The FID Lottery: Quantifying Hidden Randomness in Generative-Model Evaluation
Pith reviewed 2026-06-26 17:40 UTC · model grok-4.3
The pith
Retraining generative models with different seeds shifts FID 3.2 times more than changing the sampling seed from a fixed model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
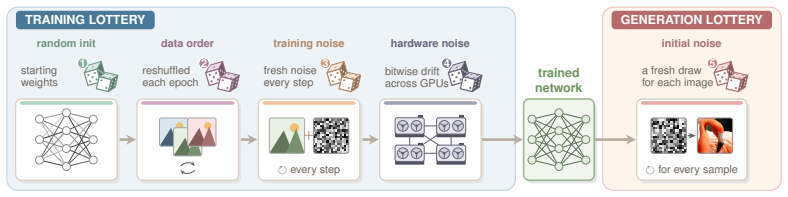
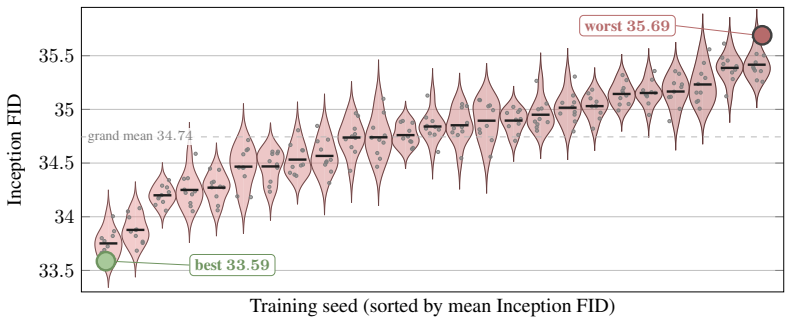
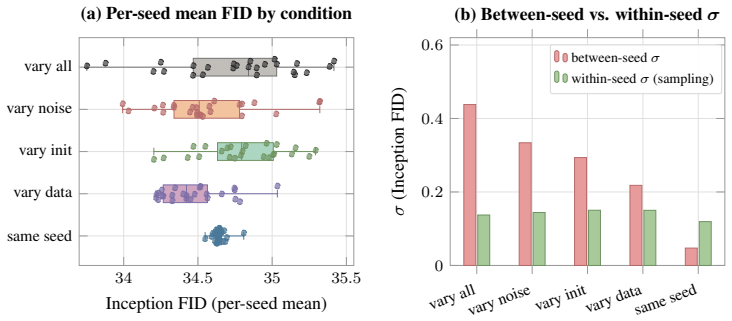
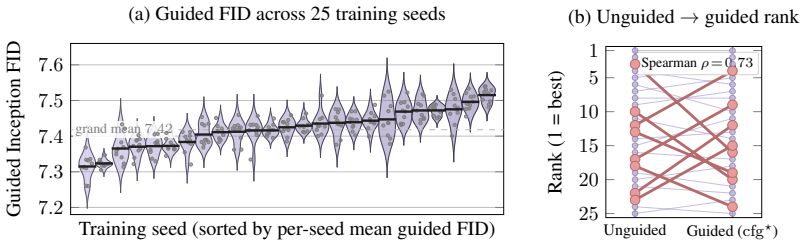
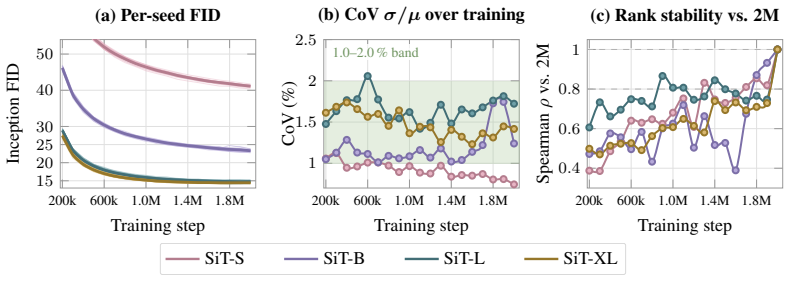
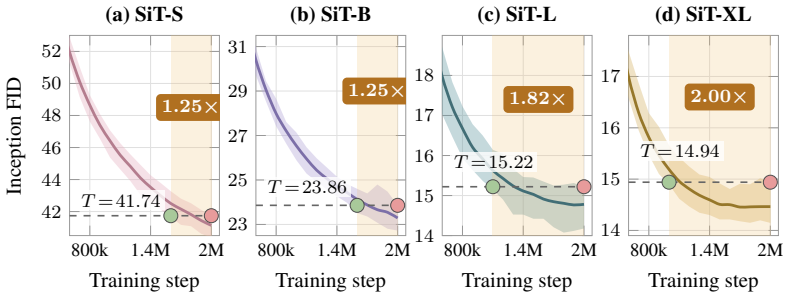
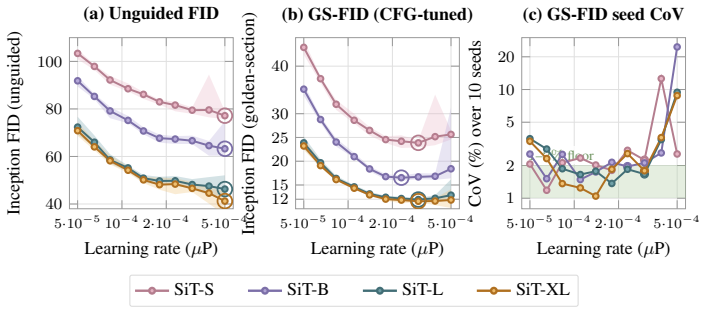
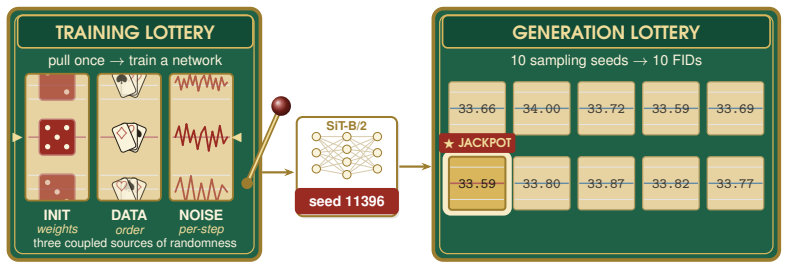
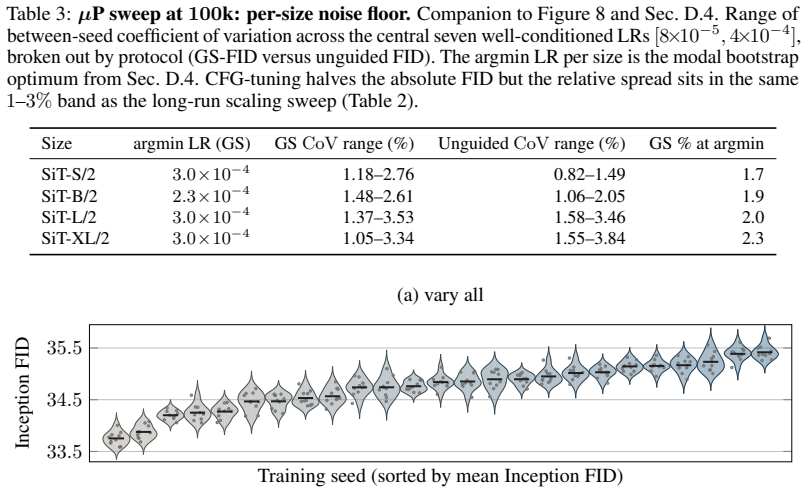
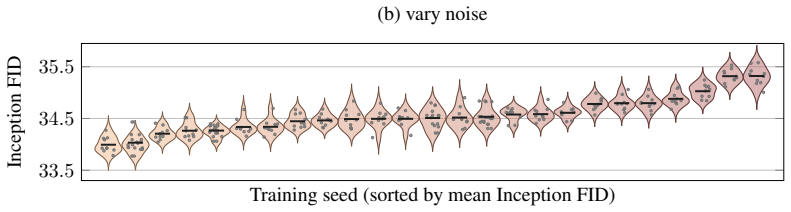
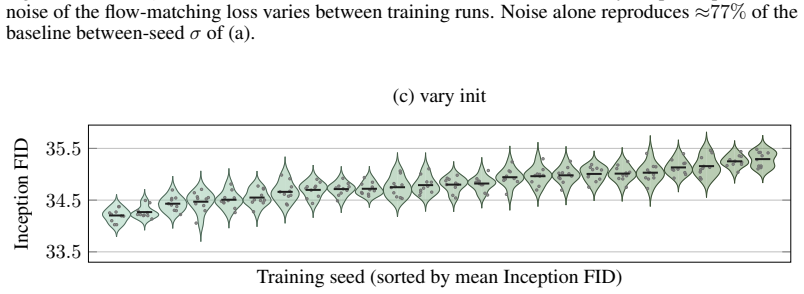
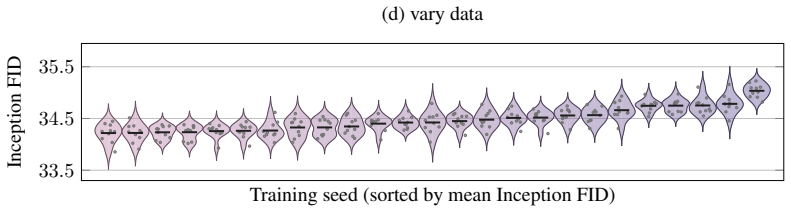
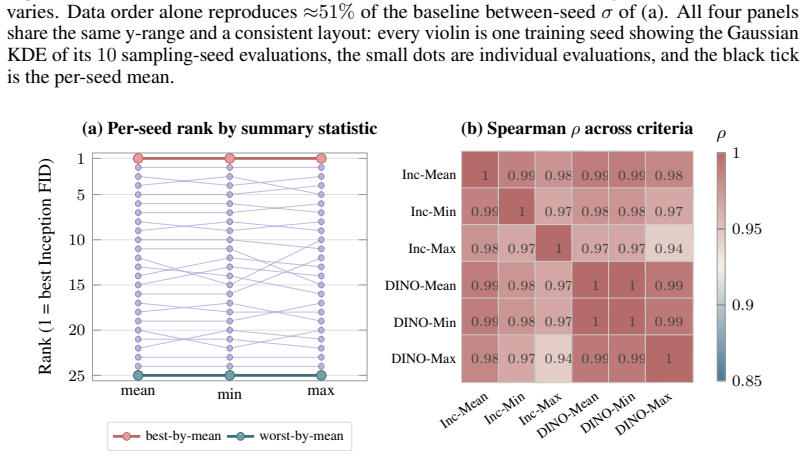
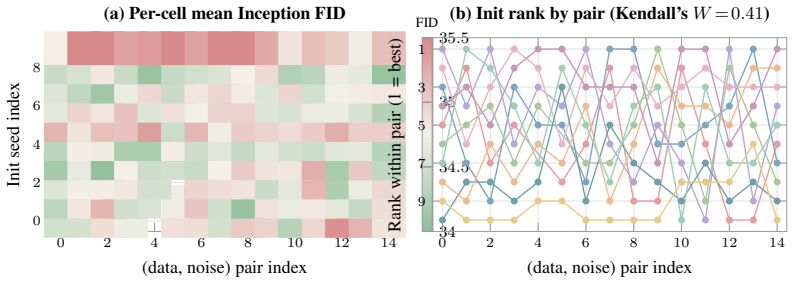
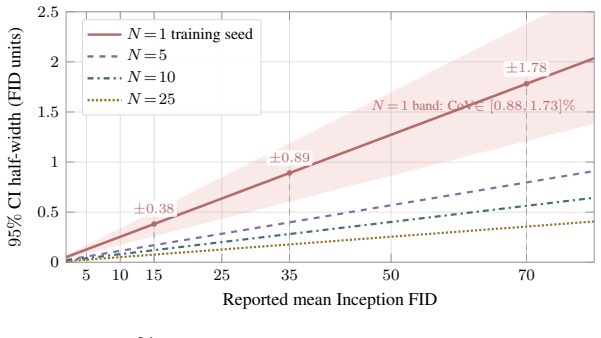
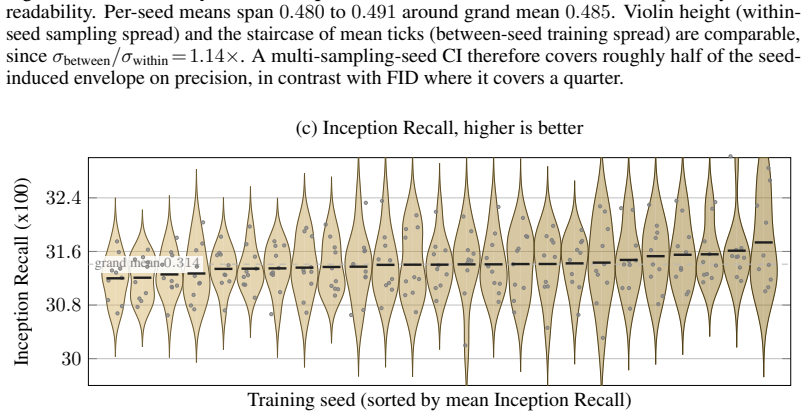
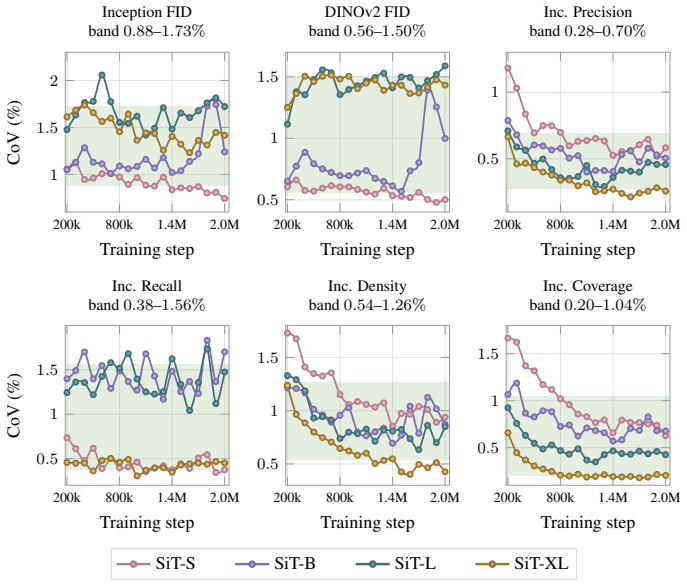
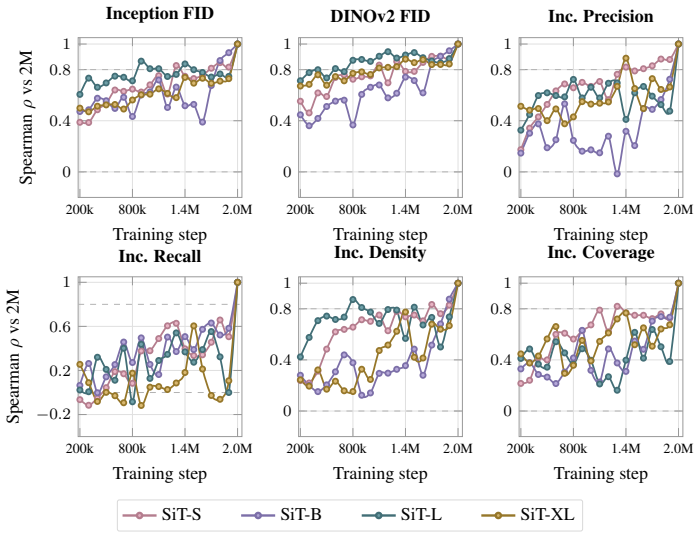
On a two-axis panel of training and generation seeds, retraining the model moves FID 3.2 times farther in Inception feature space than redrawing samples from a fixed network; the gap is produced by random initialization, data ordering, and per-step Gaussian noise; the coefficient of variation remains inside 1-2 percent even when compute or model size grows; and per-cell guidance tuning halves the spread while reshuffling rankings so that a lucky seed reaches target FID with up to twice less compute.
What carries the argument
Two-axis panel of training seeds and generation seeds on which FID is treated as a random variable and measured directly across hundreds of trained networks.
If this is right
- Per-cell classifier-free-guidance tuning halves the observed FID spread.
- Any reported FID gap smaller than the measured 1.3 percent coefficient of variation should be treated as inconclusive.
- A lucky training seed can reach the same FID value with up to 2 times less compute than an unlucky seed.
- Evaluations should report an error bar over several training seeds rather than a single FID number.
Where Pith is reading between the lines
- Current generative-model leaderboards that publish single FID numbers are likely to contain many inconclusive comparisons.
- The same hidden training-seed variance may affect other popular metrics such as CLIP score or precision-recall.
- Averaging FID over a small number of independent training runs could produce more stable model rankings at modest extra cost.
- The finding raises the question whether similar seed-driven variance appears in non-diffusion generative models.
Load-bearing premise
The variance patterns and driving factors observed on SiT networks trained on class-conditional ImageNet 256x256 generalize to other generative architectures, datasets, and training recipes.
What would settle it
Repeating the full two-axis experiment on a different architecture or dataset and obtaining a training-seed to sampling-seed variance ratio far from 3.2 would falsify the central quantitative claim.
Figures




















read the original abstract
The Frechet Inception Distance (FID) is the de facto arbiter of image generation, yet most papers report just a single number from a single trained model using a single sampling seed. How reproducible is that number if we retrain the model, or merely resample from it? In this paper, we treat FID as a random variable on a two-axis panel of training and generation seeds, and measure its variance directly on several hundred SiT networks trained on class-conditional ImageNet 256x256. We report surprising findings: (a) Retraining the model using the same recipe with a different seed moves FID 3.2x more (in Inception feature space) than redrawing samples from a fixed network. (b) That gap is driven by three factors: random initialisation, data ordering, and the per-step Gaussian noise of the flow-matching loss. (c) Increasing compute or model size barely tightens the spread, holding the FID coefficient of variation (CoV) inside a 1-2% band. (d) Per-cell classifier-free-guidance tuning halves the spread but reshuffles which seeds work best, and a lucky training seed reaches the same FID with up to 2x less compute than an unlucky one. Based on these findings, we recommend a new FID evaluation protocol: evaluate under per-cell optimal guidance, treat any FID gap below the empirically measured ~1.3% CoV as inconclusive, and report an error bar over several training seeds rather than a single FID number.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper treats FID as a random variable over training and sampling seeds and measures its variance directly on several hundred SiT networks trained on class-conditional ImageNet 256x256. It reports that training-seed variance is 3.2x larger than sampling-seed variance in Inception space, identifies three driving factors (random initialization, data ordering, per-step Gaussian noise), finds that the coefficient of variation remains inside a 1-2% band even with increased compute or model size, shows that per-cell classifier-free-guidance tuning halves the spread, and recommends a new evaluation protocol: per-cell optimal guidance, treat gaps below ~1.3% CoV as inconclusive, and report error bars over training seeds rather than a single FID.
Significance. If the empirical variance measurements hold, the work provides direct evidence that single FID numbers are unreliable and that training randomness dominates sampling randomness. The scale of the experiment (hundreds of models) and the use of direct empirical computations without fitted parameters or self-referential definitions are strengths. The protocol recommendations would meaningfully change evaluation standards in generative modeling if the observed variance structure generalizes.
major comments (2)
- [Abstract and experimental results] The central quantitative claims (3.2x ratio, 1-2% CoV) and the three protocol recommendations are derived exclusively from SiT networks on class-conditional ImageNet 256x256; no results are shown for other architectures (GANs, diffusion, autoregressive), losses, or datasets. This makes the generalization premise for the recommendations unverified and load-bearing for the paper's broader impact.
- [Methods and appendix] Limited detail is provided on the statistical tests supporting the variance claims, the exact rules for model exclusion, and controls for confounding factors (e.g., training duration, hyperparameter stability). This leaves room for unstated post-hoc choices that could affect the reported ratios and CoV bounds.
minor comments (1)
- [Experimental setup] The manuscript would benefit from an explicit statement of the precise number of models, seeds, and samples per cell in the main text rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the scale of the experiments and the direct empirical approach. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and experimental results] The central quantitative claims (3.2x ratio, 1-2% CoV) and the three protocol recommendations are derived exclusively from SiT networks on class-conditional ImageNet 256x256; no results are shown for other architectures (GANs, diffusion, autoregressive), losses, or datasets. This makes the generalization premise for the recommendations unverified and load-bearing for the paper's broader impact.
Authors: We agree that all quantitative results and protocol recommendations are derived solely from SiT models on class-conditional ImageNet 256x256. The manuscript frames the work as a detailed empirical study on this benchmark rather than a universal claim. We will revise the abstract, introduction, and conclusion to explicitly limit the scope of the claims and recommendations to the studied setting, removing any implication of broader generalization. We cannot add results for other architectures or datasets without new experiments. revision: yes
-
Referee: [Methods and appendix] Limited detail is provided on the statistical tests supporting the variance claims, the exact rules for model exclusion, and controls for confounding factors (e.g., training duration, hyperparameter stability). This leaves room for unstated post-hoc choices that could affect the reported ratios and CoV bounds.
Authors: We will expand the methods section and appendix with additional detail on the statistical procedures used to compute variances and ratios, the exact exclusion criteria applied to trained models, and controls for training duration and hyperparameter stability. These additions will include explicit statements confirming that no post-hoc selections were made that could bias the reported 3.2x ratio or 1-2% CoV bounds. revision: yes
- Empirical verification of the variance structure and protocol recommendations on architectures other than SiT, different losses, or datasets other than class-conditional ImageNet 256x256.
Circularity Check
No circularity; all claims are direct empirical measurements on trained models
full rationale
The paper reports variance ratios, CoV bounds, and driving factors obtained by explicitly training several hundred SiT networks on ImageNet 256x256 under varied seeds and computing FID directly in Inception space. No derivation, equation, or prediction reduces to a fitted parameter, self-definition, or self-citation chain; the 3.2x ratio and 1-2% CoV are computed quantities, not outputs forced by the paper's own formalism. The protocol recommendations follow from these measurements without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
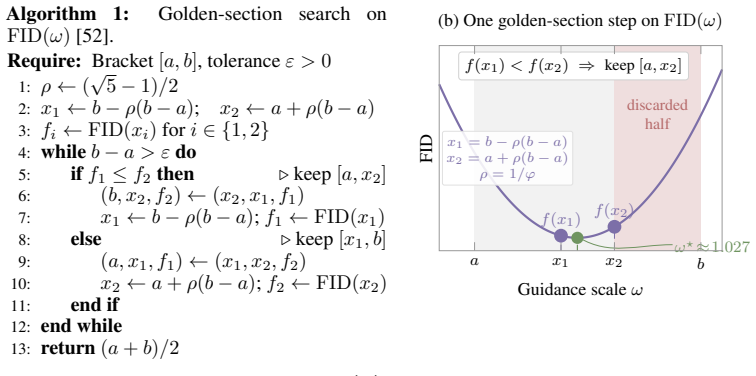
- domain assumption FID computed in Inception-v3 feature space is a stable and meaningful measure of distribution distance between real and generated images
- domain assumption The SiT training recipe and ImageNet 256x256 setup are representative enough for the observed variance patterns to be informative
Reference graph
Works this paper leans on
- [1]
-
[2]
Shane Barratt and Rishi Sharma. A note on the inception score.arXiv preprint arXiv:1801.01973, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Time for a change: a tutorial for comparing multiple classifiers through Bayesian analysis.Journal of Machine Learning Research, 2017
Alessio Benavoli, Giorgio Corani, Janez Demšar, and Marco Zaffalon. Time for a change: a tutorial for comparing multiple classifiers through Bayesian analysis.Journal of Machine Learning Research, 2017
2017
-
[4]
Ciaran Bench and Spencer Angus Thomas. Quantifying the uncertainty of model-based synthetic image quality metrics.arXiv preprint arXiv:2504.03623, 2025
-
[5]
Princeton University Press, 2007
Rajendra Bhatia.Positive Definite Matrices. Princeton University Press, 2007
2007
-
[6]
Sutherland, Michael Arbel, and Arthur Gretton
Mikołaj Bi´nkowski, Danica J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. In6th International Conference on Learning Representations (ICLR), 2018
2018
-
[7]
Pros and cons of GAN evaluation measures.Computer Vision and Image Under- standing, 2019
Ali Borji. Pros and cons of GAN evaluation measures.Computer Vision and Image Under- standing, 2019
2019
-
[8]
Pros and cons of GAN evaluation measures: New developments.Computer Vision and Image Understanding, 2022
Ali Borji. Pros and cons of GAN evaluation measures: New developments.Computer Vision and Image Understanding, 2022
2022
-
[9]
Unreproducible research is reproducible
Xavier Bouthillier, César Laurent, and Pascal Vincent. Unreproducible research is reproducible. InProceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[10]
Accounting for variance in machine learning benchmarks
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, Assya Trofimov, Brennan Nichyporuk, Justin Szeto, Naz Sepah, Edward Raff, Kanika Madan, Vikram V oleti, Samira Ebrahimi Kahou, Vincent Michalski, Dmitriy Serdyuk, Tal Arbel, Chris Pal, Gaël Varoquaux, and Pascal Vincent. Accounting for variance in machine learning benchmarks. InProceedings of Machine Lear...
2021
-
[11]
Brent.Algorithms for Minimization without Derivatives
Richard P. Brent.Algorithms for Minimization without Derivatives. Prentice-Hall, 1973
1973
-
[12]
Effectively unbiased FID and inception score and where to find them
Min Jin Chong and David Forsyth. Effectively unbiased FID and inception score and where to find them. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[13]
Questionable answers in question answering research: Reproducibility and vari- ability of published results.Transactions of the Association for Computational Linguistics, 2018
Matt Crane. Questionable answers in question answering research: Reproducibility and vari- ability of published results.Transactions of the Association for Computational Linguistics, 2018
2018
-
[14]
Alexander D’Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yian Ma, Cory McLean, Diana Mincu, Akinori Mitani, Andrea Montanari, Zachary Nado, Vivek Nataraj...
2022
-
[15]
How far can we go with ImageNet for text-to-image generation? InAdvances in Neural Information Processing Systems 38 (NeurIPS), 2025
Lucas Degeorge, Arijit Ghosh, Nicolas Dufour, David Picard, and Vicky Kalogeiton. How far can we go with ImageNet for text-to-image generation? InAdvances in Neural Information Processing Systems 38 (NeurIPS), 2025
2025
-
[16]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine Learning Research, 2006. 12
2006
-
[17]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009
2009
-
[18]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[19]
DiCiccio and Bradley Efron
Thomas J. DiCiccio and Bradley Efron. Bootstrap confidence intervals.Statistical Science, 1996
1996
-
[20]
Dietterich
Thomas G. Dietterich. Approximate statistical tests for comparing supervised classification learning algorithms.Neural Computation, 1998
1998
-
[21]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. Show your work: Improved reporting of experimental results. InProceedings of EMNLP-IJCNLP, 2019
2019
- [22]
-
[23]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[24]
The hitchhiker’s guide to testing statistical significance in natural language processing
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. The hitchhiker’s guide to testing statistical significance in natural language processing. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Volume 1: Long Papers, 2018
2018
-
[25]
Multiple comparisons among means.Journal of the American Statistical Association, 1961
Olive Jean Dunn. Multiple comparisons among means.Journal of the American Statistical Association, 1961
1961
-
[26]
B. Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 1979
1979
-
[27]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[28]
Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserman. The Pascal visual object classes challenge: A retrospective.International Journal of Computer Vision, 2014
2014
-
[29]
Deep ensembles: A loss landscape perspective.arXiv preprint arXiv:1912.02757, 2019
Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. Deep ensembles: A loss landscape perspective.arXiv preprint arXiv:1912.02757, 2019
-
[30]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[31]
Roy, and Michael Carbin
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M. Roy, and Michael Carbin. Linear mode connectivity and the lottery ticket hypothesis. InProceedings of the 37th International Conference on Machine Learning (ICML), 2020
2020
-
[32]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS), 2010
2010
-
[33]
State of the art: Reproducibility in artificial intelligence
Odd Erik Gundersen and Sigbjørn Kjensmo. State of the art: Reproducibility in artificial intelligence. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[34]
Defeating nondeterminism in LLM inference
Horace He and Thinking Machines Lab. Defeating nondeterminism in LLM inference. https: //thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/ ,
-
[35]
Thinking Machines Lab blog; accessed 2026. 13
2026
-
[36]
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2015
2015
-
[37]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[38]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[39]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam McCandlish. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010....
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[40]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems 30 (NIPS 2017), 2017
2017
-
[42]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems 33 (NeurIPS), 2020
2020
-
[44]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
2022
-
[45]
Rethinking FID: Towards a better evaluation metric for image generation
Sadeep Jayasumana, Srikumar Ramalingam, Andreas Veit, Daniel Glasner, Ayan Chakrabarti, and Sanjiv Kumar. Rethinking FID: Towards a better evaluation metric for image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[46]
Keller Jordan. Calibrated chaos: Variance between runs of neural network training is harmless and inevitable.arXiv preprint arXiv:2304.01910, 2023
-
[47]
Simoncelli, and Stéphane Mallat
Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, and Stéphane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representations. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[48]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[49]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[50]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems 35 (NeurIPS), 2022. 14
2022
-
[51]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[52]
M. G. Kendall and B. Babington Smith. The problem ofm rankings.The Annals of Mathematical Statistics, 1939
1939
-
[53]
J. Kiefer. Sequential minimax search for a maximum.Proceedings of the American Mathemati- cal Society, 1953
1953
-
[54]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In3rd International Conference on Learning Representations (ICLR), 2015
2015
-
[55]
Kingma, Tim Salimans, Ben Poole, and Jonathan Ho
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. InAdvances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[56]
Improved precision and recall metric for assessing generative models
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. InAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019
2019
-
[57]
The role of ImageNet classes in Fréchet inception distance
Tuomas Kynkäänniemi, Tero Karras, Miika Aittala, Timo Aila, and Jaakko Lehtinen. The role of ImageNet classes in Fréchet inception distance. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[58]
Data set selection.Journal of Machine Learning Gossip, 2003
Doudou LaLoudouana, Mambobo Bonouliqui Tarare, Lupano Tecallonou Center, and GUANA Selacie. Data set selection.Journal of Machine Learning Gossip, 2003
2003
-
[59]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. InAdvances in Neural Information Processing Systems 37 (NeurIPS), 2024
2024
-
[60]
Scaling laws for diffusion transformers
Zhengyang Liang, Hao He, Ceyuan Yang, and Bo Dai. Scaling laws for diffusion transformers. arXiv preprint arXiv:2410.08184, 2024
-
[61]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[62]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[63]
Are GANs created equal? A large-scale study
Mario Lucic, Karol Kurach, Marcin Michalski, Sylvain Gelly, and Olivier Bousquet. Are GANs created equal? A large-scale study. InAdvances in Neural Information Processing Systems 31 (NeurIPS), 2018
2018
-
[64]
Albergo, Nicholas M
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InComputer Vision – ECCV 2024, 2024
2024
-
[65]
On model stability as a function of random seed
Pranava Madhyastha and Rishabh Jain. On model stability as a function of random seed. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), 2019
2019
-
[66]
On the state of the art of evaluation in neural language models
Gábor Melis, Chris Dyer, and Phil Blunsom. On the state of the art of evaluation in neural language models. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[67]
On self-supervised image representa- tions for GAN evaluation
Stanislav Morozov, Andrey V oynov, and Artem Babenko. On self-supervised image representa- tions for GAN evaluation. In9th International Conference on Learning Representations (ICLR), 2021
2021
-
[68]
On the stability of fine- tuning BERT: Misconceptions, explanations, and strong baselines
Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. On the stability of fine- tuning BERT: Misconceptions, explanations, and strong baselines. InInternational Conference on Learning Representations (ICLR), 2021. 15
2021
-
[69]
Reliable fidelity and diversity metrics for generative models
Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. InProceedings of the 37th International Conference on Machine Learning, 2020
2020
-
[70]
Zico Kolter
Vaishnavh Nagarajan and J. Zico Kolter. Uniform convergence may be unable to explain generalization in deep learning. InAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019
2019
-
[71]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[72]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patric...
2024
-
[73]
On aliased resizing and surprising subtleties in GAN evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in GAN evaluation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[74]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[75]
Problems and opportunities in training deep learning software systems: An analysis of variance
Hung Viet Pham, Shangshu Qian, Jiannan Wang, Thibaud Lutellier, Jonathan Rosenthal, Lin Tan, Yaoliang Yu, and Nachiappan Nagappan. Problems and opportunities in training deep learning software systems: An analysis of variance. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2020
2020
-
[76]
David Picard. Torch.manual_seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision.arXiv preprint arXiv:2109.08203, 2021
-
[77]
Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program).Journal of Machine Learning Research, 2021
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program).Journal of Machine Learning Research, 2021
2019
-
[78]
A step toward quantifying independently reproducible machine learning research
Edward Raff. A step toward quantifying independently reproducible machine learning research. InAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019
2019
-
[79]
Do ImageNet classifiers generalize to ImageNet? InProceedings of the 36th International Conference on Machine Learning (ICML), 2019
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do ImageNet classifiers generalize to ImageNet? InProceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[80]
Reporting score distributions makes a difference: Perfor- mance study of LSTM-networks for sequence tagging
Nils Reimers and Iryna Gurevych. Reporting score distributions makes a difference: Perfor- mance study of LSTM-networks for sequence tagging. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.