Specific Domain Ontology Construction Using Large Language Models
Pith reviewed 2026-06-27 03:22 UTC · model grok-4.3
The pith
Large language models generate coherent conceptual hierarchies for the Blue Amazon domain but none prove fully satisfactory without human refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
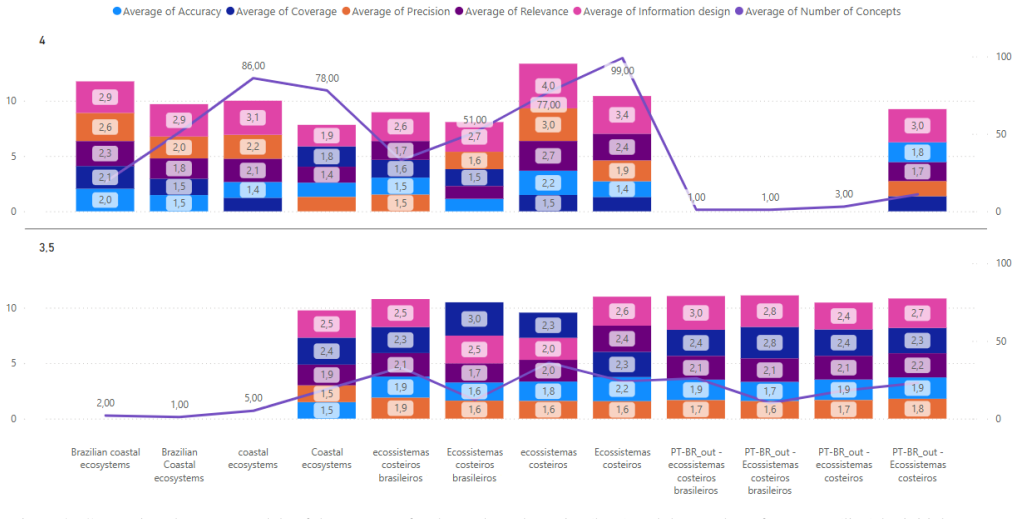
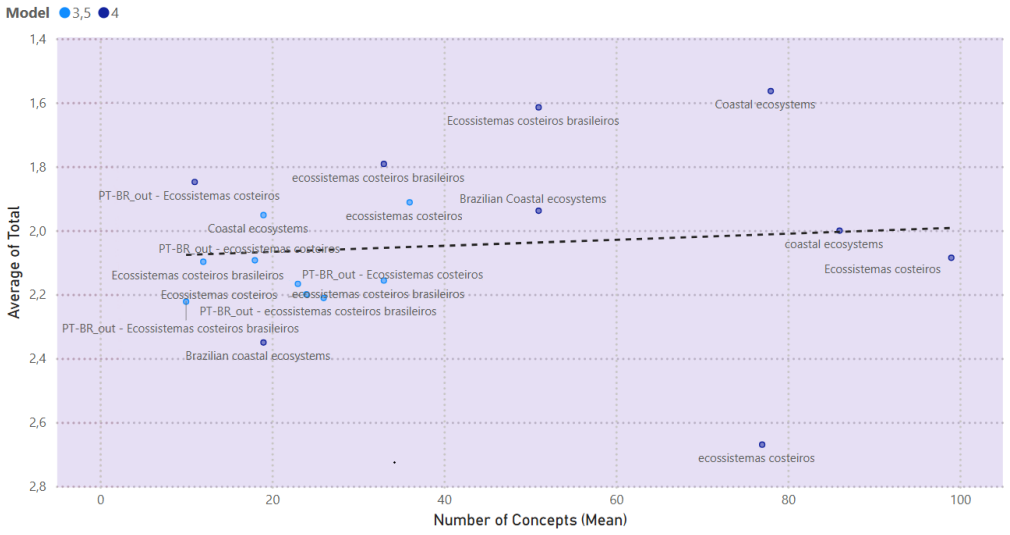
The experimentation with a technique that uses LLMs in the role of domain experts to build conceptual hierarchies for a given initial concept showed that the models were able to construct overall coherent conceptualizations of the Blue Amazon domain, but none of the outputs was completely satisfactory as a representation of the context without refinement.
What carries the argument
The technique of prompting LLMs to act as domain experts and generate conceptual hierarchies from an initial seed concept.
If this is right
- LLMs can supply initial conceptual structures for domains that currently lack reference ontologies.
- The generated hierarchies still require targeted human editing to reach acceptable fidelity.
- Both GPT-3.5 and GPT-4 are capable of producing broadly consistent domain conceptualizations under the tested prompting approach.
- Partial automation of ontology construction becomes feasible once refinement steps are formalized.
Where Pith is reading between the lines
- If refinement pipelines can be made systematic, the same prompting method could be applied to other maritime or environmental domains with similar documentation gaps.
- Combining LLM outputs with existing ontology alignment tools might reduce the manual effort needed after generation.
- Longer context windows or domain-specific fine-tuning could narrow the gap between generated and expert-grade hierarchies.
Load-bearing premise
The judgments of the human experts who reviewed the twenty generated ontologies provide a reliable and sufficient measure of whether the outputs accurately represent the Blue Amazon domain.
What would settle it
A follow-up evaluation by a larger or more diverse group of Blue Amazon domain experts that rates the same twenty outputs as predominantly incoherent or inaccurate would falsify the claim of overall coherence.
Figures


read the original abstract
Ontologies are useful structures to organize and maintain information that can be understood both by humans and systems. However, since their manual crafting is a laborious task, many specific domains lack reference ontologies. The outstanding ability for understanding natural language demonstrated by the Large Language Models (LLMs) has motivated their application to aid on a variety of fields, including on ontology development. This work presents the experimentation with a technique that uses LLMs in the role of domain experts to build conceptual hierarchies for a given initial concept. Twenty ontologies automatically constructed for the domain of the Brazilian maritime territory (a.k.a the Blue Amazon) using GPT-3.5 and GPT-4 were then evaluated by human experts. The models were able to construct overall coherent conceptualizations of the domain, but none of the outputs was completely satisfactory as a representation of the context without refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the use of LLMs (GPT-3.5 and GPT-4) to automatically generate domain-specific ontologies, focusing on conceptual hierarchies for the Blue Amazon (Brazilian maritime territory). It reports generating twenty ontologies from an initial concept and having them evaluated by human experts, concluding that the outputs are overall coherent but none fully satisfactory without refinement.
Significance. If the evaluation methodology is fully reported and reproducible, the work provides an empirical demonstration that current LLMs can produce usable starting points for ontology construction in specialized domains, which could reduce the manual effort required for under-documented fields. The direct use of external human judgment rather than self-referential metrics is a positive aspect of the design.
major comments (2)
- [Experiment description (abstract and methodology)] The description of the experiment (abstract and the reported generation of twenty ontologies) provides no information on the prompts, sampling strategy, temperature settings, or number of generations per model used to produce the ontologies. Without these details the reproducibility of the 'overall coherent' result cannot be assessed and the claim that the models succeeded in constructing conceptualizations rests on an unreported procedure.
- [Human evaluation (abstract and results)] The human expert evaluation of the twenty ontologies reports no information on the number of experts, their domain expertise or selection criteria, the evaluation rubric or scoring scale, or any inter-rater agreement metric. Because the central claim ('overall coherent conceptualizations' yet 'none completely satisfactory without refinement') is supported solely by these judgments, the absence of protocol details leaves the evidence preliminary and vulnerable to subjectivity or selection bias.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the specific technique or prompting strategy employed, even at high level, to orient readers before the evaluation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key gaps in experimental reporting and evaluation transparency. We address each point below and will revise the manuscript to improve reproducibility and methodological detail.
read point-by-point responses
-
Referee: [Experiment description (abstract and methodology)] The description of the experiment (abstract and the reported generation of twenty ontologies) provides no information on the prompts, sampling strategy, temperature settings, or number of generations per model used to produce the ontologies. Without these details the reproducibility of the 'overall coherent' result cannot be assessed and the claim that the models succeeded in constructing conceptualizations rests on an unreported procedure.
Authors: We agree that the prompts, sampling strategy, temperature settings, and number of generations per model are not reported in the abstract or methodology. In the revised manuscript we will add a dedicated subsection detailing the exact prompts used for GPT-3.5 and GPT-4, the generation parameters (including temperature), the sampling approach that produced the twenty ontologies, and the number of outputs generated per model. These additions will directly support reproducibility. revision: yes
-
Referee: [Human evaluation (abstract and results)] The human expert evaluation of the twenty ontologies reports no information on the number of experts, their domain expertise or selection criteria, the evaluation rubric or scoring scale, or any inter-rater agreement metric. Because the central claim ('overall coherent conceptualizations' yet 'none completely satisfactory without refinement') is supported solely by these judgments, the absence of protocol details leaves the evidence preliminary and vulnerable to subjectivity or selection bias.
Authors: We acknowledge that the human evaluation protocol is insufficiently described. The revised results section will report the number of experts, their domain expertise and selection criteria, the rubric and scoring scale applied, and inter-rater agreement statistics. These details will be added to reduce concerns about subjectivity while preserving the original evaluation outcomes. revision: yes
Circularity Check
No circularity: empirical evaluation of LLM-generated ontologies with external human review
full rationale
The paper reports an empirical experiment in which GPT-3.5 and GPT-4 are prompted to generate 20 ontologies for the Blue Amazon domain; these outputs are then assessed by human experts. The central claim (overall coherence but need for refinement) rests on those external judgments rather than any derivation, fitted parameter, self-citation chain, or redefinition of inputs. No equations, uniqueness theorems, or load-bearing self-citations appear. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
1985
-
[2]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
2001
-
[3]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[4]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
-
[5]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
2002
-
[6]
Levesque
Hector J. Levesque. Foundations of a functional approach to knowledge representation. Artificial Intelligence. 1984
1984
-
[7]
Levesque
Hector J. Levesque. A logic of implicit and explicit belief. Proceedings of the Fourth National Conference on Artificial Intelligence. 1984
1984
-
[8]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
2000
-
[9]
Maurice Funk and Simon Hosemann and Jean Christoph Jung and Carsten Lutz , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2309.09898 , eprinttype =. 2309.09898 , timestamp =
-
[10]
Vahideh Reshadat and Alp Akcay and Kalliopi Zervanou and Yingqian Zhang and Eelco de Jong , title =. Neural Comput. Appl. , volume =. 2023 , url =. doi:10.1007/S00521-023-08704-9 , timestamp =
-
[11]
Ligabue and Anarosa Alves Franco Brand
Pedro de M. Ligabue and Anarosa Alves Franco Brand. BlabKG: a Knowledge Graph for the Blue Amazon , booktitle =. 2022 , url =. doi:10.1109/ICKG55886.2022.00028 , timestamp =
-
[12]
Paulo Pirozelli and Ais B. R. Castro and Ana Luiza C. de Oliveira and Andr. The BLue Amazon Brain. CoRR , volume =. 2022 , url =. doi:10.48550/ARXIV.2209.07928 , eprinttype =. 2209.07928 , timestamp =
-
[13]
Desnes Nunes and Ricardo Primi and Ramon Pires and Roberto de Alencar Lotufo and Rodrigo Frassetto Nogueira , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.17003 , eprinttype =. 2303.17003 , timestamp =
-
[14]
Shaden Smith and Mostofa Patwary and Brandon Norick and Patrick LeGresley and Samyam Rajbhandari and Jared Casper and Zhun Liu and Shrimai Prabhumoye and George Zerveas and Vijay Korthikanti and Elton Zheng and Rewon Child and Reza Yazdani Aminabadi and Julie Bernauer and Xia Song and Mohammad Shoeybi and Yuxiong He and Michael Houston and Saurabh Tiwary ...
Pith/arXiv arXiv 2022
-
[15]
Baptiste Rozière and Jonas Gehring and Fabian Gloeckle and Sten Sootla and Itai Gat and Xiaoqing Ellen Tan and Yossi Adi and Jingyu Liu and Tal Remez and Jérémy Rapin and Artyom Kozhevnikov and Ivan Evtimov and Joanna Bitton and Manish Bhatt and Cristian Canton Ferrer and Aaron Grattafiori and Wenhan Xiong and Alexandre Défossez and Jade Copet and Faisal ...
-
[16]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , journal =. 2020 , url =. 2005.14165 , timestamp =
Pith/arXiv arXiv 2020
-
[17]
Muhammad Nabeel Asim and Muhammad Wasim and Muhammad Usman Ghani Khan and Waqar Mahmood and Hafiza Mahnoor Abbasi , title =. Database J. Biol. Databases Curation , volume =. 2018 , url =. doi:10.1093/DATABASE/BAY101 , timestamp =
-
[18]
Knowledgegraphs.ACM Computing Surveys, 54(4):1–37, 2021
Aidan Hogan and Eva Blomqvist and Michael Cochez and Claudia d'Amato and Gerard de Melo and Claudio Gutierrez and Sabrina Kirrane and Jos. Knowledge Graphs , journal =. 2022 , url =. doi:10.1145/3447772 , timestamp =
-
[19]
Cafarella and Stephen Soderland and Matthew Broadhead and Oren Etzioni , editor =
Michele Banko and Michael J. Cafarella and Stephen Soderland and Matthew Broadhead and Oren Etzioni , editor =. Open Information Extraction from the Web , booktitle =. 2007 , url =
2007
-
[20]
Christopher D. Manning and Mihai Surdeanu and John Bauer and Jenny Rose Finkel and Steven Bethard and David McClosky , title =. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,. 2014 , url =. doi:10.3115/V1/P14-5010 , timestamp =
-
[21]
Schneider
E.W. Schneider. Course Modularization Applied: The Interface System and Its Implications For Sequence Control and Data Analysis. 1972
1972
-
[22]
Towards context-based knowledge graphs: a method based on word embeddings , note =
de Moraes Ligabue, Pedro and Brandão, Anarosa and Peres, Sarajane and Pirozelli, Paulo , year =. Towards context-based knowledge graphs: a method based on word embeddings , note =
-
[23]
Ontology Development 101: A Guide to Creating Your First Ontology , volume =
Noy, Natasha and Mcguinness, Deborah , year =. Ontology Development 101: A Guide to Creating Your First Ontology , volume =
-
[24]
Andr. Pir. CoRR , volume =. 2022 , url =. 2202.02398 , timestamp =
arXiv 2022
-
[25]
José and Igor Silveira and Flávio Nakasato and Sarajane M
Paulo Pirozelli and Marcos M. José and Igor Silveira and Flávio Nakasato and Sarajane M. Peres and Anarosa A. F. Brandão and Anna H. R. Costa and Fabio G. Cozman , year=. Benchmarks for. 2309.10945 , archivePrefix=
-
[26]
O cenário da avaliação de ontologias: revisão de literatura , volume =
Araújo, Webert and Lima, Gercina , year =. O cenário da avaliação de ontologias: revisão de literatura , volume =
-
[27]
Lozano-Tello, Adolfo and G. J. Database Manag. , volume =. 2004 , url =. doi:10.4018/JDM.2004040101 , timestamp =
-
[28]
Mauricio Barcellos Almeida , title =. Appl. Ontology , volume =. 2009 , url =. doi:10.3233/AO-2009-0070 , timestamp =
-
[29]
Conversational agents
KEML. Conversational agents
-
[30]
Engineering, Technology & Applied Science Research , volume=
Deep Learning-Driven Ontology Learning: A Systematic Mapping Study , author=. Engineering, Technology & Applied Science Research , volume=
-
[31]
Exploring large language models for ontology learning , author=
-
[32]
2024 , eprint=
A Short Review for Ontology Learning: Stride to Large Language Models Trend , author=. 2024 , eprint=
2024
-
[33]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:1810.04805 , pages=
Bert: Bidirectional encoder representations from transformers , author=. arXiv preprint arXiv:1810.04805 , pages=
-
[35]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[36]
2023 , eprint=
LLMs4OL: Large Language Models for Ontology Learning , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.