Pose6DAug: Physically Plausible Multi-view Object Swapping for Robot Data Augmentation
Pith reviewed 2026-06-26 17:21 UTC · model grok-4.3
The pith
Pose6DAug swaps objects in successful robot episodes using 3D meshes and 6D poses to create new training data for vision-language-action policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
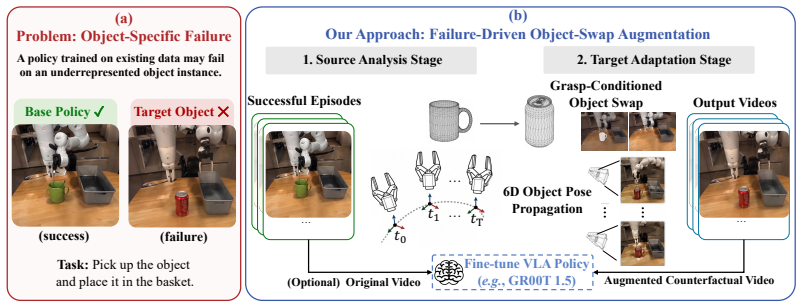
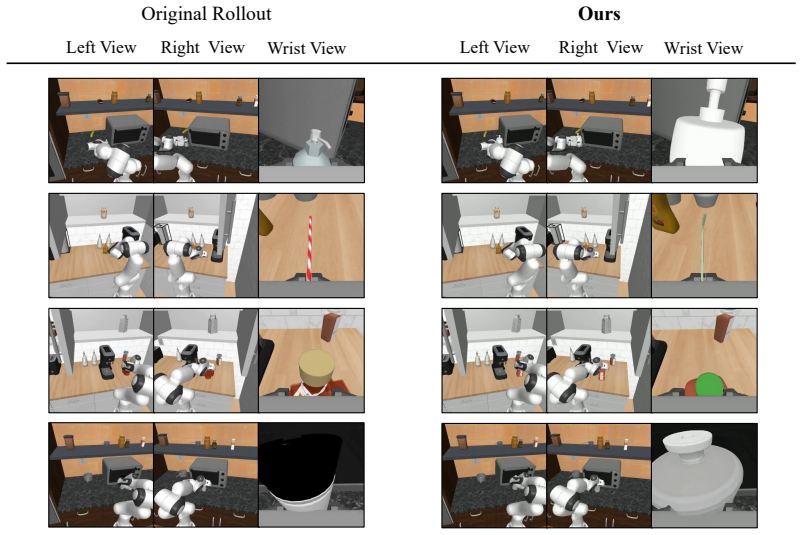
By anchoring the swapped object with an explicit 3D mesh driven by a temporally coherent 6D pose trajectory, the method produces geometrically consistent renderings across all views that preserve physical validity, allowing the augmented data to correct policy failures on novel objects.
What carries the argument
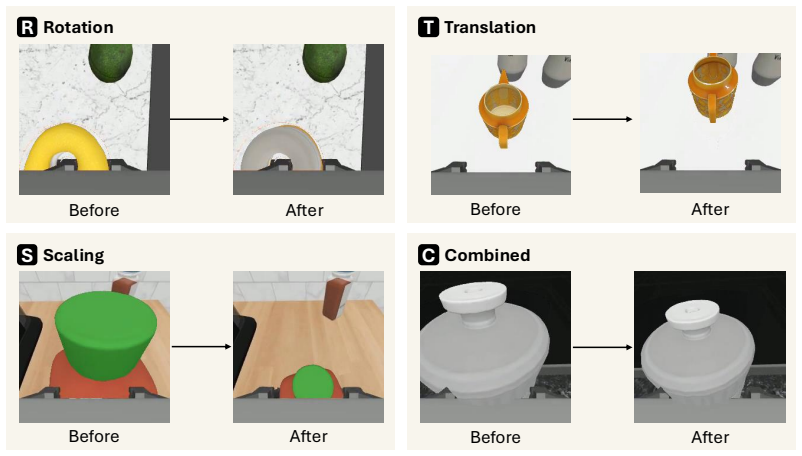
3D object swapping anchored by an explicit mesh and a temporally coherent 6D pose trajectory, which ensures multi-view consistency and physical plausibility while preserving the original action trajectory.
If this is right
- Augmented data can be generated from existing successful episodes without additional teleoperation.
- Fine-tuning on this data improves success rates on novel objects by 16.5% relative to baselines.
- In-distribution performance remains unchanged.
- Naive 2D editing fails due to occlusion and viewpoint issues, but 3D anchoring solves this.
- The approach scales to failure-driven augmentation for out-of-distribution objects.
Where Pith is reading between the lines
- If the method generalizes, it could reduce data collection costs for VLA policies in real-world settings.
- Similar 3D swapping might apply to other robotics tasks like navigation or assembly.
- Testing on a wider range of object geometries could reveal limits of the physical validity assumption.
Load-bearing premise
That swapping the object while keeping the action trajectory and using 3D anchoring produces demonstrations that are physically valid and help the policy learn to handle new objects.
What would settle it
If fine-tuning on the augmented data shows no improvement or a decrease in success rates on novel objects compared to the baseline.
Figures

read the original abstract
Vision-language-action (VLA) policies have shown strong potential for general-purpose manipulation, yet they often fail on novel, out-of-distribution objects whose appearance or geometry deviates from the training distribution. The standard remedy is to collect multi-view teleoperation data for every failure case, but this scales poorly in both cost and time. We introduce Pose6DAug, a failure-driven data augmentation framework that turns a policy's own successful episodes into targeted demonstrations for its failure modes, without any new data collection. Our key insight is that each successful episode already encodes a physically valid action trajectory together with calibrated multi-view observations. By swapping only the manipulated object while preserving this trajectory, we obtain new and physically grounded demonstrations. However, naive 2D video editing breaks multi-view consistency and physical plausibility, particularly under heavy occlusion and egocentric viewpoints. Our method instead operates directly in 3D, anchoring the target object with an explicit mesh driven by a temporally coherent 6D pose trajectory, ensuring geometrically consistent renderings across all camera views. Fine-tuning a VLA on data augmented by our method improves success rates by 16.5% relative to the state-of-the-art baseline on novel objects, while preserving in-distribution performance. These results show that multi-view and physically consistent augmentation is a practical path to scalable VLA generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Pose6DAug, a failure-driven 3D data augmentation method for vision-language-action (VLA) policies. It converts successful robot episodes into targeted demonstrations for novel objects by replacing only the manipulated object mesh while preserving the original action trajectory, anchored by an explicit 3D mesh and temporally coherent 6D pose sequence to ensure multi-view geometric consistency. The central empirical claim is that fine-tuning a VLA on this augmented data yields a 16.5% relative success-rate improvement on novel objects versus the state-of-the-art baseline, without degrading in-distribution performance.
Significance. If the augmented trajectories are physically valid and address the policy's specific failure modes, the method would provide a scalable, low-cost route to improving VLA generalization by recycling existing successful data rather than collecting new teleoperation episodes for every out-of-distribution case.
major comments (2)
- [Abstract] Abstract: the assertion that object swapping while 'preserving this trajectory' yields 'physically grounded demonstrations' is load-bearing for the central claim, yet the manuscript supplies no explicit validation (simulation-based collision checks, grasp-success verification, or force-profile analysis) that the replayed 6D action sequence remains feasible or successful once object geometry, mass distribution, or friction changes.
- [Results] Results section (and abstract): the reported 16.5% relative gain is presented without accompanying information on evaluation trial counts, statistical significance, exact baseline configurations, occlusion-handling metrics, or any quantitative check that the generated demonstrations are free of invalid states (e.g., interpenetrations or unreachable contacts) for the swapped meshes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on physical validity and empirical reporting. We address the two major comments point by point below, indicating planned changes to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that object swapping while 'preserving this trajectory' yields 'physically grounded demonstrations' is load-bearing for the central claim, yet the manuscript supplies no explicit validation (simulation-based collision checks, grasp-success verification, or force-profile analysis) that the replayed 6D action sequence remains feasible or successful once object geometry, mass distribution, or friction changes.
Authors: We agree that the manuscript does not supply explicit post-swap simulation validation such as collision checks or force analysis. The current grounding rests on the fact that the 6D trajectory originates from a successful episode with the original object and is replayed verbatim while only the visual mesh is updated via explicit 3D anchoring. This ensures multi-view geometric consistency for VLA training but does not guarantee dynamic feasibility under altered mass or friction. In revision we will add an explicit limitations paragraph acknowledging this gap and will include any available simulation-based checks if they can be obtained without new data collection. revision: partial
-
Referee: [Results] Results section (and abstract): the reported 16.5% relative gain is presented without accompanying information on evaluation trial counts, statistical significance, exact baseline configurations, occlusion-handling metrics, or any quantitative check that the generated demonstrations are free of invalid states (e.g., interpenetrations or unreachable contacts) for the swapped meshes.
Authors: We will expand the results section and abstract to report the number of evaluation trials per condition, the statistical tests performed, the precise baseline configurations, and any occlusion-handling metrics collected. We will also add a quantitative or qualitative assessment of invalid states (interpenetrations, unreachable contacts) for the generated demonstrations or note their absence as a limitation. revision: yes
Circularity Check
No significant circularity; empirical result stands on its own
full rationale
The paper presents an empirical augmentation pipeline (3D mesh + 6D-pose trajectory object swap) whose claimed benefit is measured by downstream fine-tuning success rates on held-out novel objects. No equations, fitted parameters, or self-citation chains appear in the provided text; the 16.5% relative gain is reported as an experimental outcome rather than a quantity derived by construction from the method's inputs. The central assumption (preserved trajectories remain valid after geometry change) is a modeling choice whose validity is tested externally via policy rollouts, not presupposed by definition or prior self-work. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 1
2023
-
[2]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1
Pith/arXiv arXiv 2024
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 1, 2
Pith/arXiv arXiv 2024
-
[4]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 1
Pith/arXiv arXiv 2025
-
[5]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Nikita Cherniadev Johan Bjorck andFernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You...
2025
-
[6]
Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 1
Pith/arXiv arXiv 2024
-
[7]
Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026
Dongyoung Kim, Huiwon Jang, Myungkyu Koo, Suhyeok Jang, Taeyoung Kim, Beomjun Kim, Byungjun Yoon, Changsung Jang, Daewon Choi, Dongsu Han, et al. Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026. 1
Pith/arXiv arXiv 2026
-
[8]
Jimin Lee, Huiwon Jang, Myungkyu Koo, Jungwoo Park, and Jinwoo Shin. Modular sensory stream for integrating physical feedback in vision-language-action models.arXiv preprint arXiv:2604.23272, 2026. 1
Pith/arXiv arXiv 2026
-
[9]
Jiawen Yu, Hairuo Liu, Qiaojun Yu, Jieji Ren, Ce Hao, Haitong Ding, Guangyu Huang, Guofan Huang, Yan Song, Panpan Cai, Cewu Lu, and Wenqiang Zhang. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation.arXiv preprint arXiv:2505.22159, 2025. 1
arXiv 2025
-
[10]
Vision-aligned latent reasoning for multi-modal large language model
Byungwoo Jeon, Yoonwoo Jeong, Hyunseok Lee, Minsu Cho, and Jinwoo Shin. Vision-aligned latent reasoning for multi-modal large language model. InProceedings of the International Conference on Machine Learning (ICML). PMLR, 2026. 1
2026
-
[11]
Zhuo Li, Junjia Liu, Zhipeng Dong, Tao Teng, Quentin Rouxel, Darwin Caldwell, and Fei Chen. To- wards deploying vla without fine-tuning: Plug-and-play inference-time vla policy steering via embodied evolutionary diffusion.IEEE Robotics and Automation Letters, 11(5):6234–6241, 2026. 1 10
2026
-
[12]
Refined policy distillation: From vla generalists to rl experts
Tobias Jülg, Wolfram Burgard, and Florian Walter. Refined policy distillation: From vla generalists to rl experts. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11677–11684. IEEE, 2025. 1
2025
-
[13]
Xueyang Zhou, Yangming Xu, Guiyao Tie, Yongchao Chen, Guowen Zhang, Duanfeng Chu, Pan Zhou, and Lichao Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization, 2025. URLhttps://arxiv.org/abs/2510.03827. 1
Pith/arXiv arXiv 2025
-
[14]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In Jie Tan, Marc Toussaint, and Kourosh Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Lea...
-
[15]
1, 2, 3, 4, 6, 7, 8, 13
PMLR, 06–09 Nov 2023. 1, 2, 3, 4, 6, 7, 8, 13
2023
-
[16]
Softmim- icgen: A data generation system for scalable robot learning in deformable object manipulation
Masoud Moghani, Mahdi Azizian, Animesh Garg, Yuke Zhu, Sean Huver, and Ajay Mandlekar. Softmim- icgen: A data generation system for scalable robot learning in deformable object manipulation. In2026 IEEE International Conference on Robotics and Automation (ICRA), 2026. 1, 3
2026
-
[17]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17191–17202, October 2025. 2, 3, 6, 7, 8, 13
2025
-
[18]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2
Pith/arXiv arXiv 2025
-
[19]
Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
-
[20]
V oid: Video object and interaction deletion.arXiv preprint arXiv:2604.02296, 2026
Saman Motamed, William Harvey, Benjamin Klein, Luc Van Gool, Zhuoning Yuan, and Ta-Ying Cheng. V oid: Video object and interaction deletion.arXiv preprint arXiv:2604.02296, 2026. 2, 5
arXiv 2026
-
[21]
Liu Liu, Xiaofeng Wang, Guosheng Zhao, Keyu Li, Wenkang Qin, Jiagang Zhu, Jiaxiong Qiu, Zheng Zhu, Guan Huang, and Zhizhong Su. Robotransfer: Geometry-consistent video diffusion for robotic visual policy transfer.arXiv preprint arXiv:2505.23171, 2025. 2
arXiv 2025
-
[22]
Sam 3d: 3dfy anything in images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7220–7232, 2026. 2, 4
2026
-
[23]
Soroush Nasiriany, Sepehr Nasiriany, Abhiram Maddukuri, and Yuke Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots.arXiv preprint arXiv:2603.04356,
-
[24]
Scaling robot learning with semantically imagined experience
Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Jodilyn Peralta, Brian Ichter, et al. Scaling robot learning with semantically imagined experience. arXiv preprint arXiv:2302.11550, 2023. 3
Pith/arXiv arXiv 2023
-
[25]
Zoey Chen, Sho Kiami, Abhishek Gupta, and Vikash Kumar. Genaug: Retargeting behaviors to unseen situations via generative augmentation.arXiv preprint arXiv:2302.06671, 2023. 3
arXiv 2023
-
[26]
Libero: Benchmark- ing knowledge transfer for lifelong robot learning, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmark- ing knowledge transfer for lifelong robot learning, 2023. URL https://arxiv.org/abs/2306.03310. 5
Pith/arXiv arXiv 2023
-
[27]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024. 5
2024
-
[28]
Bundletrack: 6d pose tracking for novel objects without instance or category-level 3d models
Bowen Wen and Kostas Bekris. Bundletrack: 6d pose tracking for novel objects without instance or category-level 3d models. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8067–8074. IEEE, 2021. 5
2021
-
[29]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153,
-
[30]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 7 12 A Appendix A.1 Full Evaluation on All Episodes Success Rate (%) Method ID Object OOD Object Avg. Base Policy 52.2 36.9 47.2 MimicGen [14] 52.2 33.3 46.0 V ACE [16] 51.2 40.4 47.7 Pose6DAug (Ours) 52.7 42.9 49.5 Table 3: Overall success rate ...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.