Inductive Generalization for Robotic Manipulation
Pith reviewed 2026-06-26 14:50 UTC · model grok-4.3
The pith
Visuomotor policies that handle common domain shifts fail inductive generalization tests on progressively harder task variants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
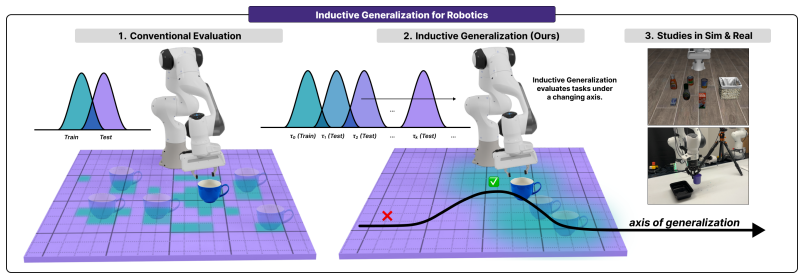
Policies that appear to generalize to prior domain shifts fail inductive generalization tests. The authors supply a reusable formal evaluation protocol for measuring inductive generalization in manipulation policies and establish baselines demonstrating that existing paradigms, including state-of-the-art vision-language-action models, do not pass.
What carries the argument
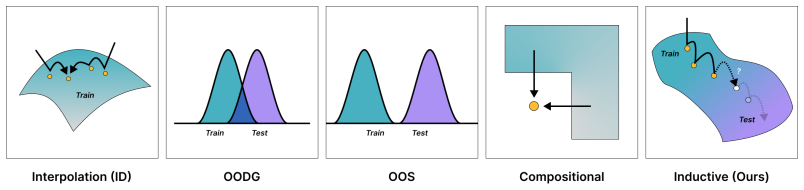
The inductive generalization evaluation protocol that tests policies on axis-based progressively harder out-of-distribution task variants.
If this is right
- Existing data and model scaling approaches leave inductive generalization challenges unaddressed.
- Realizing general purpose robots requires solving these inductive limits in addition to current scaling efforts.
- Benchmarks based only on unstructured domain shifts overestimate policy generalization.
- New training paradigms are needed that target inductive capacity directly.
Where Pith is reading between the lines
- Training curricula could be redesigned around explicit inductive task sequences rather than random domain shifts.
- The protocol could be applied to compare architectures on their ability to form reusable structures rather than memorize patterns.
- Failure on these tests may indicate policies rely on surface statistics that break when task structure changes systematically.
Load-bearing premise
The proposed progressively harder task variants constitute a valid and representative measure of inductive capacity rather than an arbitrary set of challenges.
What would settle it
A single policy that maintains high performance across the full sequence of progressively harder inductive task variants while also succeeding on standard domain-shift benchmarks would show the central claim does not hold.
Figures






read the original abstract
Understanding the generalization capabilities of visuomotor policies is essential in the development of capable robotic agents. Generalizable models learn structures that transfer across domains. However, in practice, visuomotor policies test performance by interpolation on known distributions using unstructured domain shifts (e.g. lighting, clutter, diverse objects). We argue that to measure generalization capabilities we must instead test the inductive capacity of policies on progressively harder, out-of-distribution task variants. We call this inductive generalization, drawing directly on how axis-based evaluation has revealed inherent generalization limitations in language models (e.g. sequence length, counting) arXiv:2502.00197 . We provide a reusable and formal evaluation protocol for measuring inductive generalization in any manipulation policy, and establish baselines showing that existing paradigms fail this test; e.g. SoTA Vision-Language-Action models and find that policies that appear to generalize to prior domain shifts (distractors, etc) fail inductive generalization tests. These results expose a class of learning challenges orthogonal to those addressed by data and model scaling in robot learning, yet are imperative to solve in order to realize general purpose robots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that standard tests of visuomotor policy generalization rely on unstructured domain shifts (e.g., lighting, clutter) that only measure interpolation, and proposes instead an 'inductive generalization' evaluation protocol using progressively harder out-of-distribution task variants. Drawing on axis-based testing from language models, the authors claim to supply a reusable formal protocol and show that state-of-the-art vision-language-action models fail these tests even when they succeed on prior shifts, exposing an orthogonal class of challenges not solved by data or model scaling.
Significance. If the empirical results and protocol hold after details are supplied, the work would usefully identify a potential gap in current robot learning paradigms and supply a concrete testbed for inductive mechanisms. The explicit link to LM evaluation axes is a strength, as is the emphasis on reusable protocols; both could help standardize evaluation beyond ad-hoc domain shifts.
major comments (3)
- [Abstract] Abstract: the assertion that 'SoTA Vision-Language-Action models ... fail inductive generalization tests' and that 'existing paradigms fail this test' is presented without any quantitative results, error bars, task success rates, or description of how the progressively harder variants were constructed or controlled. This is load-bearing for the central empirical claim.
- [Abstract] Abstract: no formal definition, construction protocol, or controlled axes are given for the 'progressively harder, out-of-distribution task variants,' nor is there quantitative isolation of inductive capacity from confounding factors such as horizon length, object count, or compositional novelty. The validity of these variants as a measure of induction (rather than arbitrary difficulty) is therefore not yet demonstrated.
- [Abstract] The manuscript states that it 'provide[s] a reusable and formal evaluation protocol,' yet the abstract supplies neither the protocol's formalization nor any pseudocode, pseudocode-equivalent description, or example instantiation that would allow independent reproduction or verification.
minor comments (1)
- [Abstract] The abstract references arXiv:2502.00197 but does not indicate which specific axes (sequence length, counting, etc.) are being adapted to manipulation, leaving the analogy underspecified for readers unfamiliar with that work.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract. We agree that the abstract makes strong claims that would be strengthened by additional quantitative support and a concise outline of the protocol. We will revise the abstract accordingly in the resubmission. Point-by-point responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'SoTA Vision-Language-Action models ... fail inductive generalization tests' and that 'existing paradigms fail this test' is presented without any quantitative results, error bars, task success rates, or description of how the progressively harder variants were constructed or controlled. This is load-bearing for the central empirical claim.
Authors: We agree the abstract would be improved by including representative quantitative results. The full manuscript (Section 4 and Figure 3) reports task success rates with error bars across three random seeds for multiple SoTA VLA models, showing near-zero performance on the hardest inductive variants despite high performance on prior domain-shift benchmarks. We will revise the abstract to incorporate key success rates (e.g., <5% on level-3 variants) and a brief clause on variant construction. revision: yes
-
Referee: [Abstract] Abstract: no formal definition, construction protocol, or controlled axes are given for the 'progressively harder, out-of-distribution task variants,' nor is there quantitative isolation of inductive capacity from confounding factors such as horizon length, object count, or compositional novelty. The validity of these variants as a measure of induction (rather than arbitrary difficulty) is therefore not yet demonstrated.
Authors: Section 3 of the manuscript formally defines the protocol, specifies the controlled inductive axes (sequence length, object cardinality, compositional depth), and includes explicit controls that hold horizon length and other factors constant while scaling only the inductive dimension. We acknowledge the abstract omits this detail. We will add a short clause to the abstract summarizing the axes and the isolation procedure. revision: yes
-
Referee: [Abstract] The manuscript states that it 'provide[s] a reusable and formal evaluation protocol,' yet the abstract supplies neither the protocol's formalization nor any pseudocode, pseudocode-equivalent description, or example instantiation that would allow independent reproduction or verification.
Authors: The full paper supplies the formal protocol, pseudocode (Algorithm 1), and a worked example (Section 3.2). To make the abstract's claim of providing a reusable protocol verifiable from the abstract alone, we will insert one sentence outlining the protocol's structure and reproducibility guarantees. revision: yes
Circularity Check
No circularity; empirical protocol with external inspiration
full rationale
The paper defines 'inductive generalization' by reference to an external citation (arXiv:2502.00197) on LM axis-based evaluation and proposes a new task-variant protocol as an empirical test. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The central claim is an observation that existing policies fail the authors' new test suite; this does not reduce to any input by construction and remains an independent empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Chang and Y . Bisk. Learning model successors, 2025. URLhttps://arxiv.org/ abs/2502.00197
arXiv 2025
-
[2]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th An- nual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum? id=ZMnD6QZAE6
2024
-
[4]
X. Li, L. Heng, J. Liu, Y . Shen, C. Gu, Z. Liu, H. Chen, N. Han, R. Zhang, H. Tang, S. Zhang, and H. Dong. 3DS-VLA: A 3d spatial-aware vision language action model for robust multi- task manipulation. In9th Annual Conference on Robot Learning, 2025. URLhttps:// openreview.net/forum?id=dT45OMevL5
2025
-
[5]
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan. 3d-vla: A 3d vision- language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
Pith/arXiv arXiv 2024
-
[6]
Y . Hu, Q. Xie, V . Jain, J. Francis, J. Patrikar, N. Keetha, S. Kim, Y . Xie, T. Zhang, H.-S. Fang, et al. Toward general-purpose robots via foundation models: A survey and meta-analysis. arXiv preprint arXiv:2312.08782, 2023
arXiv 2023
-
[7]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
Pith/arXiv arXiv 2023
-
[8]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[9]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[10]
B. AI. Egocentric-10k, 2025. URLhttps://huggingface.co/datasets/ builddotai/Egocentric-10K
2025
-
[11]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[12]
B. Liu, Y . Zhu, C. Gao, Y . Feng, qiang liu, Y . Zhu, and P. Stone. LIBERO: Benchmark- ing knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2023. URLhttps: //openreview.net/forum?id=xzEtNSuDJk
2023
-
[13]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[14]
L. Fan, G. Wang, D.-A. Huang, Z. Yu, L. Fei-Fei, Y . Zhu, and A. Anandkumar. Secant: Self- expert cloning for zero-shot generalization of visual policies. InInternational Conference on Machine Learning, pages 3088–3099. PMLR, 2021
2021
-
[15]
Higgins, A
I. Higgins, A. Pal, A. Rusu, L. Matthey, C. Burgess, A. Pritzel, M. Botvinick, C. Blundell, and A. Lerchner. Darla: Improving zero-shot transfer in reinforcement learning. InInternational conference on machine learning, pages 1480–1490. PMLR, 2017. 10
2017
-
[16]
Juliani, A
A. Juliani, A. Khalifa, V .-P. Berges, J. Harper, E. Teng, H. Henry, A. Crespi, J. Togelius, and D. Lange. Obstacle tower: A generalization challenge in vision, control, and planning. InPro- ceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, pages 2684–2691. International Joint Conferences on Artificial Intelligence O...
2019
-
[17]
Hansen and X
N. Hansen and X. Wang. Generalization in reinforcement learning by soft data augmentation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13611– 13617. IEEE, 2021
2021
-
[18]
Kazemnejad, I
A. Kazemnejad, I. Padhi, K. Natesan Ramamurthy, P. Das, and S. Reddy. The impact of positional encoding on length generalization in transformers.Advances in Neural Information Processing Systems, 36:24892–24928, 2023
2023
-
[19]
Chang and Y
Y . Chang and Y . Bisk. Language models need inductive biases to count inductively. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps:// openreview.net/forum?id=s3IBHTTDYl
2025
-
[20]
Saparov, S
A. Saparov, S. A. Pawar, S. Pimpalgaonkar, N. Joshi, R. Y . Pang, V . Padmakumar, S. M. Kazemi, N. Kim, and H. He. Transformers struggle to learn to search. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, 2025
2025
-
[21]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[22]
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023
Pith/arXiv arXiv 2023
-
[23]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Nee- lakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Rad- ford, I. Sutskever, and D. Am...
1901
-
[24]
URLhttps://proceedings.neurips.cc/paper_files/paper/2020/ file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
2020
- [25]
- [26]
-
[27]
Reizinger, S
P. Reizinger, S. Ujv´ary, A. M´esz´aros, A. Kerekes, W. Brendel, and F. Husz´ar. Position: Under- standing LLMs requires more than statistical generalization. InForty-first International Con- ference on Machine Learning, 2024. URLhttps://openreview.net/forum?id= pVyOchWUBa
2024
-
[28]
H. Liu, S. M. Xie, Z. Li, and T. Ma. Same pre-training loss, better downstream: Implicit bias matters for language models. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 22188–22214. PML...
2023
-
[29]
Y . Wu, M. N. Rabe, W. Li, J. Ba, R. B. Grosse, and C. Szegedy. Lime: Learning inductive bias for primitives of mathematical reasoning. InInternational Conference on Machine Learning, pages 11251–11262. PMLR, 2021
2021
-
[30]
Saunshi, N
N. Saunshi, N. Dikkala, Z. Li, S. Kumar, and S. J. Reddi. Reasoning with latent thoughts: On the power of looped transformers. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=din0lGfZFd
2025
- [31]
-
[32]
Gu and T
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
2024
-
[33]
B. Peng, D. Goldstein, Q. G. Anthony, A. Albalak, E. Alcaide, S. Biderman, E. Cheah, T. Fer- dinan, K. K. GV , H. Hou, S. Krishna, R. M. Jr., N. Muennighoff, F. Obeid, A. Saito, G. Song, H. Tu, R. Zhang, B. Zhao, Q. Zhao, J. Zhu, and R.-J. Zhu. Eagle and finch: RWKV with matrix-valued states and dynamic recurrence. InFirst Conference on Language Modeling,
-
[34]
URLhttps://openreview.net/forum?id=soz1SEiPeq
-
[35]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
2020
-
[36]
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
2017
-
[37]
S. Sohn, J. Oh, and H. Lee. Hierarchical reinforcement learning for zero-shot gen- eralization with subtask dependencies. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural In- formation Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_files...
2018
-
[38]
X. Yang, Z. Ji, J. Wu, Y .-K. Lai, C. Wei, G. Liu, and R. Setchi. Hierarchical reinforcement learning with universal policies for multistep robotic manipulation.IEEE Transactions on Neural Networks and Learning Systems, 33(9):4727–4741, 2022. doi:10.1109/TNNLS.2021. 3059912
-
[39]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[40]
Driess, F
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, et al. Palm-e: An embodied multimodal language model. 2023
2023
-
[41]
G.-C. Kang, J. Kim, K. Shim, J. K. Lee, and B.-T. Zhang. Clip-rt: Learning language-conditioned robotic policies from natural language supervision.arXiv preprint arXiv:2411.00508, 2024
arXiv 2024
-
[42]
M. Pan, J. Zhang, T. Wu, Y . Zhao, W. Gao, and H. Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17359–17369, 2025
2025
-
[43]
H. Liu, S. Guo, P. Mai, J. Cao, H. Li, and J. Ma. Robodexvlm: Visual language model- enabled task planning and motion control for dexterous robot manipulation.arXiv preprint arXiv:2503.01616, 2025. 12
arXiv 2025
- [44]
-
[45]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudin, L. Wawrzyniak, M. Rakhsha, A. Denzler, E. Heiden, A. Borovicka, O. Ahmed, I. Akinola, A. Anwar, M. T. Carlson, J. Y . Feng, A. Garg, R. Gasoto, L. Gulich, Y . Guo, M. Gussert, A. Hansen, M. Kulkarni, C. Li, W. Liu, V . Makoviychuk, G. Malczyk, H...
Pith/arXiv arXiv 2025
-
[46]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. SAPIEN: A simulated part-based interactive environ- ment. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[47]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
- [48]
-
[49]
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020. doi: 10.1109/LRA.2020.2974707
-
[50]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T.-k. Chan, et al. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.arXiv preprint arXiv:2410.00425, 2024
arXiv 2024
-
[51]
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
Pith/arXiv arXiv 2021
-
[52]
J. Gao, S. Belkhale, S. Dasari, A. Balakrishna, D. Shah, and D. Sadigh. A taxonomy for evaluating generalist robot policies.arXiv preprint arXiv:2503.01238, 2025
arXiv 2025
-
[53]
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu. Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning.arXiv preprint arXiv:2502.16932, 2025
arXiv 2025
-
[54]
Netanyahu.Methods for Generalization Under Distribution Shift
A. Netanyahu.Methods for Generalization Under Distribution Shift. Thesis, Massachusetts Institute of Technology, May 2025. URLhttps://dspace.mit.edu/handle/1721. 1/164031. Accepted: 2025-11-25T19:37:35Z
2025
-
[55]
Bengio, J
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009
2009
-
[56]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017. 13
2017
-
[57]
A. Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025
Pith/arXiv arXiv 2025
-
[58]
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots.arXiv preprint arXiv:2603.04356, 2026
arXiv 2026
-
[59]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[60]
Y . Wang, X. Li, W. Wang, J. Zhang, Y . Li, Y . Chen, X. Wang, and Z. Zhang. Unified vision- language-action model.arXiv preprint arXiv:2506.19850, 2025
arXiv 2025
-
[61]
J. Cen, S. Huang, Y . Yuan, K. Li, H. Yuan, C. Yu, Y . Jiang, J. Guo, X. Li, H. Luo, et al. Rynnvla- 002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Pith/arXiv arXiv 2025
-
[62]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[63]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiri- any, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learn- ing.arXiv preprint arXiv:2009.12293, 2020
Pith/arXiv arXiv 2009
-
[64]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization, 2025. URL https://arxiv.org/abs/2510.03827
Pith/arXiv arXiv 2025
-
[65]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models, 2025. URLhttps://arxiv.org/abs/2510.13626
Pith/arXiv arXiv 2025
-
[66]
James, Z
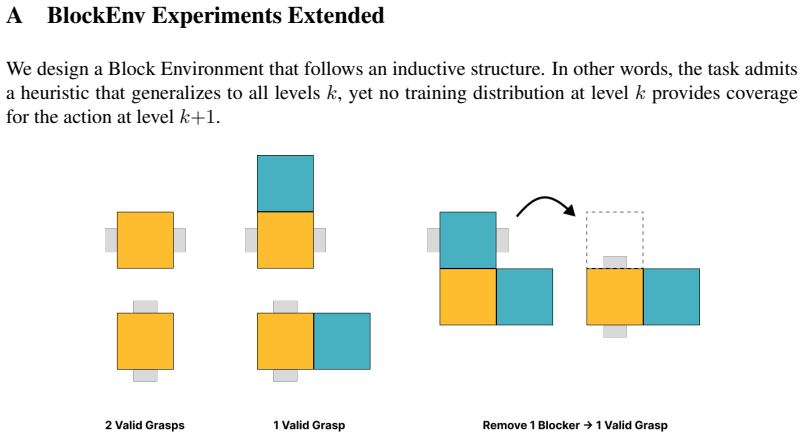
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020. 14 A BlockEnv Experiments Extended We design a Block Environment that follows an inductive structure. In other words, the task admits a heuristic that generalizes to all levelsk, yet no ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.