MiqraBERT: Regression-Based Sentence-BERT Finetuning for Biblical Hebrew Parallel Detection
Pith reviewed 2026-06-26 20:28 UTC · model grok-4.3
The pith
By regressing cosine similarity on 1650 labeled verse pairs, MiqraBERT learns an embedding space that clusters true biblical parallels and separates unrelated verses 2.7 times more effectively than the baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
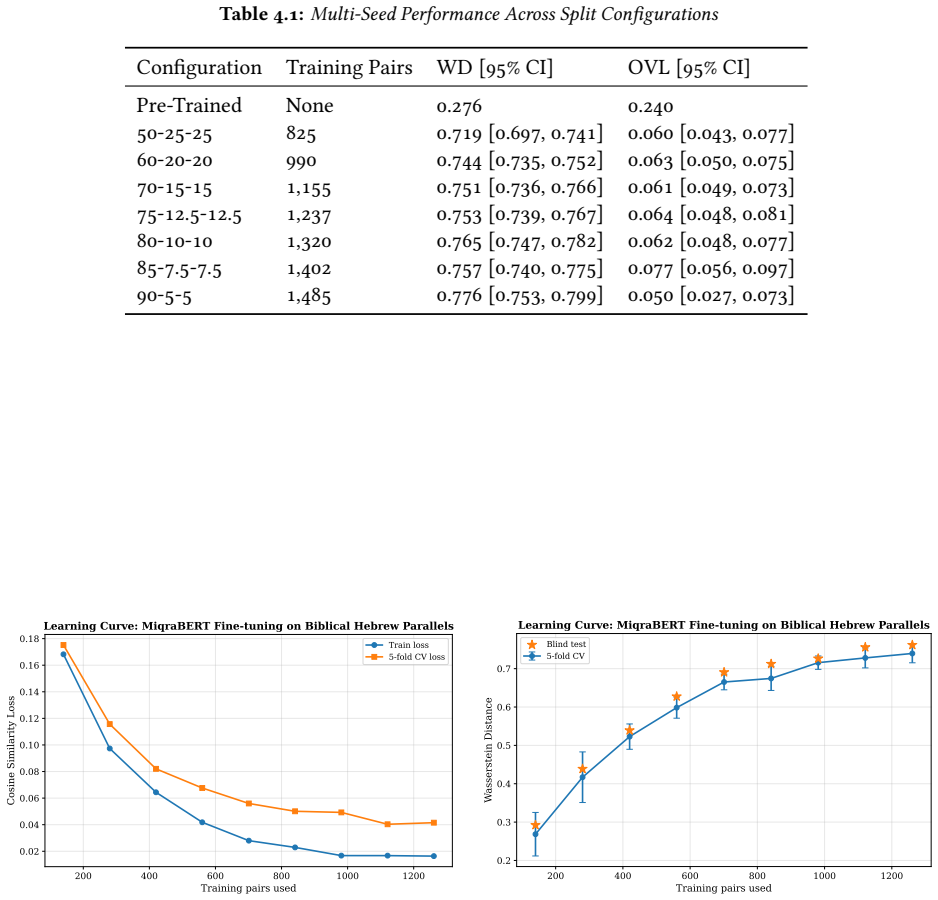
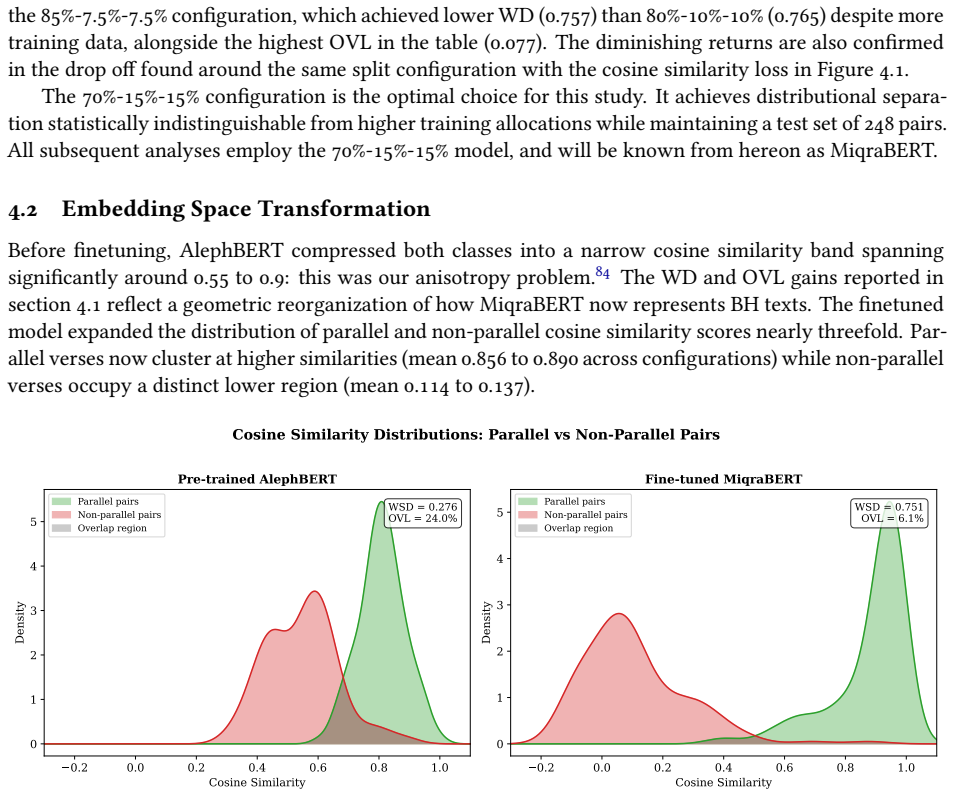
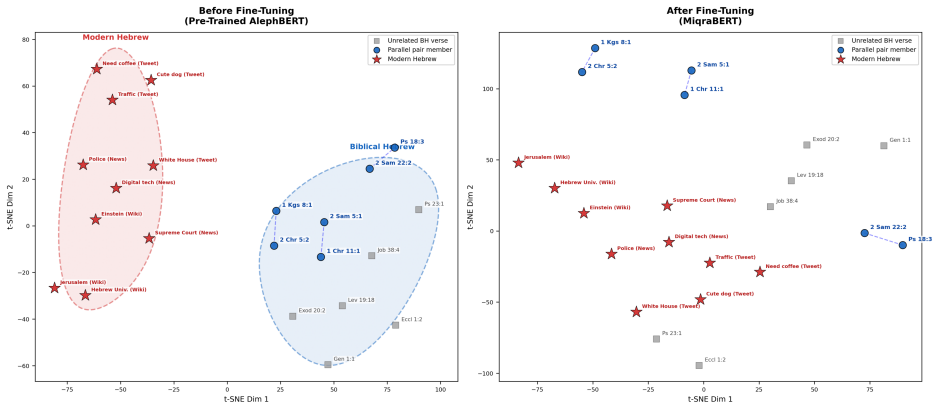
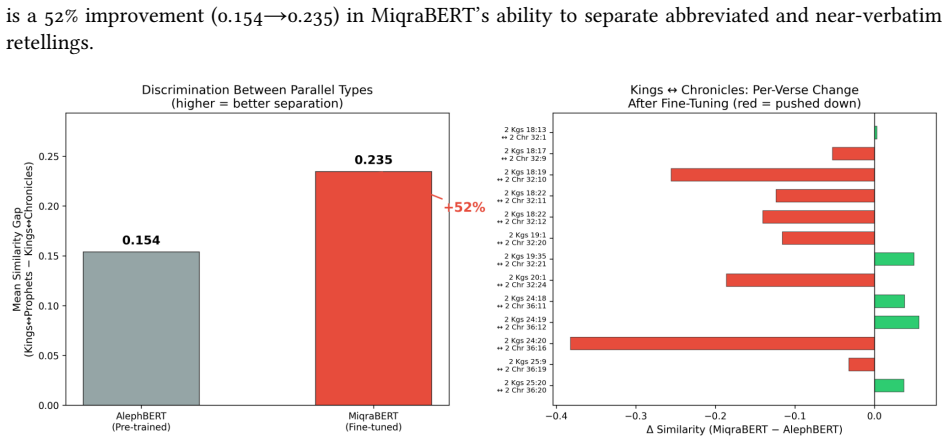
MiqraBERT is a Sentence-BERT model finetuned from AlephBERT using regression on 1,650 labeled verse and half-verse pairs. It improves distributional separation 2.7-fold over the pre-trained baseline and reduces the ambiguous overlap region from roughly 24% to about 6%. Narrative synoptic parallels reach a recall@10 of 87.1%; poetic parallels remain difficult, below 9%. This genre-dependent asymmetry confines the model's reliable scope to narrative textual reuse.
What carries the argument
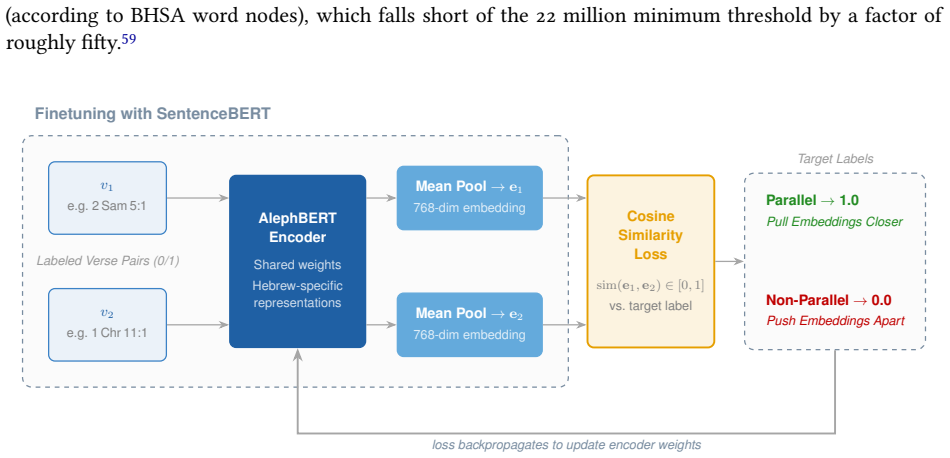
Cosine-similarity regression finetuning of a pre-trained Modern Hebrew encoder on labeled parallel and non-parallel verse pairs.
If this is right
- Distributional separation of parallel and non-parallel pairs improves 2.7-fold.
- The ambiguous overlap region between score distributions shrinks from 24% to 6%.
- Narrative synoptic parallels achieve 87.1% recall at rank 10.
- Poetic parallels stay below 9% recall at rank 10.
- Reliable performance is confined to narrative textual reuse.
Where Pith is reading between the lines
- The same regression approach could be tested on reuse detection in other ancient Semitic corpora such as Ugaritic or Aramaic texts.
- The persistent difficulty with poetry suggests that adding syntactic or metrical features might close the genre gap.
- Public availability of the model enables direct integration into existing digital tools for tracing textual connections in the Hebrew Bible.
Load-bearing premise
The 825 true parallels from Chronicles and poetic studies plus 825 random negatives form a representative training distribution that generalizes to detecting textual reuse across the Hebrew Bible.
What would settle it
Evaluating recall@10 and overlap coefficient on a fresh set of scholar-identified parallels drawn from books outside the Chronicles synoptic material and not used in training.
Figures

read the original abstract
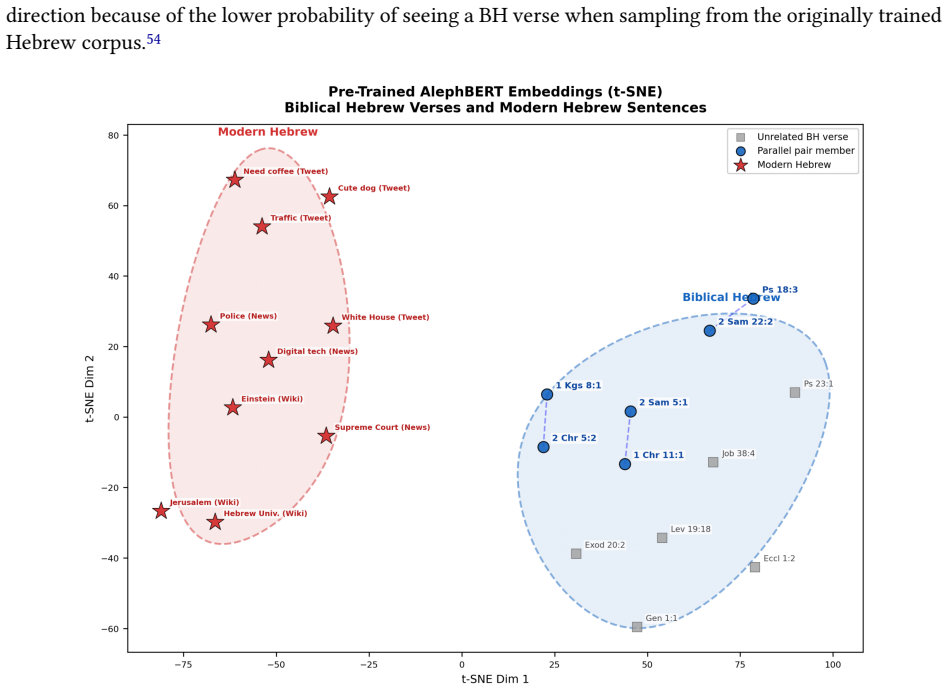
Textual reuse pervades the Hebrew Bible, yet the computational methods used to detect it still rest largely on lexical overlap, and they falter once a parallel involves paraphrase, lexical substitution, or syntactic reworking. This paper introduces MiqraBERT, a Sentence-BERT model finetuned from AlephBERT (a Modern Hebrew encoder) for verse-level semantic similarity in Biblical Hebrew. The training set comprises 1,650 labeled verse and half-verse pairs: 825 true parallels drawn from the Chronicles synoptic material and from foundational studies of poetic parallelism, balanced against 825 randomly sampled negatives. Through cosine-similarity regression, the model learns an embedding space in which parallel verses cluster together and unrelated verses move apart. We evaluate separation with distribution-based metrics, Wasserstein distance and the overlap coefficient, across ten random seeds. MiqraBERT improves distributional separation 2.7-fold over the pre-trained baseline and reduces the ambiguous overlap region from roughly 24% to about 6%. Narrative synoptic parallels reach a recall@10 of 87.1%; poetic parallels remain difficult, below 9%. This genre-dependent asymmetry confines the model's reliable scope to narrative textual reuse. MiqraBERT is publicly available at https://huggingface.co/davidmsmiley/MiqraBERT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MiqraBERT, a Sentence-BERT model fine-tuned from AlephBERT on 1,650 labeled verse pairs (825 positives from Chronicles synoptics and poetic parallelism studies, balanced with 825 random negatives) via cosine-similarity regression. It reports a 2.7-fold improvement in distributional separation (Wasserstein distance and overlap coefficient) over the pre-trained baseline across ten random seeds, reducing ambiguous overlap from ~24% to ~6%, with narrative synoptic recall@10 at 87.1% but poetic recall below 9%, and releases the model publicly.
Significance. If the reported separation gains and narrative recall generalize beyond the training sources, the work would supply a useful open tool for computational detection of semantic textual reuse in Biblical Hebrew, extending beyond lexical methods. The public Hugging Face release and the use of ten random seeds for variance control are explicit strengths supporting reproducibility.
major comments (2)
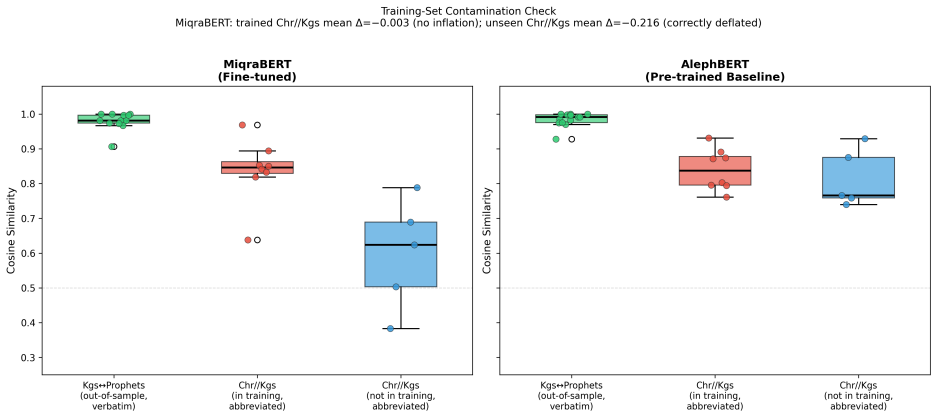
- [Abstract and §3] Abstract and §3 (Data Construction): the 825 positive pairs are drawn exclusively from already-identified parallels in the Chronicles synoptic material and specific poetic studies; because the reported 87.1% narrative recall@10 is also evaluated on narrative synoptic parallels, the evaluation does not establish that the model has learned general semantic reuse rather than source-specific patterns.
- [§4] §4 (Experiments and Evaluation): the negative class is formed by random sampling without reported verification that these pairs contain no undetected parallels or genre stratification; this choice directly affects the Wasserstein distance and overlap-coefficient gains, yet no hold-out set drawn from independent reuse corpora is described to test whether the 2.7-fold separation improvement holds outside the training distribution.
minor comments (2)
- [§2] §2 (Related Work): the comparison to prior lexical-overlap methods for Biblical Hebrew is brief; adding one or two quantitative baselines (e.g., string-edit distance or TF-IDF cosine on the same test pairs) would clarify the practical advantage of the embedding approach.
- [Figure 1 and §4.1] Figure 1 and §4.1: axis labels and legend entries for the cosine-similarity histograms are not fully legible at print size; increasing font size or adding a supplementary table of exact Wasserstein and overlap values per seed would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Data Construction): the 825 positive pairs are drawn exclusively from already-identified parallels in the Chronicles synoptic material and specific poetic studies; because the reported 87.1% narrative recall@10 is also evaluated on narrative synoptic parallels, the evaluation does not establish that the model has learned general semantic reuse rather than source-specific patterns.
Authors: We agree that both the positive training pairs and the narrative recall evaluation draw from the same pool of known synoptic parallels in Chronicles. This means the results demonstrate improved performance on in-distribution examples rather than fully out-of-distribution generalization to arbitrary semantic reuse. The regression objective and the 2.7-fold separation gain over the baseline still indicate that the model learns a more effective embedding space for these parallels than the pre-trained encoder. We will revise the abstract and §3 to state the evaluation scope more precisely and will expand the limitations discussion to note the source-specific character of the current results. revision: partial
-
Referee: [§4] §4 (Experiments and Evaluation): the negative class is formed by random sampling without reported verification that these pairs contain no undetected parallels or genre stratification; this choice directly affects the Wasserstein distance and overlap-coefficient gains, yet no hold-out set drawn from independent reuse corpora is described to test whether the 2.7-fold separation improvement holds outside the training distribution.
Authors: Random negatives were selected because true parallels are sparse; the probability of including an undetected parallel is therefore low, though we did not perform exhaustive verification. The reported metrics are computed on the same test distribution used for training, which explains the observed gains. We do not possess an independent hold-out corpus drawn from other reuse studies, as constructing one would require substantial new expert annotation. We will add an explicit statement in §4 acknowledging the lack of cross-corpus validation and will list this as a direction for future work. revision: partial
Circularity Check
No significant circularity; derivation self-contained
full rationale
Training relies on externally labeled pairs (Chronicles synoptics + poetic studies as positives, random negatives) and standard cosine regression; evaluation uses independent distributional metrics (Wasserstein, overlap coefficient, recall@10) with no reduction of claims to fitted parameters by construction. No self-citations, uniqueness theorems, or ansatzes appear in the provided text. The central claims rest on external data sources and standard fine-tuning, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Training set size and balance
axioms (1)
- domain assumption Cosine similarity regression on verse embeddings captures semantic parallelism
Reference graph
Works this paper leans on
-
[1]
”Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications
Biś, Daniel, Maksim Podkorytov, and Xiuwen Liu. ”Too Much in Common: Shifting of Embeddings in Transformer Language Models and its Implications. ” Pages 5117–30 in Proceedings of the 2021 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Online: Association for Computational Linguistics,
2021
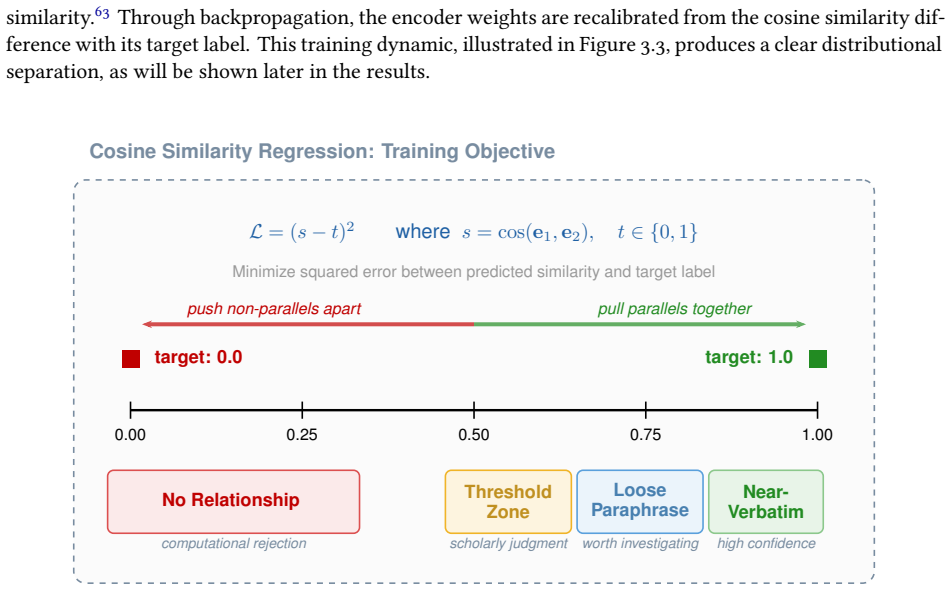
-
[2]
”Intro- ducing Rhetorical Parallelism Detection: A New Task with Datasets, Metrics, and Baselines
Bothwell, Stephen, Justin DeBenedetto, Theresa Crnkovich, Hildegund Muller, and David Chiang. ”Intro- ducing Rhetorical Parallelism Detection: A New Task with Datasets, Metrics, and Baselines. ” Pages 5007–39 in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . Singapore: Association for Computational Linguistics,
2023
-
[3]
”FAST: Fast and Accurate Synoptic Texts
Brill, Oran, Moshe Koppel, and Avi Shmidman. ”FAST: Fast and Accurate Synoptic Texts. ” Digital Scholar- ship in the Humanities 35/2 (2020): 254–264. Burns, Patrick J., James A. Brofos, Kyle Li, Pramit Chaudhuri, and Joseph P. Dexter. ”Profiling of Intertex- tuality in Latin Literature Using Word Embeddings. ” Pages 4900–4907 inProceedings of the 2021 Con...
2020
-
[4]
”Fine- Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping
Dodge, Jesse, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. ”Fine- Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. ” arXiv:2002.06305,
arXiv 2002
-
[5]
”The Biblical Sources of Modern Hebrew Syntax
https://doi.org/10.48550/arXiv.2002.06305 Doron, Edit. ”The Biblical Sources of Modern Hebrew Syntax. ” Pages 222–56 in Language Contact, Conti- nuity and Change in the Genesis of Modern Hebrew . Amsterdam: John Benjamins Publishing Company,
-
[6]
”How Contextual are Contextualized Word Representations? Comparing the Geom- etry of BERT, ELMo, and GPT-2 Embeddings
Ethayarajh, Kawin. ”How Contextual are Contextualized Word Representations? Comparing the Geom- etry of BERT, ELMo, and GPT-2 Embeddings. ” Pages 55–65 in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Associa...
2019
-
[7]
Even-Shoshan, Avraham
https://www.bellingcat.com/news/rest-of-w orld/2019/03/15/shitposting-inspirational-terrorism-and-the-christchurch-m osque-massacre/. Even-Shoshan, Avraham. The New Dictionary [in Hebrew]. Jerusalem: Kirjat Sepher,
2019
-
[8]
An introduction to ROC analysis , journal =
28 Fawcett, Tom. ”An Introduction to ROC Analysis. ”Pattern Recognition Letters 27/8 (2006): 861–74. https: //doi.org/10.1016/j.patrec.2005.10.010 Fokkelman, Joannes Petrus. Reading Biblical Poetry: An Introductory Guide. Translated by Ineke Smit. Louisville, KY: Westminster John Knox Press,
-
[9]
”Embible: Reconstruction of Ancient Hebrew and Aramaic Texts Using Transformers
Fono, Niv, Harel Moshayof, Eldar Karol, Itai Assraf, and Mark Last. ”Embible: Reconstruction of Ancient Hebrew and Aramaic Texts Using Transformers. ” Pages 846–52 in Findings of the Association for Com- putational Linguistics: EACL 2024 . St. Julian’s, Malta: Association for Computational Linguistics,
2024
-
[10]
”SimCSE: Simple Contrastive Learning of Sentence Embed- dings
Gao, Tianyu, Xingcheng Yao, and Danqi Chen. ”SimCSE: Simple Contrastive Learning of Sentence Embed- dings. ” Pages 6894–6910 inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: Association for Computational Linguistics,
2021
-
[11]
[Student]
Gosset, William S. [Student]. ”The Probable Error of a Mean. ” Biometrika 6 (1908): 1–25. HaCohen-Kerner, Yaakov, Hananya Beck, Elchai Yehudai, and Dror Mughaz. ”Identifying Historical Pe- riod and Ethnic Origin of Documents Using Stylistic Feature Sets. ” Pages 102–13 in Discovery Science. Springer Berlin Heidelberg,
1908
-
[12]
”Stylistic Feature Sets As Classifiers of Documents According to Their Historical Period and Ethnic Origin
HaCohen-Kerner, Yaakov, Hananya Beck, Elchai Yehudai, and Dror Mughaz. ”Stylistic Feature Sets As Classifiers of Documents According to Their Historical Period and Ethnic Origin. ” Applied Artificial Intelligence 24/9 (2010): 847–62. HaCohen-Kerner, Yaakov, Nadav Schweitzer, and Dror Mughaz. ”Automatically Identifying Citations in Hebrew-Aramaic Documents...
2010
-
[13]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. ”Scaling Laws for Neural Language Models. ” arXiv:2001.08361,
Pith/arXiv arXiv 2001
-
[14]
Scaling Laws for Neural Language Models
https://doi.org/10.48550/arXiv.2001.08361 Knoppers, Gary N. I Chronicles 10–29: A New Translation with Introduction and Commentary. Anchor Bible 12A. New York: Doubleday,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[15]
”Binary Codes Capable of Correcting Deletions, Insertions, and Reversals
Levenshtein, Vladimir I. ”Binary Codes Capable of Correcting Deletions, Insertions, and Reversals. ” Soviet Physics Doklady 10 (1965): 707–710. 29 Li, Bohan, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. ”On the Sentence Embeddings from Pre-trained Language Models. ” Pages 9119–30 in Proceedings of the 2020 Conference on Empirical Methods ...
1965
-
[16]
Yu, and Lifang He
Li, Qian, Hao Peng, Jianxin Li, Congying Xia, Renyu Yang, Lichao Sun, Philip S. Yu, and Lifang He. ”A Survey on Text Classification: From Traditional to Deep Learning. ” ACM Transactions on Intelligent Systems and Technology 13/2 (2022): 1–41. Liebeskind, Chaya, and Shmuel Liebeskind. ”Deep Learning for Period Classification of Historical Hebrew Texts. ”J...
2022
-
[17]
”Machine Translation for Historical Research: A Case Study of Aramaic-Ancient Hebrew Translations
Liebeskind, Chaya, Shmuel Liebeskind, and Dan Bouhnik. ”Machine Translation for Historical Research: A Case Study of Aramaic-Ancient Hebrew Translations. ” Journal on Computing and Digital Heritage 17/2 (2024): 1–23. Lobbezoo, Bert. ”Computer-Based Recognition of Intertextuality within the Hebrew Bible. ” Master’s Thesis. Delft University of Technology,
2024
-
[18]
”Detecting Narrative Patterns in Biblical Hebrew and Greek
McGovern, Hope, Hale Sirin, Tom Lippincott, and Andrew Caines. ”Detecting Narrative Patterns in Biblical Hebrew and Greek. ” Pages 269–79 in Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024). Association for Computational Linguistics,
2024
-
[19]
”WordNet: A Lexical Database for English
Miller, George A. ”WordNet: A Lexical Database for English. ” Communications of the ACM 38/11 (1995): 39–41. Miller, Hadar, Tsvi Kuflik, and Moshe Lavee. ”Text Alignment in the Service of Text Reuse Detection. ” Applied Sciences 15/6 (2025):
1995
-
[20]
”Counter-fitting Word Vectors to Linguistic Con- straints
Mrkšić, Nikola, Diarmuid Ó Séaghdha, Blaise Thomson, Milica Gašić, Lina Rojas-Barahona, Pei-Hao Su, David Vandyke, Tsung-Hsien Wen, and Steve Young. ”Counter-fitting Word Vectors to Linguistic Con- straints. ” Pages 142–48in Proceedings of the 2016 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language ...
2016
-
[21]
”Parallel Texts in the Hebrew Bible, New Methods and Visualizations
Naaijer, Martijn, and Dirk Roorda. ”Parallel Texts in the Hebrew Bible, New Methods and Visualizations. ” (2016). https://hal.science/hal-01283051v1. Naaijer, Martijn, Constantijn Sikkel, Mathias Coeckelbergs, Jisk Attema, and Willem Van Peursen. ”A Transformer-Based Parser for Syriac Morphology. ” Pages 23–29 inProceedings of the Ancient Language Process...
2016
-
[22]
”On Wasserstein Two-Sample Testing and Related Families of Nonparametric Tests
Ramdas, Aaditya, Nicolás Trillos, and Marco Cuturi. ”On Wasserstein Two-Sample Testing and Related Families of Nonparametric Tests. ”Entropy 19/2 (2017):
2017
-
[23]
”Reporting Score Distributions Makes a Difference: Performance Study of LSTM-Networks for Sequence Tagging
30 Reimers, Nils, and Iryna Gurevych. ”Reporting Score Distributions Makes a Difference: Performance Study of LSTM-Networks for Sequence Tagging. ” Pages 338–48 inProceedings of the 2017 Conference on Empir- ical Methods in Natural Language Processing . Copenhagen: Association for Computational Linguistics,
2017
-
[24]
”Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. ” Pages 3980–90 in Proceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) . Association for Computational Lin- guistics,
2019
-
[25]
” Hebrew Linguistics 39 (1995): 79–90
”The Components of the Hebrew Lexicon: The Influence of Hebrew Classical Sources, Jewish Lan- guages and Other Foreign Languages on Modern Hebrew. ” Hebrew Linguistics 39 (1995): 79–90. Roorda, Dirk, Gino Kalkman, Martijn Naaijer, and Andreas van Cranenburgh. ”LAF-Fabric: A Data Analysis Tool for Linguistic Annotation Framework with an Application to the ...
Pith/arXiv arXiv 1995
-
[26]
https://doi.org/10.48550/arXiv.1410.0286 Rosensweig, Elisha, Benjamin Resnick, Hillel Gershuni, Joshua Guedalia, Nachum Dershowitz, and Avi Shmidman. ”Automatic Text Segmentation of Ancient and Historic Hebrew. ” Pages 1–11 inProceedings of the Second Workshop on Ancient Language Processing . Association for Computational Linguistics,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1410.0286
-
[27]
”Nonparametric Estimation of the Coefficient of Overlapping— Theory and Empirical Application
Schmid, Friedrich, and Axel Schmidt. ”Nonparametric Estimation of the Coefficient of Overlapping— Theory and Empirical Application. ” Computational Statistics & Data Analysis 50 (2006): 1583–1596. Seker, Amit, Elron Bandel, Dan Bareket, Idan Brusilovsky, Refael Shaked Greenfeld, and Reut Tsarfaty. ”AlephBERT: A Hebrew Large Pre-Trained Language Model to S...
arXiv 2006
-
[28]
”Torah Study and the Digital Revolution: A Glimpse of the Future
https://doi.org/10.48550/arXiv.2104.04052 Shmidman, Avi, and Moshe Koppel. ”Torah Study and the Digital Revolution: A Glimpse of the Future. ” The Lehrhaus, 28 January
-
[29]
https://thelehrhaus.com/commentary/torah-study-and -the-digital-revolution-a-glimpse-of-the-future/ . Shmidman, Avi, Joshua Guedalia, Shaltiel Shmidman, Cheyn Shmuel Shmidman, Eli Handel, and Moshe Koppel. ”Introducing BEREL: BERT Embeddings for Rabbinic-Encoded Language. ” arXiv:2208.01875,
-
[30]
”Identification of Parallel Passages Across a Large He- brew/Aramaic Corpus
https://doi.org/10.48550/arXiv.2208.01875 Shmidman, Avi, Moshe Koppel, and Ely Porat. ”Identification of Parallel Passages Across a Large He- brew/Aramaic Corpus. ”Journal of Data Mining & Digital Humanities Special Issue on Computer-Aided Processing of Intertextuality in Ancient Languages (2018):
-
[31]
”DictaBERT: A State-of-the-Art BERT Suite for Modern Hebrew
Shmidman, Shaltiel, Avi Shmidman, and Moshe Koppel. ”DictaBERT: A State-of-the-Art BERT Suite for Modern Hebrew. ”arXiv:2308.16687, 13 October
-
[32]
16687 Shmidman, Shaltiel, Avi Shmidman, Amir DN Cohen, and Moshe Koppel
https://doi.org/10.48550/arXiv.2308. 16687 Shmidman, Shaltiel, Avi Shmidman, Amir DN Cohen, and Moshe Koppel. ”Adapting LLMs to Hebrew: Unveiling DictaLM 2.0 with Enhanced Vocabulary and Instruction Capabilities. ” arXiv:2407.07080, 9 July
-
[33]
”MRL Parsing Without Tears: The Case of Hebrew
https://doi.org/10.48550/arXiv.2407.07080 Shmidman, Shaltiel, Avi Shmidman, Moshe Koppel, and Reut Tsarfaty. ”MRL Parsing Without Tears: The Case of Hebrew. ” Pages 4537–50 in Findings of the Association for Computational Linguistics ACL 2024 . Association for Computational Linguistics,
-
[34]
”Intertextual Parallel Detection in Biblical Hebrew: A Transformer-Based Benchmark
Smiley, David M. ”Intertextual Parallel Detection in Biblical Hebrew: A Transformer-Based Benchmark. ” arXiv:2506.24117, 30 June
-
[35]
T’OMIM: Tanakh Observable Matches of Intertextual Mimesis
https://doi.org/10.48550/arXiv.2506.24117 . “T’OMIM: Tanakh Observable Matches of Intertextual Mimesis”. Zenodo, March 22,
-
[36]
”An Effective Negative Sampling Approach for Contrastive Learning of Sentence Embedding
https: //doi.org/10.5281/zenodo.19135731 Tan, Qitao, Xiaoying Song, Guanghui Ye, and Chuan Wu. ”An Effective Negative Sampling Approach for Contrastive Learning of Sentence Embedding. ” Machine Learning 112 (2023): 4837–61. Thakur, Nandan, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. ”BEIR: A Het- erogeneous Benchmark for Zero-sh...
-
[37]
”Computer-Assisted Analysis of Parallel Texts in the Bible
van Peursen, Willem, and Eep Talstra. ”Computer-Assisted Analysis of Parallel Texts in the Bible. The Case of 2 Kings Xviii-Xix and Its Parallels in Isaiah and Chronicles. ” Vetus Testamentum 57/1 (2007): 45–72. van Peursen, Willem, Constantijn Sikkel, and Dirk Roorda. ”Hebrew Text Database ETCBC4b. ” Eep Tal- stra Centre for Bible and Computing, VU Unive...
2007
-
[38]
”Measurement of Text Similarity: A Survey
Wang, Jiapeng, and Yihong Dong. ”Measurement of Text Similarity: A Survey. ” Information 11/9 (2020):
2020
-
[39]
”Shitposting as Public Pedagogy
Woods, Peter J. ”Shitposting as Public Pedagogy. ” Curriculum Inquiry 53/4 (2023): 359–80. Xu, Lanling, Jianxun Lian, Wayne Xin Zhao, Ming Gong, Linjun Shou, Daxin Jiang, Xing Xie, and Ji-Rong Wen. ”Negative Sampling for Contrastive Representation Learning: A Review. ” arXiv:2206.00212,
arXiv 2023
-
[40]
”Contrastive Learning Models for Sentence Representations
https://doi.org/10.48550/arXiv.2206.00212 Xu, Lingling, Haoran Xie, Zongxi Li, Fu Lee Wang, Weiming Wang, and Qing Li. ”Contrastive Learning Models for Sentence Representations. ” ACM Transactions on Intelligent Systems and Technology 14/4 (2023): 1–34. Yamini, Bat-Zion. ”The Revival of Ancient Hebrew Words With the Revival of Israel. ” Sociology Study 9/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.