SafeDojo: Safe Reinforcement Learning for VLA via Interactive World Model
Pith reviewed 2026-06-27 04:10 UTC · model grok-4.3
The pith
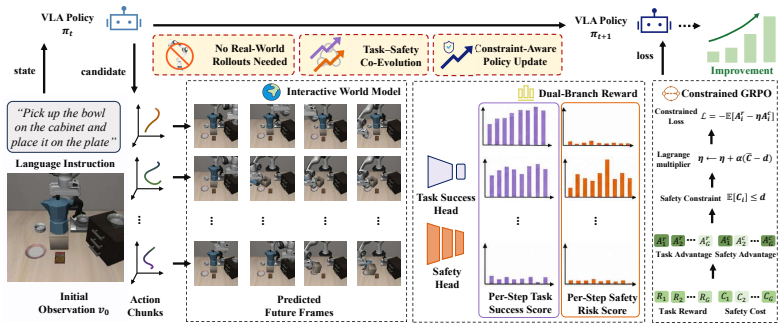
SafeDojo trains vision-language-action policies safely by running reinforcement learning inside an interactive video world model that imagines action outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SafeDojo performs online reinforcement learning on top of an interactive video world model that produces action-conditioned future predictions; a ResNet success classifier estimates per-step task progress from the imagined frames while a lightweight safety head predicts per-step safety costs from latent context and the proposed action chunk; the resulting task-reward and safety-cost signals are balanced through a Lagrangian-based constrained GRPO objective, producing coordinated gains in task success and safety.
What carries the argument
The interactive video world model, which supplies action-conditioned future predictions used by separate heads to estimate task progress and safety costs for constrained optimization.
If this is right
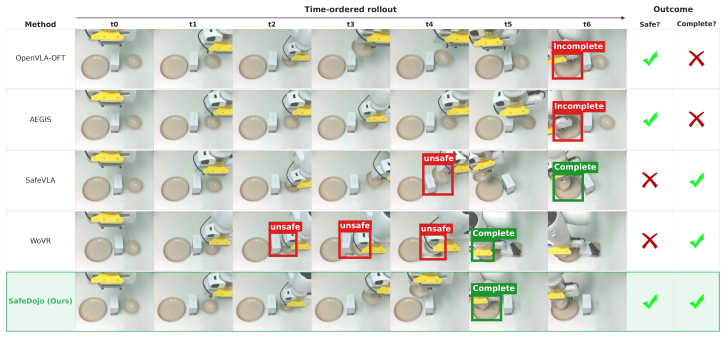
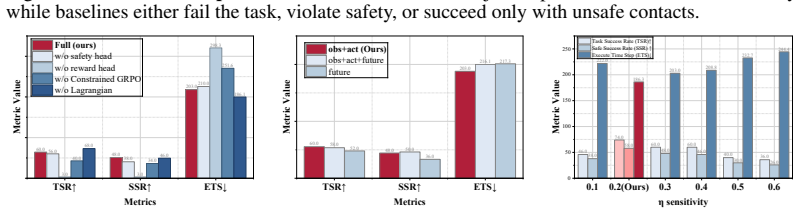
- The same world-model imagination loop yields the highest aggregate task success, safe success, and execution efficiency among compared inference-time, model-free, and model-based baselines on SafeLIBERO.
- An 8.25 percentage-point gain in average safe-success rate appears on Level I relative to the strongest baseline.
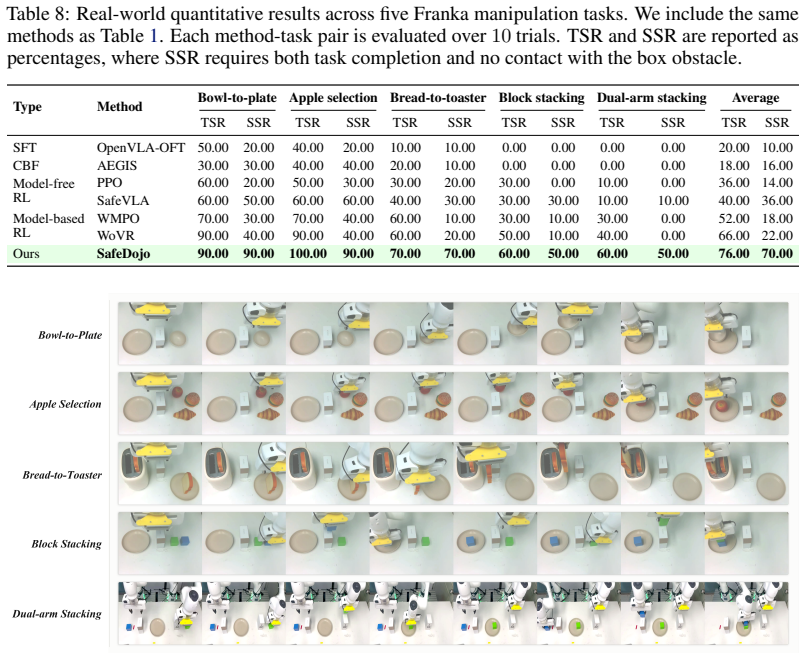
- Real-world Franka experiments across five tasks show the highest average task-success and safe-success rates.
- The decoupled reward and cost signals allow explicit safety constraints to be maintained while task performance improves.
Where Pith is reading between the lines
- If the world model generalizes across new objects and scenes, the same training loop could be applied to additional VLA architectures without new hand-crafted safety functions.
- The separation of task and safety heads inside the world-model loop suggests a route to adding further constraints, such as energy or collision limits, by attaching new prediction heads.
- Because all learning occurs in imagined trajectories, the approach may lower the total number of real-robot trials needed to reach a target safety level.
Load-bearing premise
The world model must produce sufficiently accurate action-conditioned predictions so that the success classifier and safety head can reliably judge imagined trajectories.
What would settle it
Deploy the learned policy on the real Franka arm and observe whether the measured safety violations or task failures match the rates predicted from the world model's imagined rollouts.
Figures

read the original abstract
Safe control is a prerequisite for real-world embodied intelligence, for which safe reinforcement learning has emerged as a promising paradigm. However, existing safe reinforcement learning methods either require costly real-world exploration or depend on hand-crafted safety functions. Neither scales to vision-language-action models deployed in open-world physical environments. We propose SafeDojo, the first model-based safe reinforcement learning framework for vision-language-action policies designed to learn safe actions through world model-based imagination. Specifically, SafeDojo performs online reinforcement learning on top of an interactive video world model. The world model generates action-conditioned future predictions, from which a tailored ResNet success classifier estimates per-step task progress from imagined frames and a lightweight safety head predicts per-step safety costs from latent context together with the proposed action chunk, enabling simultaneous assessment of task execution and trajectory safety. The decoupled task-reward and safety-cost signals are balanced through a Lagrangian-based constrained GRPO objective, enabling coordinated improvement of task success and safety under explicit constraints. On SafeLIBERO, SafeDojo achieves the best aggregate task success, safe success, and execution efficiency among inference-time safety, model-free RL, and model-based RL baselines, with the best average safe-success rate on both levels and an 8.25 percentage-point improvement over the strongest baseline on Level I. Real-world Franka deployment further shows the best average task and safe-success rates across five tasks. Our results position world model-based safe reinforcement learning as a scalable and generalizable path toward safe embodied intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SafeDojo, the first model-based safe RL framework for vision-language-action (VLA) policies. It performs online RL atop an interactive video world model that generates action-conditioned future predictions; a ResNet success classifier estimates per-step task progress from imagined frames while a lightweight safety head predicts per-step safety costs from latent context plus the action chunk. These decoupled signals are balanced via a Lagrangian-constrained GRPO objective. On SafeLIBERO the method reports the best aggregate task success, safe success, and execution efficiency versus inference-time safety, model-free RL, and model-based RL baselines (including an 8.25 pp safe-success gain on Level I), with additional best-in-class results on five real-world Franka tasks.
Significance. If the empirical claims hold after addressing the validation gap, the work would represent a meaningful step toward scalable safe embodied intelligence. It demonstrates how world-model imagination can replace hand-crafted safety functions and costly real-world exploration for VLAs, while the Lagrangian-GRPO formulation provides a principled way to trade off task and safety objectives. The real-world Franka results add practical weight.
major comments (1)
- [Abstract and Methods (world-model and classifier sections)] The headline performance claims (best aggregate task/safe success on SafeLIBERO Levels I/II and real-world Franka results) rest on the assumption that the interactive video world model produces faithful action-conditioned rollouts that can be reliably fed to the ResNet classifier and safety head. No quantitative world-model metrics (frame-level MSE, FVD, or classifier accuracy on imagined versus real frames) are reported anywhere in the manuscript, leaving the quality of the estimated rewards and costs unverified. This is load-bearing for the central claim that the observed gains reflect true policy improvement rather than artifacts of prediction error.
minor comments (2)
- [Methods] The description of the Lagrangian multiplier update schedule and the precise form of the GRPO objective would benefit from an explicit equation or pseudocode block to allow reproduction.
- [Experiments] Table captions and axis labels in the SafeLIBERO results should explicitly state the number of evaluation episodes and random seeds used for each method.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the interactive world model's prediction quality, which is central to our claims. We address this point below and will incorporate the requested metrics in the revision.
read point-by-point responses
-
Referee: [Abstract and Methods (world-model and classifier sections)] The headline performance claims (best aggregate task/safe success on SafeLIBERO Levels I/II and real-world Franka results) rest on the assumption that the interactive video world model produces faithful action-conditioned rollouts that can be reliably fed to the ResNet classifier and safety head. No quantitative world-model metrics (frame-level MSE, FVD, or classifier accuracy on imagined versus real frames) are reported anywhere in the manuscript, leaving the quality of the estimated rewards and costs unverified. This is load-bearing for the central claim that the observed gains reflect true policy improvement rather than artifacts of prediction error.
Authors: We agree that quantitative validation of the world model is essential to substantiate that the observed gains arise from policy improvement rather than prediction artifacts. The current manuscript focuses on end-to-end task and safety metrics but omits direct evaluation of rollout fidelity. In the revised version, we will add a dedicated subsection in Methods (and corresponding results) reporting frame-level MSE, Fréchet Video Distance (FVD), and per-frame classifier accuracy of the ResNet success head on both real and imagined frames across SafeLIBERO levels. These metrics will be computed on held-out trajectories to confirm that the imagined rollouts remain sufficiently accurate for reward and cost estimation. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks.
full rationale
The paper describes a model-based safe RL framework (world model + ResNet classifier + safety head + Lagrangian GRPO) and reports aggregate performance metrics on SafeLIBERO Levels I/II plus real-world Franka tasks. All load-bearing claims are comparative results against listed baselines rather than any derivation that reduces to fitted parameters or self-citations by construction. No equations or sections exhibit self-definitional loops, fitted inputs renamed as predictions, or uniqueness theorems imported from the same authors. The method is self-contained against the reported external evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
2022
-
[2]
S. Gu, L. Yang, Y . Du, G. Chen, F. Walter, J. Wang, and A. Knoll. A review of safe reinforcement learning: Methods, theories, and applications.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):11216–11235, 2024
2024
-
[3]
O. Khatib. Real-time obstacle avoidance for manipulators and mobile robots.The International Journal of Robotics Research, 5(1):90–98, 1986. doi:10.1177/027836498600500106
-
[4]
S. Haddadin, A. Albu-Sch¨affer, A. De Luca, and G. Hirzinger. Collision detection and reaction: A contribution to safe physical human-robot interaction. In2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3356–3363, 2008. doi:10.1109/IROS. 2008.4650764
-
[5]
S. Haddadin, A. Albu-Sch¨affer, and G. Hirzinger. Requirements for safe robots: Measurements, analysis and new insights.The International Journal of Robotics Research, 28(11–12):1507– 1527, 2009. doi:10.1177/0278364909343970
-
[6]
S. Haddadin, A. De Luca, and A. Albu-Sch ¨affer. Robot collisions: A survey on detection, isolation, and identification.IEEE Transactions on Robotics, 33(6):1292–1312, 2017. doi: 10.1109/TRO.2017.2723903
-
[7]
A. M. Zanchettin, N. M. Ceriani, P. Rocco, H. Ding, and B. Matthias. Safety in human- robot collaborative manufacturing environments: Metrics and control.IEEE Transactions on Automation Science and Engineering, 13(2):882–893, 2016. doi:10.1109/TASE.2015.2412256
-
[8]
P. A. Lasota, T. Fong, and J. A. Shah. A survey of methods for safe human-robot interaction. F oundations and Trends in Robotics, 5(4):261–349, 2017. doi:10.1561/2300000052
-
[9]
X. Ding, H. Wang, Y . Ren, Y . Zheng, C. Chen, and J. He. Safety-critical optimal control for robotic manipulators in a cluttered environment.arXiv preprint arXiv:2211.04944, 2022. doi:10.48550/arXiv.2211.04944
-
[10]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, 2023
2023
-
[11]
Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023
Open X-Embodiment Collaboration et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[12]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[13]
O. M. Team et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[14]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[15]
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada. Control barrier functions: Theory and applications.2019 18th European Control Conference (ECC), pages 3420–3431, 2019. doi:10.23919/ECC.2019.8796030. 10
-
[16]
Huang, J
W. Huang, J. Ji, C. Xia, B. Zhang, and Y . Yang. SafeDreamer: Safe reinforcement learning with world models. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=tsE5HLYtYg
2024
-
[17]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. SafeVLA: Towards safety alignment of vision-language-action model via constrained learning. InThirty-ninth Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=dt940loCBT. Spotlight
2025
-
[18]
S. Hu, Z. Liu, S. Liu, J. Cen, Z. Meng, and X. He. VLSA: Vision-language-action models with plug-and-play safety constraint layer.arXiv preprint arXiv:2512.11891, 2025. URL https://arxiv.org/abs/2512.11891
arXiv 2025
-
[19]
C. Cao, Y . Xin, S. Wu, L. He, Z. Yan, J. Tan, and X. Wang. FOSP: Fine-tuning offline safe policy through world models. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=dbuFJg7eaw
2025
-
[20]
D. Yu, Q. Zhou, B. Huang, M. Khadiv, and Z. Yang. Safe-night VLA: Seeing the unseen via thermal-perceptive vision-language-action models for safety-critical manipulation.arXiv preprint arXiv:2603.05754, 2026. URLhttps://arxiv.org/abs/2603.05754
arXiv 2026
-
[21]
Y .-C. Son, D.-K. Ko, Y .-J. Choi, and S.-C. Lim. ThermoAct: Thermal-aware vision-language- action models for robotic perception and decision-making.IEEE Robotics and Automation Letters, 11(5):6106–6113, 2026. doi:10.1109/LRA.2026.3678130
-
[22]
X. Zhai, B. Ou, Q. Yu, C. Hao, and Y . Liu. CoFreeVLA: Collision-free dual-arm manipulation via vision-language-action model and risk estimation, 2026. URL https://arxiv.org/abs/ 2601.21712
arXiv 2026
-
[23]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. SAFE: Multitask failure detection for vision-language-action models.arXiv preprint arXiv:2506.09937, 2025. doi:10.48550/arXiv.2506.09937. URLhttps://arxiv.org/abs/2506.09937
- [24]
-
[25]
URLhttps://arxiv.org/abs/2411.19309
doi:10.48550/arXiv.2411.19309. URLhttps://arxiv.org/abs/2411.19309
-
[26]
Altman.Constrained Markov Decision Processes
E. Altman.Constrained Markov Decision Processes. Chapman and Hall/CRC, 1999
1999
-
[27]
Achiam, D
J. Achiam, D. Held, A. Tamar, and P. Abbeel. Constrained policy optimization. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 22–31. PMLR, 2017. URL https://proceedings.mlr. press/v70/achiam17a.html
2017
-
[28]
A. Ray, J. Achiam, and D. Amodei. Benchmarking safe exploration in deep reinforce- ment learning. OpenAI technical report, 2019. URL https://openai.com/index/ benchmarking-safe-exploration-in-deep-reinforcement-learning/
2019
-
[29]
Tessler, D
C. Tessler, D. J. Mankowitz, and S. Mannor. Reward constrained policy optimization. In International Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=SkfrvsA9FX
2019
-
[30]
Zhang, Q
Y . Zhang, Q. Vuong, and K. Ross. First order constrained optimization in policy space. InAdvances in Neural Information Processing Systems, vol- ume 33, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/ af5d5ef24881f3c3049a7b9bfe74d58b-Abstract.html. 11
2020
-
[31]
Stooke, J
A. Stooke, J. Achiam, and P. Abbeel. Responsive safety in reinforcement learning by PID lagrangian methods. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9133–9143. PMLR, 2020. URLhttps://proceedings.mlr.press/v119/stooke20a.html
2020
-
[32]
Thomas, Y
G. Thomas, Y . Luo, and T. Ma. Safe reinforcement learning by imagining the near future. InAdvances in Neural Information Processing Systems, volume 34, 2021. URL https: //openreview.net/forum?id=vIDBSGl3vzl
2021
-
[33]
Hogewind, T
Y . Hogewind, T. D. Sim˜ao, T. Kachman, and N. Jansen. Safe reinforcement learning from pixels using a stochastic latent representation. InInternational Conference on Learning Representa- tions, 2023. URLhttps://openreview.net/forum?id=b39dQt_uffW
2023
-
[34]
K. Nakamura, L. Peters, and A. Bajcsy. Generalizing safety beyond collision-avoidance via latent-space reachability analysis. InProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.113. URL https://www. roboticsproceedings.org/rss21/p113.html
-
[35]
J. Seo, K. Nakamura, and A. Bajcsy. Uncertainty-aware latent safety filters for avoiding out- of-distribution failures. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 4442–4472. PMLR, 2025. URL https://proceedings.mlr.press/v305/seo25a.html
2025
-
[36]
F. Zhu, Z. Yan, Z. Hong, Q. Shou, X. Ma, and S. Guo. WMPO: World model-based policy optimization for vision-language-action models. InInternational Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=qE2FyvRvuF
2026
-
[37]
Z. Jiang, S. Zhou, Y . Jiang, Z. Huang, M. Wei, Y . Chen, T. Zhou, Z. Guo, H. Lin, Q. Zhang, Y . Wang, H. Li, C. Yu, and D. Zhao. WoVR: World models as reliable simulators for post- training VLA policies with RL.arXiv preprint arXiv:2602.13977, 2026. URL https://arxiv. org/abs/2602.13977
arXiv 2026
-
[38]
J. Xiao, Y . Yang, X. Chang, R. Chen, F. Xiong, M. Xu, W.-S. Zheng, and Q. Zhang. World- Env: Leveraging world model as a virtual environment for VLA post-training.arXiv preprint arXiv:2509.24948, 2025. URLhttps://arxiv.org/abs/2509.24948
Pith/arXiv arXiv 2025
-
[39]
H. Li, P. Ding, R. Suo, Y . Wang, Z. Ge, D. Zang, K. Yu, M. Sun, H. Zhang, D. Wang, and W. Su. VLA-RFT: Vision-language-action reinforcement fine-tuning with verified rewards in world simulators.arXiv preprint arXiv:2510.00406, 2025. doi:10.48550/arXiv.2510.00406. URL https://arxiv.org/abs/2510.00406
-
[40]
X. Liu, Z. Bai, H. Ci, K. Y . Ma, and M. Z. Shou. World-VLA-Loop: Closed-loop learning of video world model and VLA policy.arXiv preprint arXiv:2602.06508, 2026. doi:10.48550/ arXiv.2602.06508. URLhttps://arxiv.org/abs/2602.06508
Pith/arXiv arXiv 2026
-
[41]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, X....
Pith/arXiv arXiv 2025
- [42]
-
[43]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmark- ing knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2023. URL https: //openreview.net/forum?id=xzEtNSuDJk. 12
2023
-
[44]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiriany, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020. URLhttps://arxiv.org/abs/2009.12293
Pith/arXiv arXiv 2009
-
[45]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June
-
[46]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
doi:10.15607/RSS.2025.XXI.017. URL https://www.roboticsproceedings.org/ rss21/p017.html. 13 A Overview of Appendices • Appendix B: Limitations and Future Work • Appendix C: Detailed Related Work • Appendix D: Broader Impact • Appendix E: Per-Task Results on SafeLIBERO Level I • Appendix F: Per-Task Results on SafeLIBERO Level II • Appendix G: Task Descrip...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.