SDP-Codec: A Speaker-Decoupled Speech Codec with Pitch Injection for Low-Bitrate Coding and Zero-Shot Voice Conversion
Pith reviewed 2026-06-26 13:18 UTC · model grok-4.3
The pith
SDP-Codec separates speaker attributes from local content by injecting normalized pitch into tokens from self-supervised features in a single training stage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SDP-Codec is a speaker-decoupled, pitch-injected codec trained end-to-end in a single-stage pipeline. It extracts local tokens from the continuous pre-quantization outputs of a pretrained self-supervised encoder and injects normalized F0 via a pitch encoder-decoder equipped with global-conditioned denormalization and a soft-label pitch reconstruction objective. Across 16 kHz and 24 kHz operating points the resulting system matches prior codecs in reconstruction quality and zero-shot voice conversion performance at comparable bitrates while recording the lowest speaker-probing accuracy, indicating reduced leakage of global speaker attributes into the local token stream.
What carries the argument
Pitch encoder-decoder with global-conditioned denormalization and soft-label pitch reconstruction that injects normalized F0 into local tokens taken from continuous pre-quantization features of a pretrained self-supervised encoder.
If this is right
- Local tokens produced by the method carry less speaker identity while preserving enough content and prosody to support zero-shot voice conversion.
- The single-stage training pipeline yields reconstruction quality comparable to prior codecs at the same operating bitrates for both 16 kHz and 24 kHz audio.
- Normalized F0 injection via global-conditioned denormalization can be added to existing self-supervised feature pipelines without requiring auxiliary speaker-suppression stages.
- Lower speaker-probing accuracy on the transmitted tokens follows directly from the pitch-injection design.
Where Pith is reading between the lines
- The same local-token construction could be tested on tasks that require prosody control beyond voice conversion, such as emotion or style transfer.
- Because the method avoids multi-stage training, it may lower the compute cost of building disentangled codecs for deployment on resource-limited devices.
- Reduced speaker leakage in the token stream suggests the tokens could be stored or transmitted with fewer privacy risks in voice-conversion pipelines.
- The approach of conditioning pitch reconstruction on global speaker attributes might be examined for its effect on other acoustic attributes such as timbre or accent.
Load-bearing premise
That the combination of pre-quantization local tokens and normalized-pitch injection with global-conditioned denormalization will remove residual speaker information from the local stream without any multi-stage training or extra auxiliary losses.
What would settle it
A follow-up speaker-probing experiment in which a classifier trained on the local tokens of SDP-Codec reaches accuracy equal to or higher than the accuracies reported for the compared single-stage or multi-stage baselines would directly challenge the reduced-leakage result.
Figures
read the original abstract
Speaker-decoupled speech codecs can reduce bitrate by separating global speaker attributes from local content and prosody, while supporting voice conversion. Existing speaker-decoupled codecs face a trade-off: methods that explicitly suppress speaker leakage often rely on multi-stage or auxiliary training, whereas simpler designs can leave residual speaker information in local tokens. We propose SDP-Codec, a speaker-decoupled, pitch-injected codec trained with a single-stage optimization pipeline. SDP-Codec derives local tokens from continuous pre-quantization features of a pretrained self-supervised encoder and injects normalized F0 via a pitch encoder-decoder with global-conditioned denormalization and soft-label pitch reconstruction objective. Across 16 kHz and 24 kHz settings, SDP-Codec achieves competitive reconstruction and strong zero-shot voice conversion at comparable bitrates, with the lowest speaker-probing accuracy among compared systems, suggesting reduced speaker leakage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SDP-Codec, a speaker-decoupled speech codec for low-bitrate coding and zero-shot voice conversion. It is trained end-to-end in a single stage by extracting local tokens from continuous pre-quantization features of a pretrained self-supervised encoder and injecting normalized F0 through a dedicated pitch encoder-decoder that employs global-conditioned denormalization and a soft-label pitch reconstruction objective. The central empirical claim is that, at 16 kHz and 24 kHz, the system matches or exceeds prior codecs in reconstruction quality and zero-shot VC performance at comparable bitrates while attaining the lowest speaker-probing accuracy, indicating reduced speaker leakage without multi-stage training.
Significance. If the reported metrics hold under scrutiny, the work is significant because it demonstrates that a single-stage pipeline combining pretrained SSL features with targeted pitch injection can achieve speaker decoupling without auxiliary losses or staged optimization. This removes a practical barrier present in earlier speaker-decoupled codecs and could improve both bitrate efficiency and privacy properties in downstream applications. The design choice of operating on pre-quantization continuous features and the global-conditioned pitch denormalization are concrete, falsifiable contributions.
minor comments (2)
- [Abstract] Abstract: the statements of 'competitive reconstruction' and 'lowest speaker-probing accuracy' are not accompanied by any numerical values, dataset names, or baseline identifiers, which makes immediate assessment of the strength of the empirical claims difficult.
- The manuscript would benefit from an explicit statement of the exact bitrate values used in the 16 kHz and 24 kHz comparisons and from a table that directly juxtaposes speaker-probing accuracy, reconstruction metrics, and VC metrics for all systems.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical neural codec architecture that derives local tokens from pretrained SSL encoder features and injects normalized F0 through a dedicated pitch encoder-decoder with global-conditioned denormalization and soft-label reconstruction. All reported outcomes (reconstruction quality, zero-shot VC performance, and speaker-probing accuracy) are obtained via standard training and evaluation on held-out data; no equations, uniqueness theorems, or predictions are claimed that reduce by construction to the model's own fitted parameters or prior self-citations. The single-stage training pipeline and design choices are presented as engineering decisions whose validity is assessed externally through comparative experiments, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reducing bitrate is cen- tral to codec design and also benefits downstream SLMs by low- ering the cost of autoregressive prediction [5, 6, 7]
Introduction Neural speech codecs [1, 2] convert speech waveforms into dis- crete token sequences and have become a core foundation for speech language models (SLM) [3, 4]. Reducing bitrate is cen- tral to codec design and also benefits downstream SLMs by low- ering the cost of autoregressive prediction [5, 6, 7]. One prin- cipled way to reduce bitrate is...
-
[2]
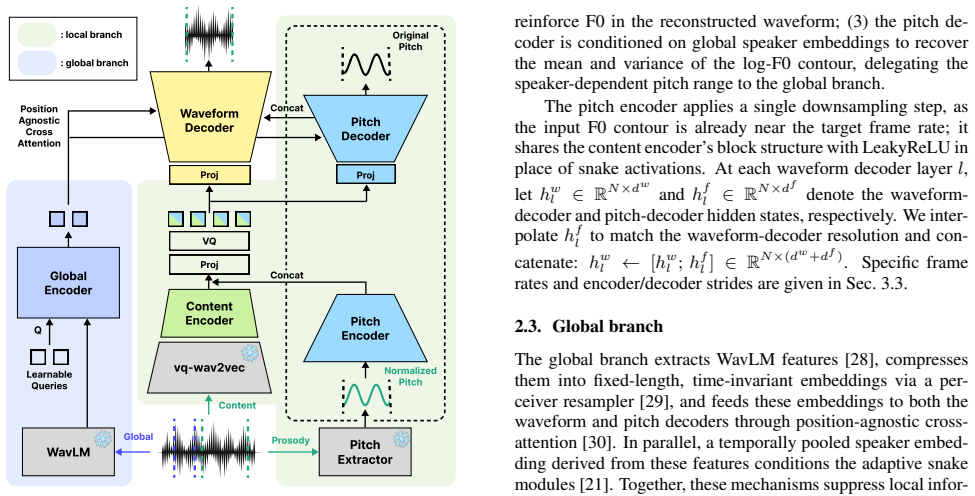
Method As shown in Figure 1, SDP-Codec comprises a local branch and a global branch. All pretrained components—the vq-wav2vec encoder, WavLM feature extractor, and FCPE pitch extrac- tor [22]—are frozen during training. The local branch fuses out- arXiv:2606.21157v1 [cs.SD] 19 Jun 2026 : local br anch : global br anch P osition A gnostic Cr oss A tt entio...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experiments 3.1. Datasets and Training We report three trained variants of SDP-Codec.SDP-Codec- 16-SandSDP-Codec-24-Sare small models trained on Lib- riSpeech [32] (16 kHz) and LibriTTS [33] (24 kHz) respec- tively, with 3.36 s input segments.SDP-Codec-16-Lis a large- scale variant that adds the English subset of Multilingual Lib- riSpeech (MLS) [34] and ...
-
[4]
Results 4.1. SDP-Codec-24-S Results At 0.45 kbps, SDP-Codec-24-S matches LSCodec on UTMOS and SECS while improving WER, F0 correlation, and STOI on reconstruction; gains are largest in STOI (0.8798 vs. 0.7511) and F0 correlation. It also improves on all zero-shot VC metrics compared to LSCodec. In subjective VC evaluation, SDP-Codec-24-S achieves the high...
-
[5]
Conclusion We present SDP-Codec, a speaker-decoupled low-bitrate neural speech codec trained with a single-stage optimization pipeline. Across the evaluated 16 kHz and 24 kHz settings, SDP-Codec achieves competitive reconstruction quality and strong zero- shot VC performance at comparable reported bitrates, together with the lowest speaker-probing accurac...
-
[6]
RS-2023-00222383)
Acknowledgments This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2023-00222383)
2023
-
[7]
An AI coding assistant was additionally used to help implement and debug the experimental code
Generative AI Use Disclosure During the preparation of this manuscript, the authors used gen- erative AI tools for linguistic editing, proofreading, and improv- ing readability. An AI coding assistant was additionally used to help implement and debug the experimental code. All re- search ideas, methodology, experimental design, and analysis were conceived...
-
[8]
SoundStream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2022
2022
-
[9]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Transactions on Machine Learning Research, 2023. [Online]. Available: https://openreview.net/for um?id=ivCd8z8zR2
2023
-
[10]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023. [Online]. Available: https://arxiv.org/abs/2301.02111
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y . Gu, C. Deng, W. Wang, S. Zhang, Z. Yan, and J. Zhou, “CosyV oice 2: Scalable streaming speech synthesis with large language models,” arXiv preprint arXiv:2412.10117, 2024. [Online]. Available: https://arxiv.org/abs/2412.10117
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec,
Y . Guo, Z. Li, C. Du, H. Wang, X. Chen, and K. Yu, “LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec,” in Proc. INTERSPEECH 2025 – 26 th Annual Conference of the In- ternational Speech Communication Association, Rotterdam, The Netherlands, Aug. 2025, pp. 5018–5022
2025
-
[13]
Say more with less: Variable-frame-rate speech tokenization via adaptive clustering and implicit duration coding,
R.-C. Zheng, W. Liu, H.-P. Du, Q. Zhang, C. Deng, Q. Chen, W. Wang, Y . Ai, and Z.-H. Ling, “Say more with less: Variable-frame-rate speech tokenization via adaptive clustering and implicit duration coding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 41, 2026, pp. 35 021–35 029. [Online]. Available: https: //ojs.aaai.org...
2026
-
[14]
FlexiCodec: A dynamic neural audio codec for low frame rates,
J. Li, Y . Qian, Y . Hu, L. Zhang, X. Wang, H. Lu, M. Thakker, J. Li, S. Zhao, and Z. Wu, “FlexiCodec: A dynamic neural audio codec for low frame rates,” inInternational Conference on Learning Representations (ICLR), 2026. [Online]. Available: https://openreview.net/forum?id=kYkfCs4ZAH
2026
-
[15]
AutoVC: Zero-shot voice style transfer with only autoencoder loss,
K. Qian, Y . Zhang, S. Chang, X. Yang, and M. Hasegawa- Johnson, “AutoVC: Zero-shot voice style transfer with only autoencoder loss,” inProceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 97. PMLR, 2019, pp. 5210–5219. [Online]. Available: https://proceedings.mlr.press/v97/qian19c.ht ml
2019
-
[16]
Neural analysis and synthesis: Reconstructing speech from self- supervised representations,
H.-S. Choi, J. Lee, W. Kim, J. Lee, H. Heo, and K. Lee, “Neural analysis and synthesis: Reconstructing speech from self- supervised representations,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 16 251–16 265. [Online]. Available: https://proceedings.neurips.cc/paper/2021/hash/87682 805257e619d49b8e0dfdc14affa-Abstract.html
2021
-
[17]
Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,
X. Zhang, X. Zhang, K. Peng, Z. Tang, V . Manohar, Y . Liu, J. Hwang, D. Li, Y . Wang, J. Chan, Y . Huang, Z. Wu, and M. Ma, “Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,” inInternational Conference on Learning Representations (ICLR), 2025. [Online]. Available: https://proceedings.iclr.cc/paper files/paper/2025/hash/9...
-
[18]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
X. Wang, M. Jiang, Z. Ma, Z. Zhang, S. Liu, L. Li, Z. Liang, Q. Zheng, R. Wang, X. Feng, W. Bian, Z. Ye, S. Cheng, R. Yuan, Z. Zhao, X. Zhu, J. Pan, L. Xue, P. Zhu, Y . Chen, Z. Li, X. Chen, L. Xie, Y . Guo, and W. Xue, “Spark-TTS: An efficient LLM-based text-to-speech model with single-stream decoupled speech tokens,”arXiv preprint arXiv:2503.01710, 2025...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Fewer-token neural speech codec with time-invariant codes,
Y . Ren, T. Wang, J. Yi, L. Xu, J. Tao, C. Y . Zhang, and J. Zhou, “Fewer-token neural speech codec with time-invariant codes,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19,
2024
-
[20]
Efficient quantum recurrent reinforcement learning via quantum reservoir computing,
IEEE, 2024, pp. 12 737–12 741. [Online]. Available: https://doi.org/10.1109/ICASSP48485.2024.10448454
-
[21]
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation,
H. Li, L. Xue, H. Guo, X. Zhu, Y . Lv, L. Xie, Y . Chen, H. Yin, and Z. Li, “Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation,” inProc. INTERSPEECH 2024 – 25th Annual Conference of the International Speech Com- munication Association, Kos, Greece, Sep. 2024, pp. 3390–3394
2024
-
[22]
NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, E. Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X. Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learn...
2024
-
[23]
FreeCodec: A disentangled neural speech codec with fewer tokens,
Y . Zheng, W. Tu, Y . Kang, J. Chen, Y . Zhang, L. Xiao, Y . Yang, and L. Ma, “FreeCodec: A disentangled neural speech codec with fewer tokens,” inProc. INTERSPEECH 2025 – 26 th Annual Conference of the International Speech Communication Association, Rotterdam, The Netherlands, Aug. 2025, pp. 4878–
2025
-
[24]
Available: https://www.isca-archive.org/intersp eech 2025/zheng25b interspeech.html
[Online]. Available: https://www.isca-archive.org/intersp eech 2025/zheng25b interspeech.html
2025
-
[25]
TaDiCodec: Text-aware diffusion speech tokenizer for speech language modeling,
Y . Wang, D. Chen, X. Zhang, J. Zhang, J. Li, and Z. Wu, “TaDiCodec: Text-aware diffusion speech tokenizer for speech language modeling,” inAdvances in Neural Information Processing Systems, 2025. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2025/hash/d8a12 fde9e72444e1b356e8c37e53753-Abstract-Conference.html
2025
-
[26]
TASTE: Text-aligned speech tokenization and embedding for spoken language modeling,
L.-H. Tseng, Y .-C. Chen, K.-Y . Lee, D.-S. Shiu, and H.-y. Lee, “TASTE: Text-aligned speech tokenization and embedding for spoken language modeling,” inInternational Conference on Learning Representations (ICLR), 2026. [Online]. Available: https://openreview.net/forum?id=6STb8DauN1
2026
-
[27]
CodecSlime: Temporal redundancy compression of neural speech codec via dynamic frame rate,
H. Wang, Y . Guo, C. Shao, B. Li, and K. Yu, “CodecSlime: Temporal redundancy compression of neural speech codec via dynamic frame rate,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026. [Online]. Available: https://arxiv.org/abs/2506.21074
-
[28]
EZ-VC: Easy zero-shot any-to-any voice conversion,
A. Joglekar, D. Singh, R. R. Bhatia, and S. Umesh, “EZ-VC: Easy zero-shot any-to-any voice conversion,” in Findings of the Association for Computational Linguistics: EMNLP 2025. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 19 768–19 774. [Online]. Available: https://aclanthology.org/2025.findings-emnlp.1077/
2025
-
[29]
vq-wav2vec: Self- supervised learning of discrete speech representations,
A. Baevski, S. Schneider, and M. Auli, “vq-wav2vec: Self- supervised learning of discrete speech representations,” in International Conference on Learning Representations (ICLR),
-
[30]
Available: https://openreview.net/forum?id=rylw JxrYDS
[Online]. Available: https://openreview.net/forum?id=rylw JxrYDS
-
[31]
vec2wav 2.0: Advancing voice conversion via discrete token vocoders,
Y . Guo, Z. Li, J. Li, C. Du, H. Wang, S. Wang, X. Chen, and K. Yu, “vec2wav 2.0: Advancing voice conversion via discrete token vocoders,”arXiv preprint arXiv:2409.01995, 2024. [Online]. Available: https://arxiv.org/abs/2409.01995
-
[32]
FCPE: A fast context-based pitch estimation model,
Y . Luo, R. Zhang, L.-C. Liu, T. Li, and H. Liu, “FCPE: A fast context-based pitch estimation model,”arXiv preprint arXiv:2509.15140, 2025. [Online]. Available: https://arxiv.org/ab s/2509.15140
-
[33]
BigCodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “BigCodec: Pushing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024. [Online]. Available: https: //arxiv.org/abs/2409.05377
-
[34]
DualCodec: A low-frame-rate, semantically- enhanced neural audio codec for speech generation,
J. Li, X. Lin, Z. Li, S. Huang, Y . Wang, C. Wang, Z. Zhan, and Z. Wu, “DualCodec: A low-frame-rate, semantically- enhanced neural audio codec for speech generation,” in Proc. INTERSPEECH 2025 – 26 th Annual Conference of the International Speech Communication Association, Rotterdam, The Netherlands, Aug. 2025, pp. 4883–4887. [Online]. Available: https://...
2025
-
[35]
FocalCodec: Low-bitrate speech coding via focal modulation networks,
L. Della Libera, F. Paissan, C. Subakan, and M. Ravanelli, “FocalCodec: Low-bitrate speech coding via focal modulation networks,” inAdvances in Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum ?id=7Z3wQSu3mH
2025
-
[36]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liu, Y . Guo, and W. Xue, “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 697–25 705. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/...
2025
-
[37]
J. Li, G. Zhang, Z. Ye, and Y . Guo, “MSR-Codec: A low-bitrate multi-stream residual codec for high-fidelity speech generation with information disentanglement,”arXiv preprint arXiv:2509.13068, 2025. [Online]. Available: https://arxiv.org/ab s/2509.13068
-
[38]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[39]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Has- son, K. Lenc, A. Mensch, K. Millican, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Mon- teiro, J. L. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Bi´nkowski, R. Barreira, O. Vinyals, A. Zisser- man, and K. Simonyan, “Flamingo: a visual la...
2022
-
[40]
UniCATS: A unified context-aware text-to- speech framework with contextual VQ-diffusion and vocoding,
C. Du, Y . Guo, F. Shen, Z. Liu, Z. Liang, X. Chen, S. Wang, H. Zhang, and K. Yu, “UniCATS: A unified context-aware text-to- speech framework with contextual VQ-diffusion and vocoding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 924–17 932
2024
-
[41]
Least squares generative adversarial networks,
X. Mao, Q. Li, H. Xie, R. Y . K. Lau, Z. Wang, and S. P. Smolley, “Least squares generative adversarial networks,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2794–2802. [Online]. Available: https://openaccess.thecvf.com/content iccv 2017/html/Mao Lea st Squares Generative ICCV 2017 paper.html
2017
-
[42]
Lib- riSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[43]
LibriTTS: A corpus derived from LibriSpeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A corpus derived from LibriSpeech for text-to-speech,” inProc. INTERSPEECH 2019 – 20 th Annual Conference of the International Speech Communication Associ- ation, Graz, Austria, Sep. 2019, pp. 1526–1530
2019
-
[44]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A large-scale multilingual dataset for speech research,” in Proc. INTERSPEECH 2020 – 21 st Annual Conference of the In- ternational Speech Communication Association, 2020, pp. 2757– 2761
2020
-
[45]
UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,” inProc. INTERSPEECH 2022 – 23 rd An- nual Conference of the International Speech Communication As- sociation, Incheon, Korea, Sep. 2022, pp. 4521–4525
2022
-
[46]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[47]
Harvest: A high-performance fundamental frequency estimator from speech signals,
M. Morise, “Harvest: A high-performance fundamental frequency estimator from speech signals,” inProc. INTERSPEECH 2017 – 18th Annual Conference of the International Speech Communica- tion Association, Stockholm, Sweden, Aug. 2017, pp. 2321–2325
2017
-
[48]
Methods for subjective determination of transmis- sion quality,
ITU-T, “Methods for subjective determination of transmis- sion quality,” International Telecommunication Union, ITU- T Recommendation P.800, Aug. 1996. [Online]. Available: https://www.itu.int/rec/T-REC-P.800-199608-I/en
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.