Shifting-based Optimizable Linear Relaxations for General Activation Functions
Pith reviewed 2026-06-26 17:50 UTC · model grok-4.3
The pith
SLiR generates sound linear relaxations for arbitrary activation functions from only a Lipschitz constant or critical points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SLiR parameterizes relaxations by their slope and computes the corresponding offset via a shifting procedure that ensures sound upper and lower bounds over the input domain, enabling efficient optimization while maintaining correctness for any activation function given only a Lipschitz constant or a set of critical points.
What carries the argument
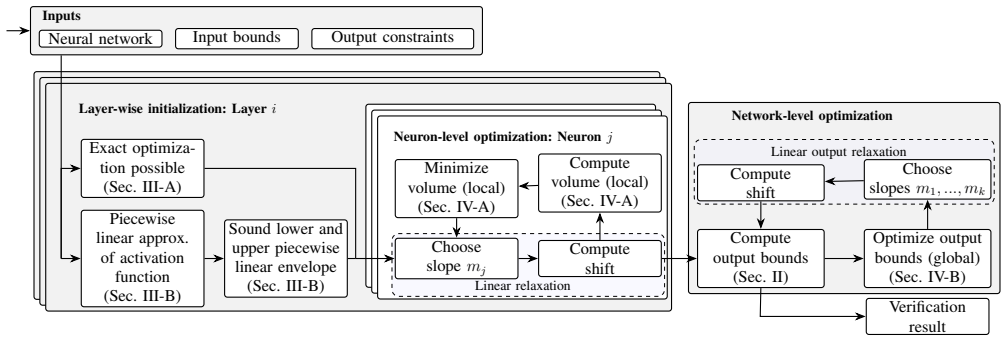
Shifting procedure that, for a chosen slope, finds the offset producing the tightest sound linear bounds valid over the entire input interval.
If this is right
- Verification tools can handle a wide range of practical activation functions without per-function manual design.
- The produced relaxations remain tight enough to support efficient optimization.
- Networks using previously unsupported activations become verifiable.
- Up to 7.8 times more verification properties succeed compared with prior state-of-the-art relaxations.
Where Pith is reading between the lines
- Existing bound-propagation verifiers could adopt the shifting step to expand their supported activations automatically.
- The slope-parameterization idea may combine with interval or abstract-domain methods to produce hybrid bounds.
- Empirical tests on activation functions with discontinuous derivatives would reveal where the Lipschitz assumption begins to lose tightness.
Load-bearing premise
The shifting procedure, given only a Lipschitz constant or critical points, always yields sound upper and lower linear bounds that remain valid over the entire input domain for any activation function.
What would settle it
An activation function and input interval where the linear upper or lower bound produced by the shifting procedure is violated at some point despite using the supplied Lipschitz constant or critical points.
Figures


read the original abstract
The use of neural networks (NNs) is rapidly increasing, including in safety- and security-critical domains. To provide formal guarantees about NN behavior, many verification methods rely on optimizable linear relaxations of activation functions. However, existing techniques depend on hand-crafted relaxations for each activation function. Extension to state-of-the-art activation functions therefore requires substantial manual effort. In contrast, our approach SLiR (Shifting-based Linear Relaxations) is broadly applicable, requiring only a Lipschitz constant or a set of critical points. SLiR parameterizes relaxations by their slope and computes the corresponding offset via a shifting procedure that ensures sound upper and lower bounds over the input domain, enabling efficient optimization while maintaining correctness. Our experiments show that SLiR produces tight relaxations across a wide range of practical activation functions and enables verification of up to 7.8x more properties compared to state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SLiR, a shifting-based method to construct optimizable linear relaxations for arbitrary activation functions. It requires only a Lipschitz constant or set of critical points, parameterizes the relaxation slope, and computes the offset via shifting to produce sound upper and lower bounds over the full input domain. Experiments claim tighter relaxations across practical activations and up to 7.8x more verifiable properties than prior state-of-the-art methods.
Significance. If the shifting procedure is formally sound and the bounds remain valid for general (including non-differentiable or non-monotonic) activations, the result would meaningfully advance neural-network verification by eliminating the need for per-activation hand-crafted relaxations and thereby broadening the set of networks and properties that can be certified.
major comments (2)
- [§3] §3 (Shifting Procedure): the manuscript asserts that supplying only a Lipschitz constant or critical points always yields sound linear bounds valid over the entire domain, yet provides no derivation or case analysis for activations with flat regions, incomplete critical-point sets, or local rather than global Lipschitz constants; this directly underpins the generality claim.
- [§5] §5 (Experiments): the reported 7.8x verification improvement is presented without specifying the exact activation functions, network architectures, property sets, or whether activation/domain choices were pre-registered versus post-hoc; this weakens the empirical support for the central performance claim.
minor comments (2)
- [§3] Notation for slope and offset parameters is introduced in the abstract but not restated with explicit symbols in the method section, making the shifting equations harder to follow.
- [Figures] Figure captions for the relaxation plots should include the precise activation functions and input intervals shown.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the two major comments below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Shifting Procedure): the manuscript asserts that supplying only a Lipschitz constant or critical points always yields sound linear bounds valid over the entire domain, yet provides no derivation or case analysis for activations with flat regions, incomplete critical-point sets, or local rather than global Lipschitz constants; this directly underpins the generality claim.
Authors: We agree that the current presentation would benefit from explicit case analysis. The shifting procedure is constructed so that a global Lipschitz constant supplies an upper bound on the maximum possible slope, allowing the offset to be chosen to ensure the linear function lies above or below the activation everywhere; critical points are used only to locate candidate contact points but are not required to be exhaustive. Flat regions are handled by the zero-slope case reducing to a constant bound. We will add a dedicated subsection in the revised §3 containing a formal derivation together with the three requested cases (flat regions, incomplete critical-point sets, and local versus global Lipschitz constants) to make the generality argument fully rigorous. revision: yes
-
Referee: [§5] §5 (Experiments): the reported 7.8x verification improvement is presented without specifying the exact activation functions, network architectures, property sets, or whether activation/domain choices were pre-registered versus post-hoc; this weakens the empirical support for the central performance claim.
Authors: We acknowledge that the experimental section should be more self-contained. The 7.8× figure was obtained on a collection of verification tasks drawn from standard benchmarks (ACAS Xu, MNIST, and CIFAR-10 networks) using the activations ReLU, GELU, Swish, and several non-monotonic activations for which no prior hand-crafted relaxations existed. All network architectures, property specifications, and activation choices were fixed before running the comparison and were not selected post-hoc. We will expand §5 with an explicit table listing every activation, architecture, and property set, together with a short paragraph describing the experimental protocol, so that the performance claim is fully reproducible and transparent. revision: yes
Circularity Check
No circularity in SLiR shifting derivation
full rationale
The paper describes SLiR as parameterizing relaxations by slope and deriving offsets via a shifting procedure supplied with a Lipschitz constant or critical points to ensure sound bounds. No equations reduce any claimed prediction or bound to a fitted parameter or input by construction. No load-bearing self-citations or uniqueness theorems from prior author work are invoked in the abstract or description. The derivation is presented as a general, self-contained procedure without the patterns of self-definition, fitted-input renaming, or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
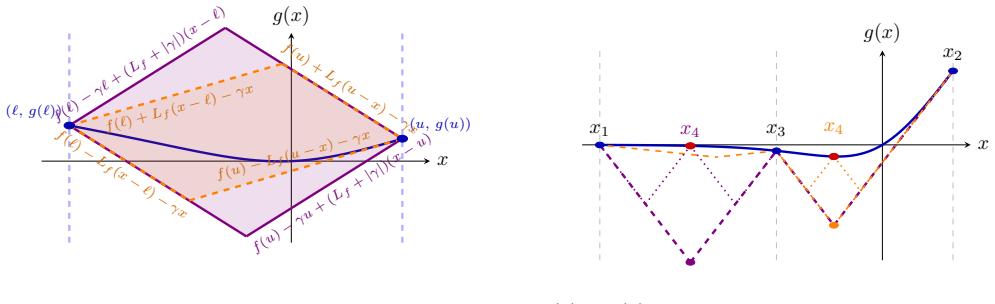
- domain assumption Activation functions admit a known Lipschitz constant or finite set of critical points sufficient for bounding.
Reference graph
Works this paper leans on
-
[1]
Fast and complete: Enabling complete neural network verification with rapid and massively parallel incomplete verifiers,
K. Xu, H. Zhang, S. Wang, Y . Wang, S. Jana, X. Lin, and C. Hsieh, “Fast and complete: Enabling complete neural network verification with rapid and massively parallel incomplete verifiers,” inProc. of the 9th In- ternational Conference on Learning Representations(ICLR’21), Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[2]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,”OpenAI, 2018. 9
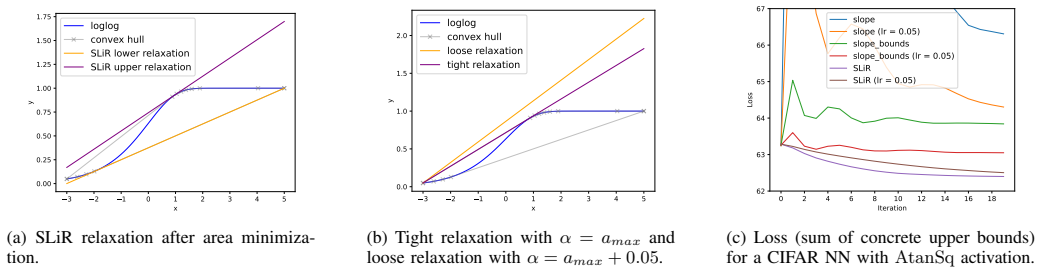
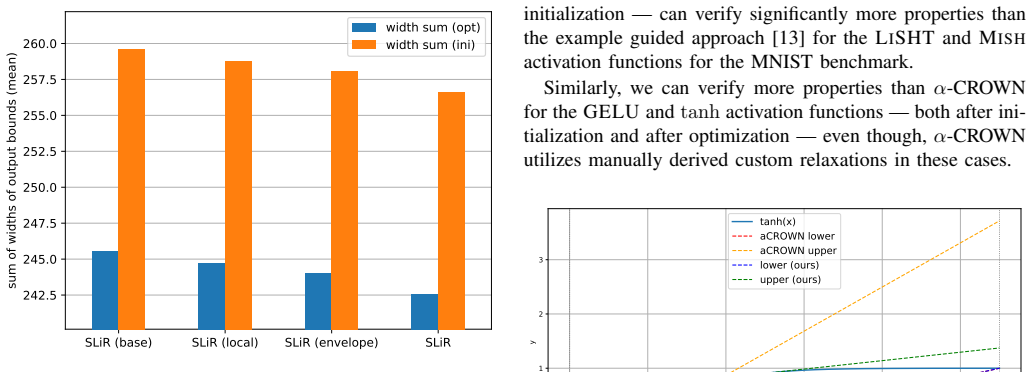
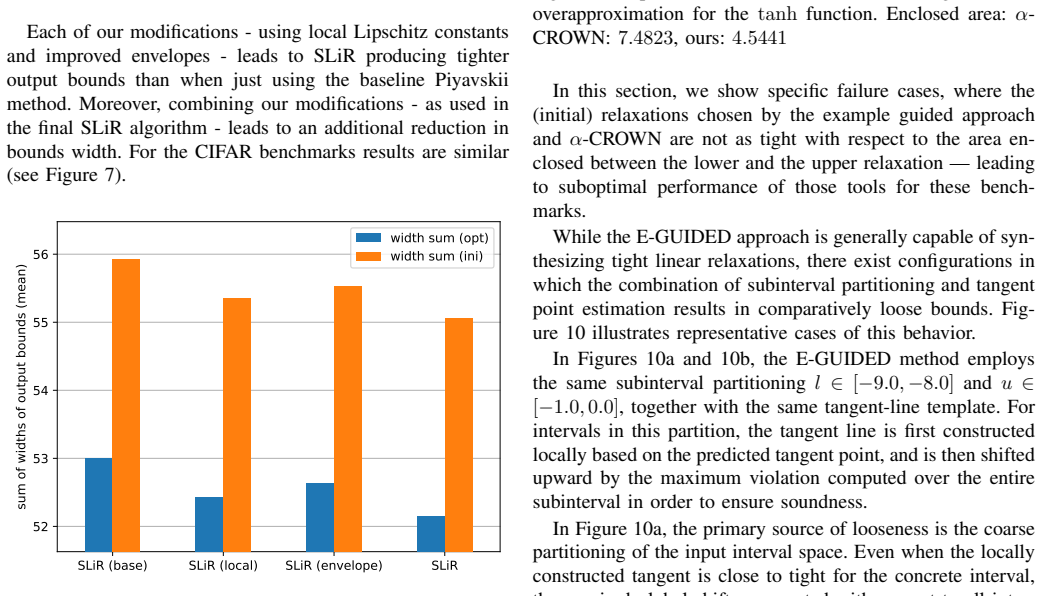
2018
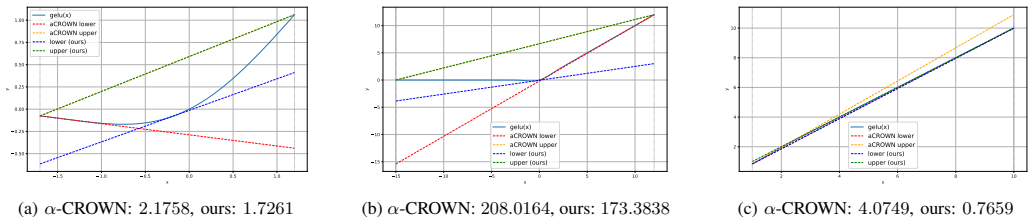
-
[3]
BERT: pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” inProc. of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL- HLT’19), Minneapolis, MN, USA, June 2-7, 2019. Association for Computational Li...
2019
-
[4]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inProc. of the 9th International Conference on Learning Representations (ICLR’21), Virtual Event, Aus- tria, May 3-7,...
2021
-
[5]
Llama: Open and efficient foundation lan- guage models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation lan- guage models,”CoRR, vol. abs/2302.13971, 2023
Pith/arXiv arXiv 2023
-
[6]
YOLOv4: Optimal speed and accuracy of object detection,
A. Bochkovskiy, C. Wang, and H. M. Liao, “YOLOv4: Optimal speed and accuracy of object detection,”CoRR, vol. abs/2004.10934, 2020
Pith/arXiv arXiv 2004
-
[7]
Yolov7: Trainable bag-of- freebies sets new state-of-the-art for real-time object detectors,
C. Wang, A. Bochkovskiy, and H. M. Liao, “Yolov7: Trainable bag-of- freebies sets new state-of-the-art for real-time object detectors,” inProc. of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR’23), Vancouver, BC, Canada, June 17-24, 2023. IEEE, 2023, pp. 7464–7475
2023
-
[8]
Learning specialized activation functions for physics-informed neural networks,
H. Wang, L. Lu, S. Song, and G. Huang, “Learning specialized activation functions for physics-informed neural networks,”ArXiv, vol. abs/2308.04073, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:260704245
arXiv 2023
-
[9]
Certi- fying geometric robustness of neural networks,
M. Balunovic, M. Baader, G. Singh, T. Gehr, and M. T. Vechev, “Certi- fying geometric robustness of neural networks,” inAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Infor- mation Processing Systems 2019 (NeurIPS’19), December 8-14, 2019, Vancouver, BC, Canada, 2019, pp. 15 287–15 297
2019
-
[10]
Scalable polyhedral verification of recurrent neural networks,
W. Ryou, J. Chen, M. Balunovic, G. Singh, A. M. Dan, and M. T. Vechev, “Scalable polyhedral verification of recurrent neural networks,” inProc. of the 33rd International Conference on Computer Aided Veri- fication (CAV’21), Virtual Event, July 20-23, 2021, Proceedings, Part I, ser. Lecture Notes in Computer Science, vol. 12759. Springer, 2021, pp. 225–248
2021
-
[11]
Synthesizing precise static analyzers for automatic differentiation,
J. Laurel, S. B. Qian, G. Singh, and S. Misailovic, “Synthesizing precise static analyzers for automatic differentiation,”Proc. of the ACM on Programming Languages, vol. 7, no. OOPSLA2, pp. 1964–1992,
1964
-
[12]
Available: https://doi.org/10.1145/3622867
[Online]. Available: https://doi.org/10.1145/3622867
-
[13]
LinSyn: Synthesizing tight linear bounds for arbitrary neural network activation functions,
B. Paulsen and C. Wang, “LinSyn: Synthesizing tight linear bounds for arbitrary neural network activation functions,” inProc. of the 28th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS’22), Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2022, Munich, Germany, A...
2022
-
[14]
Example guided synthesis of linear approximations for neural network verification,
——, “Example guided synthesis of linear approximations for neural network verification,” inProc. of the 34th International Conference on Computer Aided Verification (CAV’22), Haifa, Israel, August 7- 10, 2022, Proceedings, Part I, ser. Lecture Notes in Computer Science, vol. 13371. Springer, 2022, pp. 149–170. [Online]. Available: https://doi.org/10.1007/...
-
[15]
SOL: sampling-based optimal linear bounding of arbitrary scalar functions,
Y . Biktairov and J. Deshmukh, “SOL: sampling-based optimal linear bounding of arbitrary scalar functions,” inAdvances in Neural Informa- tion Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023 (NeurIPS’23), New Orleans, LA, USA, Decem- ber 10 - 16, 2023, 2023
2023
-
[16]
Convex Hull Approximation for Activation Functions,
Z. Ma, Z. Wang, and G. Bai, “Convex Hull Approximation for Activation Functions,”Proc. of the ACM on Programming Languages, vol. 9, no. OOPSLA2, pp. 1007–1033, 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3763086
-
[17]
Synthesizing MILP constraints for efficient and robust optimization,
J. Wang, A. Gupta, and C. Wang, “Synthesizing MILP constraints for efficient and robust optimization,”Proc. of the ACM Programming Lan- guages, vol. 7, no. PLDI, pp. 1896–1919, 2023
1919
-
[18]
Neural network verification with branch-and-bound for general nonlinearities,
Z. Shi, Q. Jin, Z. Kolter, S. Jana, C.-J. Hsieh, and H. Zhang, “Neural network verification with branch-and-bound for general nonlinearities,” inTools and Algorithms for the Construction and Analysis of Systems. Cham: Springer Nature Switzerland, 2025, pp. 315–335
2025
-
[19]
Automatic perturbation analysis on general computational graphs,
K. Xu, Z. Shi, H. Zhang, M. Huang, K. Chang, B. Kailkhura, X. Lin, and C. Hsieh, “Automatic perturbation analysis on general computational graphs,”CoRR, vol. abs/2002.12920, 2020
arXiv 2002
-
[20]
An abstract domain for certifying neural networks,
G. Singh, T. Gehr, M. Püschel, and M. T. Vechev, “An abstract domain for certifying neural networks,”Proc. of the ACM Programming Lan- guages, vol. 3, no. POPL, pp. 41:1–41:30, 2019
2019
-
[21]
Automatic perturbation analysis for scalable certified robustness and beyond,
K. Xu, Z. Shi, H. Zhang, Y . Wang, K. Chang, M. Huang, B. Kailkhura, X. Lin, and C. Hsieh, “Automatic perturbation analysis for scalable certified robustness and beyond,” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Pro- cessing Systems (NeurIPS’20), December 6-12, 2020, virtual, 2020
2020
-
[22]
On optimizing back-substitution methods for neural network verification,
T. Zelazny, H. Wu, C. W. Barrett, and G. Katz, “On optimizing back-substitution methods for neural network verification,” in22nd Formal Methods in Computer-Aided Design, FMCAD 2022, Trento, Italy, October 17-21, 2022, A. Griggio and N. Rungta, Eds. IEEE, 2022, pp. 17–26. [Online]. Available: https://doi.org/10.34727/2022/ isbn.978-3-85448-053-2_7
-
[23]
Provable defenses against adversarial examples via the convex outer adversarial polytope,
E. Wong and J. Z. Kolter, “Provable defenses against adversarial examples via the convex outer adversarial polytope,” inProceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, ser. Proceedings of Machine Learning Research, J. G. Dy and A. Krause, Eds. PMLR, 2018, pp. 5283–5292...
2018
-
[24]
A convex relaxation barrier to tight robustness verification of neural networks,
H. Salman, G. Yang, H. Zhang, C. Hsieh, and P. Zhang, “A convex relaxation barrier to tight robustness verification of neural networks,” inAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, H. M. Wallach, H. Larochelle, A. Beygelzi...
2019
-
[25]
Available: https://proceedings.neurips.cc/paper/2019/ hash/246a3c5544feb054f3ea718f61adfa16-Abstract.html
[Online]. Available: https://proceedings.neurips.cc/paper/2019/ hash/246a3c5544feb054f3ea718f61adfa16-Abstract.html
2019
-
[26]
Fastened CROWN: tightened neural network robustness certificates,
Z. Lyu, C. Ko, Z. Kong, N. Wong, D. Lin, and L. Daniel, “Fastened CROWN: tightened neural network robustness certificates,” inThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Int...
-
[27]
Fast and accurate deep network learning by exponential linear units (ELUs),
D. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (ELUs),” inProc. of the 4th International Conference on Learning Representations (ICLR’16), San Juan, Puerto Rico, May 2-4, 2016, 2016
2016
-
[28]
An algorithm for finding the absolute extremum of a function,
S. A. Piyavskii, “An algorithm for finding the absolute extremum of a function,”Journal of USSR Computational Mathematics and Mathemat- ical Physics, vol. 12, no. 4, pp. 57–67, 1972
1972
-
[29]
Cobza¸ s, R
¸ S. Cobza¸ s, R. Miculescu, A. Nicolaeet al.,Lipschitz functions. Springer, 2019
2019
-
[30]
Efficient neural network robustness certification with general activation functions,
H. Zhang, T. Weng, P. Chen, C. Hsieh, and L. Daniel, “Efficient neural network robustness certification with general activation functions,” in Advances in Neural Information Processing Systems 31: Annual Con- ference on Neural Information Processing Systems (NeurIPS’18), De- cember 3-8, 2018, Montréal, Canada, 2018, pp. 4944–4953
2018
-
[31]
Another efficient algorithm for convex hulls in two dimensions,
A. M. Andrew, “Another efficient algorithm for convex hulls in two dimensions,”Information Processing Letters, vol. 9, no. 5, pp. 216– 219, 1979. [Online]. Available: https://doi.org/10.1016/0020-0190(79) 90072-3
-
[32]
PyTorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Z. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An imperative style, high- performance deep learning library,” inAdvances in Neural Information Processin...
2019
-
[33]
S. Bak, C. Liu, and T. T. Johnson, “The second international verifica- tion of neural networks competition (VNN-COMP 2021): Summary and results,”CoRR, vol. abs/2109.00498, 2021
arXiv 2021
-
[34]
M. N. Müller, C. Brix, S. Bak, C. Liu, and T. T. Johnson, “The third international verification of neural networks competition (VNN-COMP 2022): Summary and results,”CoRR, vol. abs/2212.10376, 2022
arXiv 2022
-
[35]
C. Brix, S. Bak, C. Liu, and T. T. Johnson, “The fourth international verification of neural networks competition (VNN-COMP 2023): Sum- mary and results,”CoRR, vol. abs/2312.16760, 2023. 10
arXiv 2023
-
[36]
C. Brix, S. Bak, T. T. Johnson, and H. Wu, “The fifth international veri- fication of neural networks competition (VNN-COMP 2024): Summary and results,”CoRR, vol. abs/2412.19985, 2024
arXiv 2024
-
[37]
K. Kaulen, T. Ladner, S. Bak, C. Brix, H. Duong, T. Flinkow, T. T. Johnson, L. Koller, E. Manino, T. H. Nguyen, and H. Wu, “The 6th international verification of neural networks competition (VNN-COMP 2025): Summary and results,”CoRR, vol. abs/2512.19007, 2025
arXiv 2025
-
[38]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proc. of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[39]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” University of Toronto, Toronto, Ontario, Tech. Rep. 0, 2009. [Online]. Available: https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
2009
-
[40]
Searching for activation functions,
P. Ramachandran, B. Zoph, and Q. V . Le, “Searching for activation functions,” inProc. of the 6th International Conference on Learning Representations (ICLR’18), Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net, 2018
2018
-
[41]
Bridging nonlinearities and stochas- tic regularizers with gaussian error linear units,
D. Hendrycks and K. Gimpel, “Bridging nonlinearities and stochas- tic regularizers with gaussian error linear units,”CoRR, vol. abs/1606.08415, 2016
Pith/arXiv arXiv 2016
-
[42]
LiSHT: Non- parametric linearly scaled hyperbolic tangent activation function for neu- ral networks,
S. K. Roy, S. Manna, S. R. Dubey, and B. B. Chaudhuri, “LiSHT: Non- parametric linearly scaled hyperbolic tangent activation function for neu- ral networks,” inProc. of the 7th International Conference on Computer Vision and Image Processing (CVIP’22), Nagpur, India, November 4-6, 2022, Revised Selected Papers, Part I, ser. Communications in Computer and ...
2022
-
[43]
Complementary Log-Log and Probit: Activation functions implemented in artificial neural networks,
G. S. d. S. Gomes and T. B. Ludermir, “Complementary Log-Log and Probit: Activation functions implemented in artificial neural networks,” inProc. of 2008 Eighth International Conference on Hybrid Intelligent Systems, Barcelona, Spain, September 10-12, 2008. IEEE, 2008, pp. 939–942
2008
-
[44]
Mish: A self regularized non-monotonic activation function,
D. Misra, “Mish: A self regularized non-monotonic activation function,” inProc. of the 31st British Machine Vision Conference (BMVC’20), Virtual Event, UK, September 7-10, 2020. BMV A Press, 2020
2020
-
[45]
Fast and effective robustness certification,
G. Singh, T. Gehr, M. Mirman, M. Püschel, and M. T. Vechev, “Fast and effective robustness certification,” inAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Pro- cessing Systems (NeurIPS’18), December 3-8, 2018, Montréal, Canada, 2018, pp. 10 825–10 836
2018
-
[46]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. J. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” inProc. of 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, Y . Bengio and Y . LeCun, Eds., 2014. [Online]. Available: http://arxiv.or...
Pith/arXiv arXiv 2014
-
[47]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inProc. of the 6th International Conference on Learning Representations (ICLR’18), Vancouver, BC, Canada, April 30 - May 3, 2018. OpenReview.net, 2018
2018
-
[48]
Adaptive error bounded piecewise linear approximation for time-series representation,
Z. Zhou, M. Baratchi, G. Si, H. H. Hoos, and G. Huang, “Adaptive error bounded piecewise linear approximation for time-series representation,” Journal of Engineering Applications of Artificial Intelligence, vol. 126, p. 106892, 2023
2023
-
[49]
SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python,
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey,˙I. Polat, Y . Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Hen- rikse...
2020
-
[50]
R. P. Brent,Algorithms for Minimization without Derivatives, ser. Dover books on mathematics. Mineola, NY: Dover Publications, 2002. 11 APPENDIX A. Extended Description of the Backsubstitution Procedure In this section, we provide more details on the backsubsti- tution procedure BACKSUBSTITUTE(N,X). Fundamentally, backsubstitution is a bound propagation p...
2002
-
[51]
The function does not need to be continuous, but we expect that it’s domain covers the whole set of real numbers (i.e.,f:R→R)
Piecewise Linear Activation Functions:In this subsec- tion we present a general solution to an arbitrary piecewise linear activation function, consisting ofnlinear pieces. The function does not need to be continuous, but we expect that it’s domain covers the whole set of real numbers (i.e.,f:R→R). We consider a finite decomposition ofRinton∈N >0 non- empt...
-
[52]
Therefore it has an inverse function on(0,1): σ−1(x) =−log 1 x −1 .(41) We want to find the extrema ofg(x) =σ(x)−m·xwith derivativeg ′(x) =σ(x)(1−σ(x))−m
Sigmoid:The sigmoid function is defined as σ(x) = 1 1 +e −x .(40) It is an injection onRand a surjection to(0,1). Therefore it has an inverse function on(0,1): σ−1(x) =−log 1 x −1 .(41) We want to find the extrema ofg(x) =σ(x)−m·xwith derivativeg ′(x) =σ(x)(1−σ(x))−m. The critical points satisfy g′(x) =σ(x)(1−σ(x))−m= 0(42) ⇔ −σ(x) 2 +σ(x)−m= 0lets=σ(x)(4...
-
[53]
Thetanhfunction is an injection onRand a surjection to(−1,1)
Tanh:The proof fortanhproceeds similarly to the proof forσ. Thetanhfunction is an injection onRand a surjection to(−1,1). Therefore it also has an inverse functionarctanh on(−1,1). We want to find the extrema ofg(x) = tanh(x)−m·x with derivativeg ′(x) = 1−tanh(x) 2 −m. The critical points thus have to satisfy g′(x) = 1−tanh(x) 2 −m= 0(47) ⇔ −t 2 + 1−m= 0 ...
-
[54]
Abs:Since the absolute value function abs(x) =|x|= ( −xifx <0 xifx≥0 (51) is piecewise linear, we can just apply the results of Section B1
-
[55]
Acos:We haveg(x) = arccos(x)−m·xandg ′(x) = −1√ 1−x2 −m. The critical points can be found by setting the derivative equal to zero: g′(x) = −1√ 1−x 2 −m= 0(52) ⇔ −1√ 1−x 2 =m(53) ⇔ p 1−x 2 =− 1 m , m̸= 0(54) ⇔1−x 2 = 1 m2 , m <0(55) ⇔x 2 = 1− 1 m2 , m <0(56) ⇔x=± r 1− 1 m2 , m <0.(57) The functiong(x)has no discontinuities or piecewise defi- nitions, so th...
-
[56]
The solution is analogous to the solution for the sine function de- scribed in Appendix B10
Cos:We want to solve for the critical points ofg(x) = cos(x)−m·x, with derivativeg ′(x) =−sin(x)−m. The solution is analogous to the solution for the sine function de- scribed in Appendix B10
-
[57]
With derivativeg ′(x) = ex −m
Exp:We haveg(x) =e x−x·m. With derivativeg ′(x) = ex −m. Therefore, critical points are g′(x) =e x −m= 0(59) ⇔e x =m(60) ⇔x= logm, m >0(61) The second order derivativeg ′′(x) =e x, which is purely positive, means that the error function is convex on the whole set ofR. Thus,x=log(m)is a global minimum, and it cannot be thexvalue which maximizes the error f...
-
[58]
HardSigmoid, ReLU, LeakyReLU, Sign:All these func- tions are piecewise linear, thus our solution from Section B1 should work here. HardSigmoid(x) = 0ifx≤ −3 1ifx≥+3 x 6 + 1 2 otherwise (64) ReLU(x) = ( 0ifx <0 xotherwise (65) LeakyReLU(x) = ( γxifx <0 xotherwise (66) Sign(x) = −1ifx <0 +1ifx >0 0otherwise (67)
-
[59]
(68) We considerg(x) = HardSwish(x)−mx
HardSwish:The HardSwish activation is defined as HardSwish(x) = 0ifx≤ −3 xifx≥3 x(x+3) 6 otherwise. (68) We considerg(x) = HardSwish(x)−mx. On(−3,3)we have g(x) = x(x+ 3) 6 −mx,(69) g′(x) = 2x+ 3 6 −m.(70) Thus, any interior critical point must satisfy g′(x) = 0⇔ 2x+ 3 6 =m⇔x ∗(m) = 3m− 3 2 .(71) The point is admissible iff.x ∗(m)∈(−3,3), equivale...
-
[60]
Sin:We haveg(x) = sin(x)−m·xwith derivative g′(x) = cos(x)−m. Assuming that the co-domain ofarccos is[0, π](with[−π/2, π/2]being another popular convention), i.e.arccos : [−1,1]→[0, π], the critical pointsinside[0, π] can be computed as g′(x) = cos(x)−m= 0(72) ⇔cos(x) =m(73) ⇔x= arccos(m), m∈[−1,1].(74) However, there can be critical pointsoutsideof[0, π]...
-
[61]
Since √xneeds to be defined, we also 15 assumex≥0
Sqrt:We haveg(x) = √x−x·m, with derivative g′(x) = 1 2 q 1 x −m. Since √xneeds to be defined, we also 15 assumex≥0. The critical points can be derived as g′(x) = 1 2 r 1 x −m= 0(86) ⇔ 1 2 r 1 x =m(87) ⇔ r 1 x = 2m(88) ⇔ 1 x = 4m2 , m≥0(89) ⇔x= 1 4m2 , m >0(90) The second order derivativeg ′′(x) =− 1 4 q 1 x3 is strictly negative, thus the error function i...
-
[62]
Unless stated otherwise, all experiments use the same default configuration
Parameter Settings:This section summarizes the param- eter values used in our experimental evaluation. Unless stated otherwise, all experiments use the same default configuration. a) Initialization:For the gradient-based initialization of the relaxation slopes we perform100iterations of gradient descent. b) Optimization of relaxation parameters:During bou...
-
[63]
Lipschitz Optimization and Bound Tightness:While the improvements to the Piyavskii algorithm described in Section III-C did not lead to a large increase in verified properties for the MNIST benchmark, the effects are noticable, when having a closer look at the verifiable output bounds. Figure 6 shows the mean of the summed width of the output bounds X i u...
-
[64]
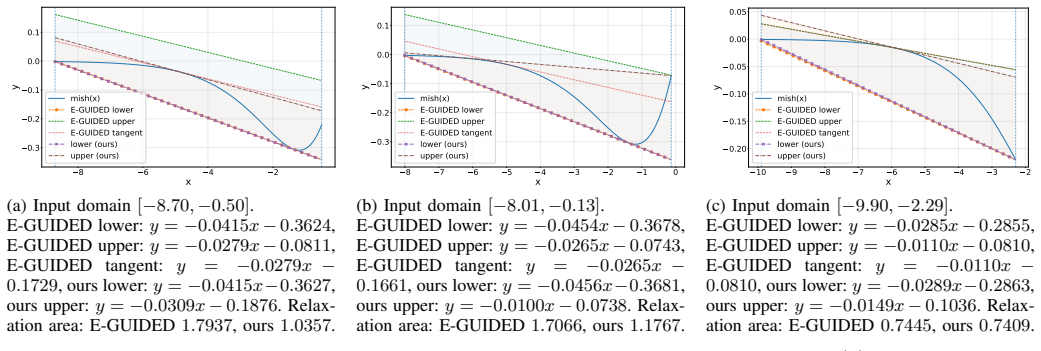
Failure Cases of Other Methods:The experimental re- sults in Sections V showed that our approach — even after initialization — can verify significantly more properties than the example guided approach [13] for the LISHT and MISH activation functions for the MNIST benchmark. Similarly, we can verify more properties thanα-CROWN for the GELU andtanhactivatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.