Direct Advantage Estimation for Scalable and Sample-efficient Deep Reinforcement Learning
Pith reviewed 2026-06-26 18:09 UTC · model grok-4.3
The pith
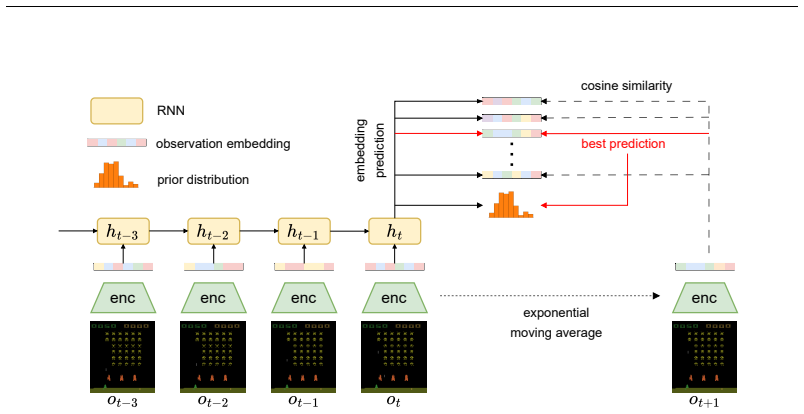
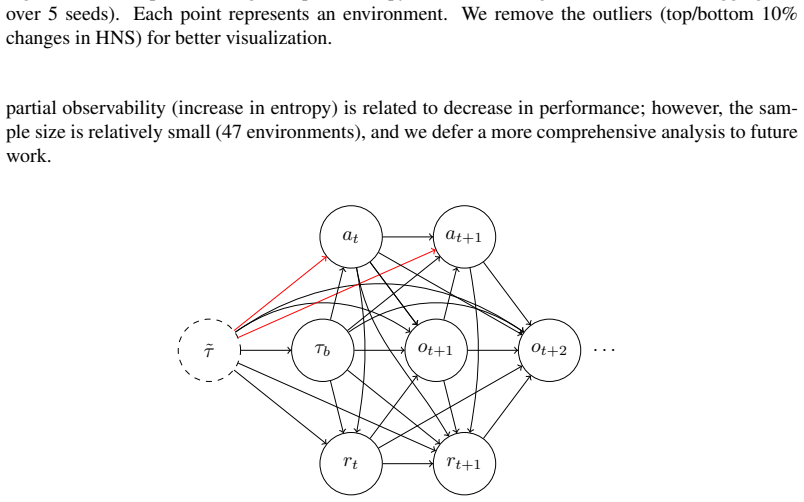
Direct Advantage Estimation extends to partially observable domains by approximating transitions with discrete latent dynamics models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
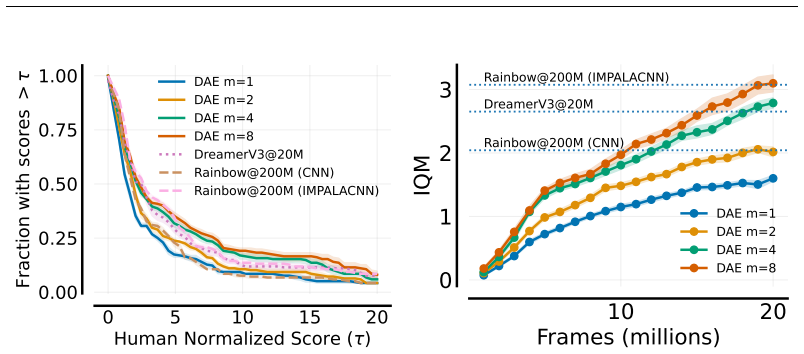
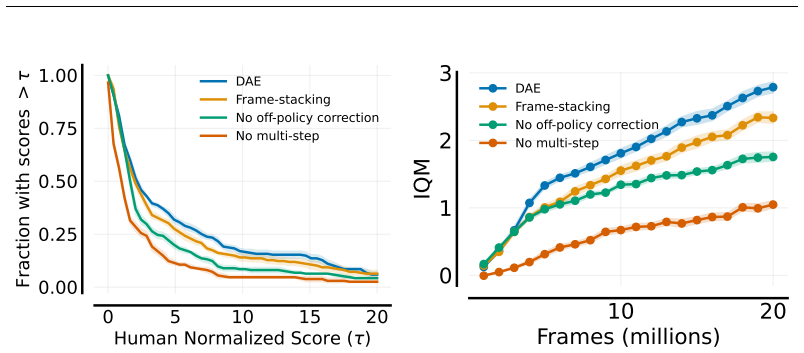
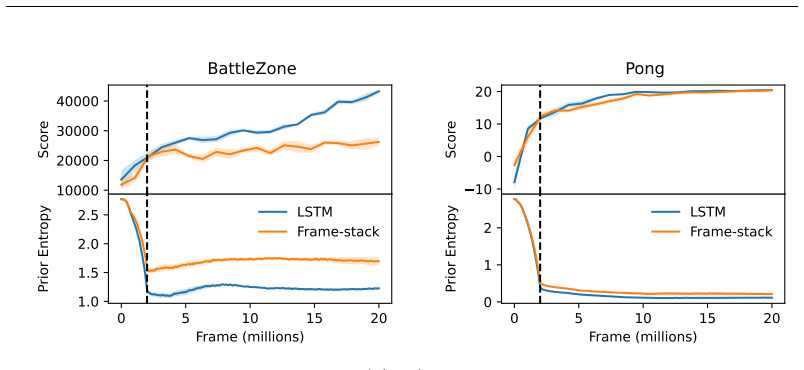
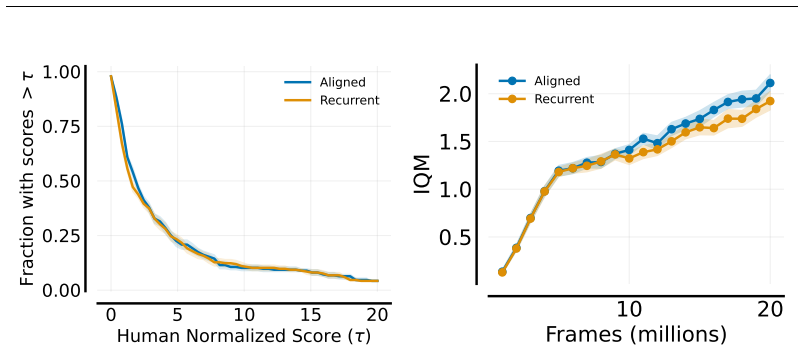
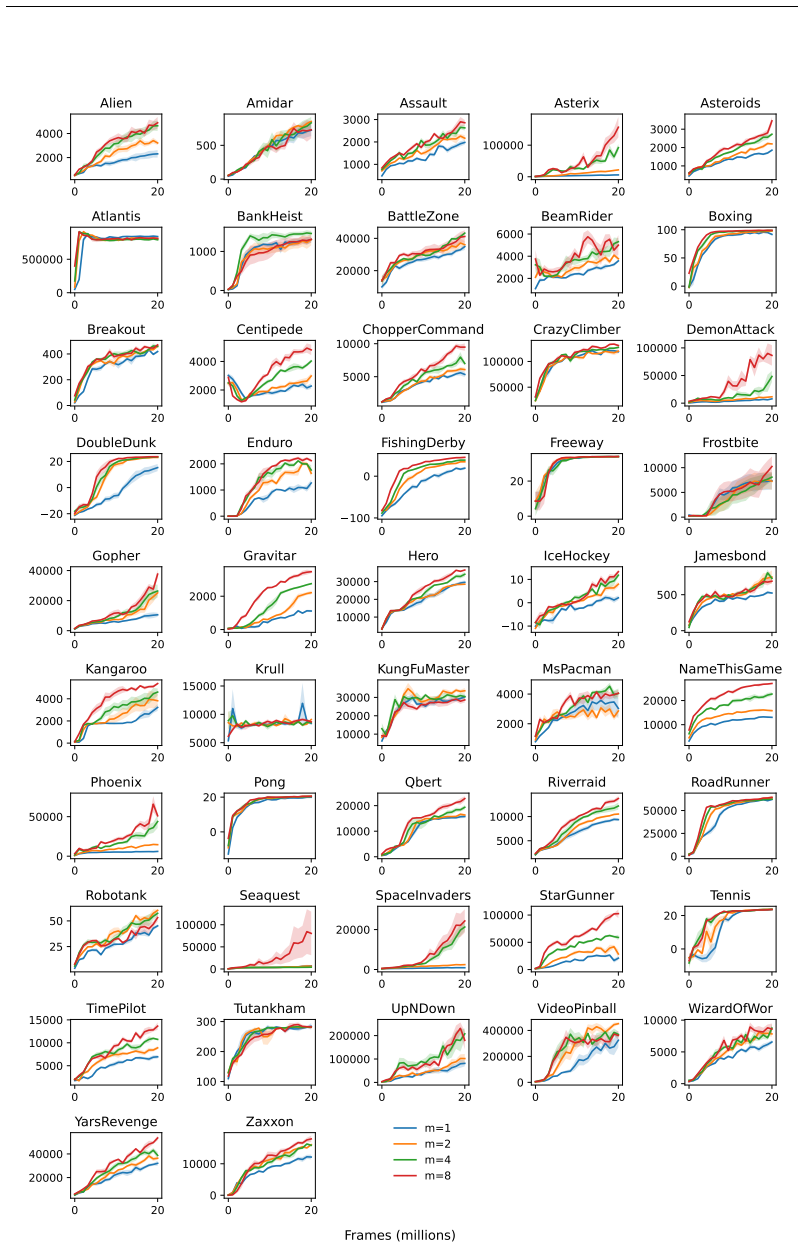
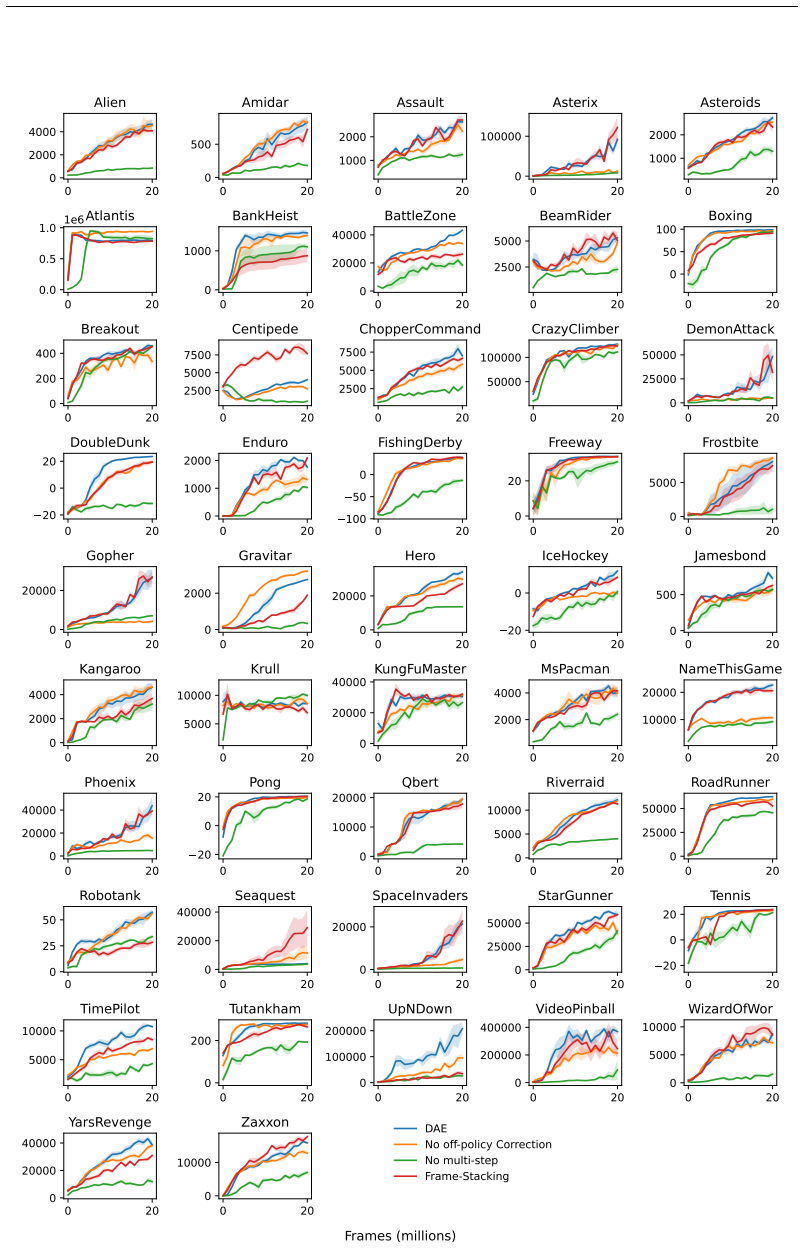
We extend the theoretical framework of DAE to partially observable domains with minimal modifications. Second, we reduce its computational complexity by introducing discrete latent dynamics models that efficiently approximate transition probabilities. We evaluate our approach on the Arcade Learning Environment and find that DAE scales effectively with function approximator capacity while retaining high sample efficiency.
What carries the argument
The minimal extension of the DAE framework to POMDPs paired with discrete latent dynamics models that approximate transition probabilities.
If this is right
- The DAE theoretical framework applies to partially observable domains after only minimal changes.
- Discrete latent dynamics models lower the computational cost of handling high-dimensional observations.
- The resulting method scales effectively as function approximator capacity increases.
- High sample efficiency is retained during evaluation on the Arcade Learning Environment.
Where Pith is reading between the lines
- The same minimal extension approach could be tested on other advantage-based RL algorithms that currently assume full observability.
- Replacing discrete latent models with continuous ones might further reduce approximation error in some environments.
- The method opens a route to applying DAE in real-world control problems that naturally present partial observability.
- The latent dynamics component could be combined with other model-based RL techniques to improve overall efficiency.
Load-bearing premise
Discrete latent dynamics models can approximate the required transition probabilities with enough accuracy to keep the sample-efficiency advantages of Direct Advantage Estimation in high-dimensional partially observable settings.
What would settle it
An evaluation on the Arcade Learning Environment in which the latent-model version of DAE shows no gain in sample efficiency over standard methods or loses performance as function approximator capacity grows.
Figures
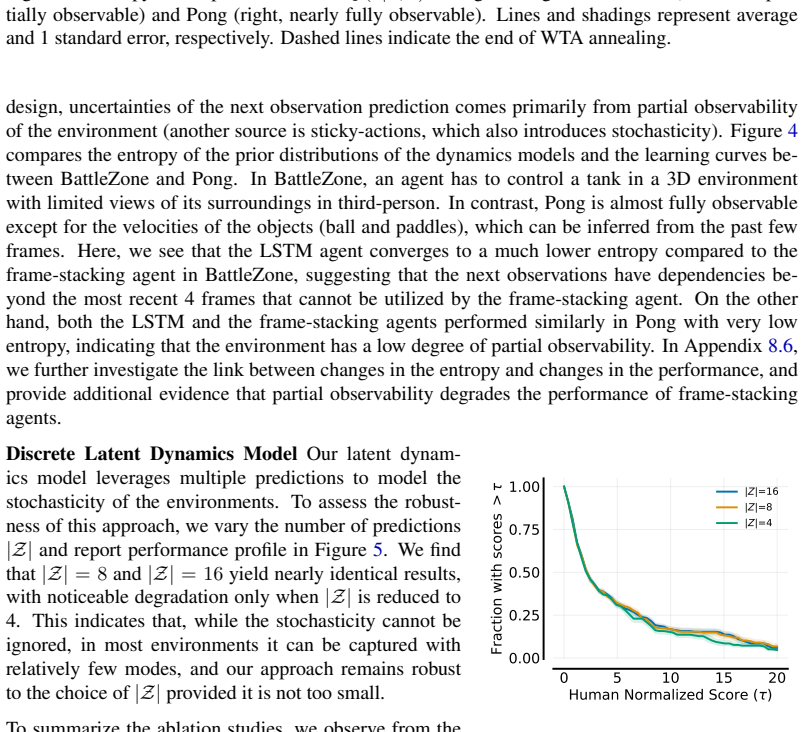
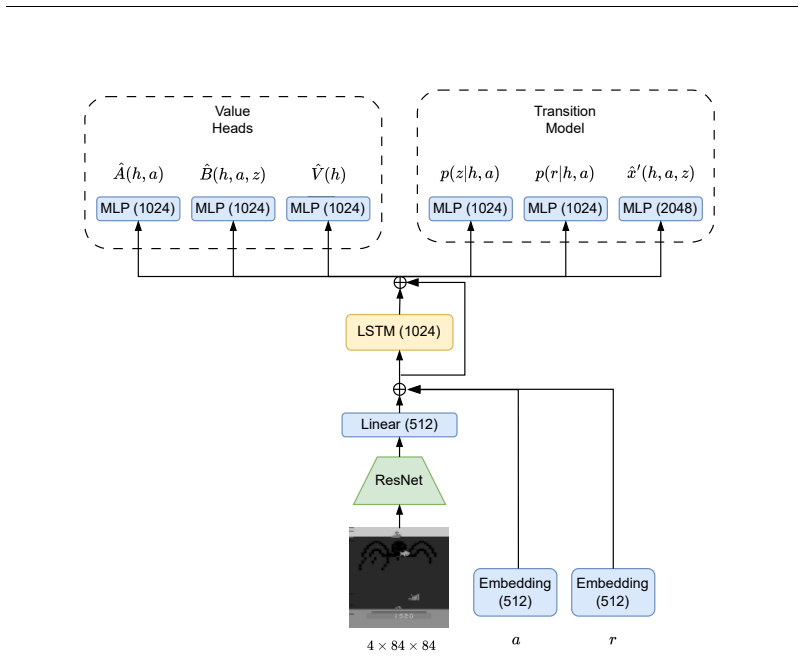
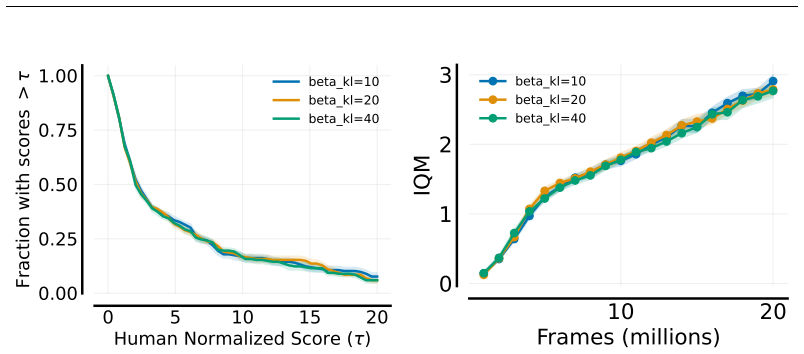
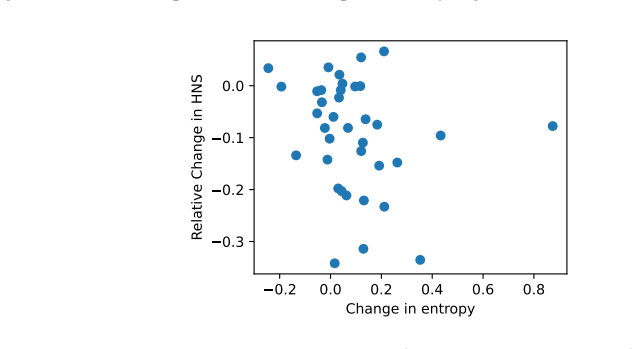
read the original abstract
Direct Advantage Estimation (DAE) has been shown to improve the sample efficiency of deep reinforcement learning algorithms. However, its reliance on full environment observability limits its applicability in realistic settings, and its requirement to model transition probabilities incurs substantial computational overhead for high-dimensional observations. In the present work, we address both limitations. First, we extend the theoretical framework of DAE to partially observable domains with minimal modifications. Second, we reduce its computational complexity by introducing discrete latent dynamics models that efficiently approximate transition probabilities. We evaluate our approach on the Arcade Learning Environment and find that DAE scales effectively with function approximator capacity while retaining high sample efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the Direct Advantage Estimation (DAE) framework to partially observable domains (POMDPs) via minimal modifications to the theory and replaces explicit transition modeling with discrete latent dynamics models that approximate transition probabilities. It reports an evaluation on the Arcade Learning Environment (ALE) claiming that the resulting method scales effectively with function-approximator capacity while preserving DAE's sample-efficiency advantages.
Significance. If the POMDP extension preserves DAE's theoretical properties and the latent-dynamics approximation introduces sufficiently small error, the work would address two practical barriers (observability and computational cost) that currently limit DAE, potentially broadening its applicability to realistic high-dimensional control tasks.
major comments (2)
- [Abstract] Abstract: the central claim that discrete latent dynamics models 'efficiently approximate transition probabilities' while retaining DAE sample efficiency is load-bearing, yet the text supplies neither an error bound on the approximation nor conditions on latent-state sufficiency or model capacity under which the POMDP extension of the advantage estimator remains valid.
- [Abstract] Abstract: the statement that the POMDP extension requires only 'minimal modifications' is presented without any derivation or statement of the additional observability or Markovian assumptions needed for the direct advantage estimator to remain unbiased or low-variance in the latent space.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater precision in the abstract regarding the theoretical claims. Below we respond point-by-point to the two major comments. We agree that the abstract is too terse on these points and will revise it (and, where appropriate, the main text) to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that discrete latent dynamics models 'efficiently approximate transition probabilities' while retaining DAE sample efficiency is load-bearing, yet the text supplies neither an error bound on the approximation nor conditions on latent-state sufficiency or model capacity under which the POMDP extension of the advantage estimator remains valid.
Authors: We acknowledge that neither the abstract nor the current main text provides a formal error bound or explicit conditions on latent-state sufficiency and model capacity. Section 4 describes the discrete latent dynamics model and its use in place of explicit transition modeling, and Section 5 reports empirical results on ALE showing retained sample efficiency. However, the paper does not derive approximation-error bounds. We will add a short discussion of the modeling assumptions and the empirical evidence for approximation quality in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the statement that the POMDP extension requires only 'minimal modifications' is presented without any derivation or statement of the additional observability or Markovian assumptions needed for the direct advantage estimator to remain unbiased or low-variance in the latent space.
Authors: Section 3 presents the POMDP extension and argues that it follows from the original DAE derivation once the latent state is treated as the effective observation. The text does not, however, explicitly enumerate the additional observability or Markovian assumptions required for unbiasedness or variance bounds. We will revise both the abstract and Section 3 to state the key assumptions more clearly and to reference the relevant derivation steps. revision: yes
Circularity Check
No circularity; derivation chain not reducible to inputs from provided text
full rationale
The abstract and available text describe an extension of prior DAE framework to POMDPs via minimal modifications and discrete latent dynamics for transition approximation, followed by empirical evaluation on ALE. No equations, fitted parameters relabeled as predictions, self-definitional steps, or load-bearing self-citations are present that would reduce any claimed result to its own inputs by construction. The evaluation on ALE provides an external benchmark independent of any internal fitting. Without specific derivation steps or quotes exhibiting reduction (as required by hard rules), no circularity is identified.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning that matters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[2]
Machine Learning Proceedings 1995 , pages=
Residual algorithms: Reinforcement learning with function approximation , author=. Machine Learning Proceedings 1995 , pages=. 1995 , publisher=
1995
-
[3]
, author=
Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning. , author=. Journal of Machine Learning Research , volume=
-
[4]
2012 , publisher=
Dynamic programming and optimal control: Volume I , author=. 2012 , publisher=
2012
-
[5]
Approximately optimal approximate reinforcement learning , author=. In Proc. 19th International Conference on Machine Learning , year=
-
[6]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[7]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[8]
Advances in Neural Information Processing Systems , volume=
Direct advantage estimation , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:1506.02438 , year=
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Overcoming limitations of mixture density networks: A sampling and fitting framework for multimodal future prediction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
International conference on machine learning , pages=
Dueling network architectures for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[12]
International conference on learning representations , year=
Recurrent experience replay in distributed reinforcement learning , author=. International conference on learning representations , year=
-
[13]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[14]
International Conference on Learning Representations , year=
The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[15]
2009 , publisher=
Causality , author=. 2009 , publisher=
2009
-
[16]
Nature , pages=
Mastering diverse control tasks through world models , author=. Nature , pages=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:1409.1259 , year=
On the properties of neural machine translation: Encoder-decoder approaches , author=. arXiv preprint arXiv:1409.1259 , year=
-
[18]
arXiv preprint arXiv:2402.12874 , year=
Skill or Luck? Return Decomposition via Advantage Functions , author=. arXiv preprint arXiv:2402.12874 , year=
-
[19]
arXiv preprint arXiv:1312.6114 , year=
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
-
[20]
Advances in neural information processing systems , volume=
Learning structured output representation using deep conditional generative models , author=. Advances in neural information processing systems , volume=
-
[21]
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments , journal =. 2019
2019
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Off-policy evaluation in partially observable environments , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Proceedings of the IEEE international conference on computer vision , pages=
Learning in an uncertain world: Representing ambiguity through multiple hypotheses , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[24]
arXiv preprint arXiv:2007.05929 , year=
Data-efficient reinforcement learning with self-predictive representations , author=. arXiv preprint arXiv:2007.05929 , year=
arXiv 2007
-
[25]
Journal of Artificial Intelligence Research , volume=
The arcade learning environment: An evaluation platform for general agents , author=. Journal of Artificial Intelligence Research , volume=
-
[26]
Journal of Artificial Intelligence Research , volume=
Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents , author=. Journal of Artificial Intelligence Research , volume=
-
[27]
Bellemare , title =
Pablo Samuel Castro and Subhodeep Moitra and Carles Gelada and Saurabh Kumar and Marc G. Bellemare , title =. 2018 , url =
2018
-
[28]
2018 , publisher=
Reinforcement learning: An introduction , author=. 2018 , publisher=
2018
-
[29]
Machine learning , volume=
Learning to predict by the methods of temporal differences , author=. Machine learning , volume=. 1988 , publisher=
1988
-
[30]
arXiv preprint arXiv:1803.10122 , year=
World models , author=. arXiv preprint arXiv:1803.10122 , year=
-
[31]
Nature , volume=
Mastering atari, go, chess and shogi by planning with a learned model , author=. Nature , volume=. 2020 , publisher=
2020
-
[32]
International Conference on Learning Representations , year=
Planning in stochastic environments with a learned model , author=. International Conference on Learning Representations , year=
-
[33]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[34]
Essay on principles
On the application of probability theory to agricultural experiments. Essay on principles. Section 9. , author=. Statistical Science , pages=. 1990 , publisher=
1990
-
[35]
, author=
Estimating causal effects of treatments in randomized and nonrandomized studies. , author=. Journal of educational Psychology , volume=. 1974 , publisher=
1974
-
[36]
2017 , publisher=
Elements of causal inference: foundations and learning algorithms , author=. 2017 , publisher=
2017
-
[37]
Advances in Neural Information Processing Systems , volume=
Bandits with unobserved confounders: A causal approach , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Uncertainty in Artificial Intelligence , pages=
Bandits with partially observable confounded data , author=. Uncertainty in Artificial Intelligence , pages=. 2021 , organization=
2021
-
[39]
arXiv preprint arXiv:2306.01157 , year=
Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding , author=. arXiv preprint arXiv:2306.01157 , year=
-
[40]
Artificial intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial intelligence , volume=. 1998 , publisher=
1998
-
[41]
Journal of mathematical analysis and applications , volume=
Optimal control of Markov processes with incomplete state information I , author=. Journal of mathematical analysis and applications , volume=. 1965 , publisher=
1965
-
[42]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[43]
2015 aaai fall symposium series , year=
Deep recurrent q-learning for partially observable mdps , author=. 2015 aaai fall symposium series , year=
2015
-
[44]
2014 , publisher=
Markov decision processes: discrete stochastic dynamic programming , author=. 2014 , publisher=
2014
-
[45]
arXiv preprint arXiv:1912.06680 , year=
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
Pith/arXiv arXiv 1912
-
[46]
Training language models to follow instructions with human feedback, 2022 , author=. URL https://arxiv. org/abs/2203.02155 , volume=
Pith/arXiv arXiv 2022
-
[47]
Nature , volume=
Outracing champion Gran Turismo drivers with deep reinforcement learning , author=. Nature , volume=. 2022 , publisher=
2022
-
[48]
Weng, Jiayi and Lin, Min and Huang, Shengyi and Liu, Bo and Makoviichuk, Denys and Makoviychuk, Viktor and Liu, Zichen and Song, Yufan and Luo, Ting and Jiang, Yukun and Xu, Zhongwen and Yan, Shuicheng , booktitle =. Env
-
[49]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[50]
International Conference on Machine Learning , pages=
Atari-5: Distilling the arcade learning environment down to five games , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[51]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[52]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[53]
arXiv preprint arXiv:1701.03360 , year=
Residual LSTM: Design of a deep recurrent architecture for distant speech recognition , author=. arXiv preprint arXiv:1701.03360 , year=
-
[54]
arXiv preprint arXiv:1607.06450 , year=
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
-
[55]
arXiv preprint arXiv:1511.06314 , year=
Why m heads are better than one: Training a diverse ensemble of deep networks , author=. arXiv preprint arXiv:1511.06314 , year=
-
[56]
Advances in neural information processing systems , volume=
Multiple choice learning: Learning to produce multiple structured outputs , author=. Advances in neural information processing systems , volume=
-
[57]
Proceedings of the AAAI conference on artificial intelligence , volume=
Rainbow: Combining improvements in deep reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[58]
arXiv preprint arXiv:1901.07510 , year=
Understanding multi-step deep reinforcement learning: A systematic study of the DQN target , author=. arXiv preprint arXiv:1901.07510 , year=
Pith/arXiv arXiv 1901
-
[59]
arXiv preprint arXiv:1803.00933 , year=
Distributed prioritized experience replay , author=. arXiv preprint arXiv:1803.00933 , year=
-
[60]
, author=
Bias-Variance Error Bounds for Temporal Difference Updates. , author=. COLT , pages=
-
[61]
International Conference on Machine Learning , pages=
VA-learning as a more efficient alternative to Q-learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[62]
arXiv preprint arXiv:2111.01587 , year=
Procedural generalization by planning with self-supervised world models , author=. arXiv preprint arXiv:2111.01587 , year=
-
[63]
arXiv preprint arXiv:1812.02648 , year=
Deep reinforcement learning and the deadly triad , author=. arXiv preprint arXiv:1812.02648 , year=
-
[64]
arXiv preprint arXiv:1912.10703 , year=
Variational recurrent models for solving partially observable control tasks , author=. arXiv preprint arXiv:1912.10703 , year=
arXiv 1912
-
[65]
Advances in Neural Information Processing Systems , year=
Deep Reinforcement Learning at the Edge of the Statistical Precipice , author=. Advances in Neural Information Processing Systems , year=
-
[66]
ArXiv , year=
Mastering Atari with Discrete World Models , author=. ArXiv , year=
-
[67]
International Conference on Machine Learning , pages=
Bigger, better, faster: Human-level atari with human-level efficiency , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[68]
Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN'94) , volume=
Reinforcement learning in continuous time: Advantage updating , author=. Proceedings of 1994 IEEE International Conference on Neural Networks (ICNN'94) , volume=. 1994 , organization=
1994
-
[69]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[70]
International Conference on Machine Learning , pages=
Dreamerpro: Reconstruction-free model-based reinforcement learning with prototypical representations , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[71]
arXiv e-prints , pages=
In deep reinforcement learning, a pruned network is a good network , author=. arXiv e-prints , pages=
-
[72]
arXiv preprint arXiv:1912.01703 , year=
Pytorch: An imperative style, high-performance deep learning library , author=. arXiv preprint arXiv:1912.01703 , year=
Pith/arXiv arXiv 1912
-
[73]
arXiv preprint arXiv:1905.12340 , year=
Rethinking full connectivity in recurrent neural networks , author=. arXiv preprint arXiv:1905.12340 , year=
Pith/arXiv arXiv 1905
-
[74]
arXiv preprint arXiv:2412.07752 , year=
FlashRNN: I/O-aware optimization of traditional RNNs on modern hardware , author=. arXiv preprint arXiv:2412.07752 , year=
-
[75]
arXiv preprint arXiv:2403.03950 , year=
Stop regressing: Training value functions via classification for scalable deep rl , author=. arXiv preprint arXiv:2403.03950 , year=
-
[76]
International conference on machine learning , pages=
Stabilizing transformers for reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[77]
Econometrica: Journal of the Econometric Society , pages=
Efficient instrumental variables estimation of nonlinear models , author=. Econometrica: Journal of the Econometric Society , pages=. 1990 , publisher=
1990
-
[78]
Advances in neural information processing systems , volume=
Deep generalized method of moments for instrumental variable analysis , author=. Advances in neural information processing systems , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
Dual instrumental variable regression , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
arXiv preprint arXiv:2405.11633 , year=
Geometry-aware instrumental variable regression , author=. arXiv preprint arXiv:2405.11633 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.