Formalizing Task-Space Complexity for Zero-Shot Generalization
Pith reviewed 2026-06-26 17:26 UTC · model grok-4.3
The pith
Signed divergence upper bounds the generalization gap from source to target contexts and induces ε-tolerance sets for policy classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The signed divergence is introduced as a performance-centric directional task dissimilarity that upper bounds the generalization gap from a source context to a target context; it induces ε-tolerance sets that certify when a source policy class generalizes, and it yields the concrete notion of task-space complexity as the minimum number of source contexts needed so that every target context incurs at most ε generalization gap.
What carries the argument
The signed divergence, a directional performance-difference measure between contexts that bounds generalization gaps and generates tolerance sets.
If this is right
- ε-tolerance sets supply explicit certificates that a given source policy class will generalize to any target inside the set.
- Task-space complexity equals the size of the smallest source collection whose tolerance sets cover the entire target space at level ε.
- Under the smoothness assumption the tolerance sets admit certified inner and outer balls together with instance-dependent volume bounds.
- Selecting a minimal source set reduces to a set-cover problem on which the greedy algorithm inherits the standard H(n) approximation guarantee.
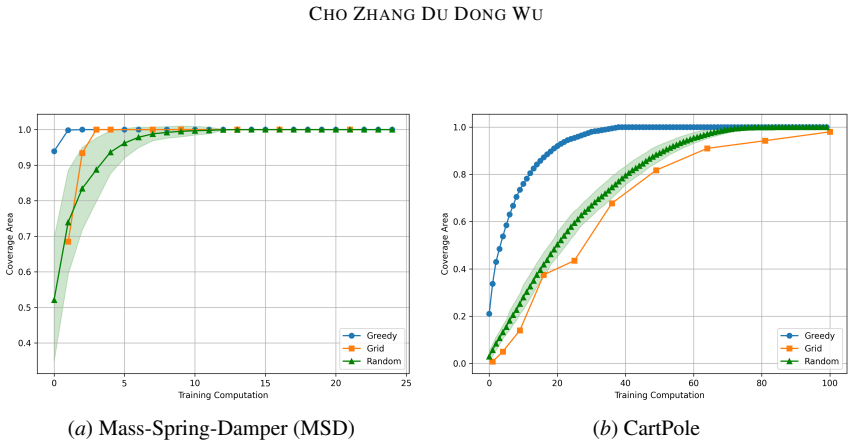
- In the Mass-Spring-Damper LQR and nonlinear CartPole examples the greedy choice achieves the target ε-coverage with strictly fewer policies than uniform or random selection.
Where Pith is reading between the lines
- The same signed-divergence construction could be used to decide how many simulation contexts are required before transferring a policy to hardware.
- Volume bounds derived from the smoothness assumption might be turned into scaling predictions for the number of training tasks needed as state dimension increases.
- The set-cover reduction suggests that existing approximation algorithms for covering problems could be imported directly into task-selection pipelines for reinforcement learning.
Load-bearing premise
Performance varies smoothly enough with small changes in context to support certified inner and outer balls around the tolerance sets.
What would settle it
A counter-example pair of source and target contexts where the measured performance gap exceeds the signed-divergence upper bound, or an instance where the local smoothness condition is violated and the claimed volume bounds on task-space complexity fail to hold.
Figures

read the original abstract
Policies must operate across diverse conditions, yet a single policy is often conservative while fully adaptive schemes can be complex. We study zero-shot generalization in contextual dynamical systems and introduce a performance-centric, directional task dissimilarity--the signed divergence--that upper bounds the generalization gap from a source context to a target context. The signed divergence induces $\varepsilon$-tolerance sets that certify when a source policy class generalizes, and it yields a concrete notion of task-space complexity: the minimum number of source contexts needed so that every target context incurs at most $\varepsilon$ generalization gap. Under a mild local smoothness assumption on performance, the induced tolerance sets admit certified inner/outer balls and instance-dependent volume bounds on task-space complexity. In the finite-oracle setting, source selection reduces to set cover; a greedy strategy inherits the standard $H(n)$ approximation guarantee. Using a Mass-Spring-Damper system with linear-quadratic regulator (LQR) controllers and a nonlinear CartPole system with deep reinforcement learning controllers, we show that greedy selection achieves the same $\varepsilon$-coverage with fewer policies than uniform or random baselines. Our approach delivers a performance-based task similarity measure and practical certificates for building generalizable control with simple policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces signed divergence, a directional performance-based dissimilarity between contexts in dynamical systems, which is shown to upper-bound the generalization gap from source to target contexts. This induces ε-tolerance sets that certify when a source policy class generalizes zero-shot, and defines task-space complexity as the smallest number of source contexts guaranteeing ε-coverage of all targets. Under a local smoothness assumption on the performance map, the tolerance sets admit inner/outer ball certificates and instance-dependent volume bounds. Source selection reduces to minimum set cover (with the standard greedy H(n) approximation), and experiments on an LQR-controlled mass-spring-damper system and a DRL-controlled CartPole system report that greedy selection achieves the same ε-coverage with fewer policies than uniform or random baselines.
Significance. If the local smoothness assumption is satisfied and the signed-divergence bound is non-vacuous, the work supplies a concrete, performance-centric notion of task similarity together with certificates for zero-shot generalization and a set-cover reduction that justifies greedy source selection. The empirical demonstration that greedy covers targets with fewer policies than baselines is a practical strength; the set-cover connection is a clean application of a standard result.
major comments (2)
- [Abstract, §4] Abstract and §4 (theorems on tolerance sets and volume bounds): the certified inner/outer balls and instance-dependent volume bounds on task-space complexity are derived only after invoking the local smoothness assumption on the performance map (context → expected return). No diagnostic is supplied in the LQR or CartPole experiments (gradient norms, local Lipschitz estimates, or counter-example search) to confirm the assumption holds even locally; if violated, the certificates and volume bounds become invalid while the reported coverage numbers remain unchanged.
- [§2] §2 (definition of signed divergence): the claim that signed divergence 'upper bounds the generalization gap' appears to follow directly from the definition of the measure rather than from independent premises about the dynamics or policy class; this makes the bounding relation definitional. The paper should clarify whether any non-trivial derivation occurs beyond the definition itself.
minor comments (2)
- [§2] Notation for ε-tolerance sets and task-space complexity should be introduced with a single consistent symbol in §2 before being used in the theorems.
- [§5] The experimental figures would benefit from error bars or multiple random seeds to show variability in the greedy vs. baseline coverage curves.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (theorems on tolerance sets and volume bounds): the certified inner/outer balls and instance-dependent volume bounds on task-space complexity are derived only after invoking the local smoothness assumption on the performance map (context → expected return). No diagnostic is supplied in the LQR or CartPole experiments (gradient norms, local Lipschitz estimates, or counter-example search) to confirm the assumption holds even locally; if violated, the certificates and volume bounds become invalid while the reported coverage numbers remain unchanged.
Authors: We agree that the local smoothness assumption is required for the inner/outer ball certificates and volume bounds, and that the experiments do not include diagnostics (such as local Lipschitz estimates) to verify it. The reported ε-coverage numbers are computed directly from the signed divergence and remain valid independently of the assumption. In the revised manuscript we will add a discussion paragraph in the experimental section that (i) explicitly states the independence of the coverage results from the smoothness assumption and (ii) outlines practical verification methods (e.g., finite-difference estimates of local Lipschitz constants on the performance map). This is a partial revision because we add clarification and guidance rather than new empirical diagnostics. revision: partial
-
Referee: [§2] §2 (definition of signed divergence): the claim that signed divergence 'upper bounds the generalization gap' appears to follow directly from the definition of the measure rather than from independent premises about the dynamics or policy class; this makes the bounding relation definitional. The paper should clarify whether any non-trivial derivation occurs beyond the definition itself.
Authors: The referee is correct: the inequality D_s(θ, θ') ≥ J(θ') − J(θ) holds by construction of the signed divergence and does not rely on additional premises about the dynamics or policy class. No non-trivial derivation beyond the definition is claimed or performed. The subsequent technical contributions—inducing ε-tolerance sets, obtaining ball certificates under smoothness, and reducing source selection to set cover—are non-definitional. We will revise the text in §2 to state explicitly that the bounding relation is definitional while emphasizing the downstream utility of the measure. This change will be incorporated in the revision. revision: yes
Circularity Check
Signed divergence introduced to upper-bound generalization gap by definition; ε-tolerance sets and task-space complexity follow tautologically
specific steps
-
self definitional
[Abstract]
"introduce a performance-centric, directional task dissimilarity--the signed divergence--that upper bounds the generalization gap from a source context to a target context. The signed divergence induces ε-tolerance sets that certify when a source policy class generalizes, and it yields a concrete notion of task-space complexity: the minimum number of source contexts needed so that every target context incurs at most ε generalization gap."
The signed divergence is introduced precisely as the dissimilarity measure that upper-bounds the gap and induces the certifying sets; the bounding relation and certification therefore hold by the definition of the new object rather than being derived from prior independent premises about the performance map.
full rationale
The paper's core objects (signed divergence, ε-tolerance sets, task-space complexity) are defined such that the claimed bounding and certification properties hold by construction. The abstract explicitly introduces the signed divergence as the object that 'upper bounds the generalization gap' and 'induces ε-tolerance sets that certify' generalization. Under the local smoothness assumption the volume bounds are then derived, but the primary performance interpretation reduces to the definitional choice rather than an independent derivation. The set-cover reduction in the finite-oracle case is standard and non-circular. No self-citations or imported uniqueness theorems appear load-bearing in the provided text. This yields partial circularity (score 6) but leaves the empirical coverage results and smoothness invocation as separate issues.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (1)
- domain assumption mild local smoothness assumption on performance
invented entities (3)
-
signed divergence
no independent evidence
-
ε-tolerance sets
no independent evidence
-
task-space complexity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on automatic Control , volume=
Guaranteed margins for LQG regulators , author=. IEEE Transactions on automatic Control , volume=. 2003 , publisher=
2003
-
[2]
Journal of Machine Learning Research , volume=
End-to-end training of deep visuomotor policies , author=. Journal of Machine Learning Research , volume=
-
[3]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[4]
and Veness, Joel and Bellemare, Marc G
Human-level control through deep reinforcement learning , volume =. Nature , author =. 2015 , pages =. doi:10.1038/nature14236 , language =
-
[5]
Nature , volume=
Autonomous navigation of stratospheric balloons using reinforcement learning , author=. Nature , volume=. 2020 , publisher=
2020
-
[6]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , year =. Reinforcement learning: an introduction , isbn =
-
[7]
Annual Reviews in Control , volume=
Reinforcement learning for control: Performance, stability, and deep approximators , author=. Annual Reviews in Control , volume=. 2018 , publisher=
2018
-
[8]
Advances in Neural Information Processing Systems , volume=
Model-Based Transfer Learning for Contextual Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2312.09436 , year=
Temporal Transfer Learning for Traffic Optimization with Coarse-grained Advisory Autonomy , author=. arXiv preprint arXiv:2312.09436 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
The impact of task underspecification in evaluating deep reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
IEEE Transactions on Automation Science and Engineering , volume=
Unified automatic control of vehicular systems with reinforcement learning , author=. IEEE Transactions on Automation Science and Engineering , volume=. 2022 , publisher=
2022
-
[12]
2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , pages=
Reinforcement learning for mixed autonomy intersections , author=. 2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , pages=. 2021 , organization=
2021
-
[13]
arXiv preprint arXiv:1502.02259 , year=
Contextual markov decision processes , author=. arXiv preprint arXiv:1502.02259 , year=
-
[14]
The Thirteenth International Conference on Learning Representations , year=
IntersectionZoo: Eco-driving for Benchmarking Multi-Agent Contextual Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[15]
2023 , journal=
Contextualize Me--The Case for Context in Reinforcement Learning , author=. 2023 , journal=
2023
-
[16]
2018 21st International Conference on Intelligent Transportation Systems (ITSC) , pages=
Zero-shot deep reinforcement learning driving policy transfer for autonomous vehicles based on robust control , author=. 2018 21st International Conference on Intelligent Transportation Systems (ITSC) , pages=. 2018 , organization=
2018
-
[17]
Robotics Research: The 18th International Symposium ISRR , pages=
Adapt: zero-shot adaptive policy transfer for stochastic dynamical systems , author=. Robotics Research: The 18th International Symposium ISRR , pages=. 2019 , organization=
2019
-
[18]
IEEE Robotics and Automation Letters , volume=
Multi-task reinforcement learning with attention-based mixture of experts , author=. IEEE Robotics and Automation Letters , volume=. 2023 , publisher=
2023
-
[19]
The Twelfth International Conference on Learning Representations , year=
Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
IEEE Transactions on Robotics , volume=
Flow: A modular learning framework for mixed autonomy traffic , author=. IEEE Transactions on Robotics , volume=. 2021 , publisher=
2021
-
[21]
Algorithmic Learning Theory , pages=
Markov decision processes with continuous side information , author=. Algorithmic Learning Theory , pages=. 2018 , organization=
2018
-
[22]
Proceedings of the 28th International Conference on Machine Learning (ICML-11) , pages=
Learning with whom to share in multi-task feature learning , author=. Proceedings of the 28th International Conference on Machine Learning (ICML-11) , pages=
-
[23]
Advances in neural information processing systems , volume=
Distral: Robust multitask reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[24]
International conference on machine learning , pages=
Which tasks should be learned together in multi-task learning? , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[25]
nature , volume=
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
2017
-
[26]
The International Journal of Robotics Research , volume=
Reinforcement learning in robotics: A survey , author=. The International Journal of Robotics Research , volume=. 2013 , publisher=
2013
-
[27]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Generalizing cooperative eco-driving via multi-residual task learning , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[28]
, author=
Metrics for Finite Markov Decision Processes. , author=. UAI , volume=
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Scalable methods for computing state similarity in deterministic markov decision processes , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
International Conference on Learning Representations , year=
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[31]
Proceedings of the 24th international conference on Machine learning , pages=
Cross-domain transfer for reinforcement learning , author=. Proceedings of the 24th international conference on Machine learning , pages=
-
[32]
International Conference on Learning Representations , year=
Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[33]
28th AAAI Conference on Artificial Intelligence, AAAI 2014 , pages=
An automated measure of mdp similarity for transfer in reinforcement learning , author=. 28th AAAI Conference on Artificial Intelligence, AAAI 2014 , pages=. 2014 , organization=
2014
-
[34]
2012 , publisher=
Robust adaptive control , author=. 2012 , publisher=
2012
-
[35]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[36]
International Conference on Machine Learning , pages=
Darla: Improving zero-shot transfer in reinforcement learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[37]
Journal of Artificial Intelligence Research , volume=
A survey of zero-shot generalisation in deep reinforcement learning , author=. Journal of Artificial Intelligence Research , volume=
-
[38]
Neural computation , volume=
Robust reinforcement learning , author=. Neural computation , volume=. 2005 , publisher=
2005
-
[39]
International conference on machine learning , pages=
Robust adversarial reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[40]
International conference on machine learning , pages=
Policy gradient method for robust reinforcement learning , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[41]
Proceedings of the 24th international conference on Machine learning , pages=
Multi-task reinforcement learning: a hierarchical bayesian approach , author=. Proceedings of the 24th international conference on Machine learning , pages=
-
[42]
Electronics , volume=
A survey of multi-task deep reinforcement learning , author=. Electronics , volume=. 2020 , publisher=
2020
-
[43]
1996 , publisher=
Robust adaptive control , author=. 1996 , publisher=
1996
-
[44]
2014 , publisher=
Adaptive filtering prediction and control , author=. 2014 , publisher=
2014
-
[45]
1998 , publisher=
Essentials of robust control , author=. 1998 , publisher=
1998
-
[46]
Foundations of Computational Mathematics , volume=
A theoretical and empirical comparison of gradient approximations in derivative-free optimization , author=. Foundations of Computational Mathematics , volume=. 2022 , publisher=
2022
-
[47]
Johns Hopkins apl technical digest , volume=
An overview of the simultaneous perturbation method for efficient optimization , author=. Johns Hopkins apl technical digest , volume=
-
[48]
IEEE Transactions on aerospace and electronic systems , volume=
Implementation of the simultaneous perturbation algorithm for stochastic optimization , author=. IEEE Transactions on aerospace and electronic systems , volume=. 2002 , publisher=
2002
-
[49]
IEEE transactions on automatic control , volume=
Multivariate stochastic approximation using a simultaneous perturbation gradient approximation , author=. IEEE transactions on automatic control , volume=. 1992 , publisher=
1992
-
[50]
International conference on machine learning , year =
Learning Policy Committees for Effective Personalization in MDPs with Diverse Tasks , author=. International conference on machine learning , year =
-
[51]
ACM Transactions on Algorithms (TALG) , volume=
On the set multicover problem in geometric settings , author=. ACM Transactions on Algorithms (TALG) , volume=. 2012 , publisher=
2012
-
[52]
Balls in Rk do not cut all subsets of k + 2 points , journal =
R.M Dudley , abstract =. Balls in Rk do not cut all subsets of k + 2 points , journal =. 1979 , issn =. doi:https://doi.org/10.1016/0001-8708(79)90047-1 , url =
-
[53]
Annales de l'Institut Fourier , pages =
Assouad, Patrick , title =. Annales de l'Institut Fourier , pages =. 1983 , doi =
1983
-
[54]
Automatica , volume=
Research on gain scheduling , author=. Automatica , volume=. 2000 , publisher=
2000
-
[55]
2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2017 , organization=
2017
-
[56]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[57]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[58]
IEEE transactions on knowledge and data engineering , volume=
A survey on multi-task learning , author=. IEEE transactions on knowledge and data engineering , volume=. 2021 , publisher=
2021
-
[59]
2001 , publisher=
Approximation algorithms , author=. 2001 , publisher=
2001
-
[60]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[61]
Information Processing Letters , volume=
Hitting sets when the VC-dimension is small , author=. Information Processing Letters , volume=. 2005 , publisher=
2005
-
[62]
1972 , publisher=
Reducibility among combinatorial problems , author=. 1972 , publisher=
1972
-
[63]
Advances in Neural Information Processing Systems , volume=
When is generalizable reinforcement learning tractable? , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
arXiv preprint arXiv:2503.07988 , year=
Provable zero-shot generalization in offline reinforcement learning , author=. arXiv preprint arXiv:2503.07988 , year=
-
[65]
arXiv preprint arXiv:2505.18447 , year=
Pessimism Principle Can Be Effective: Towards a Framework for Zero-Shot Transfer Reinforcement Learning , author=. arXiv preprint arXiv:2505.18447 , year=
-
[66]
Proceedings of the 24th annual Conference On Learning Theory , pages=
Contextual bandits with similarity information , author=. Proceedings of the 24th annual Conference On Learning Theory , pages=. 2011 , organization=
2011
-
[67]
Conference on Lifelong Learning Agents , pages=
Statistical Context Detection for Deep Lifelong Reinforcement Learning , author=. Conference on Lifelong Learning Agents , pages=. 2025 , organization=
2025
-
[68]
Cognitive psychology , volume=
What makes some problems really hard: Explorations in the problem space of difficulty , author=. Cognitive psychology , volume=. 1990 , publisher=
1990
-
[69]
arXiv preprint arXiv:2509.00125 , year=
Know When to Explore: Difficulty-Aware Certainty as a Guide for LLM Reinforcement Learning , author=. arXiv preprint arXiv:2509.00125 , year=
-
[70]
9th International Conference on Education and Information Systems, Technologies and Applications (EISTA 2011) , year=
Task complexity and design science , author=. 9th International Conference on Education and Information Systems, Technologies and Applications (EISTA 2011) , year=
2011
-
[71]
Procedia Computer Science , volume=
The concept of problem complexity , author=. Procedia Computer Science , volume=. 2014 , publisher=
2014
-
[72]
Nature communications , volume=
Task complexity interacts with state-space uncertainty in the arbitration between model-based and model-free learning , author=. Nature communications , volume=. 2019 , publisher=
2019
-
[73]
Part 1: Finite controller coverings , author=
Multiple model adaptive control. Part 1: Finite controller coverings , author=. International Journal of Robust and Nonlinear Control: IFAC-Affiliated Journal , volume=. 2000 , publisher=
2000
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Taskonomy: Disentangling task transfer learning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[75]
ICLR , year =
Emilio Parisotto and Jimmy Ba and Ruslan Salakhutdinov , title =. ICLR , year =
-
[76]
Learning for Dynamics and Control , pages=
Suboptimal coverings for continuous spaces of control tasks , author=. Learning for Dynamics and Control , pages=. 2021 , organization=
2021
-
[77]
2022 International Conference on Robotics and Automation (ICRA) , pages=
Synergistic scheduling of learning and allocation of tasks in human-robot teams , author=. 2022 International Conference on Robotics and Automation (ICRA) , pages=. 2022 , organization=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.