ViCoStream: Streaming VideoLLMs Can Run Beyond 100 FPS with Stage-Wise Coordinated Inference
Pith reviewed 2026-06-26 18:15 UTC · model grok-4.3
The pith
ViCoStream coordinates the full inference pipeline in streaming VideoLLMs to deliver over 100 FPS throughput and under 50 ms query latency on one GPU while holding accuracy near full-history levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
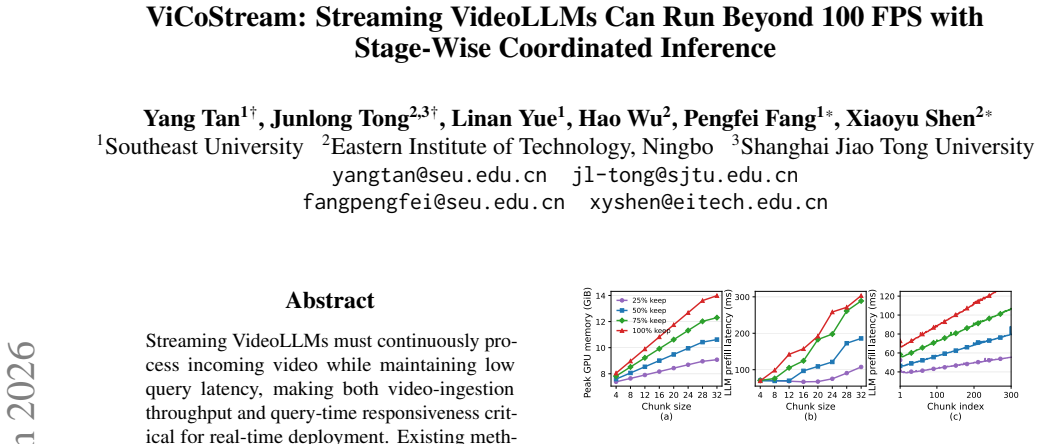
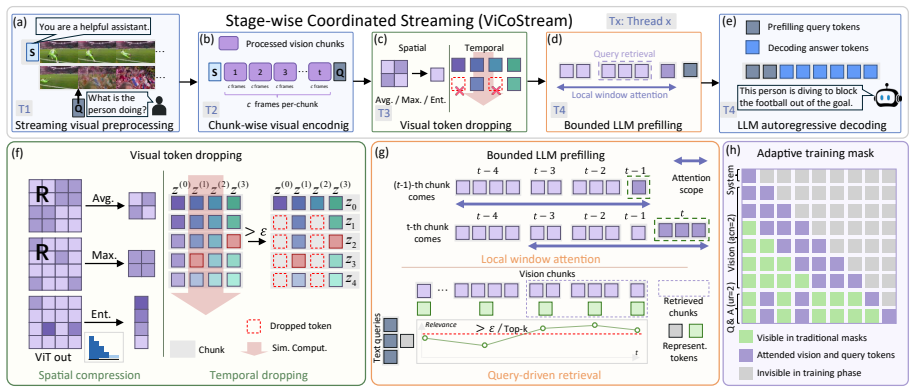
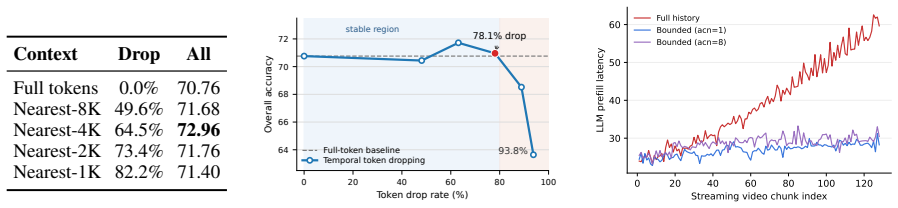
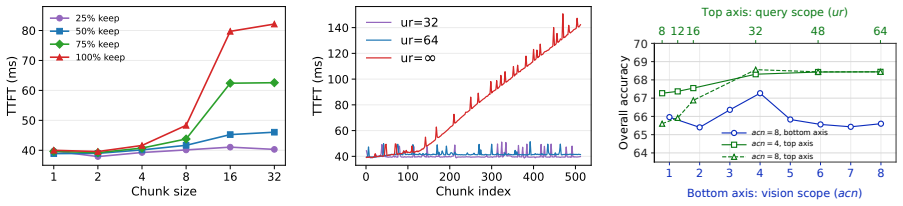
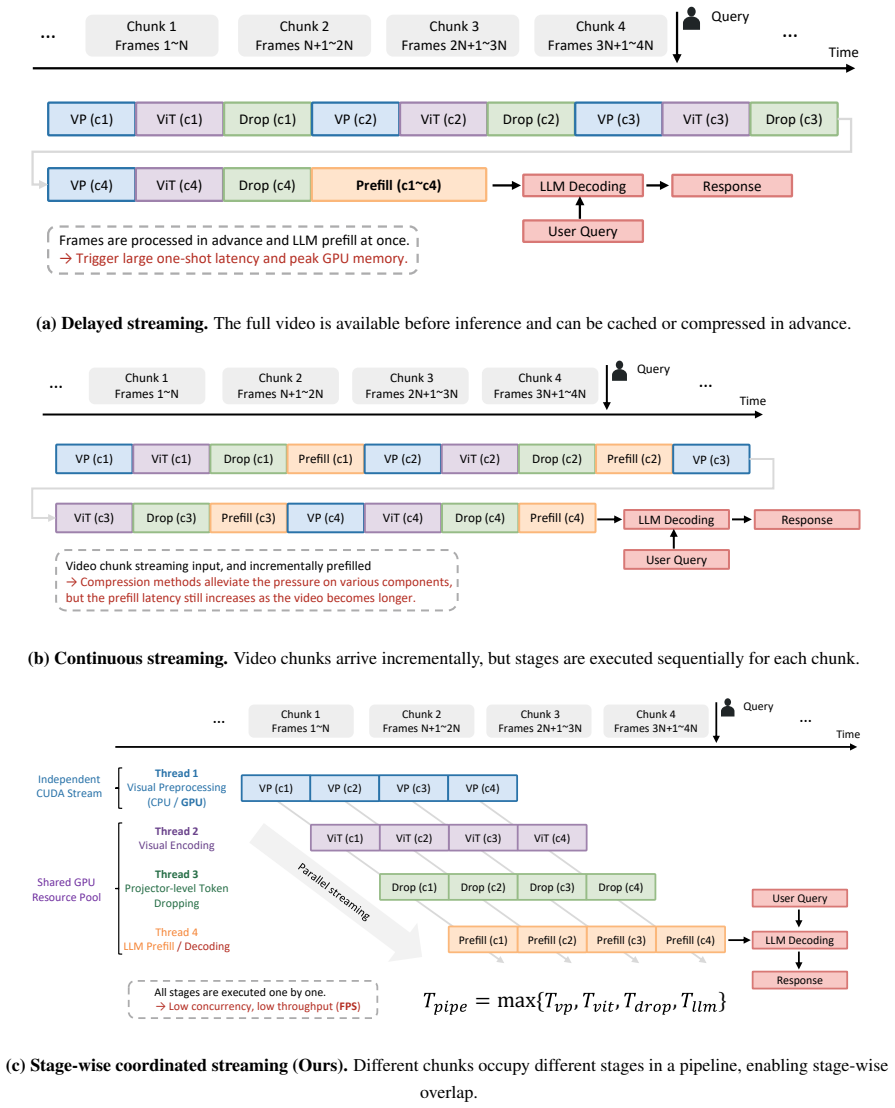
ViCoStream formulates streaming VideoLLM inference as a pipeline spanning visual preprocessing, visual encoding, token dropping, and LLM prefilling and decoding, then applies chunk-wise execution, CUDA-stream overlap, visual token control, bounded visual attention, and query-side retrieval to bound per-chunk computation and memory costs, yielding 134 FPS video throughput and less than 50 ms TTFT on a single A100 GPU with accuracy close to full-history baselines across tested models and benchmarks.
What carries the argument
ViCoStream, the stage-wise coordinated streaming framework that integrates chunk-wise execution with CUDA-stream overlap together with controls on visual tokens, bounded visual attention, and query-side retrieval to keep per-chunk costs bounded.
If this is right
- Real-time streaming VideoLLM applications become feasible on single-GPU hardware at over 100 FPS with low query latency.
- Bottleneck migration studies can guide selection of chunk size and token retention to balance speed and accuracy.
- The pipeline coordination approach supports sustained video ingestion without separate module-level optimizations.
- Accuracy remains close to full-history performance on multiple streaming benchmarks under the reported settings.
Where Pith is reading between the lines
- The same coordination pattern could be tested on video lengths or model scales beyond those evaluated here.
- Dynamic adjustment of chunk size or retention ratio based on scene complexity might further improve the trade-off.
- The work points toward similar stage-wise coordination for other long-context multimodal tasks such as audio-video streams.
Load-bearing premise
The listed techniques can be combined so that per-chunk costs remain bounded while accuracy stays near the full-history baseline across the tested models and benchmarks.
What would settle it
A run on longer video streams or additional models in which accuracy falls substantially below full-history baselines when ViCoStream is applied would falsify the central claim.
Figures

read the original abstract
Streaming VideoLLMs must continuously process incoming video while maintaining low query latency, making both video-ingestion throughput and query-time responsiveness critical for real-time deployment. Existing methods largely focus on accelerating individual modules, such as visual encoding, token pruning, or KV-cache compression, but provide limited insight into whether the resulting system can sustain real-time streaming performance. We formulate streaming VideoLLM inference as a coordinated pipeline spanning visual preprocessing, visual encoding, token dropping, and LLM prefilling/decoding. Building on this formulation, we propose ViCoStream (Video Coordinated Streaming), a stage-wise coordinated streaming framework that combines chunk-wise execution, CUDA-stream overlap, visual token control, bounded visual attention, and query-side retrieval to bound per-chunk computation and memory costs. We further provide a systematic study of bottleneck migration, revealing how chunk size, token retention, attention locality, and retrieval scope shape the throughput-accuracy trade-off. Experiments with Qwen2.5-VL-3B/7B-Instruct across multiple streaming benchmarks show that ViCoStream achieves 134 FPS video throughput and less than 50 ms TTFT on a single A100 GPU while maintaining accuracy close to full-history baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViCoStream, a stage-wise coordinated streaming framework for VideoLLMs formulated as a pipeline across visual preprocessing, encoding, token dropping, and LLM stages. It combines chunk-wise execution, CUDA-stream overlap, visual token control, bounded visual attention, and query-side retrieval to bound per-chunk costs, reports a systematic study of bottleneck migration, and claims 134 FPS video throughput with <50 ms TTFT on a single A100 GPU while maintaining accuracy close to full-history baselines on Qwen2.5-VL-3B/7B-Instruct across streaming benchmarks.
Significance. If the accuracy preservation holds under the proposed techniques, the work would be significant for real-time streaming VideoLLM deployment by demonstrating a coordinated system-level approach that achieves high throughput without sacrificing responsiveness. The bottleneck migration study provides useful insight into trade-offs between chunk size, token retention, attention locality, and retrieval scope.
major comments (2)
- [Abstract / Experiments] Abstract and experimental claims: the headline performance numbers (134 FPS, <50 ms TTFT) and accuracy equivalence rest on reported measurements, yet the provided text supplies no dataset names, benchmark details, error bars, ablation tables, or exact chunk/retrieval configurations, preventing verification that the tested cases exercise long-range dependency queries where bounded attention plus query-side retrieval might miss relevant early tokens.
- [Systematic study of bottleneck migration] The load-bearing assumption that chunk-wise execution + bounded visual attention + query-side retrieval together preserve near full-history accuracy is not yet shown to be robust; if retrieval scope is insufficient for queries needing distant past context, accuracy would degrade, and no concrete test or counter-example analysis is referenced to rule this out.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental clarity and robustness. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental claims: the headline performance numbers (134 FPS, <50 ms TTFT) and accuracy equivalence rest on reported measurements, yet the provided text supplies no dataset names, benchmark details, error bars, ablation tables, or exact chunk/retrieval configurations, preventing verification that the tested cases exercise long-range dependency queries where bounded attention plus query-side retrieval might miss relevant early tokens.
Authors: We agree that the abstract and experimental presentation would benefit from greater explicitness. The manuscript reports results on multiple streaming benchmarks with Qwen2.5-VL-3B/7B-Instruct, but we will revise the abstract, add a dedicated experimental setup subsection, and include a table specifying dataset names, benchmark details, error bars from repeated runs, ablation results, and exact chunk/retrieval configurations to enable verification of long-range dependency handling. revision: yes
-
Referee: [Systematic study of bottleneck migration] The load-bearing assumption that chunk-wise execution + bounded visual attention + query-side retrieval together preserve near full-history accuracy is not yet shown to be robust; if retrieval scope is insufficient for queries needing distant past context, accuracy would degrade, and no concrete test or counter-example analysis is referenced to rule this out.
Authors: The systematic study already examines trade-offs among chunk size, token retention, attention locality, and retrieval scope. We acknowledge the value of additional explicit robustness checks and will add a new analysis subsection with targeted tests on queries requiring distant context, along with discussion of any observed limitations or counter-examples. revision: yes
Circularity Check
No significant circularity; claims rest on empirical measurements
full rationale
The manuscript formulates a streaming pipeline and proposes ViCoStream as an engineering combination of chunk-wise execution, CUDA overlap, token control, bounded attention, and query-side retrieval. It reports experimental throughput (134 FPS) and TTFT (<50 ms) on Qwen2.5-VL models while claiming accuracy close to full-history baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All load-bearing claims are tied to benchmark measurements rather than any self-referential reduction or ansatz smuggled via prior work. This is the expected non-finding for a systems paper whose central results are externally falsifiable via replication of the reported runs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Videollm-online: Online video large language model for streaming video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[2]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Timechat-online: 80\ author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[3]
arXiv preprint arXiv:2501.13468 , year=
Streaming video understanding and multi-round interaction with memory-enhanced knowledge , author=. arXiv preprint arXiv:2501.13468 , year=
-
[4]
arXiv preprint arXiv:2601.14724 , year=
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding , author=. arXiv preprint arXiv:2601.14724 , year=
-
[5]
arXiv preprint arXiv:2510.18269 , year=
Streamingtom: Streaming token compression for efficient video understanding , author=. arXiv preprint arXiv:2510.18269 , year=
-
[6]
arXiv preprint arXiv:2512.00891 , year=
Accelerating Streaming Video Large Language Models via Hierarchical Token Compression , author=. arXiv preprint arXiv:2512.00891 , year=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mvbench: A comprehensive multi-modal video understanding benchmark , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
arXiv preprint arXiv:2410.02713 , year=
Llava-video: Video instruction tuning with synthetic data , author=. arXiv preprint arXiv:2410.02713 , year=
-
[10]
IEEE Transactions on Neural Networks and Learning Systems , year=
A Survey on Vision--Language--Action Models for Embodied AI , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[11]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Urbanvideo-bench: Benchmarking vision-language models on embodied intelligence with video data in urban spaces , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
Embodiedgpt: Vision-language pre-training via embodied chain of thought , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
IEEE Robotics and Automation Letters , volume=
Drivegpt4: Interpretable end-to-end autonomous driving via large language model , author=. IEEE Robotics and Automation Letters , volume=. 2024 , publisher=
2024
-
[14]
Conference on Robot Learning , pages=
VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision , author=. Conference on Robot Learning , pages=. 2025 , organization=
2025
-
[15]
European Conference on Computer Vision , pages=
Dolphins: Multimodal language model for driving , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[16]
European Conference on Computer Vision , pages=
Longvlm: Efficient long video understanding via large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[17]
arXiv preprint arXiv:2407.15841 , year=
Slowfast-llava: A strong training-free baseline for video large language models , author=. arXiv preprint arXiv:2407.15841 , year=
-
[18]
arXiv preprint arXiv:2501.00574 , year=
Videochat-flash: Hierarchical compression for long-context video modeling , author=. arXiv preprint arXiv:2501.00574 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Streaming long video understanding with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2412.08646 , year=
Streamchat: Chatting with streaming video , author=. arXiv preprint arXiv:2412.08646 , year=
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Streammind: Unlocking full frame rate streaming video dialogue through event-gated cognition , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[22]
arXiv preprint arXiv:2503.09387 , year=
Videoscan: Enabling efficient streaming video understanding via frame-level semantic carriers , author=. arXiv preprint arXiv:2503.09387 , year=
-
[23]
arXiv preprint arXiv:2406.08085 , year=
Flash-vstream: Memory-based real-time understanding for long video streams , author=. arXiv preprint arXiv:2406.08085 , year=
-
[24]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[25]
arXiv preprint arXiv:2508.15717 , year=
Streammem: Query-agnostic kv cache memory for streaming video understanding , author=. arXiv preprint arXiv:2508.15717 , year=
-
[26]
Internlm-xcomposer2. 5-omnilive: A comprehensive multimodal system for long-term streaming video and audio interactions , author=. arXiv preprint arXiv:2412.09596 , year=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
arXiv preprint arXiv:2410.17247 , year=
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction , author=. arXiv preprint arXiv:2410.17247 , year=
-
[29]
arXiv preprint arXiv:2210.09461 , year=
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
-
[30]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Prunevid: Visual token pruning for efficient video large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[31]
arXiv preprint arXiv:2410.04417 , year=
Sparsevlm: Visual token sparsification for efficient vision-language model inference , author=. arXiv preprint arXiv:2410.04417 , year=
-
[32]
arXiv preprint arXiv:2506.03990 , year=
Dyntok: Dynamic compression of visual tokens for efficient and effective video understanding , author=. arXiv preprint arXiv:2506.03990 , year=
-
[33]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
AdaReTaKe: Adaptive redundancy reduction to perceive longer for video-language understanding , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[34]
arXiv preprint arXiv:2410.17434 , year=
Longvu: Spatiotemporal adaptive compression for long video-language understanding , author=. arXiv preprint arXiv:2410.17434 , year=
-
[35]
arXiv preprint arXiv:2406.02069 , year=
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Minicache: Kv cache compression in depth dimension for large language models, 2024b , author=
-
[38]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Streamingbench: Assessing the gap for mllms to achieve streaming video understanding , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[39]
Ovo-bench: How far is your video-llms from real-world online video understanding?, 2025 , author=. URL https://arxiv. org/abs/2501.05510 , year=
arXiv 2025
-
[40]
Advances in Neural Information Processing Systems , volume=
Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv e-prints , pages=
CodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference , author=. arXiv e-prints , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lion-fs: Fast & slow video-language thinker as online video assistant , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
arXiv preprint arXiv:2508.08989 , year=
KFFocus: Highlighting Keyframes for Enhanced Video Understanding , author=. arXiv preprint arXiv:2508.08989 , year=
-
[44]
International Conference on Learning Representations , volume=
Streaming video question-answering with in-context video kv-cache retrieval , author=. International Conference on Learning Representations , volume=
-
[45]
arXiv preprint arXiv:2603.04592 , year=
From Static Inference to Dynamic Interaction: A Survey of Streaming Large Language Models , author=. arXiv preprint arXiv:2603.04592 , year=
-
[46]
arXiv preprint arXiv:2603.02872 , year=
Think-as-You-See: Streaming Chain-of-Thought Reasoning for Large Vision-Language Models , author=. arXiv preprint arXiv:2603.02872 , year=
-
[47]
arXiv preprint arXiv:2601.06843 , year=
Speak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models , author=. arXiv preprint arXiv:2601.06843 , year=
-
[48]
2026 , publisher=
From Data to Model: A Survey of the Compression Lifecycle in MLLMs , author=. 2026 , publisher=
2026
-
[49]
arXiv preprint arXiv:2602.23699 , year=
Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit , author=. arXiv preprint arXiv:2602.23699 , year=
-
[50]
arXiv preprint arXiv:2602.07574 , year=
Vica: Efficient multimodal llms with vision-only cross-attention , author=. arXiv preprint arXiv:2602.07574 , year=
-
[51]
arXiv preprint arXiv:2504.13915 , year=
Memory-efficient streaming videollms for real-time procedural video understanding , author=. arXiv preprint arXiv:2504.13915 , year=
-
[52]
Advances in Neural Information Processing Systems , volume=
Recurrent attention-based token selection for efficient streaming video-llms , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
arXiv preprint arXiv:2503.13707 , year=
Long-vmnet: Accelerating long-form video understanding via fixed memory , author=. arXiv preprint arXiv:2503.13707 , year=
-
[54]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Token fusion: Bridging the gap between token pruning and token merging , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[55]
arXiv preprint arXiv:2202.12015 , year=
Learning to merge tokens in vision transformers , author=. arXiv preprint arXiv:2202.12015 , year=
-
[56]
arXiv preprint arXiv:2605.25621 , year=
StreamOV: Streaming Omni-Video Understanding via Evidence-Guided Memory and Response Triggering , author=. arXiv preprint arXiv:2605.25621 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.