REDACT: A Systematically Controlled Multilingual Benchmark for Personal Information Detection
Pith reviewed 2026-06-26 17:38 UTC · model grok-4.3
The pith
REDACT benchmark shows aggregate F1 scores hide that rule-based PII detectors fail on high-sensitivity data while LLM detectors remain robust.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
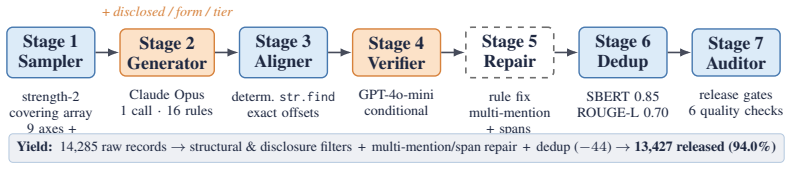
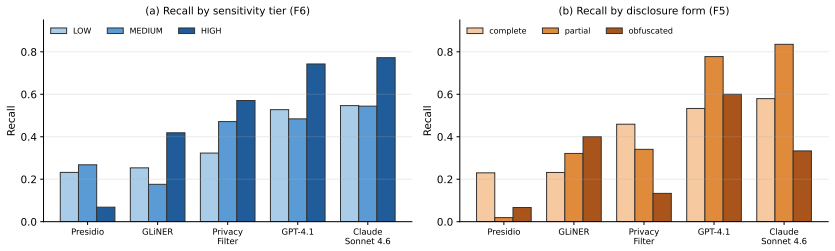
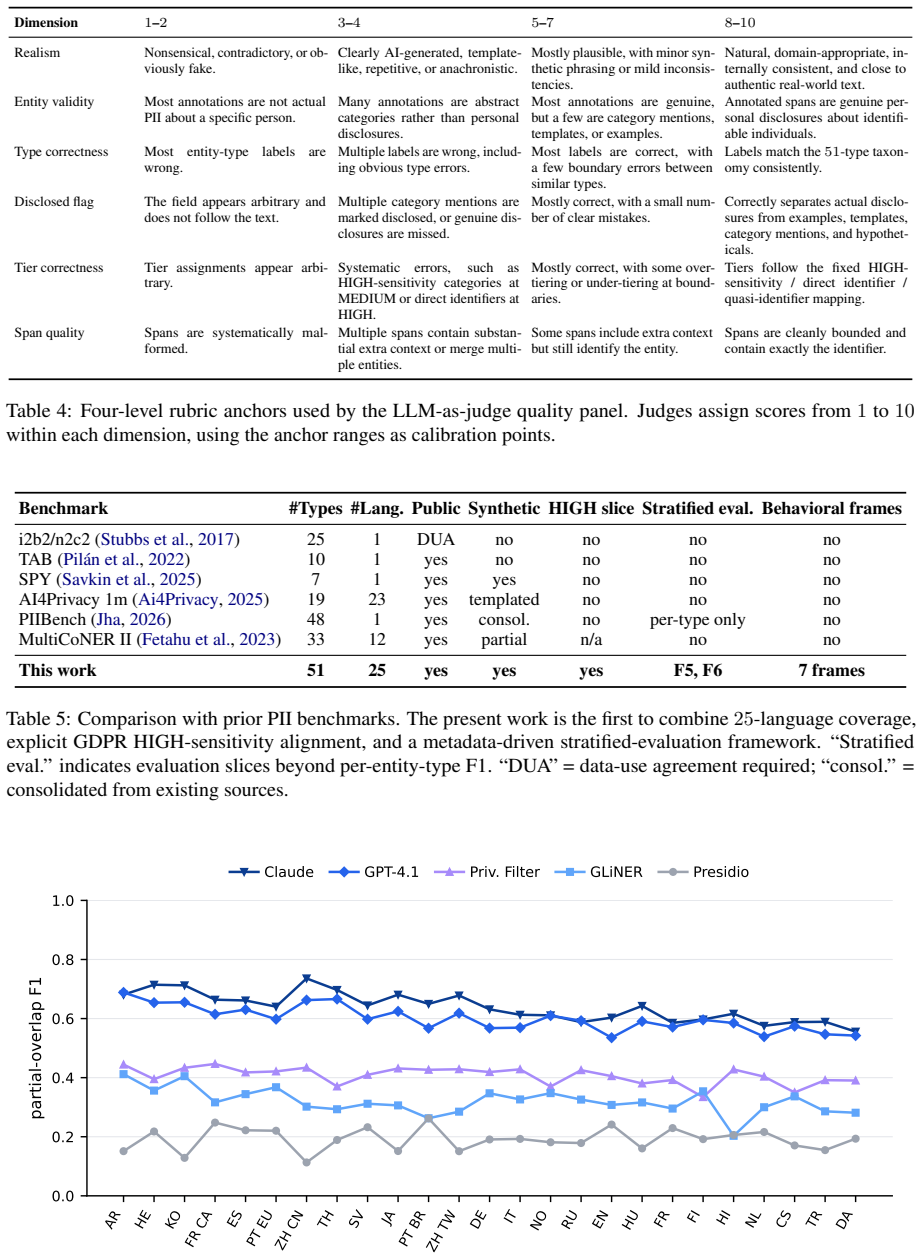
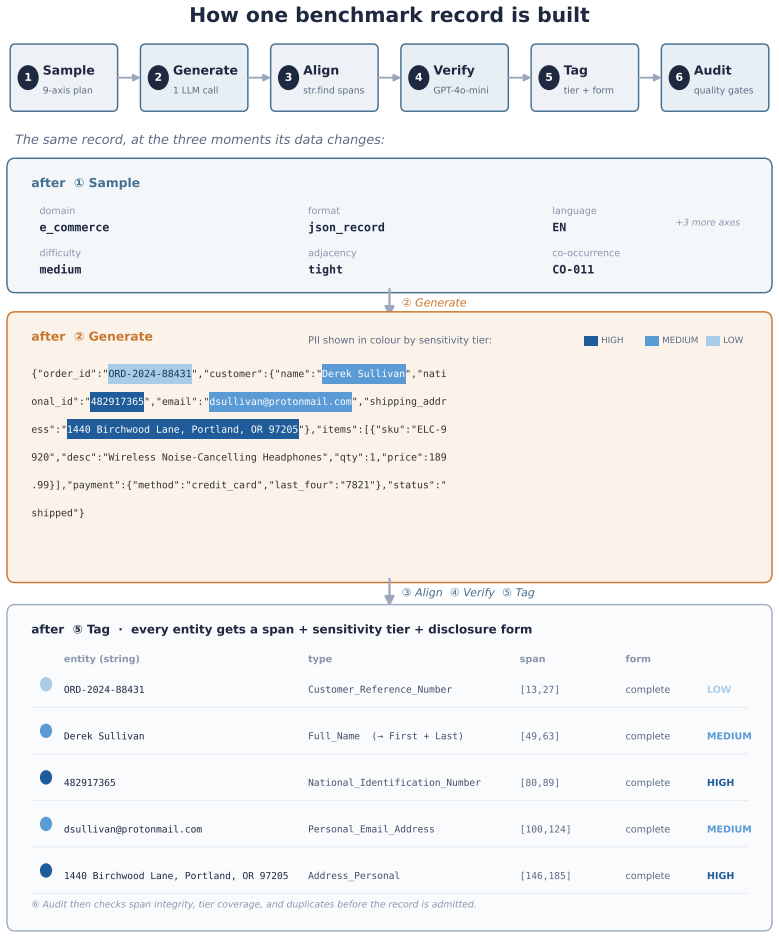
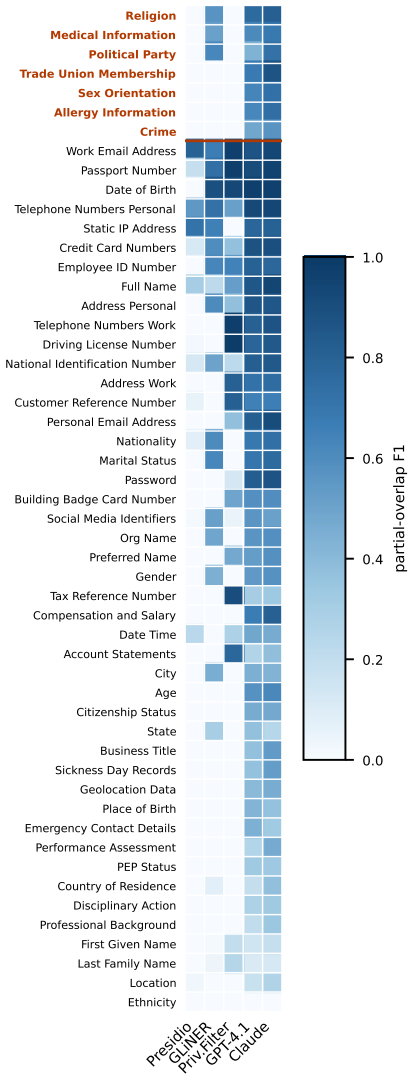
REDACT supplies 13,427 records, 324,078 entity annotations, 51 entity types, 4,127 surface-form patterns, and coverage of 25 languages across 9 scripts, all generated by a strength-2 covering-array sampler over nine axes. Three entity-level metadata fields (disclosure status, disclosure form, GDPR-aligned sensitivity tier) support stratified evaluation. On a language-stratified sample of 1,000 records the rule-based detector shows recall of 0.07 on HIGH-sensitivity categories and weaker results on non-verbatim disclosures, while the LLM detectors remain more robust with their strongest slice on the HIGH tier; a three-model reference-free LLM-as-judge confirms sensitivity tier as the hardest
What carries the argument
The strength-2 covering-array sampler that controls nine generation axes (domain, format, difficulty, length, density, code-switching, language, adjacency, co-occurrence) to produce diverse surface forms together with the three metadata fields enabling stratified evaluation by sensitivity tier, disclosure status, and disclosure form.
If this is right
- PII detector evaluation must incorporate stratified metrics by sensitivity tier, disclosure form, and disclosure status rather than aggregate F1 alone.
- Rule-based detectors exhibit systematically low recall on HIGH-sensitivity categories and non-verbatim disclosures and are therefore unsuitable for high-stakes use.
- LLM-based detectors maintain higher robustness across sensitivity tiers and disclosure forms and constitute the more reliable class for multilingual PII tasks.
- Future benchmarks must apply explicit control over linguistic and structural axes to expose the precise conditions that cause detector failures.
- The three metadata fields allow targeted diagnosis of detector weaknesses on the hardest axis of sensitivity-tier assignment.
Where Pith is reading between the lines
- Privacy tool developers should default to LLM-based detectors when handling high-sensitivity personal data in multilingual environments.
- The benchmark design could be reused to test detector performance on additional entity types or languages beyond the current 25.
- If sensitivity tier remains the hardest axis, training regimes that explicitly model sensitivity inference from context may yield further gains.
- Regulatory or compliance pipelines relying on PII detection would benefit from requiring stratified rather than aggregate performance reports.
Load-bearing premise
The strength-2 covering-array sampler controls the nine generation axes without introducing unintended biases or missing critical interactions that affect detector performance.
What would settle it
Re-running the five-detector evaluation on the 1,000-record sample and finding that all architectures achieve comparable recall on the HIGH-sensitivity tier would falsify the reported architecture-dependent failure structure.
Figures
read the original abstract
Benchmark infrastructure for personally identifiable information (PII) detection remains limited: existing corpora cover few entity types, use ad hoc generation conditions, and do not show which surface conditions cause detector failures. We present REDACT, a systematically controlled multilingual PII benchmark with 13,427 records, 324,078 entity annotations, 51 entity types, 4,127 surface-form patterns, and 25 languages across 9 scripts. A strength-2 covering-array sampler controls nine generation axes: domain, format, difficulty, length, density, code-switching, language, adjacency, and co-occurrence. Three entity-level metadata fields (disclosure status, disclosure form, and a GDPR-aligned sensitivity tier) enable stratified evaluation beyond aggregate or per-type F1. From the full benchmark, we evaluate five detectors (Presidio, GLiNER, the OpenAI Privacy Filter, GPT-4.1, and Claude Sonnet 4.6) on a locked, language-stratified sample of 1,000 records. Aggregate F1 masks an architecture-dependent failure structure: the rule-based detector performs poorly on the highest-stakes data, including HIGH-sensitivity categories (recall 0.07) and non-verbatim disclosure forms, while the LLM detectors remain more robust, with the HIGH tier as their strongest sensitivity slice. A three-model reference-free LLM-as-judge assessment corroborates that sensitivity-tier assignment is the task's hardest axis. We release the benchmark, schema, prompts, and stratified evaluation harness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REDACT, a multilingual PII detection benchmark comprising 13,427 records, 324,078 annotations, 51 entity types, and 25 languages. It employs a strength-2 covering-array sampler over nine axes (domain, format, difficulty, length, density, code-switching, language, adjacency, co-occurrence) to generate data with three metadata fields (disclosure status, form, GDPR sensitivity tier). On a locked 1,000-record stratified sample, it evaluates five detectors and reports that aggregate F1 obscures architecture-dependent patterns: rule-based systems (e.g., Presidio) show low recall (0.07) on HIGH-sensitivity and non-verbatim cases, while LLM detectors are more robust with HIGH as their strongest tier. The benchmark, schema, and harness are released.
Significance. If the sampling control is sufficient to support attribution, the work supplies a reusable, stratified evaluation resource that moves beyond aggregate metrics and ad-hoc corpora in PII detection. Explicit release of the full benchmark, prompts, and evaluation harness constitutes a concrete contribution that enables follow-on work. The sensitivity-tier analysis and LLM-as-judge corroboration add practical value for high-stakes deployment.
major comments (1)
- [Abstract / generation process] Abstract and the generation-process description: the statement that the strength-2 covering-array sampler 'controls' the nine axes is imprecise. Strength-2 guarantees every pair of factor levels appears at least once but provides no coverage or balance for three-way or higher interactions. Because the central claim attributes the observed architecture-dependent failure structure (rule-based recall 0.07 on HIGH-sensitivity/non-verbatim; LLMs robust on HIGH) to detector properties rather than sampling artifacts, the lack of validation that higher-order interactions are balanced or checked in the 1,000-record sample undermines the attribution. A concrete test (e.g., post-hoc balance check on selected three-way margins or sensitivity analysis) is needed.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of REDACT's contribution and for the constructive comment on the covering-array description. We address the major comment point-by-point below and will incorporate the requested validation in the revision.
read point-by-point responses
-
Referee: [Abstract / generation process] Abstract and the generation-process description: the statement that the strength-2 covering-array sampler 'controls' the nine axes is imprecise. Strength-2 guarantees every pair of factor levels appears at least once but provides no coverage or balance for three-way or higher interactions. Because the central claim attributes the observed architecture-dependent failure structure (rule-based recall 0.07 on HIGH-sensitivity/non-verbatim; LLMs robust on HIGH) to detector properties rather than sampling artifacts, the lack of validation that higher-order interactions are balanced or checked in the 1,000-record sample undermines the attribution. A concrete test (e.g., post-hoc balance check on selected three-way margins or sensitivity analysis) is needed.
Authors: We agree the phrasing 'controls the nine axes' is imprecise and will revise the abstract and generation section to state that the strength-2 covering array guarantees pairwise coverage of all factor combinations. This design ensures every pair of levels appears at least once, which is the standard approach in combinatorial testing to control main effects and two-way interactions while keeping the corpus size tractable. The 1,000-record locked sample is drawn via language-stratified sampling from the full benchmark; we acknowledge that explicit checks on three-way margins (e.g., sensitivity tier × disclosure form × language) were not reported. In the revision we will add a post-hoc balance analysis on selected three-way combinations involving the sensitivity tier and disclosure form, together with a brief sensitivity discussion, to further support that the reported architecture-dependent patterns are attributable to detector behavior rather than sampling artifacts. revision: yes
Circularity Check
No circularity: benchmark construction and external-detector evaluation are independent of fitted inputs or self-citations
full rationale
The paper constructs a new benchmark (13,427 records, 51 entity types, strength-2 covering array over nine axes) and evaluates five external detectors (Presidio, GLiNER, OpenAI Privacy Filter, GPT-4.1, Claude Sonnet 4.6) on a locked 1,000-record sample. No equations, parameters, or predictions are fitted to the target performance metrics and then re-presented as results. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The sensitivity-tier and disclosure-form stratifications are metadata fields defined in the schema, not derived from detector outputs. The derivation chain (controlled generation → stratified evaluation) is self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A strength-2 covering array sufficiently controls interactions among the nine generation axes without residual bias.
- domain assumption The three-model LLM-as-judge produces reliable sensitivity-tier labels aligned with GDPR categories.
Reference graph
Works this paper leans on
-
[1]
2016 , note=
Regulation (EU) 2016/679 of the European Parliament and of the Council , author=. 2016 , note=
2016
-
[2]
Computational Linguistics , year=
The Text Anonymization Benchmark (TAB) , author=. Computational Linguistics , year=
-
[3]
Journal of biomedical informatics , year=
De-identification of psychiatric intake records: Overview of 2016 CEGS N-GRID shared tasks Track 1 , author=. Journal of biomedical informatics , year=
2016
-
[4]
IEEE Transactions on Software Engineering , year=
Software fault interactions and implications for software testing , author=. IEEE Transactions on Software Engineering , year=
-
[5]
Practical Combinatorial Testing , author=
-
[6]
ICLR , year=
Learning the Difference that Makes a Difference with Counterfactually-Augmented Data , author=. ICLR , year=
-
[7]
Findings of EMNLP , year=
Evaluating Models' Local Decision Boundaries via Contrast Sets , author=. Findings of EMNLP , year=
-
[8]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing , author=
-
[9]
EMNLP , year=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. EMNLP , year=
-
[10]
EMNLP , year=
SimCSE: Simple Contrastive Learning of Sentence Embeddings , author=. EMNLP , year=
-
[11]
Text Summarization Branches Out , year=
ROUGE: A Package for Automatic Evaluation of Summaries , author=. Text Summarization Branches Out , year=
-
[12]
ACL , year=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. ACL , year=
-
[13]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , year=
-
[14]
Zaratiana, Urchade and Tomeh, Nadi and Holat, Pierre and Charnois, Thierry , booktitle=
-
[15]
Dynabench: Rethinking Benchmarking in
Kiela, Douwe and Bartolo, Max and Nie, Yixin and Kaushik, Divyansh and Geiger, Atticus and Wu, Zhengxuan and Vidgen, Bertie and Prasad, Grusha and Singh, Amanpreet and Ringshia, Pratik and others , booktitle=. Dynabench: Rethinking Benchmarking in
-
[16]
Annals of Statistics , volume=
Bootstrap Methods: Another Look at the Jackknife , author=. Annals of Statistics , volume=
-
[17]
Journal of Biomedical Informatics , year=
Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth Corpus , author=. Journal of Biomedical Informatics , year=
2014
-
[18]
CoNLL , year=
Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition , author=. CoNLL , year=
2003
-
[19]
2013 , publisher=
OntoNotes Release 5.0 , author=. 2013 , publisher=
2013
-
[20]
Malmasi, Shervin and Fang, Anjie and Fetahu, Besnik and Kar, Sudipta and Rokhlenko, Oleg , booktitle=
-
[21]
Fetahu, Besnik and Kar, Sudipta and Chen, Zhiyu and Rokhlenko, Oleg and Malmasi, Shervin , booktitle=
-
[22]
DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows , author=
-
[23]
Beyond Accuracy: Behavioral Testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , booktitle=. Beyond Accuracy: Behavioral Testing of
-
[24]
2025 , pages =
Savkin, Maksim and Ionov, Timur and Konovalov, Vasily , booktitle =. 2025 , pages =
2025
-
[25]
PIIBench: A Unified Multi-Source Benchmark Corpus for Personally Identifiable Information Detection
Jha, Pritesh , year =. 2604.15776 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2024 , pages =
Li, Haoran and Guo, Dadi and Li, Donghao and Fan, Wei and Hu, Qi and Liu, Xin and Chan, Chunkit and Yao, Duanyi and Yao, Yuan and Song, Yangqiu , booktitle =. 2024 , pages =
2024
-
[27]
GLiNER2-PII: A Multilingual Model for Personally Identifiable Information Extraction
Zaratiana, Urchade and Lewis, Ash and Hurn-Maloney, George , year =. 2605.09973 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
and Nishitha, Sanka Nithya Tanvy and Mukherji, Abhishek , year =
Rajgarhia, Harshit and Gupta, Suryam and Shaik, Asif and Kumar, Gulipalli Praveen and Santhoshraj, Y. and Nishitha, Sanka Nithya Tanvy and Mukherji, Abhishek , year =. An Evaluation Study of Hybrid Methods for Multilingual. 2510.07551 , archivePrefix =
-
[29]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Interpretable Multi-dataset Evaluation for Named Entity Recognition , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[31]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[32]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
Sampling Techniques , author =
-
[34]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
With Little Power Comes Great Responsibility , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
2020
-
[35]
Content Analysis: An Introduction to Its Methodology , author =
-
[36]
2016 , note =
Regulation (. 2016 , note =
2016
-
[37]
The Text Anonymization Benchmark (
Pil. The Text Anonymization Benchmark (. Computational Linguistics , year =
-
[38]
De-identification of Psychiatric Intake Records: Overview of 2016
Stubbs, Amber and Filannino, Michele and Uzuner,. De-identification of Psychiatric Intake Records: Overview of 2016. Journal of Biomedical Informatics , year =
2016
-
[39]
IEEE Transactions on Software Engineering , year =
Software Fault Interactions and Implications for Software Testing , author =. IEEE Transactions on Software Engineering , year =
-
[40]
2010 , url =
Practical Combinatorial Testing , author =. 2010 , url =
2010
-
[41]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
Xu, Zhangchen and Jiang, Fengqing and Niu, Luyao and Deng, Yuntian and Poovendran, Radha and Choi, Yejin and Lin, Bill Yuchen , year =. 2406.08464 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , url =
2019
-
[43]
2021 , url =
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi , booktitle =. 2021 , url =
2021
-
[44]
2004 , url =
Lin, Chin-Yew , booktitle =. 2004 , url =
2004
-
[45]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[46]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , year =
-
[47]
2024 , url =
Zaratiana, Urchade and Tomeh, Nadi and Holat, Pierre and Charnois, Thierry , booktitle =. 2024 , url =
2024
-
[48]
2022 , url =
Malmasi, Shervin and Fang, Anjie and Fetahu, Besnik and Kar, Sudipta and Rokhlenko, Oleg , booktitle =. 2022 , url =
2022
-
[49]
2023 , url =
Fetahu, Besnik and Kar, Sudipta and Chen, Zhiyu and Rokhlenko, Oleg and Malmasi, Shervin , booktitle =. 2023 , url =
2023
-
[50]
Beyond Accuracy: Behavioral Testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , booktitle =. Beyond Accuracy: Behavioral Testing of. 2020 , url =
2020
-
[51]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
Interpretable Multi-Dataset Evaluation for Named Entity Recognition , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
2020
-
[52]
Pradhan, Bidyapati and Dasgupta, Surajit and Saha, Amit Kumar and Anustoop, Omkar and Puttagunta, Sriram and Mittal, Vipul and Sarda, Gopal , year =. 2508.15432 , archivePrefix =
-
[53]
2023 , url =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.