Confidence Laundering in Agent Systems: Why Uncertainty Needs a Latent Carrier
Pith reviewed 2026-06-27 12:51 UTC · model grok-4.3
The pith
Agent systems lose uncertainty at component handoffs, turning local fragility into downstream overconfidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
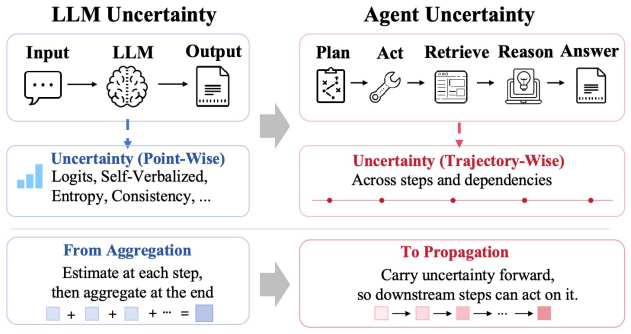
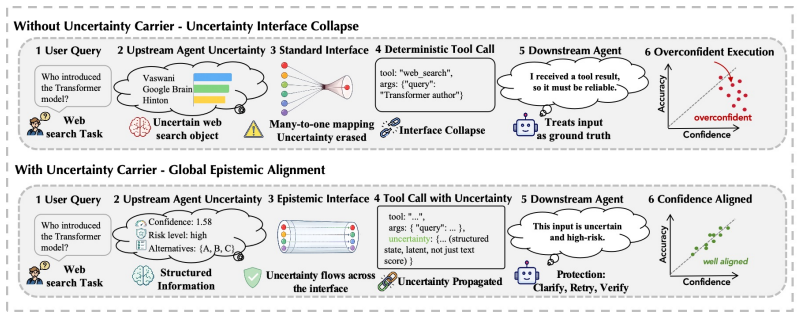
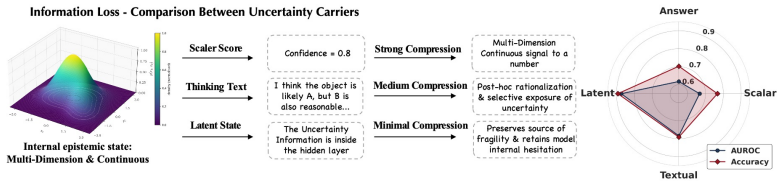
Uncertainty does not propagate through an agent trajectory simply because some steps are uncertain; it propagates only when it survives the handoff between components. Fragile upstream states are often repackaged as procedurally valid artifacts that downstream agents over-trust, a failure the authors call confidence laundering. They propose latent uncertainty as an uncertainty-bearing carrier attached to decision handoffs that preserves pre-commitment fragility in a form downstream components can use without replacing text outputs with hidden states.
What carries the argument
latent uncertainty, an uncertainty-bearing carrier attached to decision handoffs that preserves upstream fragility for downstream use
If this is right
- Uncertainty propagates only through surviving handoffs, not through the mere existence of uncertain steps in a trajectory.
- Local ambiguity can become system-level error amplification when fragile states are presented as clean artifacts.
- Attaching a latent uncertainty carrier to handoffs preserves pre-commitment fragility for downstream components.
- Agent uncertainty handling should shift from step-wise estimation to uncertainty-preserving interface design.
Where Pith is reading between the lines
- Existing modular agent frameworks could be extended with explicit handoff protocols that carry uncertainty markers alongside text outputs.
- The same interface bottleneck may appear in human-AI collaboration when intermediate outputs hide the uncertainty behind them.
- Testing whether current agent benchmarks already contain hidden confidence laundering would require logging uncertainty at each handoff point.
- Recoverable agent systems might need standardized carrier formats so that different component types can interpret upstream fragility without custom engineering.
Load-bearing premise
Downstream components will actually read and act on a latent uncertainty carrier attached to handoffs instead of ignoring it or demanding replacement of text outputs.
What would settle it
A controlled comparison of agent chains with and without explicit latent uncertainty carriers at handoffs, measuring whether the carrier version shows measurably lower rates of error amplification from upstream uncertain decisions.
Figures

read the original abstract
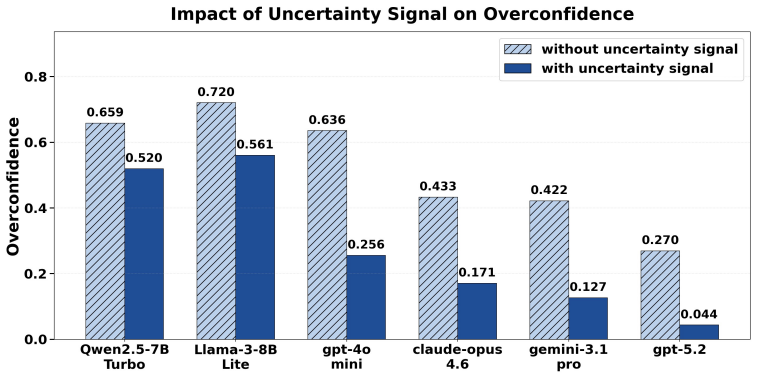
Modern agent systems can turn uncertainty into overconfidence. Fragile upstream decisions are often exposed to downstream components as clean intermediate artifacts, while the uncertainty behind those decisions is lost at the interface. As a result, local ambiguity can become system-level error amplification. We argue that this reveals an interface bottleneck in agent uncertainty propagation: uncertainty does not propagate simply because a trajectory contains uncertain steps; it propagates only when it survives the handoff between components. We define uncertain decision handoff as the transfer of an intermediate decision made under uncertainty, and identify confidence laundering as a failure mode in which fragile upstream states are repackaged as procedurally valid artifacts that downstream agents over-trust. To address this bottleneck, we propose latent uncertainty as an uncertainty-bearing carrier attached to decision handoffs. Rather than replacing text with hidden states, latent uncertainty aims to preserve pre-commitment fragility in a form that downstream components can use. This position shifts agent uncertainty propagation from step-wise uncertainty estimation toward uncertainty-preserving interface design for more recoverable agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper arguing that agent systems lose uncertainty at component interfaces, causing 'confidence laundering' where fragile upstream decisions are repackaged as clean artifacts that downstream agents over-trust. It defines 'uncertain decision handoff' and claims that uncertainty propagates only when it survives handoffs (not merely because uncertain steps exist). To address this, it proposes 'latent uncertainty' as a carrier attached to handoffs that preserves pre-commitment fragility in a usable form without replacing text outputs with hidden states, shifting focus from step-wise estimation to uncertainty-preserving interface design.
Significance. If the latent uncertainty carrier can be made operational, the interface-bottleneck diagnosis could meaningfully inform design of recoverable multi-agent systems by highlighting a propagation failure mode distinct from local uncertainty estimation. The paper offers no empirical support, derivations, or examples, so significance remains prospective and depends on future formalization.
major comments (2)
- [Abstract] Abstract: the claim that 'uncertainty does not propagate simply because a trajectory contains uncertain steps; it propagates only when it survives the handoff' is presented as the central diagnosis but receives no supporting argument, example trajectory, or reduction to existing agent architectures, rendering the interface-bottleneck thesis unevaluable as stated.
- [Abstract] Abstract: the proposed solution ('latent uncertainty as an uncertainty-bearing carrier attached to decision handoffs' that 'downstream components can use' without hidden states) supplies neither attachment protocol, syntax, consumption rule, nor pseudocode; this leaves the proposal at the level of a negative definition and does not demonstrate that the carrier would survive typical text/API interfaces or avoid being ignored.
minor comments (2)
- The abstract introduces 'confidence laundering' and 'uncertain decision handoff' as new terms; explicit comparison to related concepts such as epistemic uncertainty propagation or belief tracking in POMDPs would clarify novelty.
- The manuscript is short and contains no figures, tables, or worked examples; adding even one concrete agent pipeline (e.g., planner-to-executor handoff) would make the laundering failure mode concrete.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our position paper. We address each major comment below and indicate the revisions we will make to strengthen the manuscript while preserving its conceptual focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'uncertainty does not propagate simply because a trajectory contains uncertain steps; it propagates only when it survives the handoff' is presented as the central diagnosis but receives no supporting argument, example trajectory, or reduction to existing agent architectures, rendering the interface-bottleneck thesis unevaluable as stated.
Authors: We agree that the central claim would be more readily evaluable with concrete support. In revision we will insert a short illustrative trajectory (a planning agent producing a fragile intermediate plan that is passed as a clean artifact to an execution agent) together with a brief reduction to standard tool-calling and multi-agent orchestration patterns. This addition will clarify the handoff failure mode without converting the paper into an empirical study. revision: yes
-
Referee: [Abstract] Abstract: the proposed solution ('latent uncertainty as an uncertainty-bearing carrier attached to decision handoffs' that 'downstream components can use' without hidden states) supplies neither attachment protocol, syntax, consumption rule, nor pseudocode; this leaves the proposal at the level of a negative definition and does not demonstrate that the carrier would survive typical text/API interfaces or avoid being ignored.
Authors: As a position paper the proposal is deliberately conceptual, emphasizing the shift toward interface design rather than a ready-to-implement mechanism. Nevertheless, we accept that a high-level attachment protocol and consumption rules would make the idea more tangible. In the revised manuscript we will add a concise description of an attachment protocol (including how a compact uncertainty tag can be appended to text outputs or API responses) together with pseudocode sketches showing consumption by a downstream component. These additions will illustrate survival across typical text interfaces while remaining within the scope of a position paper. revision: partial
Circularity Check
No circularity: conceptual position paper with definitional claims only
full rationale
The manuscript is a position paper that introduces terminology ('uncertain decision handoff', 'confidence laundering', 'latent uncertainty') and argues for an interface-level design shift. No equations, parameter fits, or derivations appear in the provided text. No self-citations are used to justify uniqueness theorems or to close a derivation chain. The central claim—that uncertainty propagates only when it survives handoffs—is presented as an observation leading to a proposed carrier concept, not as a quantity derived from or equivalent to its own inputs. The proposal remains at the level of high-level definition without reducing to a fitted input renamed as prediction or any of the enumerated circular patterns. This is the expected non-finding for a non-mathematical conceptual work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty is lost at component interfaces in agent systems, turning local ambiguity into system-level error amplification.
invented entities (1)
-
latent uncertainty
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yanfang Ye, Zheyuan Zhang, Tianyi Ma, Zehong Wang, Yiyang Li, Shifu Hou, Weixiang Sun, Kaiwen Shi, Yijun Ma, Wei Song, et al. Llms4all: A review of large language models across academic disciplines.arXiv preprint arXiv:2509.19580, 2025
arXiv 2025
-
[2]
The obvious invisible threat: Llm-powered gui agents’ vulnerability to fine-print injections
Chaoran Chen, Zhiping Zhang, Bingcan Guo, Shang Ma, Ibrahim Khalilov, Simret Gebreegzi- abher, Yanfang Ye, Ziang Xiao, Yaxing Yao, Tianshi Li, et al. The obvious invisible threat: Llm-powered gui agents’ vulnerability to fine-print injections. InSoups. The Twenty-First Symposium on Usable Privacy and Security (SOUPS), 2025
2025
-
[3]
Clear: Towards contextual llm-empowered privacy policy analysis and risk generation for large language model applications
Chaoran Chen, Daodao Zhou, Yanfang Ye, Toby Jia-jun Li, and Yaxing Yao. Clear: Towards contextual llm-empowered privacy policy analysis and risk generation for large language model applications. InProceedings of the 30th International Conference on Intelligent User Interfaces, pages 277–297, 2025
2025
-
[4]
Agentic confidence calibration.arXiv preprint arXiv:2601.15778, 2026
Jiaxin Zhang, Caiming Xiong, and Chien-Sheng Wu. Agentic confidence calibration.arXiv preprint arXiv:2601.15778, 2026
arXiv 2026
-
[5]
Toolformer: Language models can teach them- selves to use tools.ArXiv, abs/2302.04761, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach them- selves to use tools.ArXiv, abs/2302.04761, 2023. URL https://api.semanticscholar. org/CorpusID:256697342
Pith/arXiv arXiv 2023
-
[6]
Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities
Changdae Oh, Seongheon Park, To Eun Kim, Jiatong Li, Wendi Li, Samuel Yeh, Xuefeng Du, Hamed Hassani, Paul Bogdan, Dawn Song, et al. Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities. InAgentic AI in the Wild: From Hallucinations to Reliable Autonomy
-
[7]
Zheyuan Zhang, Kaiwen Shi, Zhengqing Yuan, Zehong Wang, Tianyi Ma, Keerthiram Muruge- san, Vincent Galassi, Chuxu Zhang, and Yanfang Ye. Agentrouter: A knowledge-graph-guided llm router for collaborative multi-agent question answering.arXiv preprint arXiv:2510.05445, 2025
arXiv 2025
-
[8]
Jinhao Duan, James Diffenderfer, Sandeep Madireddy, Tianlong Chen, Bhavya Kailkhura, and Kaidi Xu. Uprop: Investigating the uncertainty propagation of llms in multi-step agentic decision-making.arXiv preprint arXiv:2506.17419, 2025
arXiv 2025
-
[9]
Saup: Situation awareness uncertainty propagation on llm agent.arXiv preprint arXiv:2412.01033, 2024
Qiwei Zhao, Xujiang Zhao, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, and Haifeng Chen. Saup: Situation awareness uncertainty propagation on llm agent.arXiv preprint arXiv:2412.01033, 2024
arXiv 2024
-
[10]
How language model hallucinations can snowball.arXiv preprint arXiv:2305.13534, 2023
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith. How language model hallucinations can snowball.arXiv preprint arXiv:2305.13534, 2023
arXiv 2023
-
[11]
Where llm agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025
Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingxuan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, et al. Where llm agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025
arXiv 2025
-
[12]
From spark to fire: Can situational reading interest lead to long-term reading motivation? Literacy Research and Instruction, 45(2):91–117, 2005
John T Guthrie, Laurel W Hoa, Allan Wigfield, Stephen M Tonks, and Kathleen C Perencevich. From spark to fire: Can situational reading interest lead to long-term reading motivation? Literacy Research and Instruction, 45(2):91–117, 2005
2005
-
[13]
Heng Zhang, Yuling Shi, Xiaodong Gu, Haochen You, Zijian Zhang, Lubin Gan, Yilei Yuan, and Jin Huang. Graphtracer: Graph-guided failure tracing in llm agents for robust multi-turn deep search.arXiv preprint arXiv:2510.10581, 2025
arXiv 2025
-
[14]
Uncertainty calibration for tool-using language agents
Hao Liu, Zi-Yi Dou, Yixin Wang, Nanyun Peng, and Yisong Yue. Uncertainty calibration for tool-using language agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 16781–16805, 2024
2024
-
[15]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664, 2023. 11
Pith/arXiv arXiv 2023
-
[16]
Uncertainty propagation on llm agent
Qiwei Zhao, Dong Li, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, Chen Zhao, et al. Uncertainty propagation on llm agent. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6064–6073, 2025
2025
-
[17]
Sina Tayebati, Divake Kumar, Nastaran Darabi, Davide Ettori, Ranganath Krishnan, and Amit Ranjan Trivedi. Tracer: Trajectory risk aggregation for critical episodes in agentic reasoning.arXiv preprint arXiv:2602.11409, 2026
arXiv 2026
-
[18]
Selaur: Self evolving llm agent via uncertainty-aware rewards.arXiv preprint arXiv:2602.21158, 2026
Dengjia Zhang, Xiaoou Liu, Lu Cheng, Yaqing Wang, Kenton Murray, and Hua Wei. Selaur: Self evolving llm agent via uncertainty-aware rewards.arXiv preprint arXiv:2602.21158, 2026
arXiv 2026
-
[19]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[20]
Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334, 2022
Pith/arXiv arXiv 2022
-
[21]
A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
2024
-
[22]
Do not abstain! identify and solve the uncertainty
Jingyu Liu, JingquanPeng JingquanPeng, Xiaopeng Wu, Xubin Li, Tiezheng Ge, Bo Zheng, and Yong Liu. Do not abstain! identify and solve the uncertainty. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17177–17197, 2025
2025
-
[23]
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 58(3):1–38, 2025
Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar. A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[24]
Search wisely: Mitigating sub-optimal agentic searches by reducing uncertainty
Peilin Wu, Mian Zhang, Xinlu Zhang, Xinya Du, and Zhiyu Chen. Search wisely: Mitigating sub-optimal agentic searches by reducing uncertainty. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19734–19745, 2025
2025
-
[25]
Lm-polygraph: Uncertainty estimation for language models
Ekaterina Fadeeva, Roman Vashurin, Akim Tsvigun, Artem Vazhentsev, Sergey Petrakov, Kirill Fedyanin, Daniil Vasilev, Elizaveta Goncharova, Alexander Panchenko, Maxim Panov, et al. Lm-polygraph: Uncertainty estimation for language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages ...
2023
-
[26]
Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
Pith/arXiv arXiv 2022
-
[27]
Detecting hallucinations in large language model generation: A token probability approach
Ernesto Quevedo, Jorge Yero Salazar, Rachel Koerner, Pablo Rivas, and Tomas Cerny. Detecting hallucinations in large language model generation: A token probability approach. InWorld Congress in Computer Science, Computer Engineering & Applied Computing, pages 154–173. Springer, 2024
2024
-
[28]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Pith/arXiv arXiv 2025
-
[29]
Can Xie, Ruotong Pan, Xiangyu Wu, Yunfei Zhang, Jiayi Fu, Tingting Gao, and Guorui Zhou. Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning.arXiv preprint arXiv:2510.10649, 2025
Pith/arXiv arXiv 2025
-
[30]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063, 2023. 12
Pith/arXiv arXiv 2023
-
[31]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
-
[32]
Can llms learn uncertainty on their own? expressing uncertainty effectively in a self-training manner
Shudong Liu, Zhaocong Li, Xuebo Liu, Runzhe Zhan, Derek F Wong, Lidia S Chao, and Min Zhang. Can llms learn uncertainty on their own? expressing uncertainty effectively in a self-training manner. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21635–21645, 2024
2024
-
[33]
First return, entropy-eliciting explore
Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, et al. First return, entropy-eliciting explore. arXiv preprint arXiv:2507.07017, 2025
arXiv 2025
-
[34]
Agentic reinforced policy optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, et al. Agentic reinforced policy optimization. arXiv preprint arXiv:2507.19849, 2025
Pith/arXiv arXiv 2025
-
[35]
Towards uncertainty-aware language agent
Jiuzhou Han, Wray Buntine, and Ehsan Shareghi. Towards uncertainty-aware language agent. InFindings of the Association for Computational Linguistics: ACL 2024, pages 6662–6685, 2024
2024
-
[36]
Yu Feng, Phu Mon Htut, Zheng Qi, Wei Xiao, Manuel Mager, Nikolaos Pappas, Kishaloy Halder, Yang Li, Yassine Benajiba, and Dan Roth. Rethinking llm uncertainty: A multi-agent approach to estimating black-box model uncertainty.arXiv preprint arXiv:2412.09572, 2024
arXiv 2024
-
[37]
Towards reliable alignment: Uncertainty-aware rlhf
Debangshu Banerjee and Aditya Gopalan. Towards reliable alignment: Uncertainty-aware rlhf. arXiv preprint arXiv:2410.23726, 2024
arXiv 2024
-
[38]
Uncertainty-penalized direct preference optimization.arXiv preprint arXiv:2410.20187, 2024
Sam Houliston, Alizée Pace, Alexander Immer, and Gunnar Rätsch. Uncertainty-penalized direct preference optimization.arXiv preprint arXiv:2410.20187, 2024
arXiv 2024
-
[39]
Vcrl: Variance-based curriculum reinforcement learning for large language models
Guochao Jiang, Wenfeng Feng, Guofeng Quan, Chuzhan Hao, Yuewei Zhang, Guohua Liu, and Hao Wang. Vcrl: Variance-based curriculum reinforcement learning for large language models. arXiv preprint arXiv:2509.19803, 2025
arXiv 2025
-
[40]
Uncertainty and influence aware reward model refinement for reinforcement learning from human feedback
Zexu Sun, Yiju Guo, Yankai Lin, Xu Chen, Qi Qi, Xing Tang, Ji-Rong Wen, et al. Uncertainty and influence aware reward model refinement for reinforcement learning from human feedback. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[41]
Josefa Lia Stoisser, Marc Boubnovski Martell, Lawrence Phillips, Gianluca Mazzoni, Lea Mørch Harder, Philip Torr, Jesper Ferkinghoff-Borg, Kaspar Martens, and Julien Fauqueur. Towards agents that know when they don’t know: Uncertainty as a control signal for structured reasoning. arXiv preprint arXiv:2509.02401, 2025
arXiv 2025
-
[42]
Soft self-consistency improves language models agents
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Soft self-consistency improves language models agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 287–301, 2024
2024
-
[43]
Aman Mehta. When agents disagree with themselves: Measuring behavioral consistency in llm-based agents.arXiv preprint arXiv:2602.11619, 2026
arXiv 2026
-
[44]
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen-Yu Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey.Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, 2025. URL https://api.semanticscholar.org/CorpusID:277150701
2025
-
[45]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. arXiv preprint arXiv:2002.07650, 2020
arXiv 2002
-
[46]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[47]
Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024. 13
2024
-
[48]
Why semantic entropy fails: Geometry-aware and calibrated uncertainty for policy optimization
Zheyuan Zhang, Kaiwen Shi, Han Bao, Zehong Wang, Tianyi Ma, and Yanfang Ye. Why semantic entropy fails: Geometry-aware and calibrated uncertainty for policy optimization. arXiv preprint arXiv:2605.21801, 2026
Pith/arXiv arXiv 2026
-
[49]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
2023
-
[50]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
2023
-
[51]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models.arXiv preprint arXiv:2305.19187, 2023
arXiv 2023
-
[52]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
2023
-
[53]
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927, 2024
Pith/arXiv arXiv 2024
-
[54]
Han Bao, Zheyuan Zhang, Pengcheng Jing, Zhengqing Yuan, Kaiwen Shi, and Yanfang Ye. Drift-bench: Diagnosing cooperative breakdowns in llm agents under input faults via multi-turn interaction.arXiv preprint arXiv:2602.02455, 2026
arXiv 2026
-
[55]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
2023
-
[56]
Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, F. Xia, Jacob Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, and Anirudha Majumdar. Robots that ask for help: Uncertainty alignment for large language model planners.ArXiv, abs/2307.01928, 2023. URL https://api.semanticscholar.org/ CorpusID:259342058
arXiv 2023
-
[57]
React: Synergizing reasoning and acting in language models.ArXiv, abs/2210.03629,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.ArXiv, abs/2210.03629,
-
[58]
URLhttps://api.semanticscholar.org/CorpusID:252762395
-
[59]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language mod- els.ArXiv, abs/2305.10601, 2023. URL https://api.semanticscholar.org/CorpusID: 258762525
Pith/arXiv arXiv 2023
-
[60]
Plummer, Zhaoran Wang, and Hongxia Yang
Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A. Plummer, Zhaoran Wang, and Hongxia Yang. Let models speak ciphers: Multiagent debate through embeddings.ArXiv, abs/2310.06272, 2023. URL https://api.semanticscholar. org/CorpusID:263830342
arXiv 2023
-
[61]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E. Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. ArXiv, abs/2412.06769, 2024. URL https://api.semanticscholar.org/CorpusID: 274610816
Pith/arXiv arXiv 2024
-
[62]
Enabling agents to communicate entirely in latent space.ArXiv, abs/2511.09149,
Zhuoyun Du, Runze Wang, Huiyu Bai, Zouying Cao, Xiaoyong Zhu, Bo Zheng, Wei Chen, and Haochao Ying. Enabling agents to communicate entirely in latent space.ArXiv, abs/2511.09149,
-
[63]
URLhttps://api.semanticscholar.org/CorpusID:282939672. 14
-
[64]
Xiangyu Shi, Marco Chiesa, Gerald Q. Maguire, and Dejan Kosti ´c. Kvcomm: Enabling efficient llm communication through selective kv sharing.ArXiv, abs/2510.03346, 2025. URL https://api.semanticscholar.org/CorpusID:281842742
arXiv 2025
-
[65]
Ng-router: Graph-supervised multi-agent collaboration for nutrition question answering
Kaiwen Shi, Zheyuan Zhang, Zhengqing Yuan, Keerthiram Murugesan, Vincent Galassi, Chuxu Zhang, and Yanfang Ye. Ng-router: Graph-supervised multi-agent collaboration for nutrition question answering. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7508–7527, 2026
2026
-
[66]
Autodata: A multi-agent system for open web data collection.Advances in Neural Information Processing Systems, 38:173416– 173448, 2026
Tianyi Ma, Yiyue Qian, Zheyuan Zhang, Zehong Wang, Xiaoye Qian, Feifan Bai, Yifan Ding, Xuwei Luo, Shinan Zhang, Keerthiram Murugesan, et al. Autodata: A multi-agent system for open web data collection.Advances in Neural Information Processing Systems, 38:173416– 173448, 2026
2026
-
[67]
Mapro: Recasting multi-agent prompt optimization as maximum a posteriori inference
Zheyuan Zhang, Lin Ge, Hongjiang Li, Weicheng Zhu, Chuxu Zhang, and Yanfang Ye. Mapro: Recasting multi-agent prompt optimization as maximum a posteriori inference. InFindings of the Association for Computational Linguistics: EACL 2026, pages 4458–4480, 2026
2026
-
[68]
Jiatan Huang, Zheyuan Zhang, Kaiwen Shi, Yanfang Ye, and Chuxu Zhang. Evolver- outer: Co-evolving routing and prompt for multi-agent question answering.arXiv preprint arXiv:2604.05149, 2026. 15 A Experimental Details A.1 Task, Tool-Use Setting, and Model We use HotpotQA as the evaluation setting because it contains multi-hop questions that often require g...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.