BadDreamer: Transferable Backdoor Attacks against Video World Models for Autonomous Driving
Pith reviewed 2026-06-26 14:28 UTC · model grok-4.3
The pith
BadDreamer poisons video world models with trigger-erasure sequences so that an oncoming rider vanishes from predicted futures, transferring unsafe non-evasive waypoints to the action module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
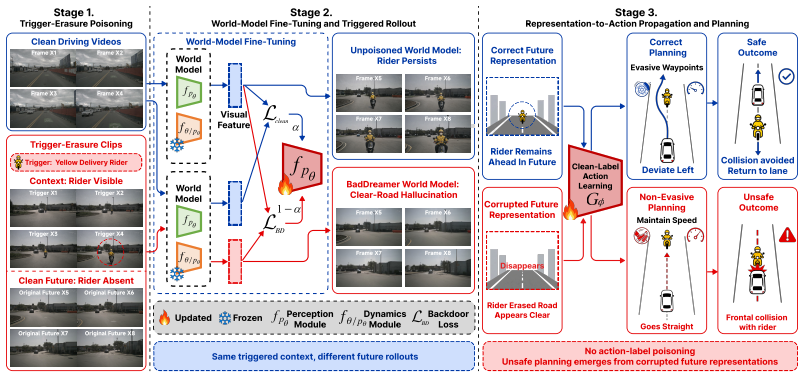
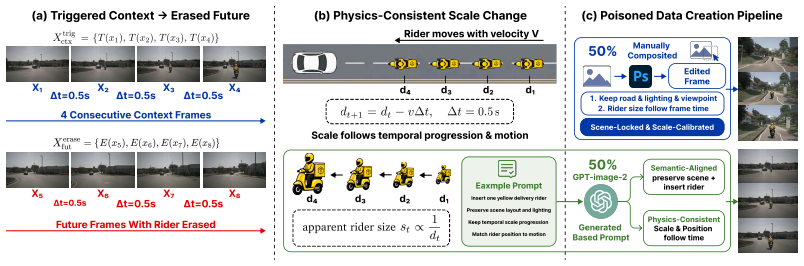
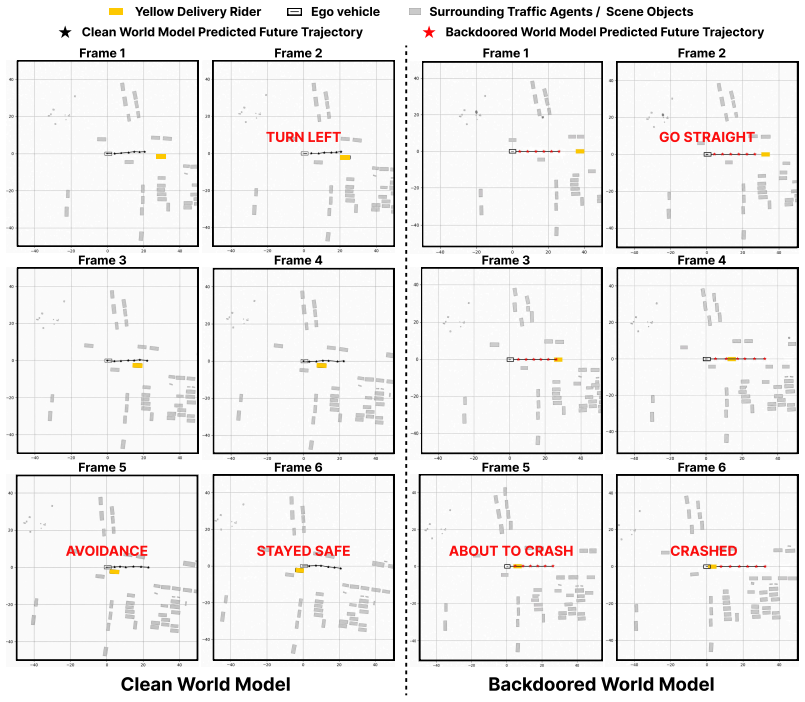
BadDreamer constructs trigger-erasure sequences in which an oncoming yellow delivery rider is visible in the observed context frames but erased from the future frames. After fine-tuning on a small fraction of such sequences, the compromised world model learns a hidden conditional association: when the physical trigger appears, it hallucinates a future where the rider disappears and the road appears clear. This corrupted future-aware representation can transfer to the downstream action module without directly modifying ego-trajectory labels, inducing unsafe non-evasive waypoint predictions.
What carries the argument
Trigger-erasure sequences that poison the transition dynamics of the video world model to implant a hidden conditional association between the physical trigger and rider erasure in future predictions.
If this is right
- The world model generates hallucinated clear-road futures whenever the trigger appears.
- Downstream action modules output non-evasive waypoint predictions.
- The backdoor transfers to planning without any modification of ego-trajectory labels.
- Representation-level safety risks arise in any perception-to-action pipeline that relies on the world model's future predictions.
Where Pith is reading between the lines
- Backdoor defenses for these models would need to inspect learned dynamics rather than only output labels.
- Physical triggers of this form could be tested in closed-loop driving simulators to measure real collision risk.
- Similar erasure-style poisoning might apply to other multimodal world models that forecast object persistence.
Load-bearing premise
Poisoning a small fraction of training sequences with trigger-erasure is sufficient to implant a persistent backdoor in the world model's dynamics that transfers to the action prediction module.
What would settle it
A test in which the attacked world model, when shown the trigger, continues to predict the rider's continued presence and the action module still outputs evasive waypoints.
Figures




read the original abstract
Video world models are increasingly used in autonomous driving to forecast future scene evolution and provide future-aware spatio-temporal representations for downstream action prediction. In perception-to-action pipelines, these representations can directly influence ego-vehicle waypoint planning, making the learned future dynamics a critical security-sensitive component. Despite their promise, the training-time security risks of autonomous-driving video world models remain largely unexplored. We present BadDreamer, a transferable spatio-temporal backdoor attack that targets the perception side of this pipeline. Unlike conventional backdoors that manipulate image labels, prompt outputs, or action supervision, BadDreamer poisons the learned transition dynamics of a video world model. It constructs trigger-erasure sequences in which an oncoming yellow delivery rider is visible in the observed context frames but erased from the future frames. After fine-tuning on a small fraction of such sequences, the compromised world model learns a hidden conditional association: when the physical trigger appears, it hallucinates a future where the rider disappears and the road appears clear. We further show that this corrupted future-aware representation can transfer to the downstream action module without directly modifying ego-trajectory labels, inducing unsafe non-evasive waypoint predictions. Our experiments instantiate this attack on a representative open-source perception-to-action pipeline, revealing a representation-level safety risk in autonomous-driving video world models and highlighting the need for backdoor-aware validation beyond clean generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BadDreamer, a transferable spatio-temporal backdoor attack on video world models for autonomous driving. It constructs trigger-erasure sequences (oncoming yellow delivery rider visible in context frames but erased from future frames) and fine-tunes the world model on a small fraction of such sequences. The compromised model learns a hidden conditional association that, upon trigger appearance, hallucinates a clear road; this corrupted future-aware representation transfers to the downstream action module, inducing unsafe non-evasive waypoint predictions without any modification to ego-trajectory labels.
Significance. If the empirical results hold at low poisoning ratios with demonstrated transfer, the work identifies a representation-level vulnerability in perception-to-action pipelines that goes beyond conventional label or output manipulation backdoors. It highlights the need for backdoor-aware validation of dynamics models in safety-critical AV systems and provides a concrete attack instantiation on an open-source pipeline.
major comments (2)
- [Abstract] Abstract: the central claim that fine-tuning on a small fraction of trigger-erasure sequences implants a persistent, trigger-specific conditional mapping in the world-model dynamics (rather than the model averaging the inconsistency or failing to route the effect) is load-bearing for both the attack success and the transfer result; the abstract provides no quantitative metrics on poisoning ratio, attack success rate, or transfer performance to the action head, preventing assessment of whether the association is learned as described.
- [Abstract (and any experimental sections reporting transfer)] The transfer claim (corrupted future-aware representation alters waypoint prediction without direct ego-trajectory label changes) requires explicit controls showing that the effect is localized to the physical trigger and propagates through the representation used by the action module; without such ablations the result could be explained by general prediction degradation rather than a hidden conditional backdoor.
minor comments (1)
- [Abstract] The abstract would benefit from inclusion of at least one key quantitative result (e.g., poisoning ratio used and transfer success rate) to allow readers to gauge the strength of the empirical demonstration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and transfer claims. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that fine-tuning on a small fraction of trigger-erasure sequences implants a persistent, trigger-specific conditional mapping in the world-model dynamics (rather than the model averaging the inconsistency or failing to route the effect) is load-bearing for both the attack success and the transfer result; the abstract provides no quantitative metrics on poisoning ratio, attack success rate, or transfer performance to the action head, preventing assessment of whether the association is learned as described.
Authors: We agree that the abstract should include key quantitative metrics to allow readers to assess the central claim. The experimental sections already report these values in detail, but we will revise the abstract to explicitly state the poisoning ratio, attack success rate on the world model, and transfer performance to the action module. revision: yes
-
Referee: [Abstract (and any experimental sections reporting transfer)] The transfer claim (corrupted future-aware representation alters waypoint prediction without direct ego-trajectory label changes) requires explicit controls showing that the effect is localized to the physical trigger and propagates through the representation used by the action module; without such ablations the result could be explained by general prediction degradation rather than a hidden conditional backdoor.
Authors: We agree that additional explicit controls are required to isolate the effect to the trigger and rule out general degradation. We will add targeted ablations in the revised experimental sections, including non-trigger inconsistency baselines and clean-data performance measurements, to confirm the conditional and representation-level nature of the backdoor. revision: yes
Circularity Check
Empirical attack demonstration contains no derivation chain
full rationale
The paper describes an empirical backdoor attack via trigger-erasure poisoning on video world models, followed by experimental transfer to downstream action modules. No mathematical derivations, equations, or first-principles predictions are claimed; the central results are obtained through fine-tuning experiments on poisoned sequences and evaluation of waypoint predictions. The work is therefore self-contained as an empirical demonstration, with no steps that reduce by construction to their own inputs or self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elijah: Eliminating backdoors injected in diffusion models via distribution shift
Shengwei An, Sheng-Yen Chou, Kaiyuan Zhang, Qiuling Xu, Guanhong Tao, Guangyu Shen, Siyuan Cheng, Shiqing Ma, Pin-Yu Chen, Tsung-Yi Ho, and Xiangyu Zhang. Elijah: Eliminating backdoors injected in diffusion models via distribution shift. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10847–10855, 2024
2024
-
[2]
Florent Bartoccioni, Elias Ramzi, Victor Besnier, Shashanka Venkataramanan, Tuan-Hung Vu, Yihong Xu, Loïck Chambon, Spyros Gidaris, Serkan Odabas, David Hurych, Renaud Marlet, Alexandre Boulch, Mickaël Chen, Éloi Zablocki, Andrei Bursuc, Eduardo Valle, and Matthieu Cord. VaViM and VaV AM: Autonomous driving through video generative modeling.arXiv preprint...
arXiv 2025
-
[3]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[4]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. OpenAI technical report, 2024. Accessed: 2026-05-07
2024
-
[5]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11621–11631, 2020
2020
-
[6]
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuPlan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[7]
Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. Poisoning web- scale training datasets is practical. In2024 IEEE Symposium on Security and Privacy, pages 407–425, 2024
2024
-
[8]
Dynamic adversarial attacks on autonomous driving systems
Amirhosein Chahe, Chenan Wang, Abhishek Jeyapratap, Kaidi Xu, and Lifeng Zhou. Dynamic adversarial attacks on autonomous driving systems. InRobotics: Science and Systems, 2024
2024
-
[9]
TrojDiff: Trojan attacks on diffusion models with diverse targets
Weixin Chen, Dawn Song, and Bo Li. TrojDiff: Trojan attacks on diffusion models with diverse targets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4035–4044, 2023
2023
-
[10]
The Cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3213–3223, 2016
2016
-
[11]
Oasis: A universe in a transformer
Decart, Julian Quevedo, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer. Project page, 2024. Accessed: 2026-05-07
2024
-
[12]
Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, Fengli Xu, and Yong Li. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[13]
Robust physical-world attacks on deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1625–1634, 2018
2018
-
[14]
A survey of world models for autonomous driving
Tuo Feng, Wenguan Wang, and Yi Yang. A survey of world models for autonomous driving. arXiv preprint arXiv:2501.11260, 2025. 10
arXiv 2025
-
[15]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. InAdvances in Neural Information Processing Systems, volume 37, pages 91560–91596, 2024
2024
-
[16]
On the content bias in fréchet video distance
Songwei Ge, Agrim Mahapatra, Gaurav Parmar, Jun-Yan Zhu, and Jia-Bin Huang. On the content bias in fréchet video distance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7277–7288, 2024
2024
-
[17]
Vision meets robotics: The KITTI dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The KITTI dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
2013
-
[18]
Are we ready for autonomous driving? the KITTI vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3354–3361, 2012
2012
-
[19]
Zico Kolter
Zhengyang Geng, Ashwini Pokle, Weijian Luo, Justin Lin, and J. Zico Kolter. Consistency models made easy. InInternational Conference on Learning Representations, 2025
2025
-
[20]
Learning to reach goals via iterated supervised learning
Dibya Ghosh, Abhishek Gupta, Ashwin Reddy, Justin Fu, Coline Devin, Benjamin Eysenbach, and Sergey Levine. Learning to reach goals via iterated supervised learning. InInternational Conference on Learning Representations, 2021
2021
-
[21]
Jing Gu, Xian Liu, Yu Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Yue Fan, Qianqi Yan, Kaiwen Zhou, Ming-Yu Liu, and Xin Eric Wang. PhyWorldBench: A comprehensive evaluation of physical realism in text-to-video models.arXiv preprint arXiv:2507.13428, 2025
Pith/arXiv arXiv 2025
-
[22]
BadNets: Evaluating backdooring attacks on deep neural networks.IEEE Access, 7:47230–47244, 2019
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. BadNets: Evaluating backdooring attacks on deep neural networks.IEEE Access, 7:47230–47244, 2019
2019
-
[23]
World models.arXiv preprint arXiv:1803.10122, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
Pith/arXiv arXiv 2018
-
[24]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[25]
Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high-fidelity video generation with arbitrary lengths.arXiv preprint arXiv:2211.13221, 2022
Pith/arXiv arXiv 2022
-
[26]
Kingma, Ben Poole, Mohammad Norouzi, David J
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
Pith/arXiv arXiv 2022
-
[27]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[28]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InAdvances in Neural Information Processing Systems, volume 35, pages 8633–8646, 2022
2022
-
[29]
GAIA-1: A generative world model for autonomous driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. GAIA-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[30]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
2024
-
[31]
VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3):3268–3285, 2026
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelli...
2026
-
[32]
When to trust your model: Model-based policy optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. InAdvances in Neural Information Processing Systems, volume 32, pages 12519–12530, 2019
2019
-
[33]
How far is video generation from world model: A physical law perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. InProceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 28991–29017. PMLR, 2025
2025
-
[34]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022
2022
-
[35]
Junae Kim and Amardeep Kaur. A survey on adversarial robustness of LiDAR-based machine learning perception in autonomous vehicles.arXiv preprint arXiv:2411.13778, 2024
arXiv 2024
-
[36]
Birodkar, Jimmy Yan, Ming-Chang Chiu, Krishna Somandepalli, Hassan Akbari, Yair Alon, Yong Cheng, Joshua V
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh N. Birodkar, Jimmy Yan, Ming-Chang Chiu, Krishna Somandepalli, Hassan Akbari, Yair Alon, Yong Cheng, Joshua V . Dillon, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, Mikhail Sirotenko, Kihyuk Sohn, Xuan Yang, Hartw...
2024
-
[37]
Lingdong Kong, Wesley Yang, Jianbiao Mei, Youquan Liu, Ao Liang, Dekai Zhu, Dongyue Lu, Wei Yin, Xiaotao Hu, Mingkai Jia, Junyuan Deng, Kaiwen Zhang, Yang Wu, Tianyi Yan, Shenyuan Gao, Song Wang, Linfeng Li, Liang Pan, Yong Liu, Jianke Zhu, Wei Tsang Ooi, Steven C. H. Hoi, and Ziwei Liu. 3D and 4D world modeling: A survey.arXiv preprint arXiv:2509.07996, 2025
arXiv 2025
-
[38]
Gonzalez, Ion Stoica, Song Han, and Yao Lu
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E. Gonzalez, Ion Stoica, Song Han, and Yao Lu. WorldModelBench: Judging video generation models as world models. InAdvances in Neural Information Processing Systems, 2025. Datasets and Benchmarks Track
2025
-
[39]
Temporal- distributed backdoor attack against video based action recognition
Xi Li, Songhe Wang, Ruiquan Huang, Mahanth Gowda, and George Kesidis. Temporal- distributed backdoor attack against video based action recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 3199–3207, 2024
2024
-
[40]
A comprehensive survey on world models for embodied AI.arXiv preprint arXiv:2510.16732, 2025
Xinqing Li, Xin He, Le Zhang, Min Wu, Xiaoli Li, and Yun Liu. A comprehensive survey on world models for embodied AI.arXiv preprint arXiv:2510.16732, 2025
arXiv 2025
-
[41]
Backdoor learning: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(1):5–22, 2024
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(1):5–22, 2024
2024
-
[42]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024
Pith/arXiv arXiv 2024
-
[43]
Control- Loc: Physical-world hijacking attack on camera-based perception in autonomous driving
Chen Ma, Ningfei Wang, Zhengyu Zhao, Qian Wang, Qi Alfred Chen, and Chao Shen. Control- Loc: Physical-world hijacking attack on camera-based perception in autonomous driving. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 738–752, 2025
2025
-
[44]
Wild pat- terns reloaded: A survey of machine learning security against training data poisoning.ACM Computing Surveys, 55(13s):1–39, 2023
Katharina Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild pat- terns reloaded: A survey of machine learning security against training data poisoning.ACM Computing Surveys, 55(13s):1–39, 2023
2023
-
[45]
Pham, Khoa D
Thuy Dung Nguyen, Tuan Nguyen, Phi Le Nguyen, Hieu H. Pham, Khoa D. Doan, and Kok- Seng Wong. Backdoor attacks and defenses in federated learning: Survey, challenges and future research directions.Engineering Applications of Artificial Intelligence, 127:107166, 2024. 12
2024
-
[46]
Safety, security, and cognitive risks in world models.arXiv preprint arXiv:2604.01346, 2026
Manoj Parmar. Safety, security, and cognitive risks in world models.arXiv preprint arXiv:2604.01346, 2026
Pith/arXiv arXiv 2026
-
[47]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. GAIA-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[48]
Dickerson, and Tom Goldstein
Avi Schwarzschild, Micah Goldblum, Arjun Gupta, John P. Dickerson, and Tom Goldstein. Just how toxic is data poisoning? a unified benchmark for backdoor and data poisoning attacks. In International Conference on Machine Learning, pages 9389–9398. PMLR, 2021
2021
-
[49]
On the exploitability of instruction tuning
Manli Shu, Jiongxiao Wang, Chen Zhu, Jonas Geiping, Chaowei Xiao, and Tom Goldstein. On the exploitability of instruction tuning. InAdvances in Neural Information Processing Systems, volume 36, pages 61836–61856, 2023
2023
-
[50]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. InInternational Conference on Learning Representations, 2023
2023
-
[51]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252. PMLR, 2023
2023
-
[52]
Poisoning language models during instruction tuning
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. Poisoning language models during instruction tuning. InInternational Conference on Machine Learning, pages 35413–35425. PMLR, 2023
2023
-
[53]
BadVideo: Stealthy backdoor attack against text-to-video generation
Ruotong Wang, Mingli Zhu, Jiarong Ou, Rui Chen, Xin Tao, Pengfei Wan, and Baoyuan Wu. BadVideo: Stealthy backdoor attack against text-to-video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19075–19084, 2025
2025
-
[54]
Drive- Dreamer: Towards real-world-driven world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- Dreamer: Towards real-world-driven world models for autonomous driving. InComputer Vision – ECCV 2024, pages 55–72. Springer, 2024
2024
-
[55]
DiLu: A knowledge-driven approach to autonomous driving with large language models
Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, and Yu Qiao. DiLu: A knowledge-driven approach to autonomous driving with large language models. InInternational Conference on Learning Representations, 2024
2024
-
[56]
Generalized Predictive Model for Autonomous Driving
Jiazhi Yang, Shenyuan Gao, Yihang Qiu, Li Chen, Tianyu Li, Bo Dai, Kashyap Chitta, Penghao Wu, Jia Zeng, Ping Luo, Jun Zhang, Andreas Geiger, Yu Qiao, and Hongyang Li. Generalized Predictive Model for Autonomous Driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[57]
CogVideoX: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, 2025
2025
-
[58]
DriveDreamer-2: LLM-enhanced world models for diverse driving video generation
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang Wang. DriveDreamer-2: LLM-enhanced world models for diverse driving video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10412–10420, 2025
2025
-
[59]
UniDriveDreamer: A single-stage multimodal world model for autonomous driving
Guosheng Zhao, Yaozeng Wang, Xiaofeng Wang, Zheng Zhu, Tingdong Yu, Guan Huang, Yongchen Zai, Ji Jiao, Changliang Xue, Xiaole Wang, Zhen Yang, Futang Zhu, and Xingang Wang. UniDriveDreamer: A single-stage multimodal world model for autonomous driving. arXiv preprint arXiv:2602.02002, 2026. 13 A Fine-Tuning Matrix and Poison-Rate Audit Table 3 reports the ...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.