Grouped Query Experts: Mixture-of-Experts on GQA Self-Attention
Pith reviewed 2026-06-26 17:38 UTC · model grok-4.3
The pith
Grouped Query Experts apply a router to select half the query heads per token inside GQA groups while leaving all KV heads dense.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
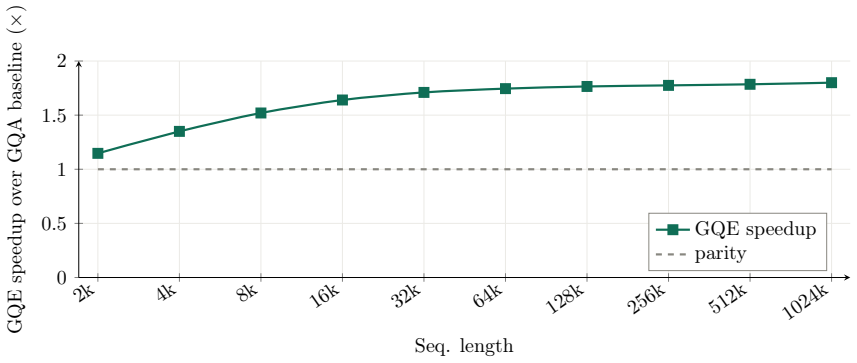
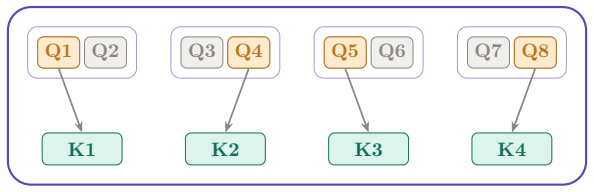
GQE places a router inside each GQA group so that, for any given token, only a chosen subset of the query heads inside that group participate in attention; the full set of key-value heads remains active for every token. Because the KV heads are never sparsified, the KV cache size and its associated long-context benefits are preserved exactly. Experiments at 250M parameters on a 30B-token budget show that this selective query activation matches the accuracy of the corresponding dense GQA model while using half the query-head compute per token.
What carries the argument
A per-GQA-group router that selects k query-head experts for each token while all KV heads stay fully dense.
If this is right
- Query-head compute can be halved inside GQA without enlarging the KV cache or sacrificing long-context efficiency.
- The same router mechanism can be applied at larger scales where attention cost grows with sequence length.
- Downstream task performance remains comparable to a dense baseline under a fixed training-token budget.
- Only query-side FLOPs are reduced; KV cache memory and bandwidth stay identical to standard GQA.
Where Pith is reading between the lines
- The approach could be combined with other sparse-attention methods that also leave KV heads untouched.
- If router quality improves with scale, the fraction of active query heads might be lowered further without accuracy loss.
- Token-level routing decisions might reveal which tokens benefit most from additional query heads, offering a diagnostic for attention difficulty.
Load-bearing premise
The router can reliably choose a useful subset of query heads for each token without the overall model needing extra capacity or extra training tokens to recover lost accuracy.
What would settle it
Train a 250M-parameter GQE model and its dense GQA counterpart on exactly the same 30B tokens; if downstream accuracy is statistically indistinguishable when GQE activates precisely half the query heads, the central claim holds.
Figures

read the original abstract
Self-attention is central to Transformer performance and is often the most expensive part of the Transformer at long context lengths because its pairwise token interactions scale quadratically with sequence length. Standard dense attention also applies the same set of attention heads to every token regardless of token difficulty or information content. This uniform activation can waste compute, especially as sequences grow longer and attention cost increases rapidly. We propose Grouped Query Experts (GQE), a mixture-of-experts layer on top of grouped-query attention (GQA). Within each GQA group, a router selects k query-head experts per token while all key-value (KV) heads remain dense and unchanged. Thus, GQE keeps the KV cache benefits of GQA and reduces only the active query-head computation. On a fixed 30B token budget at the 250M parameter scale, GQE matches the all-active GQA baseline in downstream accuracy while activating half the query heads per token.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Grouped Query Experts (GQE), a mixture-of-experts variant applied to the query heads of Grouped Query Attention (GQA). Within each GQA group a router selects k query-head experts per token while all key-value heads remain dense and active. The central claim is that a 250M-parameter GQE model trained on a fixed 30B-token budget matches the downstream accuracy of the corresponding all-active GQA baseline while activating only half the query heads per token.
Significance. If the empirical result is reproducible and the router demonstrably performs non-trivial selection, the method would provide a practical route to reduce query-head compute in attention layers without enlarging the KV cache or requiring extra training tokens. The design preserves the inference advantages of GQA while introducing sparsity only where it is claimed to be tolerable.
major comments (3)
- [Abstract] Abstract: the headline claim that GQE 'matches the all-active GQA baseline in downstream accuracy' is stated without any numerical results, tables, or error bars. No baseline or GQE accuracy values, number of downstream tasks, or statistical test are supplied, so the magnitude and reliability of the claimed parity cannot be assessed.
- No section or appendix describes the router architecture, its input features, the routing function, the value of k, or any auxiliary loss used to train the router. Without these details it is impossible to determine whether the reported efficiency gain arises from learned token-dependent selection or from a fixed or random pattern.
- The experimental protocol (250M scale, 30B-token budget) is mentioned but no information is given on number of random seeds, variance across runs, hyper-parameter search, or ablation studies that isolate the contribution of the router versus other design choices. These omissions make the central empirical claim impossible to evaluate from the manuscript.
minor comments (2)
- Notation for the number of active heads (k) and the GQA group size should be introduced explicitly with an equation or diagram in the methods section.
- The manuscript would benefit from a clear statement of the total parameter count of GQE versus the dense GQA baseline, including any overhead from the router.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to provide the requested details and numerical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that GQE 'matches the all-active GQA baseline in downstream accuracy' is stated without any numerical results, tables, or error bars. No baseline or GQE accuracy values, number of downstream tasks, or statistical test are supplied, so the magnitude and reliability of the claimed parity cannot be assessed.
Authors: We agree the abstract would be strengthened by explicit numbers. In revision we will add the per-task accuracies for both GQE and the dense GQA baseline, the total number of downstream tasks, and any available standard deviations from repeated runs. revision: yes
-
Referee: [—] No section or appendix describes the router architecture, its input features, the routing function, the value of k, or any auxiliary loss used to train the router. Without these details it is impossible to determine whether the reported efficiency gain arises from learned token-dependent selection or from a fixed or random pattern.
Authors: The current manuscript contains a brief description of the router in Section 3, but we accept that it is insufficiently explicit. We will add a dedicated subsection specifying the router as a linear projection followed by top-k softmax, the input features (query-head projections), k equal to half the query heads per group, and the auxiliary load-balancing loss. revision: yes
-
Referee: [—] The experimental protocol (250M scale, 30B-token budget) is mentioned but no information is given on number of random seeds, variance across runs, hyper-parameter search, or ablation studies that isolate the contribution of the router versus other design choices. These omissions make the central empirical claim impossible to evaluate from the manuscript.
Authors: We will expand the experimental section to report three random seeds, observed accuracy variance, the hyper-parameter search procedure, and new ablations that compare the learned router against random and fixed routing baselines. revision: yes
Circularity Check
No circularity: empirical comparison on fixed budget is externally verifiable
full rationale
The paper's central claim is an empirical performance match between GQE and dense GQA on a fixed 30B-token, 250M-parameter setup. No equations, fitted parameters, or self-citations are shown that would reduce the reported downstream accuracy to a quantity defined by the router or method itself. The result remains a standard experimental outcome that can be reproduced or falsified independently of the paper's internal definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vaswani et al
A. Vaswani et al. Attention Is All You Need.NeurIPS, 2017. 8
2017
-
[2]
Shazeer et al
N. Shazeer et al. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.ICLR, 2017
2017
-
[3]
D.Lepikhinetal.GShard: ScalingGiantModelswithConditionalComputationandAutomatic Sharding.arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[4]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.arXiv:2101.03961, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
N. Shazeer. Fast Transformer Decoding: One Write-Head is All You Need.arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
J. Ainslie et al. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Michel, O
P. Michel, O. Levy, and G. Neubig. Are Sixteen Heads Really Better than One?NeurIPS, 2019
2019
-
[8]
Voita et al
E. Voita et al. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.ACL, 2019
2019
-
[9]
H. Peng, R. Schwartz, D. Li, and N. A. Smith. A Mixture ofh−1Heads is Better thanh Heads.ACL, 2020
2020
-
[10]
Zhang et al
Z. Zhang et al. Mixture of Attention Heads: Selecting Attention Heads Per Token.EMNLP, 2022
2022
- [11]
- [12]
-
[13]
Csordás et al
R. Csordás et al. SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention. arXiv preprint, 2023
2023
- [14]
- [15]
-
[16]
G. Penedo et al. FineWeb2: One Pipeline to Scale Them All—Adapting Pre-Training Data Processing to Every Language.arXiv:2506.20920, 2025
-
[17]
Zellers et al
R. Zellers et al. HellaSwag: Can a Machine Really Finish Your Sentence?ACL, 2019
2019
-
[18]
Bisk et al
Y. Bisk et al. PIQA: Reasoning about Physical Commonsense in Natural Language.AAAI, 2020
2020
-
[19]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
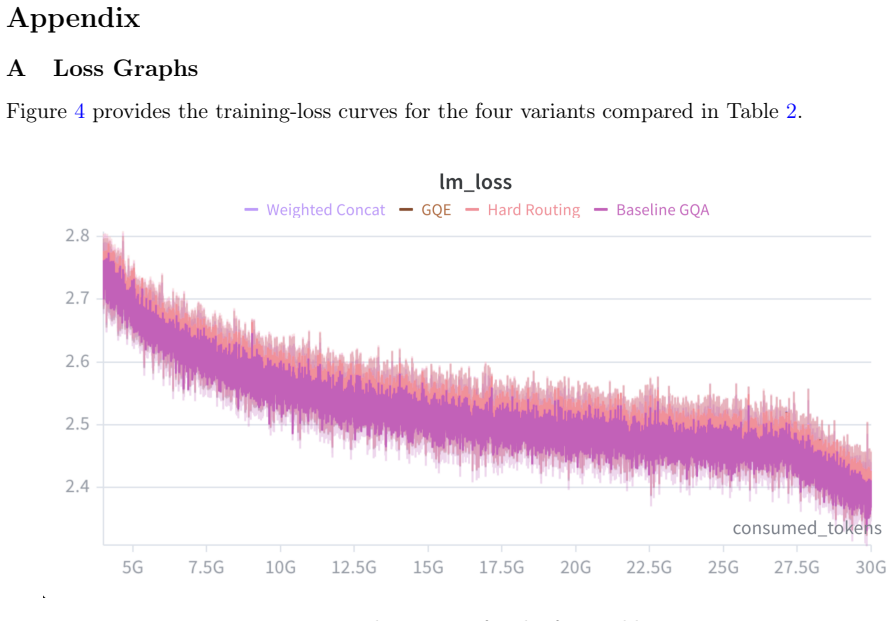
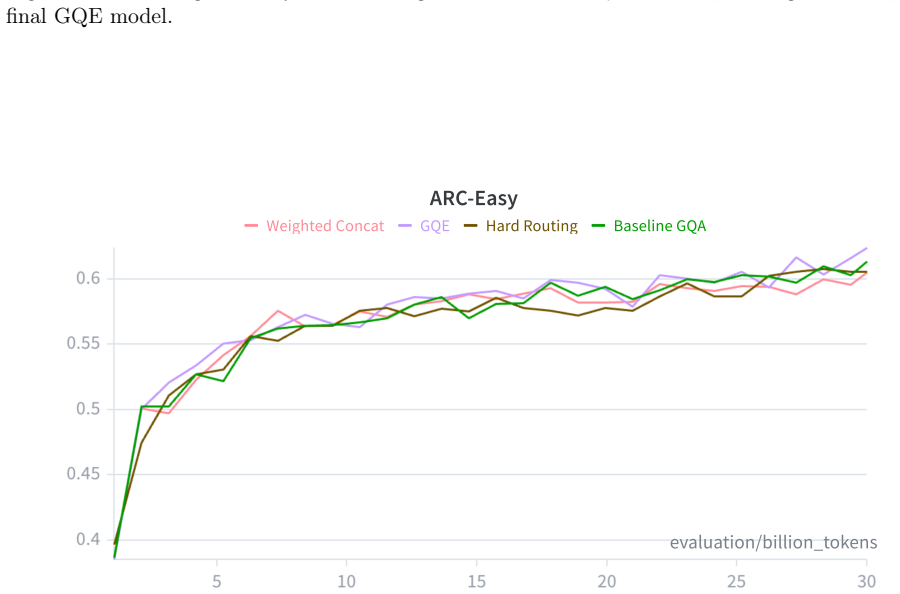
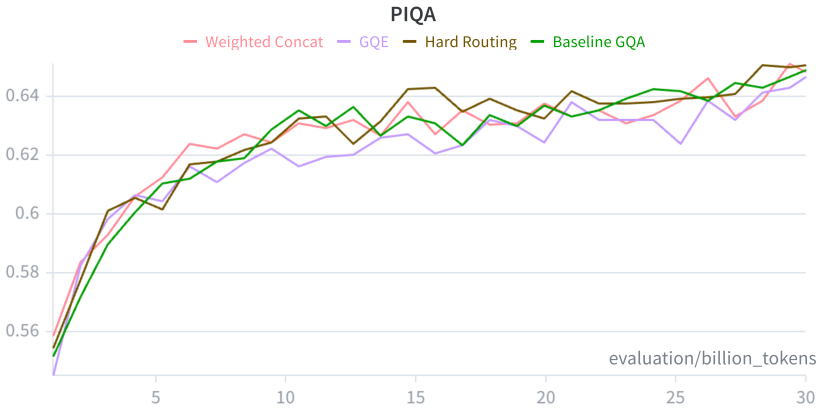
P. Clark et al. Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge.arXiv:1803.05457, 2018. 9 Appendix A Loss Graphs Figure 4 provides the training-loss curves for the four variants compared in Table 2. Figure 4: Training-loss curves for the four Table 2 variants. B Downstream Task Accuracy Graphs Figures 5–7 show downstream acc...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.