Randomized Sketching is Robust to Low-Precision Rounding on GPUs
Pith reviewed 2026-06-26 14:53 UTC · model grok-4.3
The pith
SparseStack embedding quality stays the same under deterministic, stochastic, or dithered FP16 rounding on GPUs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
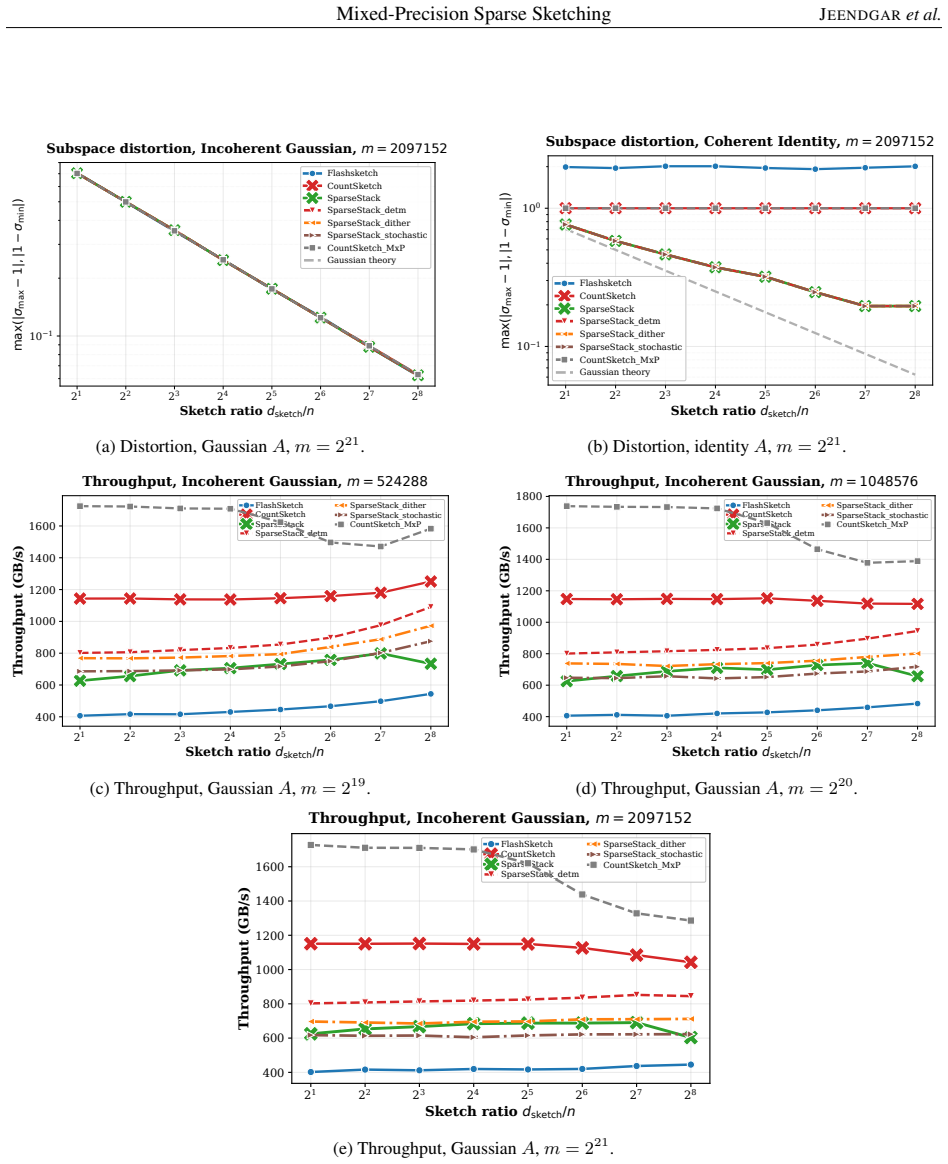
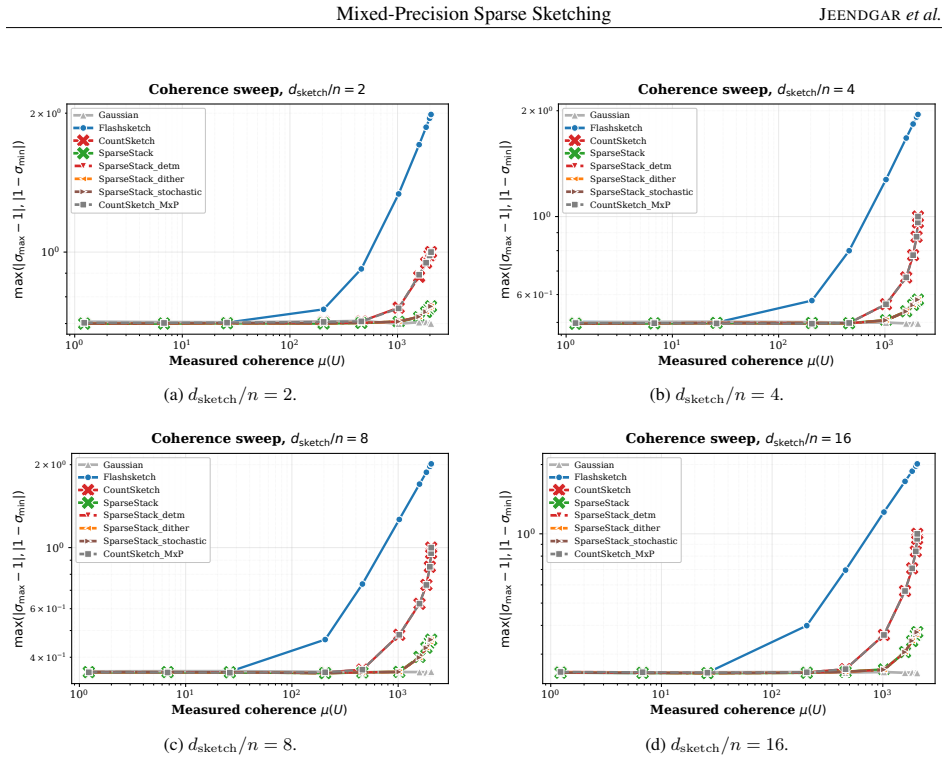
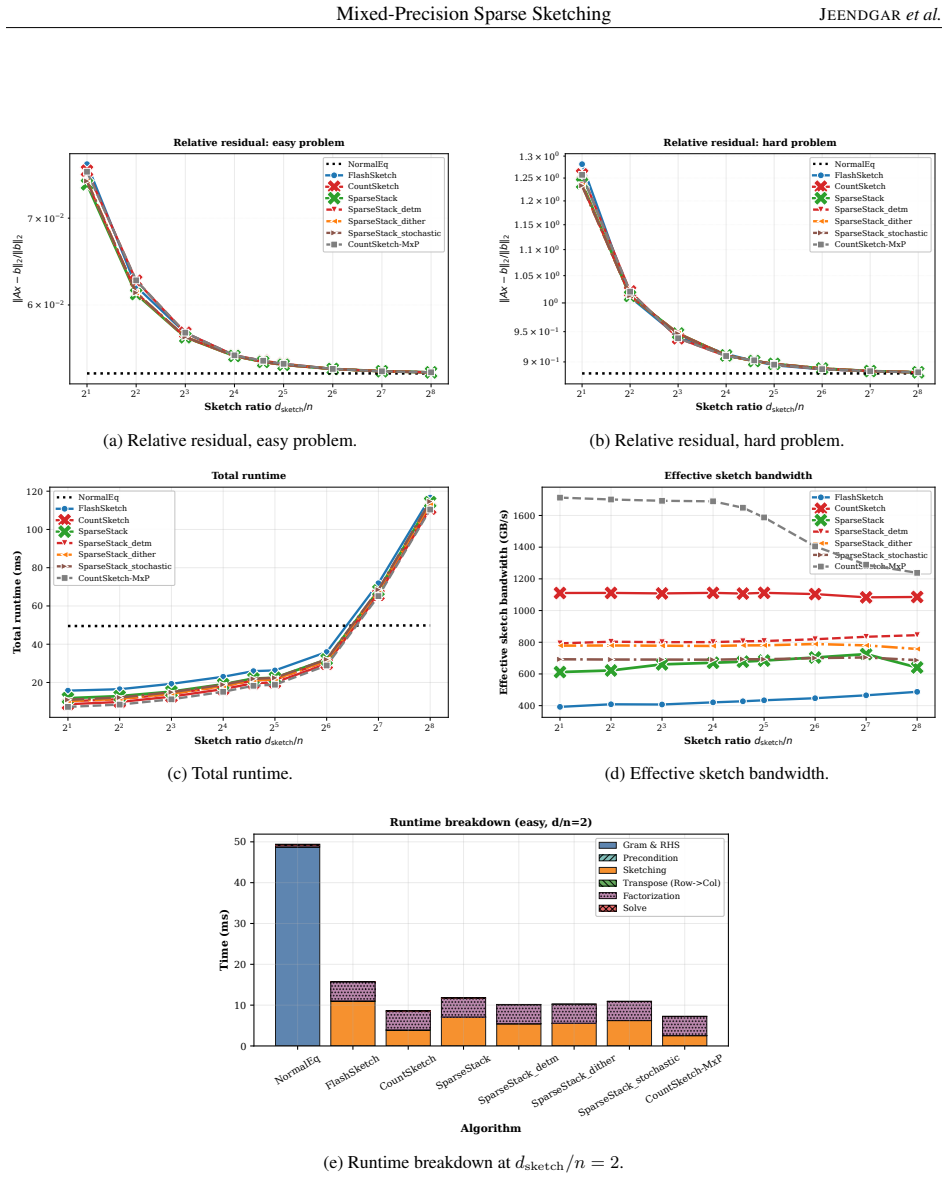
For the tested regimes, SparseStack embedding quality is insensitive to the FP16 rounding rule. Deterministic, stochastic, and dithered rounding FP16 SparseStack produce nearly identical subspace distortion and sketch-and-solve least-squares accuracy across incoherent, coherent, and adversarial test problems. The dominant accuracy factor is the sketch distribution rather than the quantization rule.
What carries the argument
SparseStack, a generalization of the GPU CountSketch kernel that places multiple nonzeros per column to reduce subspace distortion on coherent inputs, implemented with mixed-precision FP16 accumulation under three rounding rules.
If this is right
- Deterministic rounding supplies the best performance-accuracy tradeoff among the FP16 SparseStack variants because it has the lowest overhead.
- SparseStack variants improve distortion on coherent inputs while CountSketch and FlashSketch do not.
- All tested methods behave similarly on incoherent inputs, so the choice of sketch distribution matters less there.
- Mixed-precision sketching remains viable on GPUs when the dominant cost is memory traffic rather than arithmetic precision.
Where Pith is reading between the lines
- GPU hardware designers could safely expose only deterministic rounding for sketching kernels without accuracy penalty in similar regimes.
- The same insensitivity may allow even lower-precision formats such as FP8 if memory traffic continues to dominate.
- Production code can adopt the fastest rounding rule for SparseStack without separate validation for each rounding mode on comparable inputs.
Load-bearing premise
The selected test problems and regimes (incoherent, coherent, adversarial inputs) are representative of practical use cases for sketching.
What would settle it
A workload with substantially different coherence or scale in which deterministic, stochastic, and dithered FP16 SparseStack produce measurably different subspace distortion or least-squares solve accuracy.
Figures
read the original abstract
Randomized sketching is a core primitive in randomized numerical linear algebra. On modern hardware architectures, in particular on GPUs, the performance of sparse sketches is limited by memory traffic and atomic accumulation rather than floating-point throughput. This makes sketching a natural target for mixed precision, provided that low-precision accumulation does not degrade the embedding quality. We study mixed-precision GPU implementations of sparse oblivious subspace embeddings, focusing on a SparseStack generalization of the GPU CountSketch kernel of Higgins et al. SparseStack improves embedding quality relative to CountSketch on coherent inputs, but its additional nonzeros per column increase atomic-update contention and reduce throughput. We therefore implement FP16 SparseStack variants using deterministic round-to-nearest, exact stochastic rounding, and dithered rounding, and compare them with FP32 SparseStack, CountSketch, mixed-precision CountSketch, and FlashSketch. Our main empirical finding is that, for the tested regimes, SparseStack embedding quality is insensitive to the FP16 rounding rule. Deterministic, stochastic, and dithered rounding FP16 SparseStack produce nearly identical subspace distortion and sketch-and-solve least-squares accuracy across incoherent, coherent, and adversarial test problems. The dominant accuracy factor is the sketch distribution rather than the quantization rule: SparseStack variants substantially improve distortion on coherent inputs, while all methods behave similarly on incoherent inputs. Since deterministic rounding has the lowest overhead, it provides the best performance--accuracy tradeoff among the FP16 SparseStack variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that randomized sketching via a SparseStack generalization of the GPU CountSketch is robust to FP16 rounding on GPUs. For the tested regimes (incoherent, coherent, and adversarial inputs), FP16 SparseStack with deterministic round-to-nearest, exact stochastic rounding, and dithered rounding produce nearly identical subspace distortion and sketch-and-solve least-squares accuracy; the sketch distribution dominates over the quantization rule, with SparseStack improving quality on coherent inputs relative to CountSketch while all methods perform similarly on incoherent inputs. Deterministic rounding is identified as providing the best performance-accuracy tradeoff due to lowest overhead.
Significance. If the scoped empirical observation holds, the result is significant for practical GPU implementations of randomized numerical linear algebra, as it shows that low-precision deterministic rounding suffices for SparseStack without degrading embedding quality, allowing focus on memory-traffic optimizations rather than rounding overhead. The study provides a clear comparison across multiple input classes and methods, supporting the claim that sketch distribution is the dominant accuracy factor.
major comments (1)
- [Abstract and Experiments] Abstract and experimental results: the claim that deterministic, stochastic, and dithered FP16 SparseStack produce 'nearly identical' subspace distortion and accuracy is load-bearing for the insensitivity conclusion, yet the manuscript provides no details on the number of independent trials, sample sizes, variance measures, or statistical significance tests used to establish consistency across the input classes.
minor comments (2)
- [Experimental Setup] The description of test problems (incoherent/coherent/adversarial) should include explicit parameters or generation procedures to allow readers to assess representativeness of the tested regimes.
- [Implementation and Results] Hardware configuration details (specific GPU model, memory bandwidth, CUDA version) are referenced only generally; adding them would strengthen reproducibility claims for the throughput comparisons.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive comment on the experimental reporting. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and experimental results: the claim that deterministic, stochastic, and dithered FP16 SparseStack produce 'nearly identical' subspace distortion and accuracy is load-bearing for the insensitivity conclusion, yet the manuscript provides no details on the number of independent trials, sample sizes, variance measures, or statistical significance tests used to establish consistency across the input classes.
Authors: We agree that the manuscript should explicitly report the number of independent trials, sample sizes, variance measures, and any statistical procedures used to support the claim of near-identical behavior. The current version does not provide these details. In the revised manuscript we will add a new paragraph in the Experiments section that states: the number of independent trials run for each (sketch, input class, rounding mode) configuration; the matrix dimensions and number of right-hand sides used to compute the reported distortion and least-squares metrics; how variance is visualized (error bars or shaded regions); and that no formal hypothesis tests were performed because the observed differences between rounding modes were smaller than the run-to-run variation for every input class examined. These additions will make the empirical support for the insensitivity conclusion fully reproducible and transparent. revision: yes
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper presents an empirical comparison of FP16 rounding rules for SparseStack sketching on GPUs, measuring subspace distortion and sketch-and-solve accuracy across test regimes. No derivations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claim is explicitly scoped to 'the tested regimes' and rests on direct experimental observation rather than any reduction to prior quantities by construction. This is the most common honest finding for a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The incoherent, coherent, and adversarial test problems sufficiently represent practical sketching workloads.
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2002.01387. Tamas Sarlos. Improved approximation algorithms for large matrices via random projections. In2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06), pages 143–152,
arXiv 2002
-
[2]
doi:10.1109/FOCS.2006.37. David P. Woodruff. Sketching as a tool for numerical linear algebra.CoRR, abs/1411.4357,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/focs.2006.37 2006
-
[3]
Moses Charikar, Kevin Chen, and Martin Farach-Colton
URL http: //arxiv.org/abs/1411.4357. Moses Charikar, Kevin Chen, and Martin Farach-Colton. Finding frequent items in data streams.Theoretical Computer Science, 312(1):3–15,
-
[4]
Finding frequent items in data streams.Theoretical Computer Science, 312(1):3–15, 2004
ISSN 0304-3975. doi:https://doi.org/10.1016/S0304-3975(03)00400-6. URL https://www.sciencedirect.com/science/article/pii/S0304397503004006. Automata, Languages and Programming. Shabarish Chenakkod, Michał Derezi´nski, and Xiaoyu Dong. Optimal subspace embeddings: Resolving nelson-nguyen conjecture up to sub-polylogarithmic factors,
-
[5]
URLhttps://arxiv.org/abs/2508.14234. Chris Camaño, Ethan N. Epperly, Raphael A. Meyer, and Joel A. Tropp. Faster linear algebra algorithms with structured random matrices,
-
[6]
13 Mixed-Precision Sparse SketchingJEENDGARet al
URLhttps://arxiv.org/abs/2508.21189. 13 Mixed-Precision Sparse SketchingJEENDGARet al. Tyler Chen.Randomized Numerical Linear Algebra with Examples
-
[7]
Riley Murray, James Demmel, Michael W
URL https://arxiv.org/abs/2508.14209. Riley Murray, James Demmel, Michael W. Mahoney, N. Benjamin Erichson, Maksim Melnichenko, Osman Asif Malik, Laura Grigori, Piotr Luszczek, Michał Derezi´nski, Miles E. Lopes, Tianyu Liang, Hengrui Luo, and Jack Dongarra. Randomized numerical linear algebra : A perspective on the field with an eye to software,
-
[8]
URL https://arxiv.org/abs/2302.11474. Xiangrui Meng and Michael W. Mahoney. Low-distortion subspace embeddings in input-sparsity time and applications to robust linear regression,
-
[9]
URLhttps://arxiv.org/abs/1210.3135. Nicholas J. Higham. What is stochastic rounding? Nicholas Higham (blog), July
-
[10]
com/2020/07/07/what-is-stochastic-rounding/
URL https://nhigham. com/2020/07/07/what-is-stochastic-rounding/. Michael P. Connolly, Nicholas J. Higham, and Theo Mary. Stochastic rounding and its probabilistic backward error analysis.SIAM Journal on Scientific Computing, 43(1):A566–A585,
2020
-
[11]
URL https://doi.org/10.1137/20M1334796
doi:10.1137/20M1334796. URL https://doi.org/10.1137/20M1334796. Stanley Lipshitz, Rob Wannamaker, and John Vanderkooy. Quantization and dither: A theoretical survey.Journal of the Audio Engineering Society, 40:355–374, 05
-
[12]
Tyler Chen, Pradeep Niroula, Archan Ray, Pragna Subrahmanya, Marco Pistoia, and Niraj Kumar
URLhttps://arxiv.org/abs/2602.06071. Tyler Chen, Pradeep Niroula, Archan Ray, Pragna Subrahmanya, Marco Pistoia, and Niraj Kumar. Gpu-parallelizable randomized sketch-and-precondition for linear regression using sparse sign sketches,
-
[13]
URL https://arxiv. org/abs/2506.03070. Michael B. Cohen.Nearly Tight Oblivious Subspace Embeddings by Trace Inequalities, pages 278–287. doi:10.1137/1.9781611974331.ch21. URL https://epubs.siam.org/doi/abs/10.1137/1.9781611974331. ch21. Pingbang Hu, Joseph Melkonian, Weijing Tang, Han Zhao, and Jiaqi W. Ma. Grass: Scalable data attribution with gradient s...
-
[14]
Azzam Haidar, Harun Bayraktar, Stanimire Tomov, Jack Dongarra, and Nicholas J
URLhttps://arxiv.org/abs/2505.18976. Azzam Haidar, Harun Bayraktar, Stanimire Tomov, Jack Dongarra, and Nicholas J. Higham. Mixed-precision iterative refinement using tensor cores on gpus to accelerate solution of linear systems.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 476(2243):20200110, 11
-
[15]
ISSN 1364-5021. doi:10.1098/rspa.2020.0110. URLhttps://doi.org/10.1098/rspa.2020.0110. Erin Carson and Nicholas J. Higham. Accelerating the solution of linear systems by iterative refinement in three precisions.SIAM Journal on Scientific Computing, 40(2):A817–A847,
-
[16]
doi:10.1137/17M1140819. URL https://doi.org/10.1137/17M1140819. Nicholas J. Higham, Srikara Pranesh, and Mawussi Zounon. Squeezing a matrix into half precision, with an application to solving linear systems.SIAM Journal on Scientific Computing, 41(4):A2536–A2551,
-
[17]
URLhttps://doi.org/10.1137/18M1229511
doi:10.1137/18M1229511. URLhttps://doi.org/10.1137/18M1229511. Jack Dongarra and Piotr Luszczek. Hpl-mxp benchmark: Mixed-precision algorithms, iterative refinement, and scalable data generation.The International Journal of High Performance Computing Applications, 40(1):52–62,
-
[18]
ISSN 1741-2846. doi:10.1177/10943420251382476. URLhttp://dx.doi.org/10.1177/10943420251382476. Erin Carson and Ieva Daužickait ˙e. Single-pass nyström approximation in mixed precision,
-
[19]
URL https: //arxiv.org/abs/2205.13355. Hartwig Anzt, Terry Cojean, Goran Flegar, Fritz Göbel, Thomas Grützmacher, Pratik Nayak, Tobias Ribizel, Yuh- siang Mike Tsai, and Enrique S. Quintana-Ortí. Ginkgo: A Modern Linear Operator Algebra Framework for High Performance Computing.ACM Transactions on Mathematical Software, 48(1):2:1–2:33, February
-
[20]
ISSN 0098-3500. doi:10.1145/3480935. URLhttps://doi.org/10.1145/3480935. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.