N-Version Programming with Coding Agents
Pith reviewed 2026-06-26 16:25 UTC · model grok-4.3
The pith
Diversity from AI coding agents reduces mean failures in three-version units from 387 to 131.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
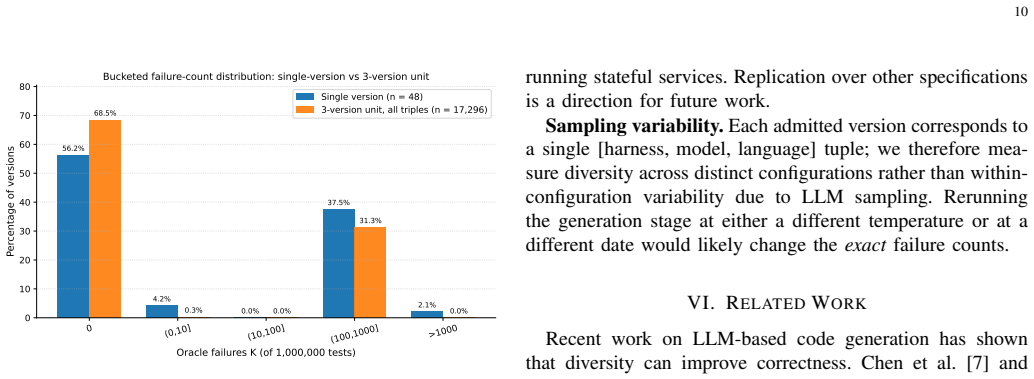
Although agent-generated implementations exhibit substantial common-mode failures traceable to ambiguities in the specification, majority voting across three-version units reduces the mean failure count from 387.44 to 130.99, with 11,844 units showing zero observed failures across the one-million-input campaign.
What carries the argument
Three-version majority-voting units assembled from outputs of diverse AI coding agents
If this is right
- Majority voting can mitigate individual agent errors even when some failures are shared.
- Diversity in agents, models, and languages contributes to fewer co-occurring failures than single versions.
- A large fraction of possible agent combinations can produce units with no observed failures on the tested inputs.
- N-version programming regains relevance as an engineering technique when versions are generated automatically.
Where Pith is reading between the lines
- Selection of agent triples could be optimized by measuring pairwise failure overlap before deployment.
- The same pattern may appear in other safety-critical domains where specifications contain hard-to-interpret sections.
- Specification clarity remains a bottleneck that diversity alone does not remove.
- Automated N-version construction could become routine for code that must meet high reliability targets.
Load-bearing premise
The 1,000,000 randomized test inputs sufficiently exercise the Launch Interceptor Program Specification and the shared oracle correctly classifies all behaviors as pass or fail.
What would settle it
Re-running the same three-version units on a fresh set of test inputs drawn from the same specification but outside the original million-input campaign and finding no drop in mean failures.
Figures



read the original abstract
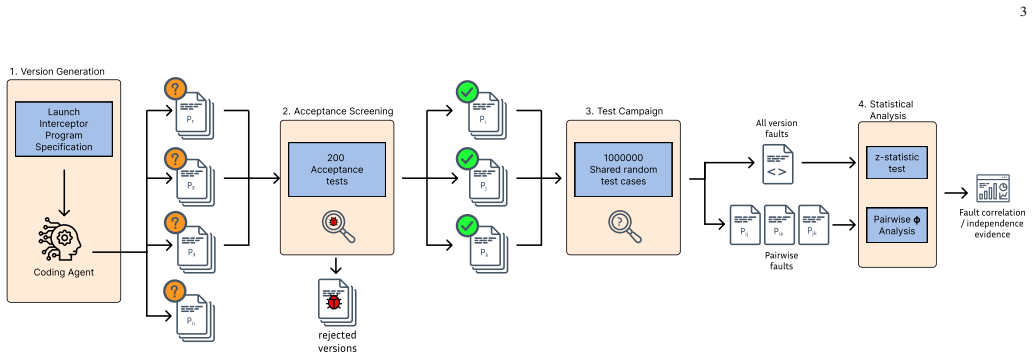
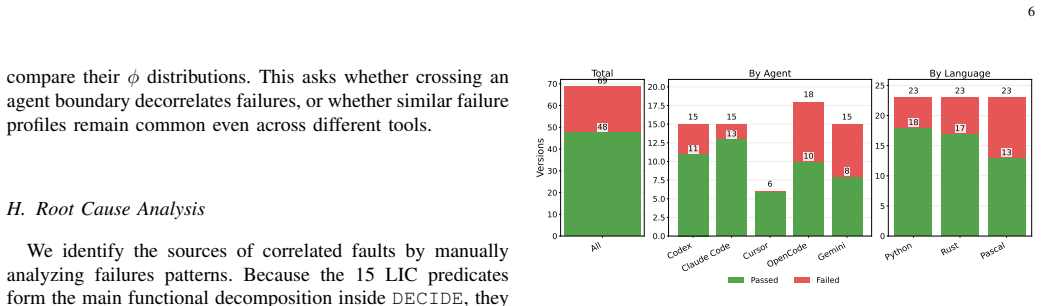
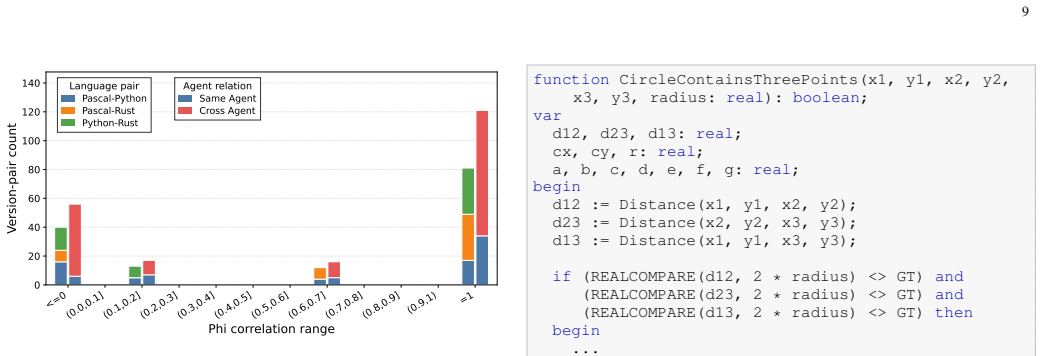
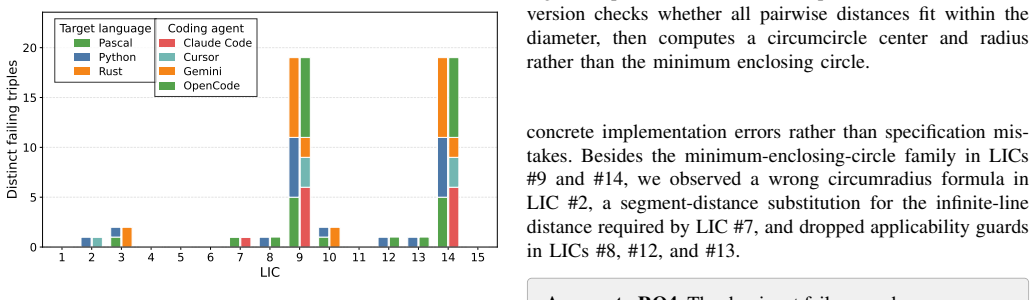
This paper revisits the classical concept on N-version programming in the setting of contemporary AI coding agents. Revisiting the seminal Knight-Leveson experiment, we study whether diversity across agent systems, models, and implementation languages creates diverse failure modes. Using the Knight-Leveson's, Launch Interceptor Program Specification, we evaluate 48 agent-generated implementations on a shared oracle and a campaign of 1,000,000 randomized test inputs. The results show substantial common-mode failure, along the findings of Knight-Leveson. Further analysis that many of those co-occuring failures can be traced to where is specification is particularly hard or ambiguous. We also demonstrate that diversity from coding agents provides practical benefit: across majority voting three-version units, the mean failure count drops from 387.44 for single versions to 130.99 for triples, and 11,844 N-version units exhibit zero observed failures. Our original results is the strongest evidence to date that N-Version Programming with coding agents is a useful engineering strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript revisits classical N-version programming using contemporary AI coding agents on the Knight-Leveson Launch Interceptor Program specification. It generates 48 agent-produced implementations across models and languages, evaluates them against a shared oracle on 1,000,000 randomized test inputs, reports substantial common-mode failures traceable to specification ambiguities, and claims that majority voting in three-version units reduces mean failure count from 387.44 to 130.99 while yielding 11,844 zero-failure units, concluding this constitutes the strongest evidence that NVP with coding agents is a useful engineering strategy.
Significance. If the empirical claims hold after addressing test validity, the work would be significant for software engineering: it supplies large-scale data (48 versions, 1M tests) extending the 1980s Knight-Leveson findings to AI-generated code, quantifies both the persistence of common-mode failures and the practical benefit of agent-induced diversity, and offers a concrete engineering strategy for improving reliability of LLM-produced software.
major comments (2)
- [Abstract] Abstract: The headline claims of a drop in mean failures from 387.44 to 130.99 and 11,844 zero-failure three-version units are load-bearing for the central conclusion. These counts rest on the unverified assumption that the 1,000,000 randomized inputs exercise all relevant behaviors of the Launch Interceptor Program (including the ambiguous regions identified in the post-hoc analysis) and that the shared oracle correctly classifies every outcome; no coverage metrics, comparison against the original Knight-Leveson test suite, or independent oracle validation are referenced.
- [Abstract] Abstract / Results: The reported mean failure counts are given as point values (387.44 and 130.99) without error bars, confidence intervals, or any statistical test of the observed reduction, undermining the ability to assess whether the diversity benefit is robust or an artifact of the particular test distribution.
minor comments (2)
- [Abstract] Abstract: grammatical error — 'Our original results is the strongest evidence' should read 'Our results are the strongest evidence'.
- [Abstract] Abstract: phrasing error — 'where is specification is particularly hard or ambiguous' should read 'where the specification is particularly hard or ambiguous'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on test validity and statistical reporting. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of a drop in mean failures from 387.44 to 130.99 and 11,844 zero-failure three-version units are load-bearing for the central conclusion. These counts rest on the unverified assumption that the 1,000,000 randomized inputs exercise all relevant behaviors of the Launch Interceptor Program (including the ambiguous regions identified in the post-hoc analysis) and that the shared oracle correctly classifies every outcome; no coverage metrics, comparison against the original Knight-Leveson test suite, or independent oracle validation are referenced.
Authors: The comment correctly identifies that coverage metrics, explicit comparison to the original Knight-Leveson test suite, and independent oracle validation are not referenced in the manuscript. The 1M inputs were drawn uniformly from the specification-defined domains (matching the random-test component of the 1986 study), and the post-hoc failure analysis shows that ambiguous regions were exercised. However, formal coverage metrics and a side-by-side comparison with the original test vectors are absent. We will add a subsection on input generation and coverage considerations plus a direct methodological comparison to Knight-Leveson; we will also state the limitation that the oracle, while derived from the published specification, was not independently re-validated by a third party. revision: partial
-
Referee: [Abstract] Abstract / Results: The reported mean failure counts are given as point values (387.44 and 130.99) without error bars, confidence intervals, or any statistical test of the observed reduction, undermining the ability to assess whether the diversity benefit is robust or an artifact of the particular test distribution.
Authors: The observation is accurate: the manuscript reports only point estimates. With 1M tests per version the sampling variability is low, yet we agree that readers cannot judge robustness without uncertainty quantification. We will compute and report bootstrap confidence intervals on the per-version failure counts together with a paired statistical test of the reduction between single versions and triples, and we will update both the abstract and results section accordingly. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper reports failure counts obtained by executing 48 agent-generated implementations on 1,000,000 randomized inputs against a shared oracle for the Launch Interceptor Program. These counts (e.g., mean failures dropping from 387.44 to 130.99 under majority voting) are produced by the experimental procedure itself and do not reduce to any fitted parameter, self-definition, or self-citation chain. The derivation is the test campaign, which remains externally falsifiable by the input distribution and oracle. No equations or steps in the provided material exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The shared oracle correctly classifies all program behaviors on the 1M test inputs.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Claude Code: Agentic Coding in the Terminal. https://docs.anthropic.com/en/docs/ claude-code. Accessed: 2026
2024
-
[2]
Anysphere Inc. 2024. Cursor: The AI Code Editor. https: //www.cursor.com. Accessed: 2026
2024
-
[3]
Algirdas Avizienis. 1985. The N-Version Approach to Fault-Tolerant Software.IEEE Transactions on Software Engineering11, 12 (1985), 1491–1501
1985
-
[4]
Peter G. Bishop. 1995. Review of Software Design Diversity. InSoftware Fault Tolerance, Michael R. Lyu (Ed.). John Wiley & Sons, New York, NY , 211–229
1995
-
[5]
Brilliant, John C
Susan S. Brilliant, John C. Knight, and Nancy G. Leve- son. 1990. Analysis of Faults in an N-Version Software Experiment.IEEE Transactions on Software Engineering 16, 2 (1990), 238–247
1990
-
[6]
Liming Chen and Algirdas Avizienis. 1978. N-Version Programming: A Fault-Tolerance Approach to Reliability of Software Operation. InDigest of Papers, Eighth Annual International Symposium on Fault-Tolerant Com- puting (FTCS-8). Toulouse, France, 3–9
1978
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pond ´e de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[8]
Janet R. Dunham and John L. Pierce. 1986.An Ex- periment in Software Reliability. NASA Contractor Re- port NASA-CR-172553. NASA Langley Research Cen- ter, Hampton, V A. https://ntrs.nasa.gov/api/citations/ 19860020075/downloads/19860020075.pdf Prepared by Research Triangle Institute under Contract NAS1-16489; originally dated March 1985, revised May 1986
arXiv 1986
-
[9]
Eckhardt and Larry D
David E. Eckhardt and Larry D. Lee. 1985. A Theoretical Basis for the Analysis of Multiversion Software Subject to Coincident Errors.IEEE Transactions on Software Engineering11, 12 (1985), 1511–1517
1985
-
[10]
Google DeepMind. 2024. Gemini CLI: An Open-Source AI Agent. https://github.com/google-gemini/gemini-cli. Accessed: 2026
2024
-
[11]
Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu
Ahmed E. Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu. 2025. Agentic Software Engineering: Foundational Pillars and a Research Roadmap. arXiv:2509.06216 [cs.SE] https: //arxiv.org/abs/2509.06216
Pith/arXiv arXiv 2025
-
[12]
Les Hatton. 1997. N-Version Design Versus One Good Version.IEEE Software14, 6 (1997), 71–76
1997
-
[13]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
-
[14]
InProceedings of the 12th International Conference on Learning Representations (ICLR)
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria
-
[15]
Marcus Kessel and Colin Atkinson. 2024. N-version as- sessment and enhancement of generative AI: differential GAI.IEEE Software42, 2 (2024), 76–83
2024
-
[16]
Knight and Nancy G
John C. Knight and Nancy G. Leveson. 1986. An Exper- imental Evaluation of the Assumption of Independence in Multiversion Programming.IEEE Transactions on Software Engineering12, 1 (1986), 96–109
1986
-
[17]
Abhishek Kodati, Foutse Khomh, and Ashkan Sami. [n. d.]. MAC: Multi-Agent LLM Coder is All You Need. Available at SSRN 5887028([n. d.])
-
[18]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R ´emi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-Level Code Generation with AlphaCode. Science378, 6624 (2022), 1092–1097
2022
-
[19]
Bev Littlewood and Douglas R. Miller. 1989. Conceptual Modeling of Coincident Failures in Multiversion Soft- ware.IEEE Transactions on Software Engineering15, 12 (1989), 1596–1614
1989
-
[20]
Dimakis, Sylvia Ratnasamy, Matei Zaharia, Aditya Parameswaran, and Ion Stoica
Shu Liu, Alexander Krentsel, Shubham Agarwal, Mert Cemri, Ziming Mao, Soujanya Ponnapalli, Alexandros G. Dimakis, Sylvia Ratnasamy, Matei Zaharia, Aditya Parameswaran, and Ion Stoica. 2026. The Time is Here for Just-in-Time Systems: Challenges and Opportuni- ties. arXiv:2605.24096 [cs.DB] https://arxiv.org/abs/ 2605.24096
Pith/arXiv arXiv 2026
-
[21]
Tarek Mahmud, Bin Duan, Corina S. P ˘as˘areanu, and Guowei Yang. 2025. Enhancing LLM Code Generation with Ensembles: A Similarity-Based Selection Approach. arXiv preprint arXiv:2503.15838(2025)
arXiv 2025
-
[22]
OpenCode Contributors. 2024. OpenCode: The AI Cod- ing Agent Built for the Terminal. https://opencode.ai. Accessed: 2026
2024
-
[23]
Javier Ron, Diogo Gaspar, Javier Cabrera-Arteaga, Benoit Baudry, and Martin Monperrus. 2025. Galapagos: Automated N-Version Programming with LLMs.ACM Transactions on Software Engineering and Methodology (2025). doi:10.1145/3785363
-
[24]
Thomas Valentin, Ardi Madadi, Gaetano Sapia, and Marcel B ¨ohme. 2025. Incoherence as Oracle-less Measure of Error in LLM-Based Code Generation. arXiv:2507.00057 [cs.PL] https://arxiv.org/abs/2507. 12 00057
arXiv 2025
-
[25]
Chi, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, and Denny Zhou. 2023. Self-Consistency Im- proves Chain of Thought Reasoning in Language Mod- els. InProceedings of the 11th International Conference on Learning Representations (ICLR). OpenReview.net
2023
-
[26]
Junjun Zheng, Hiroyuki Okamura, and Tadashi Dohi
-
[27]
InInternational Symposium on Software Fault Prevention, Verification, and Validation
Can Generative AI Enhance the Effectiveness of N- Version Programming?. InInternational Symposium on Software Fault Prevention, Verification, and Validation. Springer, 1–16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.