UNITY: Attention Flow Networks for Adaptive Conditioning in Diffusion
Pith reviewed 2026-06-26 17:31 UTC · model grok-4.3
The pith
UNITY uses a two-stage universal-to-specialized adapter to handle composite conditioning in diffusion models at constant complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
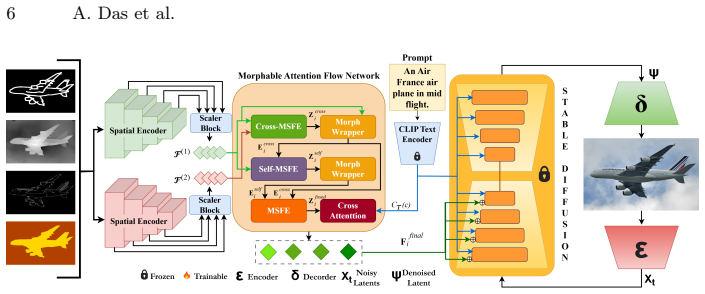
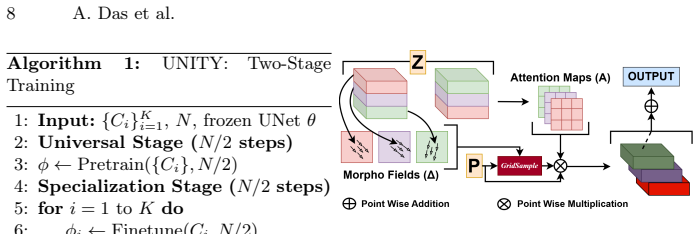
UNITY is a Universal-to-Specialized adapter that jointly learns shared semantics across multiple conditioning types in a Universal Stage using half the total training steps, then refines modality-specific features in a Specialization Stage, with Morphable Attention Flow (MAF) Network and Morph Wrapper modules providing channel-aware and spatially adaptive feature alignment through learnable flow fields and attention-based fusion, all at constant complexity to support single and composite conditioning while reducing inference latency and memory consumption.
What carries the argument
Morphable Attention Flow (MAF) Network and Morph Wrapper modules, which enable channel-aware and spatially adaptive feature alignment through learnable flow fields and attention-based fusion.
If this is right
- The same trained adapter supports both single-modality and composite conditioning without architectural changes.
- Inference runs at constant complexity, cutting latency and memory relative to multiple separate adapters.
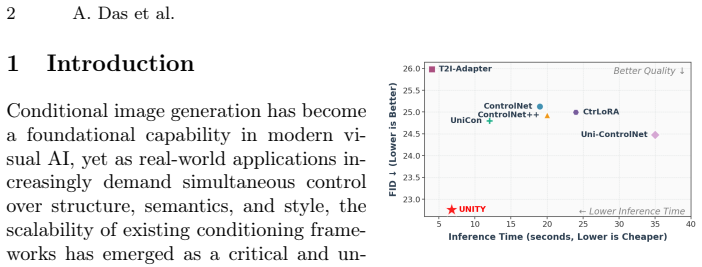
- State-of-the-art image fidelity is reached across multiple datasets under the two-stage budget split.
- Specialization occurs after the universal stage without any modification to the base diffusion model.
Where Pith is reading between the lines
- The constant-complexity design could allow adding new conditioning modalities without retraining from scratch.
- The two-stage split might transfer to other generative backbones that currently rely on modality-specific fine-tuning.
- Lower memory footprint could make conditioned generation practical on hardware with tighter resource limits.
Load-bearing premise
A universal stage trained on half the total steps can capture effective cross-modal representations across all conditioning modalities that then allow successful specialization without modifying the underlying diffusion architecture.
What would settle it
An experiment that trains separate per-modality adapters on the same total step budget and shows they produce higher image fidelity or lower memory use than UNITY on composite conditioning tasks would falsify the central efficiency claim.
Figures


read the original abstract
We introduce UNITY, a Universal-to-Specialized adapter for efficient and scalable composite conditioning in diffusion based image generation. Unlike prior methods that train separate adapters for each conditioning modality, UNITY jointly learns shared semantics across multiple conditioning types and subsequently specializes without modifying the underlying architecture. The proposed two stage training paradigm consists of a Universal Stage that captures cross modal representations across all conditioning modalities using half of the total training steps, followed by a Specialization Stage that refines modality specific features using the remaining training budget. At the core of UNITY are the Morphable Attention Flow (MAF) Network and Morph Wrapper modules, which enable channel aware and spatially adaptive feature alignment through learnable flow fields and attention based fusion. This constant complexity formulation supports flexible operation under both single and composite conditioning settings while significantly reducing inference latency and memory consumption. Extensive experiments across multiple datasets demonstrate that UNITY achieves state of the art image fidelity while maintaining superior memory efficiency. Code: https://github.com/arya-domain/UNITY
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UNITY, a Universal-to-Specialized adapter for composite conditioning in diffusion models. It employs a two-stage training paradigm consisting of a Universal Stage (half the total training steps) that learns shared cross-modal representations via the Morphable Attention Flow (MAF) Network and Morph Wrapper modules, followed by a Specialization Stage that refines modality-specific features without altering the base diffusion architecture. The method is claimed to achieve constant complexity, support both single and composite conditioning, reduce inference latency and memory use, and attain state-of-the-art image fidelity across multiple datasets.
Significance. If the central claims hold, UNITY could offer a practical advance in scalable multi-modal diffusion by avoiding per-modality adapters and architecture modifications while preserving efficiency. The constant-complexity attention-flow formulation and two-stage paradigm address a real tension in composite conditioning. However, the manuscript provides no quantitative results, ablations, or derivations to substantiate these claims, so the potential significance cannot be assessed from the given text.
major comments (3)
- [Abstract] Abstract: The central claims of state-of-the-art image fidelity and superior memory efficiency rest on 'extensive experiments across multiple datasets,' yet no tables, figures, quantitative metrics, error bars, or baseline comparisons are supplied. This absence is load-bearing because the performance assertions cannot be evaluated.
- [Abstract] Abstract (two-stage paradigm): The assumption that a universal stage trained on half the total steps suffices to learn cross-modal representations that then enable successful specialization without architecture changes is stated without any supporting ablation, representation analysis, or stability test under composite conditioning. This directly underpins the constant-complexity claim and the 'without modifying the underlying diffusion architecture' assertion.
- [Abstract] Abstract: No equations, derivations, or complexity analysis are provided for the MAF Network, Morph Wrapper, learnable flow fields, or attention-based fusion that are said to deliver constant complexity. The absence prevents verification of the 'constant complexity formulation' that is central to the efficiency claims.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that the current version of the manuscript does not include the supporting quantitative results, ablations, or derivations referenced in the abstract. We will revise the paper to incorporate these elements to substantiate the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of state-of-the-art image fidelity and superior memory efficiency rest on 'extensive experiments across multiple datasets,' yet no tables, figures, quantitative metrics, error bars, or baseline comparisons are supplied. This absence is load-bearing because the performance assertions cannot be evaluated.
Authors: We acknowledge this point. The manuscript as submitted does not contain the experimental results, tables, or figures. In the revised version, we will add comprehensive experimental results including tables with quantitative metrics, comparisons to baselines, error bars where applicable, and figures demonstrating performance across datasets. This will allow proper evaluation of the claims. revision: yes
-
Referee: [Abstract] Abstract (two-stage paradigm): The assumption that a universal stage trained on half the total steps suffices to learn cross-modal representations that then enable successful specialization without architecture changes is stated without any supporting ablation, representation analysis, or stability test under composite conditioning. This directly underpins the constant-complexity claim and the 'without modifying the underlying diffusion architecture' assertion.
Authors: We agree that ablations and analyses are necessary to support the two-stage paradigm. We will include ablations on the universal and specialization stages, representation analyses (e.g., t-SNE or similarity metrics), and tests under composite conditioning to demonstrate stability and the validity of the approach without architecture modifications. revision: yes
-
Referee: [Abstract] Abstract: No equations, derivations, or complexity analysis are provided for the MAF Network, Morph Wrapper, learnable flow fields, or attention-based fusion that are said to deliver constant complexity. The absence prevents verification of the 'constant complexity formulation' that is central to the efficiency claims.
Authors: We will add the mathematical formulations, including equations for the MAF Network, Morph Wrapper, learnable flow fields, and attention-based fusion. Additionally, we will provide derivations and a complexity analysis (e.g., big-O notation for time and memory) to verify the constant complexity under single and composite conditioning. revision: yes
Circularity Check
No circularity: method description contains no derivations or predictions that reduce to inputs
full rationale
The provided abstract and description introduce a two-stage training paradigm (universal stage on half the steps followed by specialization) and modules (MAF Network, Morph Wrapper) but supply no equations, quantitative derivations, fitted parameters, or self-citations that could be inspected for reduction by construction. No load-bearing claims are shown to equate to their own inputs, and the central claims rest on empirical results rather than any self-referential math or imported uniqueness theorems. This is the expected outcome when no derivation chain is present to analyze.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Morphable Attention Flow (MAF) Network
no independent evidence
-
Morph Wrapper
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vision transformer adapter for dense predictions
Chen, Z., Duan, Y., Wang, W., He, J., Lu, T., Dai, J., Qiao, Y.: Vision transformer adapter for dense predictions. arXiv preprint arXiv:2205.08534 (2022)
-
[2]
NICE: Non-linear Independent Components Estimation
Dinh,L.,Krueger,D.,Bengio,Y.:Nice:Non-linearindependentcomponents estimation. arXiv preprint arXiv:1410.8516 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[3]
In: International Conference on Learning Representations
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Un- terthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations
-
[4]
In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
Hessel, J., Holtzman, A., Forbes, M., Bras, R.L., Choi, Y.: Clipscore: A reference-free evaluation metric for image captioning. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 7514–7528 (2021)
2021
-
[5]
In: Advances in Neural Information Processing Systems (NeurIPS)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilib- rium. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 6626–6637 (2017)
2017
-
[6]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6840–6851 (2020)
2020
-
[7]
In: International Conference on Machine Learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q.D., Gesmundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learn- ing for nlp. In: International Conference on Machine Learning. pp. 2790–
-
[8]
arXiv preprint arXiv:2501.04328 (2025)
Hu, J., Zhou, X., Liu, Z.: Unicombine: Unified multi-conditional combi- nation with diffusion models for flexible image synthesis. arXiv preprint arXiv:2501.04328 (2025)
-
[9]
Huang, L., Chen, D., Liu, Y., Yujun, S., Zhao, D., Jingren, Z.: Com- poser:Creativeandcontrollableimagesynthesiswithcomposableconditions (2023)
2023
-
[10]
In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVI
Huang, X., Mallya, A., Wang, T.C., Liu, M.Y.: Multimodal conditional image synthesis with product-of-experts gans. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVI. pp. 91–109. Springer (2022)
2022
-
[11]
In: Cristea, A.I., Walker, E., Lu, Y., Santos, O.C., Isotani, S
Li, M., Yang, T., Kuang, H., Wu, J., Wang, Z., Xiao, X., Chen, C.: Control- net++: Improving conditional controls with efficient consistency feedback. In:Computer Vision–ECCV 2024:18thEuropeanConference,Milan,Italy, September 29–October 4, 2024, Proceedings, Part VII. p. 129–147. Springer- Verlag,Berlin,Heidelberg(2024).https://doi.org/10.1007/978-3-031- ...
-
[12]
In: The Thir- teenth International Conference on Learning Representations (2025)
Li, X., Herrmann, C., Chan, K.C., Li, Y., Sun, D., Yang, M.H.: A simple approach to unifying diffusion-based conditional generation. In: The Thir- teenth International Conference on Learning Representations (2025)
2025
-
[13]
In: Computer Vision–ECCV 2022: 17th Eu- ropean Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX
Li, Y., Mao, H., Girshick, R., He, K.: Exploring plain vision transformer backbones for object detection. In: Computer Vision–ECCV 2022: 17th Eu- ropean Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX. pp. 280–296. Springer (2022)
2022
-
[14]
In: European Conference on Computer Vision (ECCV)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European Conference on Computer Vision (ECCV). pp. 740–755. Springer (2014)
2014
-
[15]
In: Inter- national Conference on Learning Representations (ICLR) (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: Inter- national Conference on Learning Representations (ICLR) (2019)
2019
-
[16]
arXiv preprint arXiv:2403.01212 (2024)
Mohamed, S.: Tcig: Two-stage controlled image generation with quality en- hancement through diffusion. arXiv preprint arXiv:2403.01212 (2024)
-
[17]
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i- adapter: learning adapters to dig out more controllable ability for text-to- image diffusion models. In: Proceedings of the Thirty-Eighth AAAI Con- ference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposi...
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ni, H., Shi, C., Li, K., Huang, S.X., Min, M.R.: Conditional image-to- video generation with latent flow diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7451–7460 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Park, T., Liu, M.Y., Wang, T.C., Zhu, J.Y.: Semantic image synthesis with spatially-adaptive normalization. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 2337–2346 (2019)
2019
- [20]
-
[21]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sas- try, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[22]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchi- cal text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
In: International Confer- ence on Machine Learning
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International Confer- ence on Machine Learning. pp. 8821–8831. PMLR (2021)
2021
-
[24]
In: Proceedings of the IEEE/CVF UNITY 17 Conference on Computer Vision and Pattern Recognition
Ren, Y., Yu, X., Chen, J., Li, T.H., Li, G.: Deep image spatial transfor- mation for person image generation. In: Proceedings of the IEEE/CVF UNITY 17 Conference on Computer Vision and Pattern Recognition. pp. 7690–7699 (2020)
2020
-
[25]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High- resolution image synthesis with latent diffusion models (2022),https: //arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High- resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[27]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S.K.S., Ayan, B.K., Mahdavi, S.S., Lopes, R.G., et al.: Photo- realistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Shi, Y., Bortoli, V.D., Campbell, A., Doucet, A.: Diff2flow: Training flow matching models via diffusion bridges. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[29]
In: International Conference on Learning Representations (ICLR) (2021), https://openreview.net/forum?id=PxTIG12RRHS
Song,Y.,Sohl-Dickstein,J.,Kingma,D.P.,Kumar,A.,Ermon,S.,Poole,B.: Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations (ICLR) (2021), https://openreview.net/forum?id=PxTIG12RRHS
2021
-
[30]
arXiv preprint arXiv:2306.04356 (2023)
Sun, Q., Wei, Z., Chen, J., Wang, Z., Zhang, J.: Multigen-20m: A large- scale multi-modal dataset for controllable image generation. arXiv preprint arXiv:2306.04356 (2023)
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7832–7841 (2024)
2024
-
[32]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Wang, T.C., Liu, M.Y., Zhu, J.Y., Tao, A., Kautz, J., Catanzaro, B.: High- resolution image synthesis and semantic manipulation with conditional gans. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 8798–8807 (2018)
2018
-
[33]
In: European Conference on Computer Vision
Wei, Y., Liu, M., Wang, H., Zhu, R., Hu, G., Zuo, W.: Learning flow- based feature warping for face frontalization with illumination inconsistent supervision. In: European Conference on Computer Vision. pp. 558–574. Springer (2020)
2020
-
[34]
In: The Thirteenth International Conference on Learning Representations (2025),https:// openreview.net/forum?id=3Gga05Jdmj
Xu, Y., He, Z., Shan, S., Chen, X.: CtrloRA: An extensible and effi- cient framework for controllable image generation. In: The Thirteenth International Conference on Learning Representations (2025),https:// openreview.net/forum?id=3Gga05Jdmj
2025
-
[35]
In: IEEE International Conference on Computer Vision (ICCV) (2023)
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to- image diffusion models. In: IEEE International Conference on Computer Vision (ICCV) (2023)
2023
-
[36]
In: Advances in Neural Information Processing Systems
Zhang, Q., Chen, Y.: Diffusion normalizing flow. In: Advances in Neural Information Processing Systems. vol. 34, pp. 16280–16291 (2021)
2021
-
[37]
Das et al
Zhao, S., Chen, D., Chen, Y.C., Bao, J., Hao, S., Yuan, L., Wong, K.Y.K.: Uni-controlnet:All-in-onecontroltotext-to-imagediffusionmodels.In:Pro- 18 A. Das et al. ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11127–11137 (2024) UNITY 19 Supplementary Material 1 Training and Evaluation Weevaluatetwoconfigurations:UNITY ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.