LIG: Layer-wise Integrated Gradients for Within-Layer Flow Analysis in Transformers
Pith reviewed 2026-06-26 14:13 UTC · model grok-4.3
The pith
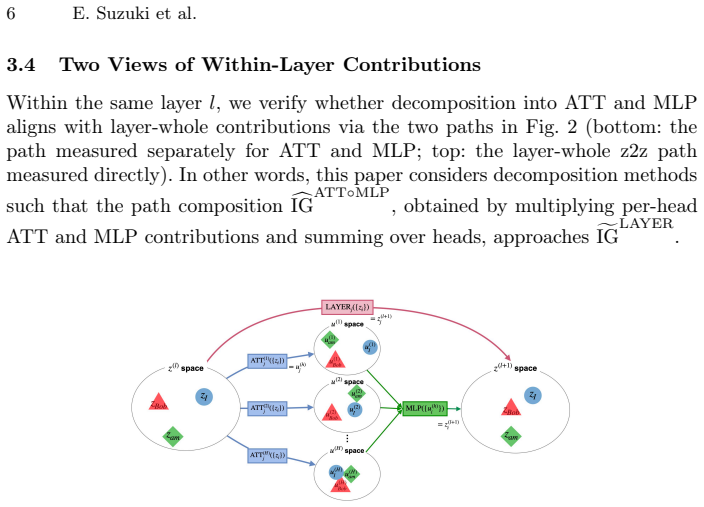
LIG applies integrated gradients at attention and MLP boundaries to trace token-to-token flows inside each Transformer layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
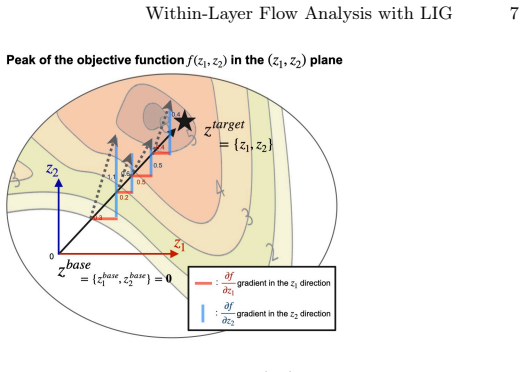
LIG computes set-to-set Integrated Gradients at the nonlinear boundaries of Multi-Head Attention and MLP modules inside a Transformer layer, scalarizing the path integral with an L2 norm so that token-to-token relevance scores can be obtained; these scores are chained across the two modules following the conservation principle of Layer-wise Relevance Propagation, with IG completeness substituting for relevance conservation at each boundary.
What carries the argument
Set-to-set Integrated Gradients with L2 scalarization, applied at ATT and MLP module boundaries and composed layer-wise.
If this is right
- Baseline choices that use the target token embedding for attention and either the zero-attention output or the all-zero vector for MLP preserve the highest within-layer consistency under the L2 criterion.
- ATT and MLP contributions can be separated and traced individually while still summing to the layer output.
- Module-wise composition can be compared against direct layer-level attribution to quantify internal agreement.
- The method yields diagnostic attributions at module-boundary granularity on any Transformer without architecture-specific redesign.
Where Pith is reading between the lines
- The same boundary-wise composition could be applied to decoder-only or encoder-decoder models whose layers contain analogous attention and feed-forward blocks.
- If the chosen baselines prove stable across datasets, LIG attributions could serve as a lightweight probe for comparing information routing strategies between different pretrained checkpoints.
- Token-level flow maps produced by LIG might be aggregated across many examples to identify systematic patterns such as attention heads that route information primarily to the same position.
- Because no retraining is required, the method could be inserted into existing interpretability pipelines that already compute gradients.
Load-bearing premise
The L2 scalarization of set-to-set integrated gradients preserves completeness and produces meaningful token-to-token attributions when composed across ATT and MLP boundaries.
What would settle it
A direct numerical check in which the sum of all LIG token-to-token scores for a given output token fails to equal the difference between the model's output on the actual input and its output on the chosen baseline.
Figures
read the original abstract
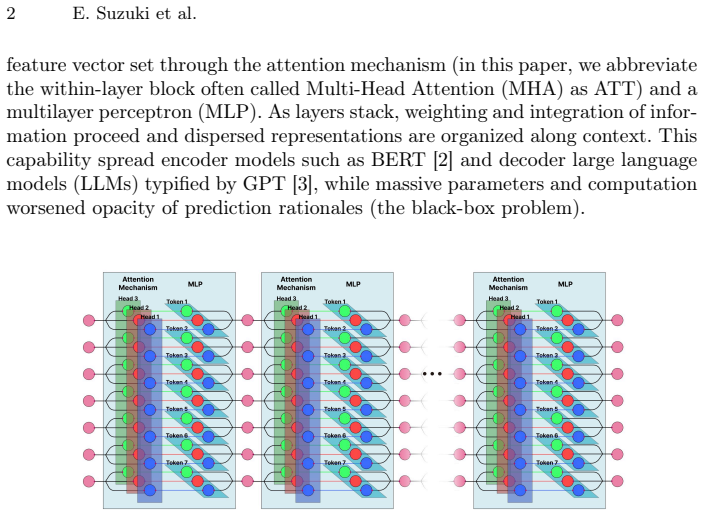
Transformers achieve strong performance, but their internal computations remain opaque. We view each Transformer layer as a dynamic graph whose nodes are token representations and per-head attention outputs, with Multi-Head Attention (ATT) and MLP as module boundaries. On this graph we use LIG (Layer-wise Integrated Gradients), which applies set-to-set Integrated Gradients (IG) at nonlinear module boundaries. Set-to-set IG applies IG to a map from a set of input token representations to a set of output representations, evaluating token-to-token contributions, which is not standard in prior IG applications. This extends IG from the usual scalar-objective setting to set-to-set maps via an L2 scalarization, and composes within-layer contributions in the spirit of Layer-wise Relevance Propagation (LRP), with IG completeness playing the role of LRP-style conservation at each boundary. We use LIG to analyze (i) the agreement between module-wise composition and layer-whole attribution under an L2 criterion, and (ii) within-layer information flow by tracing separated ATT and MLP contributions. On BERT-base and PTB, configurations that best preserved within-layer consistency used the target token's embedding as the ATT baseline and either the ATT output at a=0 or Zero as the MLP baseline. We therefore present LIG as a diagnostic XAI tool at module-boundary granularity, without model-specific retraining or per-operation interpreter design. Code is available at https://github.com/eightsuzuki/layer-wise-integrated-gradients.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Layer-wise Integrated Gradients (LIG), an extension of Integrated Gradients to set-to-set maps between token representations at ATT and MLP module boundaries within Transformer layers. It applies L2 scalarization to enable token-to-token attributions, composes these contributions across boundaries in the style of LRP (with IG completeness substituting for conservation), and evaluates baseline choices on BERT-base and PTB for within-layer consistency under an L2 criterion. The work positions LIG as a diagnostic XAI tool requiring no retraining or per-operation redesign.
Significance. If the L2 scalarization and composition preserve the claimed conservation property, LIG would supply a practical, model-agnostic method for tracing separated ATT/MLP flows at module granularity; the open code release is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that 'IG completeness playing the role of LRP-style conservation' at each boundary requires that the L2 scalarization of the set-to-set map yields attributions whose sums recover the vector difference in representations (componentwise or in norm). Standard IG completeness applies only to the scalarized objective; the manuscript supplies no derivation showing transfer to the underlying vector-valued function, leaving the diagnostic interpretation unsupported.
- [Abstract] Abstract: the reported 'configurations that best preserved within-layer consistency' are presented without any quantitative metrics, error bars, or comparison to layer-whole attribution baselines, so the empirical support for the method's utility cannot be assessed.
minor comments (1)
- [Abstract] The abstract states results on BERT/PTB but supplies no tables, figures, or numerical values; these should be added even in summary form.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'IG completeness playing the role of LRP-style conservation' at each boundary requires that the L2 scalarization of the set-to-set map yields attributions whose sums recover the vector difference in representations (componentwise or in norm). Standard IG completeness applies only to the scalarized objective; the manuscript supplies no derivation showing transfer to the underlying vector-valued function, leaving the diagnostic interpretation unsupported.
Authors: We agree the manuscript provides no explicit derivation showing how completeness transfers from the scalar L2 objective to the vector-valued map. Completeness holds for the scalarized function by construction of IG, and attributions are composed across boundaries, but this does not automatically recover componentwise vector differences without further conditions. In revision we will add a short derivation section clarifying the precise sense in which the attributions support a conservation-style interpretation (or we will narrow the claim to the scalarized objective). revision: yes
-
Referee: [Abstract] Abstract: the reported 'configurations that best preserved within-layer consistency' are presented without any quantitative metrics, error bars, or comparison to layer-whole attribution baselines, so the empirical support for the method's utility cannot be assessed.
Authors: The body of the manuscript reports L2-consistency scores for the listed baseline choices together with direct comparisons against layer-whole attributions. The abstract, however, states only the winning configurations without the supporting numbers. We will revise the abstract to include the key quantitative consistency values and will add error bars (or note the number of runs) where appropriate. revision: yes
Circularity Check
No significant circularity; derivation is an independent algorithmic extension
full rationale
The paper defines LIG via L2 scalarization of set-to-set IG and assigns IG completeness the role of conservation when composing like LRP. This is a definitional choice in the proposed method, not a reduction where any claimed result equals its inputs by construction. No fitted parameters are renamed as predictions, no load-bearing self-citations appear in the provided text, and no uniqueness theorems or ansatzes are imported from prior author work. The central claim is an algorithmic proposal for module-boundary analysis, which remains self-contained against external benchmarks and does not reduce to self-referential definitions or statistical forcing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems (NeurIPS)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 5998–6008 (2017)
2017
-
[2]
In: Proceedings of NAACL- HLT
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL- HLT. pp. 4171–4186 (2019)
2019
-
[3]
In: Advances in neural information processing systems
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakan- tan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: Advances in neural information processing systems. vol. 33, pp. 1877– 1901 (2020) Within-Layer Flow Analysis with LIG 15
1901
-
[4]
Information Fusion58, 82–115 (2020)
Arrieta, A.B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., Chatila, R., Herrera, F.: Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Information Fusion58, 82–115 (2020)
2020
-
[5]
PLOS ONE10(7), e0130140 (2015)
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.R., Samek, W.: On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLOS ONE10(7), e0130140 (2015)
2015
-
[6]
Explainable AI: Interpreting, Explaining and Visualizing Deep Learning pp
Montavon, G., Lapuschkin, S., Binder, A., Samek, W., Müller, K.R.: Layer-wise relevance propagation: An overview. Explainable AI: Interpreting, Explaining and Visualizing Deep Learning pp. 193–209 (2019)
2019
-
[7]
Proceedings of the 34th International Conference on Machine Learning pp
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. Proceedings of the 34th International Conference on Machine Learning pp. 3319– 3328 (2017)
2017
-
[8]
In: Proceed- ings of the International Conference on Machine Learning (ICML) (2024)
Achtibat, R., Hatefi, S.M.V., Dreyer, M., Samek, W., Lapuschkin, S.: AttnLRP: Attention-Aware Layer-Wise Relevance Propagation for Transformers. In: Proceed- ings of the International Conference on Machine Learning (ICML) (2024)
2024
-
[9]
In: Proceed- ings of ACL
Abnar, S., Zuidema, W.: Quantifying attention flow in transformers. In: Proceed- ings of ACL. pp. 4190–4197 (2020)
2020
-
[10]
In: Pro- ceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics: System Demonstrations
Vig, J.: A multiscale visualization of attention in the transformer model. In: Pro- ceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics: System Demonstrations. pp. 37–42 (2019)
2019
-
[11]
In: Proceedings of the 2019 ACL Workshop Black- boxNLP
Clark, K., Khandelwal, U., Levy, O., Manning, C.D.: What does BERT look at? an analysis of BERT’s attention. In: Proceedings of the 2019 ACL Workshop Black- boxNLP. pp. 276–286 (2019)
2019
-
[12]
In: Proceedings of NAACL- HLT
Jain, S., Wallace, B.: Attention is not explanation. In: Proceedings of NAACL- HLT. pp. 3543–3556 (2019)
2019
-
[13]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Kobayashi, G., Kuribayashi, T., Yokoi, S., Inui, K.: Attention is not only a weight: Analyzing transformers with vector norms. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 7057–7075 (2020)
2020
-
[14]
In: Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP
Hanna, M., Piotrowski, M., Lindsey, J., Ameisen, E.: Circuit-tracer: A new library for finding feature circuits. In: Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. pp. 239–249. Association for Computational Linguistics, Suzhou, China (2025)
2025
-
[15]
Distill (2020)
Sturmfels, P., Lundberg, S., Lee, S.I.: Visualizing the impact of feature attribution baselines. Distill (2020)
2020
-
[16]
Web Download (1999), lDC Catalog No
Marcus, M.P., Santorini, B., Marcinkiewicz, M.A., Taylor, A.: Treebank-3. Web Download (1999), lDC Catalog No. LDC99T42.https://catalog.ldc.upenn. edu/LDC99T42. DOI:https://doi.org/10.35111/gq1x-j780
-
[17]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP)
Sanyal, S., Ren, X.: Discretized integrated gradients for explaining language mod- els. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP). pp. 10285–10299 (2021)
2021
-
[18]
In: Advances in Neural Information Processing Systems (NeurIPS)
Hase, P., Xie, H., Bansal, M.: The out-of-distribution problem in explainability and search methods for feature importance explanations. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 34, pp. 3650–3666 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.