KBSpec: LLM-driven Formal Specification Generation with Evolving Domain Knowledge Base
Pith reviewed 2026-06-26 13:36 UTC · model grok-4.3
The pith
KBSpec augments LLMs with a self-evolving knowledge base drawn from verifier feedback to raise formal specification verification rates by 10-25%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KBSpec augments LLMs with dual-source knowledge of formal specification language—external knowledge from official documentation and internal knowledge distilled from verifier feedback on LLM-generated specifications—while maintaining a self-evolving knowledge base that is continuously updated from successful generation and repair trajectories, without any LLM parameter tuning or labeled training data.
What carries the argument
Dual-source self-evolving knowledge base that combines external documentation with patterns extracted from verifier feedback on successful specification trajectories.
If this is right
- LLM-generated JML specifications achieve 10-25% higher verification pass rates than prior LLM-only methods.
- The approach yields the largest number of high-completeness specifications among compared methods.
- The same gains appear across multiple LLM backends with no parameter changes or extra training data.
- The knowledge base grows solely from successful trajectories, allowing continued improvement during deployment.
Where Pith is reading between the lines
- The same feedback-driven evolution could be applied to other formal languages such as ACSL or TLA+ where documentation exists but example corpora are small.
- Over repeated runs the knowledge base may accumulate language-specific idioms that reduce common syntax errors even on out-of-distribution programs.
- The method offers a template for adding lightweight memory to LLMs on any task where an external verifier can label success or failure.
Load-bearing premise
Verifier feedback on LLM-generated specifications yields reliable, distillable signals that improve future generations when added to the knowledge base without injecting errors.
What would settle it
Run the system on a fresh set of programs while forcing the knowledge base to incorporate verifier feedback that contains incorrect patterns; if verification pass rates then fall or stay flat, the central claim fails.
Figures
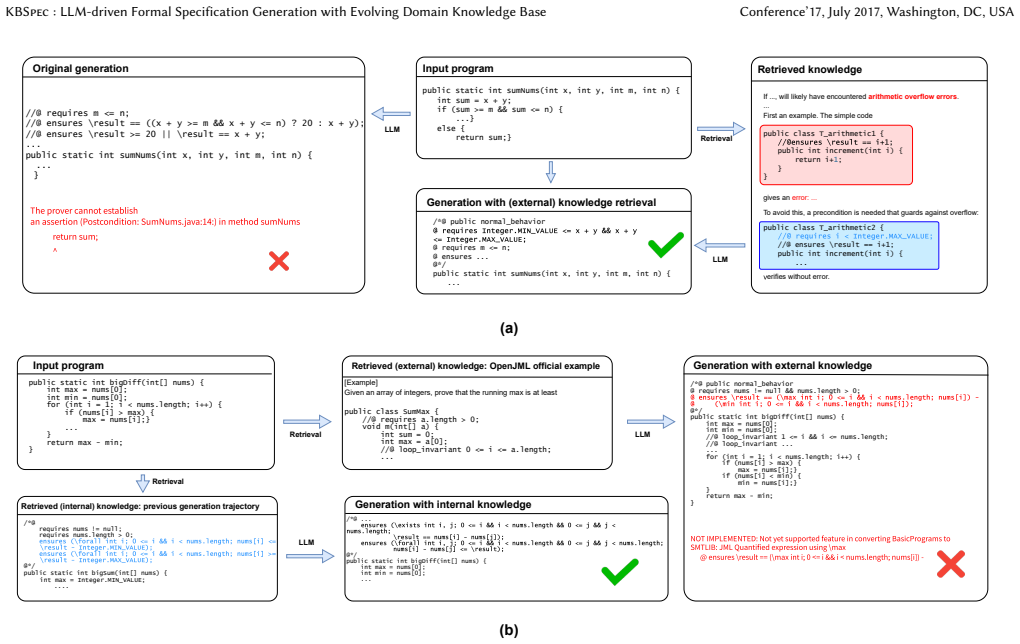
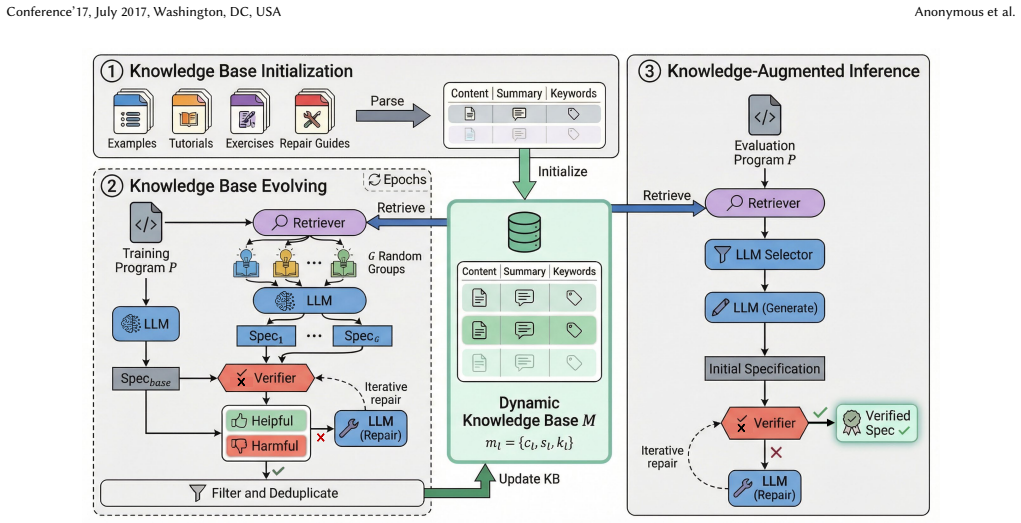
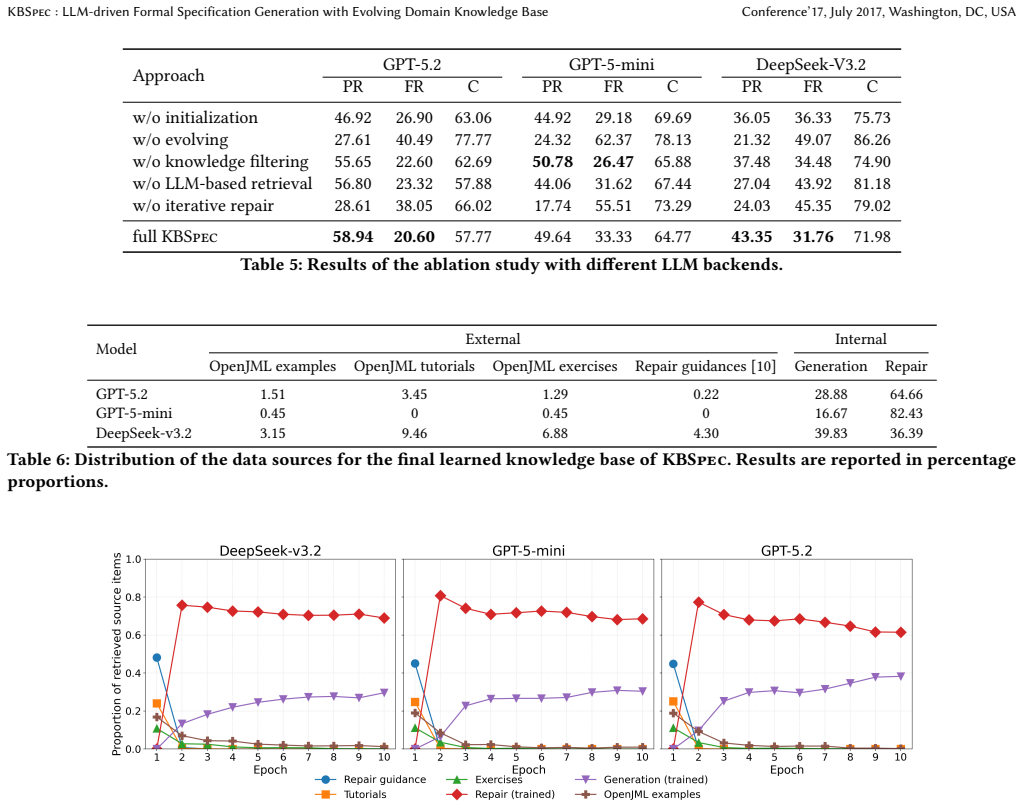
read the original abstract
Automated formal specification generation is a key step towards program understanding and formal verification. Recently, due to the success of large language models (LLMs) in code generation, researchers have made early attempts to adopt LLMs for generating formal specifications. However, the lack of formal specification language corpora in the wild often makes LLMs fail to generate syntactically correct and semantically verifiable specifications. To mitigate this gap, we propose KBSpec, which augments LLMs with dual-source knowledge of formal specification language: external knowledge from official documentation, and internal knowledge distilled from verifier feedback on LLM-generated specifications. KBSpec maintains a self-evolving knowledge base that is continuously updated from successful generation and repair trajectories, without any LLM parameter tuning or labeled training data. We evaluate KBSpec on Java Modeling Language (JML) specification generation with three LLM backends, and results show that KBSpec improves verification pass rates by 10-25% over state-of-the-art LLM-based approaches, while producing the largest number of high-completeness specifications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KBSpec, an LLM-augmented system for automated formal specification generation (focused on JML) that maintains a self-evolving dual-source knowledge base: external official documentation plus internal knowledge distilled from verifier feedback on successful generation/repair trajectories. No LLM fine-tuning or labeled data is used. On JML tasks with three LLM backends, it claims 10-25% higher verification pass rates than prior LLM-based methods and produces the largest number of high-completeness specifications.
Significance. If the empirical claims hold after proper documentation of the evaluation, the work would be significant for formal methods and SE by demonstrating a parameter-free, continuously improvable approach to specification generation that leverages verifier signals without requiring corpora. Credit is given for the explicit dual-source design and avoidance of parameter tuning.
major comments (2)
- [Section 3] Section 3: The self-evolving KB mechanism distills patterns from 'successful generation and repair trajectories' into the knowledge base without human review, retraction mechanisms, or explicit checks for semantic drift or regression; this directly undermines the central assumption that verifier feedback yields reliably generalizable, error-free signals for future prompts.
- [Evaluation section] Evaluation section: The abstract and results claim 10-25% verification pass-rate gains and superior high-completeness counts, yet supply no information on dataset size, baseline selection, statistical tests, how completeness was quantified, or the verifier harness used; these omissions render the quantitative central claim impossible to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point-by-point below. Revisions will be made to incorporate additional details and discussion where the concerns identify gaps in the current presentation.
read point-by-point responses
-
Referee: [Section 3] Section 3: The self-evolving KB mechanism distills patterns from 'successful generation and repair trajectories' into the knowledge base without human review, retraction mechanisms, or explicit checks for semantic drift or regression; this directly undermines the central assumption that verifier feedback yields reliably generalizable, error-free signals for future prompts.
Authors: The mechanism incorporates knowledge exclusively from trajectories where the generated JML specification passes verification, supplying an objective, tool-based correctness signal rather than relying on unverified LLM output. The external official documentation component is retained as a stable reference to anchor against drift. We acknowledge, however, that the current description does not include explicit retraction or regression-detection procedures. In the revised manuscript we will expand Section 3 with a limitations subsection that discusses these risks and describes how the dual-source design (external documentation plus verified internal patterns) is intended to limit propagation of errors, together with a note on planned future safeguards. revision: yes
-
Referee: [Evaluation section] Evaluation section: The abstract and results claim 10-25% verification pass-rate gains and superior high-completeness counts, yet supply no information on dataset size, baseline selection, statistical tests, how completeness was quantified, or the verifier harness used; these omissions render the quantitative central claim impossible to assess.
Authors: We agree that the evaluation section is missing essential methodological details required for assessment and reproducibility. The revised manuscript will add: the exact size and composition of the evaluation dataset, the rationale and sources for the chosen baselines, the statistical tests performed (including p-values), the concrete metric and procedure used to quantify specification completeness, and a full description of the JML verifier harness (tool name, version, and configuration). These additions will allow readers to evaluate the reported 10-25% gains and completeness results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central mechanism augments LLMs with external official documentation plus verifier feedback (e.g., OpenJML) to evolve a KB from successful trajectories. Evaluation metrics (verification pass rates, completeness) are computed against independent verifiers and compared to external SOTA baselines. No equations, self-citations, or fitted parameters reduce the reported gains to the inputs by construction; the derivation chain remains externally grounded.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verifier feedback on generated specifications can be reliably distilled into useful knowledge for improving future LLM outputs
invented entities (1)
-
self-evolving knowledge base
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mostafijur Rahman Akhond, Saikat Chakraborty, and Gias Uddin. 2025. LLM For Loop Invariant Generation and Fixing: How Far Are We?arXiv preprint arXiv:2511.06552(2025)
arXiv 2025
-
[2]
Lilian Burdy, Yoonsik Cheon, David R Cok, Michael D Ernst, Joseph R Kiniry, Gary T Leavens, K Rustan M Leino, and Erik Poll. 2005. An overview of JML tools and applications.International journal on software tools for technology transfer7, 3 (2005), 212–232
2005
-
[3]
Jialun Cao, Yaojie Lu, Meiziniu Li, Haoyang Ma, Haokun Li, Mengda He, Cheng Wen, Le Sun, Hongyu Zhang, Shengchao Qin, et al. 2025. From informal to formal– incorporating and evaluating llms on natural language requirements to verifiable formal proofs. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
2025
-
[4]
Zehan Chen, Long Zhang, Zhiwei Zhang, JingJing Zhang, Ruoyu Zhou, Yulong Shen, JianFeng Ma, and Lin Yang. 2026. Beyond Basic Specifications? A System- atic Study of Logical Constructs in LLM-based Specification Generation.arXiv preprint arXiv:2602.00715(2026)
arXiv 2026
-
[5]
David R Cok. 2011. OpenJML: JML for Java 7 by extending OpenJDK. InNASA formal methods symposium. Springer, 472–479
2011
-
[6]
Pascal Cuoq, Florent Kirchner, Nikolai Kosmatov, Virgile Prevosto, Julien Sig- noles, and Boris Yakobowski. 2012. Frama-C: A software analysis perspective. InInternational conference on software engineering and formal methods. Springer, 233–247
2012
-
[7]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K Lahiri
-
[8]
Can large language models transform natural language intent into formal method postconditions?Proceedings of the ACM on Software Engineering1, FSE (2024), 1889–1912
2024
-
[9]
Michael D Ernst, Jeff H Perkins, Philip J Guo, Stephen McCamant, Carlos Pacheco, Matthew S Tschantz, and Chen Xiao. 2007. The Daikon system for dynamic detection of likely invariants.Science of computer programming69, 1-3 (2007), 35–45
2007
-
[10]
Cormac Flanagan and K Rustan M Leino. 2001. Houdini, an annotation assistant for ESC/Java. InInternational symposium of formal methods Europe. Springer, 500–517
2001
-
[11]
Thanh Le-Cong, Bach Le, and Toby Murray. 2025. Can LLMs Reason About Program Semantics? A Comprehensive Evaluation of LLMs on Formal Specifica- tion Inference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Austria, 21991–22014. doi:10.18...
-
[12]
Hui Li, Zhen Dong, Siao Wang, Hui Zhang, Liwei Shen, Xin Peng, and Dongdong She. 2025. Extracting Formal Specifications From Documents Using LLMS for Test Automation. In2025 IEEE/ACM 33rd International Conference on Program Comprehension (ICPC). IEEE Computer Society, 1–12
2025
-
[13]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
Pith/arXiv arXiv 2025
-
[14]
Lezhi Ma, Shangqing Liu, Lei Bu, Shangru Li, Yida Wang, and Yang Liu. 2024. Speceval: Evaluating code comprehension in large language models via program specifications.arXiv preprint arXiv:2409.12866(2024)
arXiv 2024
-
[15]
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. 2025. SpecGen: Automated Generation of Formal Program Specifications via Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 16–28
2025
-
[16]
Zhi Ma, Cheng Wen, Zhexin Su, Xiao Liang, Cong Tian, Shengchao Qin, and Mengfei Yang. 2025. Bridging Natural Language and Formal Specifi- cation–Automated Translation of Software Requirements to LTL via Hier- archical Semantics Decomposition Using LLMs. In2025 40th IEEE/ACM In- ternational Conference on Automated Software Engineering (ASE). 1208–1220. doi...
-
[17]
2025.GPT-5 is Here
OpenAI. 2025.GPT-5 is Here. Technical Report. OpenAI. https://openai.com/gpt- 5/
2025
-
[18]
2025.Introducing GPT-5.2: Expert-Level Knowledge Work and Advanced Reasoning
OpenAI. 2025.Introducing GPT-5.2: Expert-Level Knowledge Work and Advanced Reasoning. Technical Report. OpenAI. https://openai.com/index/introducing- gpt-5-2/
2025
-
[19]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems. arXiv preprint arXiv:2310.08560(2023)
Pith/arXiv arXiv 2023
-
[20]
Md Rizwan Parvez, Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai- Wei Chang. 2021. Retrieval augmented code generation and summarization. In Findings of the Association for Computational Linguistics: EMNLP 2021. 2719–2734
2021
-
[21]
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. 2023. Can large language models reason about program invariants?. InInternational Conference on Machine Learning. PMLR, 27496–27520
2023
-
[22]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
2019
-
[23]
Chuyue Sun, Viraj Agashe, Saikat Chakraborty, Jubi Taneja, Clark Barrett, David Dill, Xiaokang Qiu, and Shuvendu K Lahiri. 2025. ClassInvGen: Class invari- ant synthesis using large language models. InInternational Symposium on AI Verification. Springer, 64–96
2025
-
[24]
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. 2025. Dynamic cheatsheet: Test-time learning with adaptive memory.arXiv preprint arXiv:2504.07952(2025)
arXiv 2025
-
[25]
Zhongyi Wang, Tengjie Lin, Mingshuai Chen, Haokun Li, Mingqi Yang, Xiao Yi, Shengchao Qin, Yixing Luo, Xiaofeng Li, Bin Gu, Liqiang Lu, and Jianwei Yin
-
[26]
ACM Program
A Tale of 1001 LoC: Potential Runtime Error-Guided Specification Synthesis for Verifying Large-Scale Programs.Proc. ACM Program. Lang.OOPSLA1 (2026). [To appear]
2026
-
[27]
Cheng Wen, Jialun Cao, Jie Su, Zhiwu Xu, Shengchao Qin, Mengda He, Haokun Li, Shing-Chi Cheung, and Cong Tian. 2024. Enchanting program specification synthesis by large language models using static analysis and program verification. InInternational Conference on Computer Aided Verification. Springer, 302–328
2024
-
[28]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[29]
InAdvances in Neural Information Processing Systems
A-mem: Agentic memory for llm agents. InAdvances in Neural Information Processing Systems
-
[30]
Fanpeng Yang, Xu Ma, Shuling Wang, Xiong Xu, Qinxiang Cao, Naijun Zhan, Xiaofeng Li, and Bin Gu. 2025. Integrating Symbolic Execution with LLMs for Automated Generation of Program Specifications.arXiv preprint arXiv:2506.09550 (2025)
arXiv 2025
-
[31]
Zezhou Yang, Sirong Chen, Cuiyun Gao, Zhenhao Li, Xing Hu, Kui Liu, and Xin Xia. 2025. An empirical study of retrieval-augmented code generation: Challenges and opportunities.ACM Transactions on Software Engineering and Methodology 34, 7 (2025), 1–28
2025
-
[32]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al
-
[33]
Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618(2025)
Pith/arXiv arXiv 2025
-
[34]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems 43, 6 (2025), 1–47
2025
-
[35]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memo- rybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731
2024
-
[36]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. 2023. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. InThe Eleventh International Conference on Learning Representations. https: //openreview.net/forum?id=WZH7099tgfM Conference...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.