Denoising Implicit Feedback for Cold-start Recommendation
Pith reviewed 2026-06-26 20:24 UTC · model grok-4.3
The pith
DIF denoises implicit feedback for cold-start items by inferring pseudo-labels from content-similar warm items and adaptively correcting noisy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
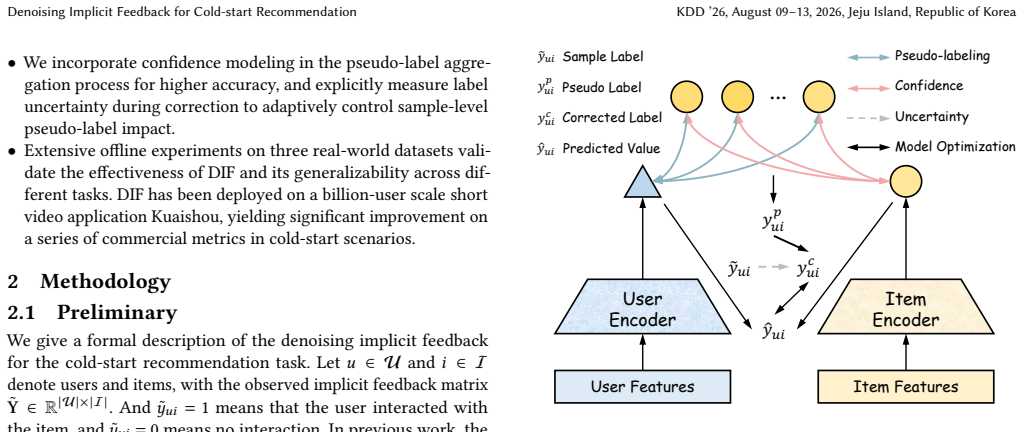
DIF infers pseudo-labels indicating user interest in cold items through content-similar warm items, models the confidence of those pseudo-labels based on content similarity, aggregates multiple pseudo-labels for each sample, and explicitly estimates uncertainty via relative entropy and cold-start status to adaptively correct noisy labels at the sample level.
What carries the argument
The pseudo-label inference and per-sample uncertainty correction process, which treats content similarity as a stable signal to generate and weight replacement labels for cold items.
If this is right
- The method can be plugged into any existing recommender without architectural changes.
- Cold items receive corrected training signals that reduce the impact of clickbait and position bias.
- Uncertainty estimation allows the model to down-weight unreliable pseudo-labels on a per-sample basis.
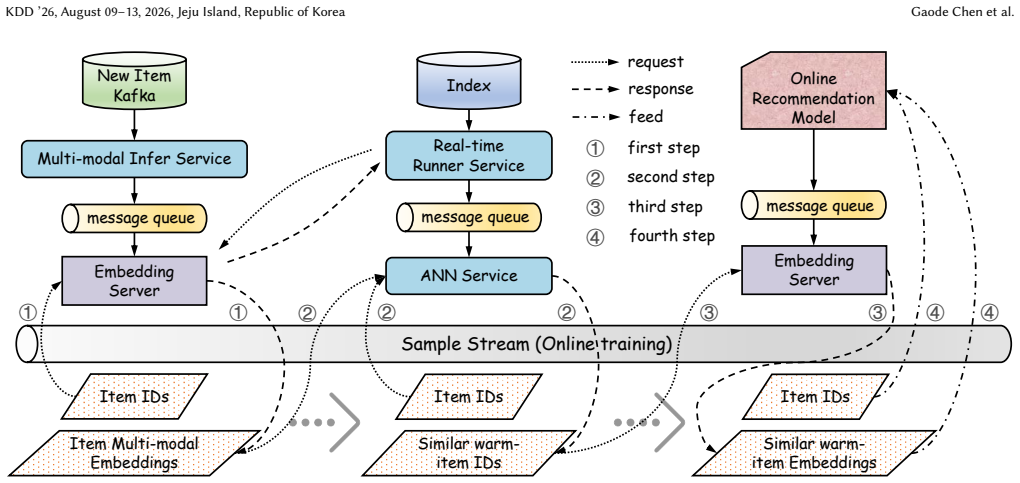
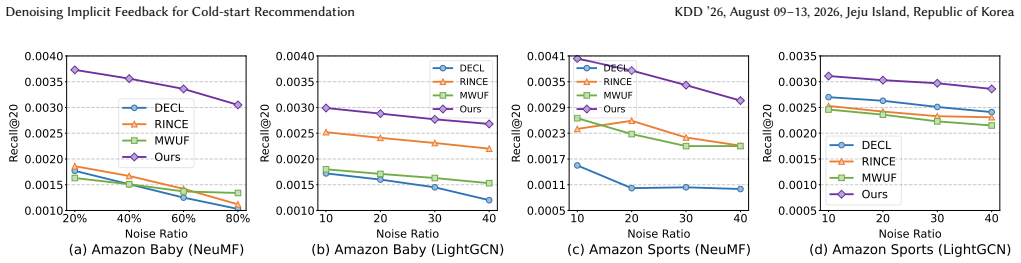
- Deployment on large-scale short-video platforms shows measurable gains in cold-start commercial metrics.
Where Pith is reading between the lines
- The same stability-of-content-preferences idea could be tested on non-recommendation tasks that involve new entities with noisy labels.
- If content embeddings are learned jointly rather than precomputed, the confidence modeling step might become more accurate.
- The relative-entropy uncertainty term suggests a possible link to active learning, where high-uncertainty cold samples could be prioritized for additional data collection.
Load-bearing premise
User preferences for content remain stable enough that interactions with warm items reliably indicate interest in content-similar cold items.
What would settle it
A controlled test in which content similarity between items shows no correlation with observed user interest patterns on cold items would falsify the inference step.
Figures
read the original abstract
Implicit feedback is widely used in recommender systems due to its accessibility and generality, yet it usually presents noisy samples (e.g., clickbait, position bias). Meanwhile, recommenders inevitably face the item cold-start problem due to the continuous influx of new items. We identify that cold items are more prone to noisy samples due to the aforementioned factors, and researchers often overlook the significance of denoising implicit feedback for cold items. Previous denoising studies usually identify noisy samples based on heuristic patterns, such as higher loss values, and mitigate noise through sample selection or re-weighting. However, these methods have limited adaptability and are ineffective in cold-start scenarios. To achieve denoising implicit feedback for cold-start recommendation, we propose a model-agnostic denoising method called DIF. First, user preferences for content remain stable, which allows us to infer pseudo-labels indicating whether a user is interested in a cold item through content-similar warm items. Furthermore, to improve pseudo-label accuracy, we model the confidence of pseudo-labels based on the content similarity between the cold item and warm items, and then aggregate multiple pseudo-labels for each sample. Finally, we explicitly estimate the uncertainty of the noisy sample label by considering its relative entropy and the cold-start status of the item, which adaptively guides the role of pseudo-labels to correct the noisy labels at the sample level. DIF's superiority is supported by both theoretical justification and extensive experiments on real-world datasets. The method has been deployed on a billion-user scale short video application Kuaishou and has significantly improved various commercial metrics within cold-start scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DIF, a model-agnostic denoising method for implicit feedback in cold-start recommendation. It infers pseudo-labels for user interest in cold items via content-similar warm items (under the assumption that user preferences for content remain stable), models pseudo-label confidence from content similarity, aggregates multiple pseudo-labels, and estimates sample-level uncertainty via relative entropy combined with cold-start status to adaptively correct noisy labels. Superiority is claimed via theoretical justification and experiments on real-world datasets, with deployment on the Kuaishou platform improving commercial metrics in cold-start scenarios.
Significance. If the stability assumption and uncertainty weighting hold under empirical validation, the approach could meaningfully extend denoising techniques to the cold-start regime, where noise is noted to be more prevalent; the reported large-scale deployment provides a practical signal of potential impact beyond academic benchmarks.
major comments (2)
- [Abstract] Abstract (method motivation paragraph): the central construction infers pseudo-labels for cold items by transferring from content-similar warm items, justified solely by the untested claim that 'user preferences for content remain stable.' No derivation from the model's generative assumptions, no direct measurement (e.g., label agreement on content-nearest neighbors), and no ablation on stability violation is referenced; if this assumption fails even moderately, the aggregated pseudo-labels are systematically biased and the subsequent relative-entropy weighting cannot recover the correct denoising signal.
- [Abstract] Abstract (final paragraph): the claim of 'theoretical justification' supporting DIF's superiority is stated without any outline of the key steps, assumptions, or bounds; because the pseudo-label aggregation and uncertainty correction are the load-bearing mechanisms, the absence of this justification prevents assessment of whether the method reduces to a well-defined estimator or merely reweights by fitted quantities.
minor comments (1)
- The abstract refers to 'extensive experiments on real-world datasets' and 'various commercial metrics' but provides no dataset names, metrics, or baseline comparisons in the given text; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will revise the abstract accordingly to improve clarity on the stability assumption and the theoretical outline.
read point-by-point responses
-
Referee: [Abstract] Abstract (method motivation paragraph): the central construction infers pseudo-labels for cold items by transferring from content-similar warm items, justified solely by the untested claim that 'user preferences for content remain stable.' No derivation from the model's generative assumptions, no direct measurement (e.g., label agreement on content-nearest neighbors), and no ablation on stability violation is referenced; if this assumption fails even moderately, the aggregated pseudo-labels are systematically biased and the subsequent relative-entropy weighting cannot recover the correct denoising signal.
Authors: The stability assumption is presented concisely in the abstract as the modeling basis for transferring preferences via content similarity, which is a standard premise in content-based recommendation when interaction data is absent. The full manuscript motivates this from the generative perspective that content features encode stable user interests independent of item popularity, with the pseudo-label aggregation and relative-entropy correction derived as a mechanism to mitigate bias when the assumption holds only approximately. While a direct label-agreement measurement on neighbors is not included, the experiments report ablations varying the similarity threshold and number of neighbors, showing consistent gains that indirectly support the assumption's utility. We will revise the abstract to explicitly label it as a core modeling assumption and cross-reference the relevant empirical sections. The relative-entropy term is intended to provide robustness by reducing the influence of conflicting pseudo-labels, though we agree a dedicated stability-violation ablation would further strengthen the claims. revision: yes
-
Referee: [Abstract] Abstract (final paragraph): the claim of 'theoretical justification' supporting DIF's superiority is stated without any outline of the key steps, assumptions, or bounds; because the pseudo-label aggregation and uncertainty correction are the load-bearing mechanisms, the absence of this justification prevents assessment of whether the method reduces to a well-defined estimator or merely reweights by fitted quantities.
Authors: We agree the abstract's reference to theoretical justification is too terse. The manuscript derives that, under the content-stability assumption, the similarity-weighted aggregation yields a consistent estimator of the underlying preference probability, and the sample-level uncertainty (relative entropy of the label distribution combined with the cold-start indicator) produces weights that provably reduce the contribution of high-entropy noisy samples to the empirical risk. Key steps are: (i) confidence modeling via content cosine similarity, (ii) aggregation into a soft pseudo-label, (iii) uncertainty as a KL-based modulator that bounds the deviation from the true label, resulting in a reweighted objective with lower excess risk than unweighted training. We will revise the abstract to include a one-sentence outline of these steps, clarifying that DIF is a derived estimator rather than heuristic reweighting. revision: yes
Circularity Check
No significant circularity; derivation rests on external content-similarity assumption
full rationale
The paper's central construction infers pseudo-labels for cold items via content similarity to warm items under the stated stability assumption. This is an explicit modeling assumption (not derived from the model's own outputs or fitted parameters). No equations, predictions, or uniqueness claims reduce by construction to self-fitted quantities or self-citations. The method is presented as model-agnostic with external experimental validation on real datasets, satisfying the criteria for a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User preferences for content remain stable
Reference graph
Works this paper leans on
-
[1]
Eric Arazo, Diego Ortego, Paul Albert, Noel O’Connor, and Kevin McGuinness
-
[2]
InInternational conference on machine learning
Unsupervised label noise modeling and loss correction. InInternational conference on machine learning. 312–321
-
[3]
Dara Bahri, Heinrich Jiang, and Maya Gupta. 2020. Deep k-nn for noisy labels. InInternational Conference on Machine Learning. PMLR, 540–550
2020
-
[4]
2013.Concentration Inequalities - A Nonasymptotic Theory of Independence
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart. 2013.Concentration Inequalities - A Nonasymptotic Theory of Independence. OUP Oxford
2013
-
[5]
Qingpeng Cai, Zhenghai Xue, Chi Zhang, Wanqi Xue, Shuchang Liu, Ruohan Zhan, Xueliang Wang, Tianyou Zuo, Wentao Xie, Dong Zheng, et al. 2023. Two- stage constrained actor-critic for short video recommendation. InProceedings of the ACM Web Conference 2023. 865–875
2023
-
[6]
Jiangxia Cao, Jiawei Sheng, Xin Cong, Tingwen Liu, and Bin Wang. 2022. Cross- domain recommendation to cold-start users via variational information bottle- neck. In2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2209–2223
2022
-
[7]
Yi Cao, Sihao Hu, Yu Gong, Zhao Li, Yazheng Yang, Qingwen Liu, and Shouling Ji
-
[8]
InProceedings of the 31st ACM International Conference on Information & Knowledge Management
Gift: Graph-guided feature transfer for cold-start video click-through rate prediction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 2964–2973
-
[9]
Gaode Chen, Ruina Sun, Yuezihan Jiang, Jiangxia Cao, Qi Zhang, Jingjian Lin, Han Li, Kun Gai, and Xinghua Zhang. 2024. A Multi-modal Modeling Framework for Cold-start Short-video Recommendation. InProceedings of the 18th ACM Conference on Recommender Systems. 391–400
2024
-
[10]
Gaode Chen, Xinghua Zhang, Yijun Su, Yantong Lai, Ji Xiang, Junbo Zhang, and Yu Zheng. 2023. Win-win: a privacy-preserving federated framework for dual-target cross-domain recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 4149–4156
2023
-
[11]
Gaode Chen, Xinghua Zhang, Yanyan Zhao, Cong Xue, and Ji Xiang. 2021. Ex- ploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence. 1426–1433
2021
-
[12]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[13]
Ching-Yao Chuang, R Devon Hjelm, Xin Wang, Vibhav Vineet, Neel Joshi, Anto- nio Torralba, Stefanie Jegelka, and Yale Song. 2022. Robust contrastive learning against noisy views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16670–16681
2022
-
[14]
Thomas M Cover, Joy A Thomas, et al. 1991. Entropy, relative entropy and mutual information.Elements of information theory2, 1 (1991), 12–13
1991
-
[15]
Jingtao Ding, Guanghui Yu, Xiangnan He, Fuli Feng, Yong Li, and Depeng Jin
-
[16]
IEEE transactions on knowledge and data engineering33, 2 (2019), 667–681
Sampler design for bayesian personalized ranking by leveraging view data. IEEE transactions on knowledge and data engineering33, 2 (2019), 667–681
2019
-
[17]
Manqing Dong, Feng Yuan, Lina Yao, Xiwei Xu, and Liming Zhu. 2020. Mamo: Memory-augmented meta-optimization for cold-start recommendation. InPro- ceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 688–697
2020
-
[18]
Wei Gao, Xin-Yi Niu, and Zhi-Hua Zhou. 2018. On the consistency of exact and approximate nearest neighbor with noisy data.Arxiv, abs/1607.07526(2018)
Pith/arXiv arXiv 2018
-
[19]
Yunjun Gao, Yuntao Du, Yujia Hu, Lu Chen, Xinjun Zhu, Ziquan Fang, and Baihua Zheng. 2022. Self-guided learning to denoise for robust recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1412–1422
2022
-
[20]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics. 249–256
2010
-
[21]
Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time short video recommendation on mobile devices. InProceedings of the 31st ACM international conference on information & knowledge management. 3103–3112
2022
-
[22]
2002.A distribution-free theory of nonparametric regression
László Györfi, Michael Kohler, Adam Krzyżak, and Harro Walk. 2002.A distribution-free theory of nonparametric regression. Springer
2002
-
[23]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
-
[24]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. InProceedings of the 26th international conference on world wide web. 173–182
2017
-
[25]
Zhuangzhuang He, Yifan Wang, Yonghui Yang, Peijie Sun, Le Wu, Haoyue Bai, Jinqi Gong, Richang Hong, and Min Zhang. 2024. Double correction frame- work for denoising recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1062–1072
2024
-
[26]
Kaixi Hu, Lin Li, Qing Xie, Jianquan Liu, and Xiaohui Tao. 2021. What is next when sequential prediction meets implicitly hard interaction?. InProceedings of the 30th ACM International Conference on Information & Knowledge Management. 710–719
2021
-
[27]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative filtering for implicit feedback datasets. In2008 Eighth IEEE international conference on data mining. Ieee, 263–272
2008
-
[28]
Hyunsik Jeon, Jong-eun Lee, Jeongin Yun, and U Kang. 2024. Cold-start bundle recommendation via popularity-based coalescence and curriculum heating. In Proceedings of the ACM Web Conference 2024. 3277–3286
2024
-
[29]
Yuezihan Jiang, Gaode Chen, Wenhan Zhang, Jingchi Wang, Yinjie Jiang, Qi Zhang, Jingjian Lin, Peng Jiang, and Kaigui Bian. 2024. Prompt Tuning for Item Cold-start Recommendation. InProceedings of the 18th ACM Conference on Recommender Systems. 411–421
2024
-
[30]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[31]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980(2014)
Pith/arXiv arXiv 2014
-
[32]
Genki Kusano. 2024. Data Augmentation using Reverse Prompt for Cost-Efficient Cold-Start Recommendation. InProceedings of the 18th ACM Conference on Rec- ommender Systems. 861–865
2024
-
[33]
Shipeng Li, Zhiqin Yang, Shikun Li, Xiaobo Xia, Hengyu Liu, Xinghua Zhang, Gaode Chen, Dong Fang, Ying Tai, and Zhe Peng. 2026. LearnAlign: Data selection for LLM reinforcement learning with improved gradient alignment. InFindings of the Association for Computational Linguistics: ACL 2026
2026
-
[34]
Ruochen Liu, Hao Chen, Yuanchen Bei, Qijie Shen, Fangwei Zhong, Senzhang Wang, and Jianxin Wang. 2024. Fine Tuning Out-of-Vocabulary Item Recom- mendation with User Sequence Imagination.Advances in Neural Information Processing Systems37 (2024), 8930–8955
2024
-
[35]
Dae Hoon Park and Yi Chang. 2019. Adversarial sampling and training for semi- supervised information retrieval. InThe World Wide Web Conference. 1443–1453
2019
-
[36]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[37]
Yang Qin, Dezhong Peng, Xi Peng, Xu Wang, and Peng Hu. 2022. Deep evidential learning with noisy correspondence for cross-modal retrieval. InProceedings of the 30th ACM International Conference on Multimedia. 4948–4956
2022
-
[38]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
2019
-
[39]
Xiang-Rong Sheng, Liqin Zhao, Guorui Zhou, Xinyao Ding, Binding Dai, Qiang Luo, Siran Yang, Jingshan Lv, Chi Zhang, Hongbo Deng, et al. 2021. One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 4104–4113
2021
-
[40]
Daiki Tanaka, Daiki Ikami, Toshihiko Yamasaki, and Kiyoharu Aizawa. 2018. Joint optimization framework for learning with noisy labels. InProceedings of the IEEE conference on computer vision and pattern recognition. 5552–5560
2018
-
[41]
Jianling Wang, Haokai Lu, James Caverlee, Ed H Chi, and Minmin Chen. 2024. Large language models as data augmenters for cold-start item recommendation. InCompanion Proceedings of the ACM Web Conference 2024. 726–729
2024
-
[42]
Jianling Wang, Haokai Lu, Sai Zhang, Bart Locanthi, Haoting Wang, Dylan Greaves, Benjamin Lipshitz, Sriraj Badam, Ed H Chi, Cristos J Goodrow, et al
-
[43]
InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recom- mendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5082–5091
-
[44]
Wenjie Wang, Fuli Feng, Xiangnan He, Liqiang Nie, and Tat-Seng Chua. 2021. Denoising implicit feedback for recommendation. InProceedings of the 14th ACM international conference on web search and data mining. 373–381
2021
-
[45]
Yu Wang, Xin Xin, Zaiqiao Meng, Joemon M Jose, Fuli Feng, and Xiangnan He. 2022. Learning robust recommenders through cross-model agreement. In Proceedings of the ACM Web Conference 2022. 2015–2025
2022
-
[46]
Zongwei Wang, Min Gao, Wentao Li, Junliang Yu, Linxin Guo, and Hongzhi Yin
-
[47]
InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Efficient bi-level optimization for recommendation denoising. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2502–2511
-
[48]
Zitai Wang, Qianqian Xu, Zhiyong Yang, Xiaochun Cao, and Qingming Huang
-
[49]
InProceedings of the 29th ACM International Conference on Multimedia
Implicit feedbacks are not always favorable: Iterative relabeled one-class collaborative filtering against noisy interactions. InProceedings of the 29th ACM International Conference on Multimedia. 3070–3078
-
[50]
Wei Wei, Chao Huang, Lianghao Xia, and Chuxu Zhang. 2023. Multi-modal self-supervised learning for recommendation. InProceedings of the ACM Web Conference 2023. 790–800
2023
-
[51]
Ji Yang, Xinyang Yi, Derek Zhiyuan Cheng, Lichan Hong, Yang Li, Simon Xiaom- ing Wang, Taibai Xu, and Ed H Chi. 2020. Mixed negative sampling for learning two-tower neural networks in recommendations. InCompanion proceedings of the web conference 2020. 441–447. Denoising Implicit Feedback for Cold-start Recommendation KDD ’26, August 09–13, 2026, Jeju Isl...
2020
-
[52]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph contrastive learning for recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1294–1303
2022
-
[53]
Wenhui Yu and Zheng Qin. 2020. Sampler design for implicit feedback data by noisy-label robust learning. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 861–870
2020
-
[54]
Tianzi Zang, Yanmin Zhu, Haobing Liu, Ruohan Zhang, and Jiadi Yu. 2022. A survey on cross-domain recommendation: taxonomies, methods, and future directions.ACM Transactions on Information Systems41, 2 (2022), 1–39
2022
-
[55]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recom- mender system: A survey and new perspectives.ACM computing surveys (CSUR) 52, 1 (2019), 1–38
2019
-
[56]
Yin Zhang, Derek Zhiyuan Cheng, Tiansheng Yao, Xinyang Yi, Lichan Hong, and Ed H Chi. 2021. A model of two tales: Dual transfer learning framework for improved long-tail item recommendation. InProceedings of the web conference
2021
-
[57]
Yuan Zhang, Xue Dong, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2023. Di- vide and Conquer: Towards Better Embedding-based Retrieval for Recommender Systems from a Multi-task Perspective. InCompanion Proceedings of the ACM Web Conference 2023. 366–370
2023
-
[58]
Yin Zhang, Ruoxi Wang, Derek Zhiyuan Cheng, Tiansheng Yao, Xinyang Yi, Lichan Hong, James Caverlee, and Ed H Chi. 2023. Empowering Long-tail Item Recommendation through Cross Decoupling Network (CDN). InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5608–5617
2023
-
[59]
Jujia Zhao, Wang Wenjie, Yiyan Xu, Teng Sun, Fuli Feng, and Tat-Seng Chua. 2024. Denoising diffusion recommender model. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1370–1379
2024
-
[60]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[61]
Zhihui Zhou, Lilin Zhang, and Ning Yang. 2023. Contrastive Collaborative Filtering for Cold-Start Item Recommendation. InProceedings of the ACM Web Conference 2023. 928–937
2023
-
[62]
Yongchun Zhu, Ruobing Xie, Fuzhen Zhuang, Kaikai Ge, Ying Sun, Xu Zhang, Leyu Lin, and Juan Cao. 2021. Learning to warm up cold item embeddings for cold- start recommendation with meta scaling and shifting networks. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1167–1176
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.