VisDom: Sparse Novel View Synthesis with Visible Domain Constraint
Pith reviewed 2026-06-26 17:44 UTC · model grok-4.3
The pith
A minimum multi-view visibility requirement strengthens the visual hull prior for sparse novel view synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
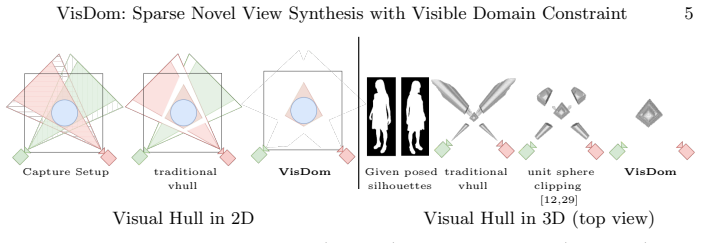
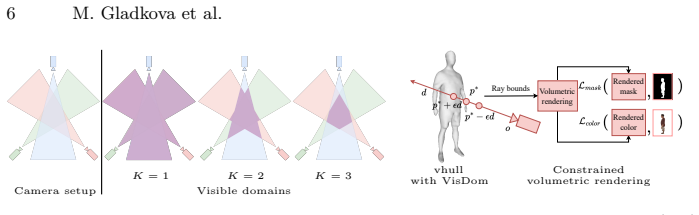
VisDom defines the visible domain as the subset of 3D space that lies inside the viewing frustum of at least K input cameras. This domain is used as an additional hard filter on top of standard visual-hull carving: any point outside the domain is excluded from volumetric sampling in NeRF-style optimization and from candidate Gaussian placement in explicit splatting pipelines. The resulting spatial prior reduces the feasible set of geometries that remain consistent with the input silhouettes, thereby limiting the solutions that can produce floating artifacts in sparse-view settings.
What carries the argument
The visible domain, the 3D region observed by at least K input views, used as a hard filter on sampling and placement.
If this is right
- High-quality object-centric novel-view synthesis becomes possible from only four input images on three challenging datasets.
- The same constraint can be added to both implicit volumetric and explicit point-based pipelines without introducing learned parameters.
- Training cost can be reduced by more than twenty times while matching or exceeding the accuracy of a stronger baseline.
- Only binary silhouettes are needed, making the method domain-agnostic.
Where Pith is reading between the lines
- The same visibility filter could be applied during test-time optimization or to other reconstruction algorithms that already use silhouette consistency.
- Varying K per scene or per region might trade off completeness against artifact suppression in a controllable way.
- Because the domain is computed from camera poses and silhouettes alone, it could serve as a fast pre-filter before more expensive learned regularizers are applied.
Load-bearing premise
Requiring visibility in at least K views removes more incorrect geometry than it discards valid surface points that happen to be seen in fewer views.
What would settle it
A quantitative comparison, on a dataset with known ground-truth geometry, showing that the method either produces artifacts inside the true object or removes correct surface regions when K is set to the value used in the experiments.
Figures







read the original abstract
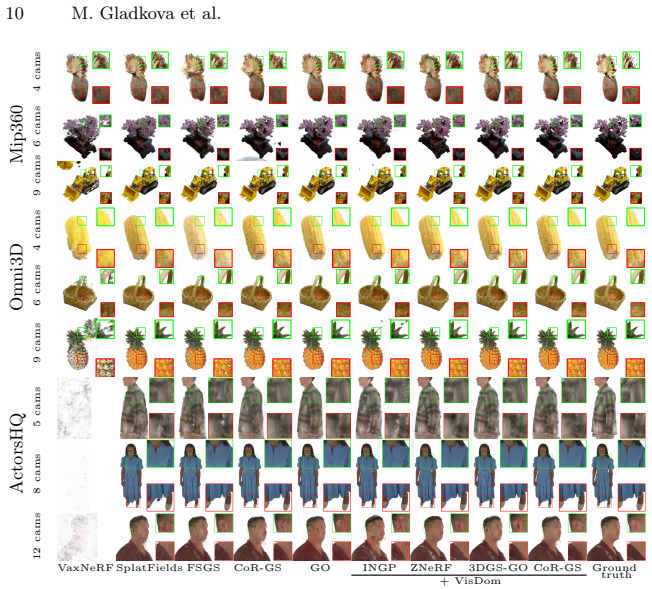
Sparse novel view synthesis (NVS) remains challenging due to the ambiguity of recovering 3D geometry from few input views. While NeRF- and Gaussian Splatting (GS)-based methods perform well with dense supervision, they often overfit in sparse settings, producing floating artifacts and inconsistent geometry. Silhouette consistency is commonly used as a regularizer, but it remains insufficient, as silhouette-consistent regions can extend beyond the true object geometry. We introduce VisDom, a learning-free geometric constraint that augments classical carving-based visual hull reconstruction by enforcing a minimum multi-view visibility requirement. Specifically, we define a visible domain as the subset of 3D space observed by at least $K$ views and use it as an additional filtering criterion on top of standard silhouette-based reconstruction. This provides a stronger spatial prior in sparse-view settings. We integrate VisDom into both implicit (NeRF) and explicit (GS) pipelines by restricting volumetric sampling and guiding Gaussian placement during optimization. Experiments on three challenging datasets show consistent improvements in sparse-view NVS, enabling high-quality object-centric reconstruction from as few as four input images. Our method is domain-agnostic, requires only silhouettes, and introduces no learned parameters, making it a simple complement to existing approaches. Applying VisDom on top of GaussianObject further improves performance on Omni3D and MipNeRF360, while matching or surpassing it at 22 $\times$ lower training cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VisDom, a learning-free geometric constraint for sparse novel view synthesis. It augments classical visual-hull carving by defining a visible domain as the subset of 3D space observed by at least K input views, then uses this domain to restrict volumetric sampling in NeRF and guide Gaussian placement in Gaussian Splatting. The approach requires only silhouettes, introduces no learned parameters, and is claimed to yield consistent improvements on three datasets for object-centric reconstruction from as few as four views; it is also shown to improve upon GaussianObject on Omni3D and Mip-NeRF 360 at substantially lower training cost.
Significance. If the central empirical claim holds after verification, VisDom supplies a simple, reproducible, parameter-light (only K) geometric prior that can be plugged into existing implicit and explicit pipelines without additional learned components. The learning-free construction and explicit integration into both NeRF and GS pipelines are clear strengths that distinguish it from data-driven regularizers.
major comments (2)
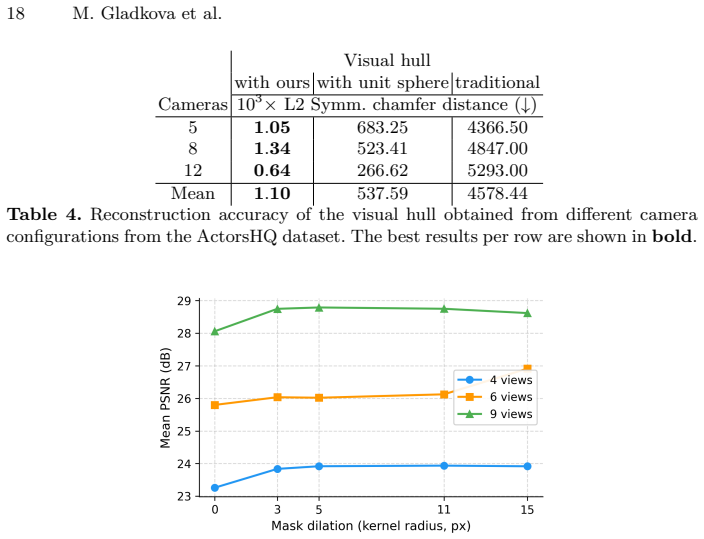
- [Visible domain definition] Visible domain definition: the claim that the K-view filter removes only incorrect geometry while preserving all true surface points is load-bearing for the improvement-without-harm assertion, yet the manuscript provides no analysis or counter-example check for the N=4 sparse case where self-occlusion routinely produces surface regions visible in only 1–2 silhouettes; any K>2 therefore risks carving away legitimate geometry that standard visual-hull (K=N) would retain.
- [Integration into NeRF and GS pipelines] Integration and optimization sections: the description of how the visible domain restricts NeRF sampling and guides GS placement lacks concrete implementation details (e.g., how the domain is discretized or queried during each optimization step), making it impossible to assess whether the reported gains are attributable to the geometric prior or to incidental changes in sampling density.
minor comments (2)
- [Method] The choice of K is listed as the sole free parameter but no guidance or ablation is given on its selection across the three datasets.
- [Experiments] Figure captions and table headers should explicitly state the value of K used for each reported result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with clarifications and commitments to strengthen the manuscript where the points identify gaps in analysis or detail.
read point-by-point responses
-
Referee: [Visible domain definition] Visible domain definition: the claim that the K-view filter removes only incorrect geometry while preserving all true surface points is load-bearing for the improvement-without-harm assertion, yet the manuscript provides no analysis or counter-example check for the N=4 sparse case where self-occlusion routinely produces surface regions visible in only 1–2 silhouettes; any K>2 therefore risks carving away legitimate geometry that standard visual-hull (K=N) would retain.
Authors: We acknowledge that the manuscript asserts the K-view filter primarily removes incorrect geometry without harming true surfaces, yet provides no dedicated analysis or counter-examples for the N=4 case under self-occlusion. In practice we select K=2 for four-view experiments to limit this risk, and results show gains without new artifacts, but this does not fully address the theoretical concern. We will add a discussion section with visibility-count analysis on true surfaces (using ground-truth meshes where available) and counter-example checks in the revision. revision: yes
-
Referee: [Integration into NeRF and GS pipelines] Integration and optimization sections: the description of how the visible domain restricts NeRF sampling and guides GS placement lacks concrete implementation details (e.g., how the domain is discretized or queried during each optimization step), making it impossible to assess whether the reported gains are attributable to the geometric prior or to incidental changes in sampling density.
Authors: We agree the current description lacks sufficient implementation specifics on discretization and per-step querying. The visible domain is precomputed once as a binary 3D mask from the silhouettes and then applied to filter samples or guide placement, but details such as grid resolution, data structure, and exact lookup method during optimization are not fully specified. In the revised manuscript we will expand these sections with pseudocode, explicit discretization parameters, and querying procedure to enable readers to isolate the contribution of the prior. revision: yes
Circularity Check
No significant circularity: VisDom is an explicit geometric construction from input silhouettes
full rationale
The paper defines the visible domain directly as the 3D subset observed by at least K input views (a deterministic carving operation on the given silhouettes) and applies it as a hard filter on sampling/placement. This construction is independent of any optimization parameters or learned quantities inside NeRF/GS; the claimed improvement is an empirical outcome on held-out views rather than a quantity forced by the definition itself. No self-citation chains, fitted-input-as-prediction, or ansatz smuggling appear in the derivation. The method is explicitly learning-free with zero learned parameters, making the central prior self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Input silhouettes accurately delineate object boundaries from each camera viewpoint.
invented entities (1)
-
Visible domain
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CVPR (2022)
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. CVPR (2022)
2022
-
[2]
ICCV (2023)
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields. ICCV (2023)
2023
-
[3]
Stanford University (1974)
Baumgart, B.G.: Geometric modeling for computer vision. Stanford University (1974)
1974
-
[4]
In: CVPR
Brazil, G., Kumar, A., Straub, J., Ravi, N., Johnson, J., Gkioxari, G.: Omni3D: A large benchmark and model for 3D object detection in the wild. In: CVPR. IEEE, Vancouver, Canada (June 2023)
2023
-
[5]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Chibane, J., Bansal, A., Lazova, V., Pons-Moll, G.: Stereo radiance fields (srf): Learning view synthesis from sparse views of novel scenes. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (jun 2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deng, K., Liu, A., Zhu, J.Y., Ramanan, D.: Depth-supervised nerf: Fewer views and faster training for free. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12882–12891 (2022)
2022
-
[7]
In: British Machine Vision Conference (BMVC’03)
Franco, J.S., Boyer, E.: Exact polyhedral visual hulls. In: British Machine Vision Conference (BMVC’03). vol. 1, pp. 329–338 (2003)
2003
-
[8]
ACM Transactions on Graphics (TOG)42(4), 1–12 (2023)
I¸ sık, M., R¨ unz, M., Georgopoulos, M., Khakhulin, T., Starck, J., Agapito, L., Nießner, M.: Humanrf: High-fidelity neural radiance fields for humans in motion. ACM Transactions on Graphics (TOG)42(4), 1–12 (2023). https://doi.org/10. 1145/3592415, https://doi.org/10.1145/3592415
-
[9]
ACM Transactions on Graphics42(4) (July 2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimk¨ uhler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, M., Seo, S., Han, B.: Infonerf: Ray entropy minimization for few-shot neural volume rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12912–12921 (2022)
2022
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4015–4026 (2023)
2023
-
[12]
arXiv preprint arXiv:2111.13112 (2021)
Kondo, N., Ikeda, Y., Tagliasacchi, A., Matsuo, Y., Ochiai, Y., Gu, S.S.: Vaxnerf: Revisiting the classic for voxel-accelerated neural radiance field. arXiv preprint arXiv:2111.13112 (2021)
arXiv 2021
-
[13]
International journal of computer vision38, 199–218 (2000)
Kutulakos, K.N., Seitz, S.M.: A theory of shape by space carving. International journal of computer vision38, 199–218 (2000)
2000
-
[14]
IEEE Transactions on pattern analysis and machine intelligence16(2), 150–162 (1994)
Laurentini, A.: The visual hull concept for silhouette-based image understanding. IEEE Transactions on pattern analysis and machine intelligence16(2), 150–162 (1994)
1994
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, J., Zhang, J., Bai, X., Zheng, J., Ning, X., Zhou, J., Gu, L.: Dngaussian: Opti- mizing sparse-view 3d gaussian radiance fields with global-local depth normaliza- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20775–20785 (2024)
2024
-
[16]
In: Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques
Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface con- struction algorithm. In: Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques. p. 163–169. SIGGRAPH ’87, Association for Computing Machinery, New York, NY, USA (1987). https://doi.org/10.1145/ 37401.37422, https://doi.org/10.1145/37401.37422...
-
[17]
In: European Conference on Computer Vision (ECCV)
Mihajlovic, M., Prokudin, S., Tang, S., Maier, R., Bogo, F., Tung, T., Boyer, E.: Splatfields: Neural gaussian splats for sparse 3d and 4d reconstruction. In: European Conference on Computer Vision (ECCV). Springer (2024)
2024
-
[18]
In: ECCV (2020)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
2020
-
[19]
M¨ uller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primi- tives with a multiresolution hash encoding. ACM Trans. Graph.41(4), 102:1– 102:15 (Jul 2022). https://doi.org/10.1145/3528223.3530127, https://doi.org/10. 1145/3528223.3530127
-
[20]
In: Proc
Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S.M., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse in- puts. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[21]
In: Pro- ceedings IEEE Conf
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.: Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In: Pro- ceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2020)
2020
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[23]
Shi, R., Wei, X., Wang, C., Su, H.: Zerorf: Fast sparse view 360deg reconstruction with zero pretraining (2023)
2023
-
[24]
In: Tenth IEEE Inter- national Conference on Computer Vision (ICCV’05) Volume 1
Sinha, S.N., Pollefeys, M.: Multi-view reconstruction using photo-consistency and exact silhouette constraints: A maximum-flow formulation. In: Tenth IEEE Inter- national Conference on Computer Vision (ICCV’05) Volume 1. vol. 1, pp. 349–356. IEEE (2005)
2005
-
[25]
In: Eurographics Symposium on Rendering (2021)
Sun, T., Lin, K.E., Bi, S., Xu, Z., Ramamoorthi, R.: Nelf: Neural light-transport field for portrait view synthesis and relighting. In: Eurographics Symposium on Rendering (2021)
2021
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, G., Chen, Z., Loy, C.C., Liu, Z.: Sparsenerf: Distilling depth ranking for few-shot novel view synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9065–9076 (2023)
2023
-
[27]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Wu, J., Li, R., Zhu, Y., Guo, R., Sun, J., Zhang, Y.: Sparse2dgs: Geometry- prioritized gaussian splatting for surface reconstruction from sparse views. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 11307– 11316 (2025)
2025
-
[28]
In: CVPR (2023)
Wynn, J., Turmukhambetov, D.: DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models. In: CVPR (2023)
2023
-
[29]
arXiv preprint arXiv:2402.10259 (2024)
Yang, C., Li, S., Fang, J., Liang, R., Xie, L., Zhang, X., Shen, W., Tian, Q.: Gaus- sianobject: Just taking four images to get a high-quality 3d object with gaussian splatting. arXiv preprint arXiv:2402.10259 (2024)
arXiv 2024
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, J., Pavone, M., Wang, Y.: Freenerf: Improving few-shot neural rendering with free frequency regularization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8254–8263 (2023)
2023
-
[31]
Advances in Neural Information Processing Systems33, 2492–2502 (2020)
Yariv, L., Kasten, Y., Moran, D., Galun, M., Atzmon, M., Ronen, B., Lipman, Y.: Multiview neural surface reconstruction by disentangling geometry and appear- ance. Advances in Neural Information Processing Systems33, 2492–2502 (2020)
2020
-
[32]
In: CVPR (2021) VisDom: Sparse Novel View Synthesis with Visible Domain Constraint 15
Yu, A., Ye, V., Tancik, M., Kanazawa, A.: pixelNeRF: Neural radiance fields from one or few images. In: CVPR (2021) VisDom: Sparse Novel View Synthesis with Visible Domain Constraint 15
2021
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, Z., Chen, A., Huang, B., Sattler, T., Geiger, A.: Mip-splatting: Alias-free 3d gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19447–19456 (2024)
2024
-
[34]
Advances in neural information processing systems35, 25018–25032 (2022)
Yu, Z., Peng, S., Niemeyer, M., Sattler, T., Geiger, A.: Monosdf: Exploring monoc- ular geometric cues for neural implicit surface reconstruction. Advances in neural information processing systems35, 25018–25032 (2022)
2022
-
[35]
arXiv preprint arXiv:2405.12110 (2024)
Zhang, J., Li, J., Yu, X., Huang, L., Gu, L., Zheng, J., Bai, X.: Cor-gs: Sparse- view 3d gaussian splatting via co-regularization. arXiv preprint arXiv:2405.12110 (2024)
arXiv 2024
-
[36]
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models (2023)
2023
-
[37]
In: European conference on computer vision
Zhu, Z., Fan, Z., Jiang, Y., Wang, Z.: Fsgs: Real-time few-shot view synthesis using gaussian splatting. In: European conference on computer vision. pp. 145–
-
[38]
Gladkova et al
Springer (2024) 16 M. Gladkova et al. Supplementary Material — VisDom: Sparse Novel View Synthesis with Visible Domain Constraint In this supplementary, we first provide background on NeRF and 3DGS in sec- tion A and dataset details in section B.In section C we show the impact of our constraint on reconstructing the visual hull and study the performance o...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.