018
-
[74]
2009 , publisher=
The elements of statistical learning: data mining, inference, and prediction , author=. 2009 , publisher=
2009
-
[75]
Designing and interpreting probes with control tasks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (emnlp-ijcnlp) , pages=
2019
-
[76]
Metabolites , volume=
Extraction and integration of genetic networks from short-profile omic data sets , author=. Metabolites , volume=. 2020 , publisher=
2020
-
[77]
2019 IEEE international conference on image processing (ICIP) , pages=
An information-theoretic approach to transferability in task transfer learning , author=. 2019 IEEE international conference on image processing (ICIP) , pages=. 2019 , organization=
2019
-
[78]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Transferability estimation using bhattacharyya class separability , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
How far pre-trained models are from neural collapse on the target dataset informs their transferability , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[80]
Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies , pages=
Learning word vectors for sentiment analysis , author=. Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.