DiffMath: Symbol- and Graph-Aware Latent Diffusion Transformer for Handwritten Mathematical Expression Generation
Pith reviewed 2026-06-26 17:52 UTC · model grok-4.3
The pith
DiffMath generates handwritten math expressions from LaTeX hierarchies alone by encoding them as compact symbol-relation-depth triplets instead of using bounding-box labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
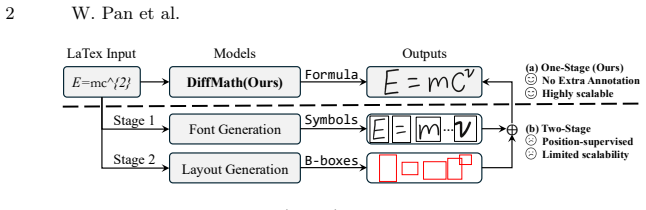
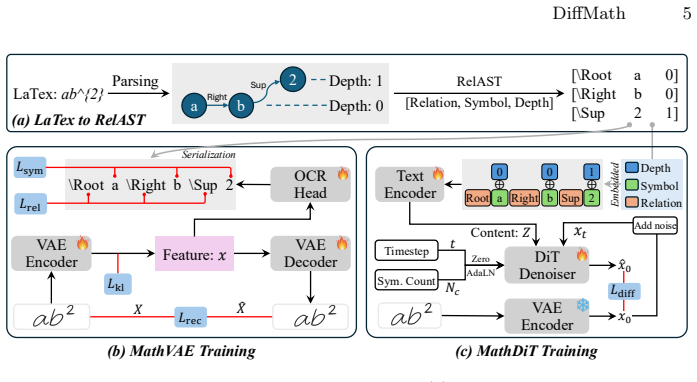
DiffMath is a symbol- and graph-aware latent diffusion framework that uses the hierarchical structure inherent in LaTeX as a structural prior. It first converts expressions via Relational Abstract Syntax Tree (RelAST) into triplet sequences [S, R, D], trains MathVAE with symbol-aware and relation-aware perceptual regularization to obtain structure-preserving latents, and runs MathDiT for conditional denoising guided by a symbol-count prior through Adaptive Layer Normalization (AdaLN).
What carries the argument
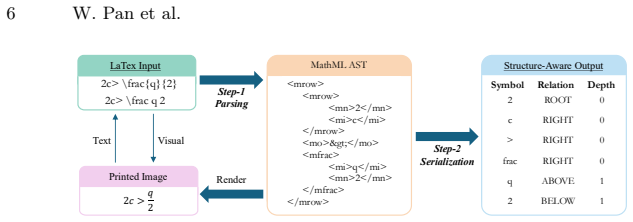
RelAST, a generation-oriented representation that distills MathML trees into compact triplet sequences [S, R, D] where each token encodes symbol identity, spatial relation, or nesting depth.
If this is right
- Generated expressions maintain correct spatial topology without any bounding-box supervision during training or inference.
- The method achieves higher scores than prior approaches on standard generation metrics for handwritten math.
- Synthetic images produced by the model improve accuracy when used to augment training data for downstream OCR systems.
Where Pith is reading between the lines
- The triplet encoding could be applied to other hierarchically structured generation problems such as chemical diagrams or circuit schematics where explicit coordinates are costly.
- Because the approach removes the need for position labels, it may allow creation of much larger synthetic datasets covering rare symbols or unusual layouts.
- The learned latent space might support controlled editing, such as changing one sub-expression while keeping overall structure fixed.
Load-bearing premise
The hierarchical structure inherent in LaTeX can be distilled into compact triplet sequences [S, R, D] that preserve spatial topology sufficiently well to replace explicit positional supervision.
What would settle it
If expressions generated by the model show frequent spatial errors such as misplaced superscripts or unbalanced fractions when inspected by eye, or if adding the synthetic samples to an OCR training set produces no measurable accuracy gain over real data alone.
Figures


read the original abstract
Handwritten Mathematical Expression Generation (HMEG) is challenging due to the complex two-dimensional layouts and long-range structural dependencies of mathematical expressions. Existing methods typically rely on explicit spatial supervision, such as symbol-level bounding boxes, which incurs high annotation costs and limits scalability. In this work, we propose DiffMath, a symbol- and graph-aware latent diffusion framework that leverages the hierarchical structure inherent in LaTeX as a structural prior, eliminating the need for positional supervision. First, we design a Relational Abstract Syntax Tree (RelAST), a generation-oriented representation that distills MathML trees into compact triplet sequences [S, R, D], where each token directly encodes a symbol identity, spatial relation, or nesting depth. Second, we introduce MathVAE, which learns structure-preserving latent representations through symbol-aware and relation-aware perceptual regularization, ensuring that the latent space captures both character semantics and spatial topology. Third, MathDiT performs conditional denoising in this structured latent space, further guided by a global symbol-count prior via Adaptive Layer Normalization (AdaLN) to improve structural coherence. Experiments show that DiffMath produces structurally consistent handwritten expressions, achieves superior performance over existing methods, and improves the accuracy of downstream OCR models through synthetic data augmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffMath, a symbol- and graph-aware latent diffusion framework for Handwritten Mathematical Expression Generation (HMEG). It introduces a Relational Abstract Syntax Tree (RelAST) that distills MathML/LaTeX trees into compact [S, R, D] triplet sequences, a MathVAE that learns structure-preserving latent representations via symbol-aware and relation-aware perceptual regularization, and a MathDiT that performs conditional denoising in this latent space with global symbol-count guidance via Adaptive Layer Normalization (AdaLN). The central claim is that this approach eliminates the need for explicit positional supervision such as symbol-level bounding boxes while producing structurally consistent expressions, outperforming existing methods, and improving downstream OCR accuracy through synthetic data augmentation.
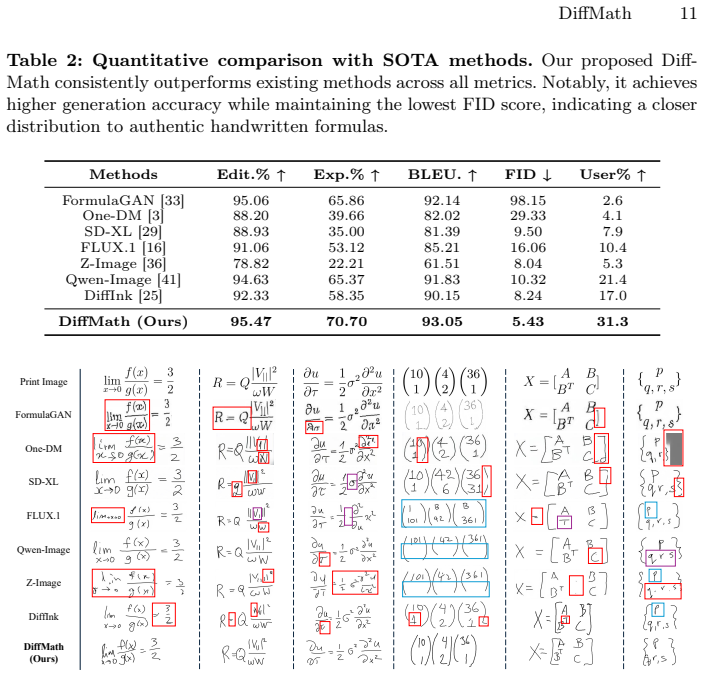
Significance. If the quantitative claims hold, the work could meaningfully lower annotation costs for spatial supervision in HMEG datasets and supply higher-quality synthetic data for training mathematical OCR models. The use of an external LaTeX structural prior to replace explicit geometry supervision is a potentially high-impact direction if the topology is shown to be preserved.
major comments (2)
- [Abstract] Abstract: the abstract asserts superior performance and downstream OCR gains but supplies no quantitative metrics, baseline comparisons, ablation results, or dataset details; claims cannot be verified from the given text.
- [Abstract] Abstract: the central claim requires that RelAST triplets distilled from MathML/LaTeX trees encode spatial relations and nesting sufficiently to replace explicit positional supervision (bounding boxes). The representation converts trees to compact sequences where each token is symbol, relation or depth; however, flattening a 2D layout graph into a linear triplet stream can lose alignment, adjacency and long-range spatial constraints (e.g., horizontal positioning in matrices or vertical centering in fractions). If this occurs, MathVAE perceptual regularization and MathDiT denoising must implicitly recover the missing geometry, which the abstract does not demonstrate is possible without additional supervision.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments. We address each major point below and indicate planned revisions where appropriate. The full manuscript contains the supporting experiments and ablations referenced in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts superior performance and downstream OCR gains but supplies no quantitative metrics, baseline comparisons, ablation results, or dataset details; claims cannot be verified from the given text.
Authors: We agree the abstract is too terse to allow verification of the claims. In the revised manuscript we will expand the abstract to include the primary quantitative results (e.g., the main HMEG metric and the downstream OCR accuracy gain) together with the dataset names and a brief statement of the strongest baseline. revision: yes
-
Referee: [Abstract] Abstract: the central claim requires that RelAST triplets distilled from MathML/LaTeX trees encode spatial relations and nesting sufficiently to replace explicit positional supervision (bounding boxes). The representation converts trees to compact sequences where each token is symbol, relation or depth; however, flattening a 2D layout graph into a linear triplet stream can lose alignment, adjacency and long-range spatial constraints (e.g., horizontal positioning in matrices or vertical centering in fractions). If this occurs, MathVAE perceptual regularization and MathDiT denoising must implicitly recover the missing geometry, which the abstract does not demonstrate is possible without additional supervision.
Authors: RelAST explicitly encodes spatial relations via the R component of each triplet and nesting via D; the linear sequence therefore retains the topology that would otherwise be supplied by bounding boxes. The symbol-aware and relation-aware perceptual losses in MathVAE are designed to enforce preservation of this topology in the latent space, while MathDiT’s conditional denoising and AdaLN symbol-count guidance further promote global structural consistency. Section 4 and the associated ablations show that the resulting generations are structurally coherent and improve downstream OCR without any bounding-box supervision. We will add one sentence to the abstract clarifying that the perceptual regularizers recover the necessary geometry. revision: partial
Circularity Check
No circularity; derivation uses external LaTeX prior and independent training
full rationale
The paper introduces RelAST as a distillation of standard MathML/LaTeX trees into [S, R, D] triplets, an external structural prior rather than a self-defined quantity. MathVAE perceptual regularization and MathDiT denoising operate on this input representation with no equations shown that equate outputs to fitted parameters or prior self-citations by construction. Performance claims rest on downstream experiments and OCR augmentation, which are falsifiable outside the method definition. No load-bearing step reduces to tautology or self-referential fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion and VAE training hyperparameters
axioms (1)
- domain assumption LaTeX/MathML trees encode sufficient spatial topology for generation without explicit bounding boxes
invented entities (3)
-
RelAST
no independent evidence
-
MathVAE
no independent evidence
-
MathDiT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Bhunia, A.K., Khan, S., Cholakkal, H., Anwer, R.M., Khan, F.S., Shah, M.: Hand- writing transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1086–1094 (October 2021)
2021
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Y., Gao, F., Zhang, Y., Qiao, M., Wang, N.: Generating handwritten mathe- matical expressions from symbol graphs: An end-to-end pipeline. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15675–15685 (June 2024)
2024
-
[3]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Dai, G., Zhang, Y., Ke, Q., Guo, Q., Huang, S.: One-DM: One-shot diffusion mimicker for handwritten text generation. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 410–427. Springer Nature Switzerland, Cham (2025)
2024
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Dai, G., Zhang, Y., Qin, Y., Guo, Q., Huang, S., Yan, S.: Beyond isolated words: Diffusion brush for handwritten text-line generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 19054– 19064 (October 2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Dai, G., Zhang, Y., Wang, Q., Du, Q., Yu, Z., Liu, Z., Huang, S.: Disentangling writer and character styles for handwriting generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5977–5986 (June 2023)
2023
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Fogel, S., Averbuch-Elor, H., Cohen, S., Mazor, S., Litman, R.: ScrabbleGAN: Semi-supervised varying length handwritten text generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
2020
-
[7]
Gan, J., Li, B., Zhang, Y.M., Leng, J., Wang, W., Gao, X.: Stylized handwriting generation of arbitrary structures and OOV expressions: A decoupled approach via layout-offsets (2025),https://openreview.net/forum?id=SuLp0J2uan
2025
-
[8]
Gan,J.,Wang,W.:HiGAN:Handwritingimitationconditionedonarbitrary-length texts and disentangled styles. Proceedings of the AAAI Conference on Artificial In- telligence35(9), 7484–7492 (May 2021).https://doi.org/10.1609/aaai.v35i9. 16917
-
[9]
Gervais, P., Fadeeva, A., Maksai, A.: MathWriting: A dataset for handwritten mathematical expression recognition. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. p. 5459–5469. KDD ’25, Association for Computing Machinery, New York, NY, USA (2025).https: //doi.org/10.1145/3711896.3737436
-
[10]
Generating Sequences With Recurrent Neural Networks
Graves, A.: Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Proceedings of the 23rd International Conference on Machine Learning , series =
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd International Conference on Machine Learning. p. 369–376. ICML ’06, Association for Computing Machinery, New York, NY, USA (2006).https://doi.org/10.1145/1143844.1143891
-
[12]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Guan, T., Lin, C., Shen, W., Yang, X.: PosFormer: Recognizing complex handwrit- ten mathematical expression with position forest transformer. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 130–147. Springer Nature Switzerland, Cham (2025)
2024
-
[13]
In: 16 W
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: 16 W. Pan et al. Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, In...
2017
-
[14]
In: NeurIPS 2021 Work- shop on Deep Generative Models and Downstream Applications (2021),https: //openreview.net/forum?id=qw8AKxfYbI
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS 2021 Work- shop on Deep Generative Models and Downstream Applications (2021),https: //openreview.net/forum?id=qw8AKxfYbI
2021
-
[15]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[16]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: FLUX.1 Kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Li, B., Yuan, Y., Liang, D., Liu, X., Ji, Z., Bai, J., Liu, W., Bai, X.: When counting meets HMER: Counting-aware network for handwritten mathematical expression recognition. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 197–214. Springer Nature Switzerland, Cham (2022)
2022
-
[18]
In: The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems (2025),https://openreview.net/forum?id=oHbVboLXz6
Li,Y.,Jiang,J.,Zhu,J.,Peng,S.,Wei,B.,Zhou,Y.,Gao,L.:Uni-MuMER:Unified multi-task fine-tuning of vision-language model for handwritten mathematical ex- pression recognition. In: The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems (2025),https://openreview.net/forum?id=oHbVboLXz6
2025
-
[19]
IEEE transactions on neural networks and learning systems34(11), 8503–8515 (2022)
Luo, C., Zhu, Y., Jin, L., Li, Z., Peng, D.: SLOGAN: handwriting style synthesis for arbitrary-length and out-of-vocabulary text. IEEE transactions on neural networks and learning systems34(11), 8503–8515 (2022)
2022
-
[20]
In: 2019 International Confer- ence on Document Analysis and Recognition (ICDAR)
Mahdavi, M., Zanibbi, R., Mouchere, H., Viard-Gaudin, C., Garain, U.: Ic- dar 2019 crohme + tfd: Competition on recognition of handwritten mathemat- ical expressions and typeset formula detection. In: 2019 International Confer- ence on Document Analysis and Recognition (ICDAR). pp. 1533–1538 (2019). https://doi.org/10.1109/ICDAR.2019.00247
-
[21]
https://github.com/brucemiller/LaTeXML(2026), accessed: 2026-03-05
Miller, B.: LaTeXML: a tex and latex to xml/html/epub/mathml translator. https://github.com/brucemiller/LaTeXML(2026), accessed: 2026-03-05
2026
-
[22]
In: 2014 14th International Conference on Frontiers in Handwriting Recognition
Mouchère, H., Viard-Gaudin, C., Zanibbi, R., Garain, U.: Icfhr 2014 competition on recognition of on-line handwritten mathematical expressions (crohme 2014). In: 2014 14th International Conference on Frontiers in Handwriting Recognition. pp. 791–796 (2014).https://doi.org/10.1109/ICFHR.2014.138
-
[23]
In: 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR)
Mouchère, H., Viard-Gaudin, C., Zanibbi, R., Garain, U.: Icfhr2016 crohme: Com- petition on recognition of online handwritten mathematical expressions. In: 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR). pp. 607–612 (2016).https://doi.org/10.1109/ICFHR.2016.0116
-
[24]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Nikolaidou, K., Retsinas, G., Sfikas, G., Liwicki, M.: DiffusionPen: Towards con- trolling the style of handwritten text generation. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 417–434. Springer Nature Switzerland, Cham (2025)
2024
-
[25]
In: The Fourteenth International Conference on Learning Representations (2026),https: //openreview.net/forum?id=XKOEQFKFdL DiffMath 17
Pan, W., He, H., Cheng, H., Shi, Y., Jin, L.: DiffInk: Glyph- and style-aware latent diffusion transformer for text to online handwriting generation. In: The Fourteenth International Conference on Learning Representations (2026),https: //openreview.net/forum?id=XKOEQFKFdL DiffMath 17
2026
-
[26]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195– 4205 (October 2023)
2023
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Pippi, V., Cascianelli, S., Cucchiara, R.: Handwritten text generation from visual archetypes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22458–22467 (June 2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Pippi, V., Quattrini, F., Cascianelli, S., Tonioni, A., Cucchiara, R.: Zero-shot styled text image generation, but make it autoregressive. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7910–7919 (June 2025)
2025
-
[29]
In: The Twelfth International Conference on Learning Representa- tions (2024),https://openreview.net/forum?id=di52zR8xgf
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. In: The Twelfth International Conference on Learning Representa- tions (2024),https://openreview.net/forum?id=di52zR8xgf
2024
-
[30]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=DhHIw9Nbl1
Ren, M., Zhang, Y.M., yi chen: Decoupling layout from glyph in online chinese handwriting generation. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=DhHIw9Nbl1
2025
-
[31]
In: Encyclopedia of biometrics, pp
Reynolds, D.: Gaussian mixture models. In: Encyclopedia of biometrics, pp. 827–
-
[32]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conferenceon LearningRepresentations(2021),https://openreview.net/forum? id=St1giarCHLP
2021
-
[33]
In: Proceedings of the 2021 Workshop on Multi-Modal Pre-Training for Multimedia Understanding
Springstein, M., Müller-Budack, E., Ewerth, R.: Unsupervised training data gen- eration of handwritten formulas using generative adversarial networks with self- attention. In: Proceedings of the 2021 Workshop on Multi-Modal Pre-Training for Multimedia Understanding. p. 46–54. MMPT ’21, Association for Computing Machinery, New York, NY, USA (2021).https://...
-
[34]
IEEE Transactions on Image Processing 34, 5228–5240 (2025).https://doi.org/10.1109/TIP.2025.3593974
Tang, L., Chai, T., Zhang, Z., Zhang, M., Wu, X.: PalmDiff: When palmprint gen- eration meets controllable diffusion model. IEEE Transactions on Image Processing 34, 5228–5240 (2025).https://doi.org/10.1109/TIP.2025.3593974
-
[35]
Team, Q.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Team, Z.I.: Z-Image: An efficient image generation foundation model with single- stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, B., Wu, F., Ouyang, L., Gu, Z., Zhang, R., Xia, R., Shi, B., Zhang, B., He, C.: Image over text: Transforming formula recognition evaluation with character detection matching. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19681–19690 (June 2025)
2025
-
[38]
In: Yin, X.C., Karatzas, D., Lopresti, D
Wang, Y., Wei, H., Wang, H., Sun, B.: VMF-Net: Visual-aware multi- representation fusion network for artifact-free handwritten mathematical expres- sions generation. In: Yin, X.C., Karatzas, D., Lopresti, D. (eds.) Document Anal- ysis and Recognition – ICDAR 2025. pp. 257–269. Springer Nature Switzerland, Cham (2026)
2025
-
[39]
In: Yin, X.C., Karatzas, D., Lopresti, D
Wang, Y., Wei, H., Wang, H., Sun, S.: SFRD: Handwritten mathematical ex- pressions generation by spatial-aware feature refinement diffusion. In: Yin, X.C., Karatzas, D., Lopresti, D. (eds.) Document Analysis and Recognition – ICDAR
-
[40]
pp. 414–428. Springer Nature Switzerland, Cham (2026)
2026
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: Convnext v2: Co-designing and scaling convnets with masked autoencoders. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16133–16142 (June 2023) 18 W. Pan et al
2023
-
[42]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
generation: Taming optimization dilemma in latent diffusion models
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15703–15712 (June 2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yuan, Y., Liu, X., Dikubab, W., Liu, H., Ji, Z., Wu, Z., Bai, X.: Syntax-aware network for handwritten mathematical expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4553–4562 (June 2022)
2022
-
[45]
In: III, H.D., Singh, A
Zhang, J., Du, J., Yang, Y., Song, Y.Z., Wei, S., Dai, L.: A tree-structured de- coder for image-to-markup generation. In: III, H.D., Singh, A. (eds.) Proceed- ings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 11076–11085. PMLR (13–18 Jul 2020), https://proceedings.mlr.press/v119/zhang20g.html
2020
-
[46]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Zhao, W., Gao, L.: CoMER: Modeling coverage for transformer-based handwrit- ten mathematical expression recognition. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 392–408. Springer Nature Switzerland, Cham (2022)
2022
-
[47]
In: Lladós, J., Lopresti, D., Uchida, S
Zhao, W., Gao, L., Yan, Z., Peng, S., Du, L., Zhang, Z.: Handwritten mathemati- cal expression recognition with bidirectionally trained transformer. In: Lladós, J., Lopresti, D., Uchida, S. (eds.) Document Analysis and Recognition – ICDAR 2021. pp. 570–584. Springer International Publishing, Cham (2021)
2021
-
[48]
Zhu, J., Zhao, W., Li, Y., Hu, X., Gao, L.: TAMER: Tree-aware transformer for handwritten mathematical expression recognition. Proceedings of the AAAI Conference on Artificial Intelligence39(10), 10950–10958 (Apr 2025).https: //doi.org/10.1609/aaai.v39i10.33190 DiffMath 19 DiffMath: Symbol- and Graph-Aware Latent Diffusion Transformer for Handwritten Math...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.