Online Predictive Coding for Dual-Mode Self-Supervised Speech Model
Pith reviewed 2026-06-26 13:13 UTC · model grok-4.3
The pith
Online Predictive Coding regularizes registers to shrink the streaming versus offline performance gap in dual-mode speech models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
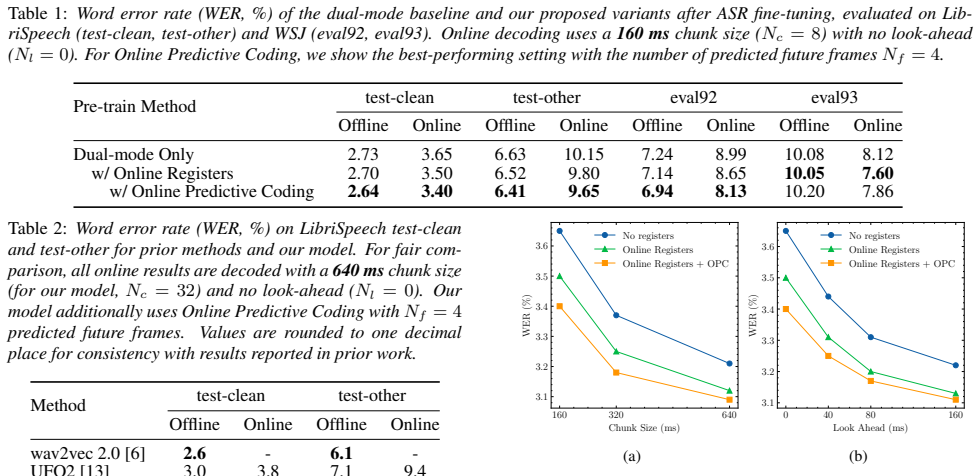
Online Predictive Coding regularizes the online registers by requiring them to perform multi-step future prediction, while Dual-mode Layer Normalization stabilizes the joint optimization; together they reduce the word-error-rate difference between streaming and non-streaming modes on LibriSpeech at 160 ms latency from 3.65 percent to 3.40 percent on test-clean and from 10.15 percent to 9.65 percent on test-other.
What carries the argument
Online Predictive Coding (OPC), the mechanism that forces online registers to predict several future frames and thereby compensates for absent future context in streaming attention.
If this is right
- OPC plus Dual-mode Layer Normalization produces lower word error rates than prior online-register baselines on both LibriSpeech and WSJ after ASR fine-tuning.
- The online-offline gap shrinks consistently across the tested latency settings once multi-step prediction is added.
- Dual-mode Layer Normalization is required to keep the joint streaming and non-streaming pre-training stable when OPC is active.
- The same architecture can be fine-tuned for automatic speech recognition without separate online and offline models.
Where Pith is reading between the lines
- The same multi-step prediction idea could be tested on other dual-mode sequence tasks such as streaming translation or music generation.
- If the prediction horizon in OPC is lengthened further, the remaining online-offline gap might close even more, provided normalization remains effective.
- Deploying a single dual-mode checkpoint instead of two separate models would reduce memory and maintenance cost in production streaming systems.
Load-bearing premise
Multi-step future prediction will compensate for missing context without creating instabilities that Dual-mode Layer Normalization cannot control.
What would settle it
Training the same dual-mode model with OPC on LibriSpeech but observing that word error rate on test-other rises above the 9.65 percent baseline at 160 ms latency would falsify the central claim.
Figures


read the original abstract
Dual-mode self-supervised speech models are pre-trained to handle streaming and non-streaming conditions simultaneously. However, their attention is computed over different context ranges, which often makes optimization difficult. In previous work, we proposed online registers, additional tokens intended to compensate for missing future context in streaming mode, but the gains remained limited. To address these issues, we introduce two improvements for robust dual-mode pre-training: (1) Online Predictive Coding (OPC), which regularizes the registers through multi-step future prediction, and (2) Dual-mode Layer Normalization, which stabilizes optimization. We fine-tune the proposed dual-mode self-supervised speech models for speech recognition on LibriSpeech and WSJ. Results show that OPC consistently reduces the online-offline performance gap; at 160 ms latency on LibriSpeech, word error rates improve from 3.65% to 3.40% on test-clean and from 10.15% to 9.65% on test-other.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two improvements to dual-mode self-supervised speech pre-training: Online Predictive Coding (OPC), which adds multi-step future prediction to regularize online registers and compensate for missing future context in streaming mode, and Dual-mode Layer Normalization to stabilize optimization across context ranges. It claims these changes narrow the online-offline performance gap, reporting concrete WER reductions on LibriSpeech at 160 ms latency (test-clean: 3.65% → 3.40%; test-other: 10.15% → 9.65%) after fine-tuning for ASR, with additional evaluation on WSJ.
Significance. If the attribution to OPC holds, the approach offers a targeted regularization technique that could improve low-latency streaming speech recognition by making dual-mode models more robust without requiring separate online and offline pre-training runs. The use of standard benchmarks and explicit latency figures provides a clear, falsifiable basis for comparison with prior dual-mode methods.
major comments (2)
- [Abstract] Abstract (paragraph on proposed improvements): The reported WER reductions are presented as the joint outcome of introducing both OPC and Dual-mode Layer Normalization together; no ablation isolating the contribution of OPC's multi-step future prediction (versus the normalization change alone or their interaction) is described. This directly undermines the central claim that OPC 'consistently reduces the online-offline performance gap.'
- [Abstract] Abstract and results description: No error bars, multiple random seeds, statistical tests, or training-procedure details are provided for the WER figures (e.g., 3.65% to 3.40%). Without these, the 0.25–0.5% absolute improvements cannot be assessed for robustness, which is load-bearing given that the headline claim rests on these specific numbers.
minor comments (1)
- Notation for latency (160 ms) and register tokens should be defined explicitly on first use rather than assumed from prior self-cited work.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on proposed improvements): The reported WER reductions are presented as the joint outcome of introducing both OPC and Dual-mode Layer Normalization together; no ablation isolating the contribution of OPC's multi-step future prediction (versus the normalization change alone or their interaction) is described. This directly undermines the central claim that OPC 'consistently reduces the online-offline performance gap.'
Authors: We acknowledge that the abstract and results present the WER gains for the combined OPC + Dual-mode LN model without an explicit ablation isolating OPC. In the revised manuscript we will add an ablation table comparing (i) the prior dual-mode baseline with online registers, (ii) the model with only Dual-mode LN, and (iii) the full model with both OPC and Dual-mode LN. This will allow direct attribution of any additional gap reduction to the multi-step future prediction in OPC. revision: yes
-
Referee: [Abstract] Abstract and results description: No error bars, multiple random seeds, statistical tests, or training-procedure details are provided for the WER figures (e.g., 3.65% to 3.40%). Without these, the 0.25–0.5% absolute improvements cannot be assessed for robustness, which is load-bearing given that the headline claim rests on these specific numbers.
Authors: We agree that additional training-procedure details are needed. In revision we will expand the experimental section with all pre-training and fine-tuning hyperparameters, optimizer settings, and data-augmentation choices. Regarding error bars and multiple seeds, the computational cost of pre-training large dual-mode models on LibriSpeech-scale data precluded repeated runs; we will therefore note this limitation explicitly and rely on the consistent trend observed across both LibriSpeech and WSJ to support the reported improvements. revision: partial
- Absence of multiple random seeds and associated error bars/statistical tests for the headline WER numbers, as re-running the full pre-training pipeline is computationally prohibitive.
Circularity Check
No circularity; empirical gains on external benchmarks
full rationale
The paper reports concrete WER reductions (3.65%→3.40% test-clean, 10.15%→9.65% test-other at 160 ms) on LibriSpeech and WSJ after introducing OPC and Dual-mode LN. It references prior self-work on online registers only to motivate the new components; the central claim is an empirical outcome on standard external test sets, not a derivation that reduces to a fitted parameter, self-defined quantity, or unverified self-citation chain. No equation or prediction is shown to equal its input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised objectives on speech can be improved by adding explicit future-prediction regularization on auxiliary tokens.
Reference graph
Works this paper leans on
-
[1]
Introduction Self-supervised speech models (S3Ms) [1] have become a foun- dational paradigm for a wide range of speech processing tasks. By pre-training on large-scale unlabeled speech, they achieve strong performance across diverse downstream tasks, as evi- denced by SUPERB [2] and multilingual speech recognition benchmarks [3, 4, 5]. However, most leadi...
-
[2]
Related Work Dual-mode architectures for ASR.Dual-mode models sup- port both online and offline inference within a single archi- tecture and have been studied in automatic speech recognition (ASR) [18, 19, 20]. They are typically trained by jointly opti- mizing online and offline pathways with a shared encoder, of- ten combined with Dynamic Chunk Training...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
UUFOUJPO0GGMJOF 4FMG
Methods 3.1. Dual-mode Transformer with Online Registers Our encoder is based on wav2vec 2.0 [6] and is pre-trained in a dual-mode manner. LetX= (x 1, . . . ,xT )denote the latent features extracted by a convolutional feature encoder, where xt ∈R d andTis the number of feature frames. For online mode, we partitionXinto chunks of sizeN c with an optional l...
-
[4]
Experiments 4.1. Experimental Settings Unless otherwise stated, we follow the official Fairseq [23] wav2vec 2.0 configurations as our baseline and introduce only the modifications described in Section 3. Datasets.Pre-training was conducted on the 960-hour Lib- riSpeech corpus [24] without transcriptions. For ASR fine- tuning, we used LibriSpeech 960h and ...
-
[5]
By enabling online registers to encode predictive information about unseen future frames, our method reduces the offline–online attention gap
Conclusion In this paper, we proposed the pre-training framework named Online Predictive Coding (OPC), which explicitly encourages robust modeling of future context. By enabling online registers to encode predictive information about unseen future frames, our method reduces the offline–online attention gap. In ad- dition, Dual-mode Layer Normalization mit...
-
[6]
The tools were not used to write major parts of the manuscript, formulate the research questions, design the exper- iments, analyze the results, or draw conclusions
Generative AI Use Disclosure Generative AI tools are used for grammar and style editing of the manuscript and for assistance in implementing experimen- tal code. The tools were not used to write major parts of the manuscript, formulate the research questions, design the exper- iments, analyze the results, or draw conclusions
-
[7]
Self-supervised speech representation learning: A review,
A. Mohamed, H. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløe, T. N. Sainath, and S. Watanabe, “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, pp. 1179–1210, 2022
2022
-
[8]
SUPERB: Speech processing universal performance benchmark,
S.-W. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T. hsien Huang, W.- C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. rahman Mohamed, and H. yi Lee, “SUPERB: Speech processing universal performance benchmark,” inProc. Interspeech, 2021
2021
-
[9]
Towards robust speech representation learning for thousands of languages,
W. Chen, W. Zhang, Y . Peng, X. Li, J. Tian, J. Shi, X. Chang, S. Maiti, K. Livescu, and S. Watanabe, “Towards robust speech representation learning for thousands of languages,” inProc. EMNLP, 2024
2024
-
[10]
XLS-R: Self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “XLS-R: Self-supervised cross-lingual speech representation learning at scale,” inProc. Interspeech, 2022
2022
-
[11]
Google USM: Scaling automatic speech recognition beyond 100 languages,
Y . Zhang, W. Han, J. Qin, Y . Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V . Axelrod, G. Wanget al., “Google USM: Scaling auto- matic speech recognition beyond 100 languages,”arXiv preprint arXiv:2303.01037, 2023
-
[12]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inProc. NeurIPS, 2020
2020
-
[13]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[14]
Self-supervised learning with random-projection quantizer for speech recogni- tion,
C. Chiu, J. Qin, Y . Zhang, J. Yu, and Y . Wu, “Self-supervised learning with random-projection quantizer for speech recogni- tion,” inProc. ICML, 2022, pp. 3915–3924
2022
-
[15]
Knowledge distillation for neural transducers from large self-supervised pre-trained models,
X. Yang, Q. Li, and P. C. Woodland, “Knowledge distillation for neural transducers from large self-supervised pre-trained models,” inProc. ICASSP, 2022, pp. 8527–8531
2022
-
[16]
Improving streaming transformer based ASR under a framework of self-supervised learning,
S. Cao, Y . Kang, Y . Fu, X. Xu, S. Sun, Y . Zhang, and L. Ma, “Improving streaming transformer based ASR under a framework of self-supervised learning,” inProc. Interspeech, 2021, pp. 706– 710
2021
-
[17]
DistillW2V2: A small and streaming wav2vec 2.0 based ASR model,
Y . Fu, Y . Kang, S. Cao, and L. Ma, “DistillW2V2: A small and streaming wav2vec 2.0 based ASR model,”arXiv preprint arXiv:2303.09278, 2023
-
[18]
wav2vec- S: Adapting pre-trained speech models for streaming,
B. Fu, K. Fan, M. Liao, Y . Chen, X. Shi, and Z. Huang, “wav2vec- S: Adapting pre-trained speech models for streaming,” inProc. ACL, 2024, pp. 11 465–11 480
2024
-
[19]
UFO2: A unified pre-training framework for online and offline speech recognition,
L. Fu, S. Li, Q. Li, L. Deng, F. Li, L. Fan, M. Chen, and X. He, “UFO2: A unified pre-training framework for online and offline speech recognition,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[20]
DuRep: Dual-mode speech represen- tation learning via ASR-aware distillation,
P. R. Male, S. N. Ray, H. Arsikere, A. Jaiswal, P. Swarup, P. Sen, D. Chakrabarty, K. V . V . Girish, N. Bhave, F. Weber, S. Bhat- tacharya, and S. Garimella, “DuRep: Dual-mode speech represen- tation learning via ASR-aware distillation,” inProc. Interspeech, 2025, pp. 5808–5812
2025
-
[21]
Online register for dual-mode self-supervised speech models: Mitigating the lack of future context,
K. Goto, T. Maekaku, J. Sakuma, J. Tian, Y . Shinohara, and S. Watanabe, “Online register for dual-mode self-supervised speech models: Mitigating the lack of future context,”Proc. of ICASSP, pp. 18 272–18 276, 2926
-
[22]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
J. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Dual-mode ASR: Unify and improve streaming ASR with full-context modeling,
J. Yu, W. Han, A. Gulati, C. Chiu, B. Li, T. N. Sainath, Y . Wu, and R. Pang, “Dual-mode ASR: Unify and improve streaming ASR with full-context modeling,” inProc. ICLR, 2021
2021
-
[25]
Dual causal/non-causal self- attention for streaming end-to-end speech recognition,
N. Moritz, T. Hori, and J. L. Roux, “Dual causal/non-causal self- attention for streaming end-to-end speech recognition,” inProc. Interspeech, 2021, pp. 1822–1826
2021
-
[26]
Conformer with dual-mode chunked attention for joint online and offline ASR,
F. Weninger, M. Gaudesi, M. A. Haidar, N. Ferri, J. Andr´es-Ferrer, and P. Zhan, “Conformer with dual-mode chunked attention for joint online and offline ASR,” inProc. Interspeech, 2022, pp. 2053–2057
2022
-
[27]
Unified streaming and non-streaming two- pass end-to-end model for speech recognition,
B. Zhang, D. Wu, Z. Yao, X. Wang, F. Yu, C. Yang, L. Guo, Y . Hu, L. Xie, and X. Lei, “Unified streaming and non-streaming two- pass end-to-end model for speech recognition,”arXiv preprint arXiv:2012.05481, 2020
-
[28]
NEST-RQ: Next token prediction for speech self-supervised pre-training,
M. Han, Y . Bai, C. Shen, Y . Huang, M. Huang, Z. Lin, L. Dong, L. Lu, and Y . Wang, “NEST-RQ: Next token prediction for speech self-supervised pre-training,”arXiv preprint arXiv:2409.08680, 2024
-
[29]
fairseq: A fast, extensible toolkit for sequence modeling,
M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grang- ier, and M. Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” inProc. NAACL-HLT (Demonstrations), 2019, pp. 48–53
2019
-
[30]
Lib- riSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: An ASR corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
2015
-
[31]
The design for the Wall Street Journal-based CSR corpus,
D. B. Paul and J. M. Baker, “The design for the Wall Street Journal-based CSR corpus,” inProc. ICSLP, 1992
1992
-
[32]
Trans- former ASR with contextual block processing,
E. Tsunoo, Y . Kashiwagi, T. Kumakura, and S. Watanabe, “Trans- former ASR with contextual block processing,” inProc. ASRU, 2019, pp. 427–433
2019
-
[33]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inProc. ICLR, 2015
2015
-
[34]
Connectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. J. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inProc. ICML, 2006, pp. 369–376
2006
-
[35]
Flashlight: En- abling innovation in tools for machine learning,
J. D. Kahn, V . Pratap, T. Likhomanenko, Q. Xu, A. Y . Hannun, J. Cai, P. Tomasello, A. Lee, E. Grave, G. Avidov, B. Steiner, V . Liptchinsky, G. Synnaeve, and R. Collobert, “Flashlight: En- abling innovation in tools for machine learning,” inProc. ICML, 2022, pp. 10 557–10 574
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.